EPIC-Bench: A Perception-Centric Benchmark for Fine-Grained Embodied Visual Grounding in Vision-Language Models
Pith reviewed 2026-05-20 15:43 UTC · model grok-4.3
The pith
EPIC-Bench reveals that vision-language models struggle with visual grounding needed for physical interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EPIC-Bench is a fine-grained grounding benchmark comprising 6.6k meticulously annotated (Image, Text, Mask) tuples that spans 23 tasks across the three core stages of embodied interaction: Target Localization, Navigation, and Manipulation. Extensive evaluations of over 89 leading VLMs reveal that current models universally struggle with complex visual-text alignment for physical interactions, with critical bottlenecks in multi-target counting, part-whole relationship understanding, and affordance region detection.
What carries the argument
EPIC-Bench, a perception-centric benchmark with 6.6k image-text-mask tuples and 23 fine-grained tasks that isolate visual perceptual capabilities from linguistic priors across Target Localization, Navigation, and Manipulation.
If this is right
- Advanced reasoning models show partial promise but still exhibit the same critical bottlenecks in counting, part-whole relations, and affordance detection.
- Future vision-driven embodied models will need targeted improvements in these three specific perceptual skills to support physical interactions.
- Existing question-answering benchmarks allow models to bypass genuine visual grounding and therefore understate the gaps.
- The three-stage pipeline of Target Localization, Navigation, and Manipulation provides a structured way to diagnose and track progress in embodied perception.
- EPIC-Bench supplies actionable insights that can guide the design of training data and objectives for next-generation models.
Where Pith is reading between the lines
- The static image focus leaves open whether the same weaknesses appear in video or sequential decision-making settings typical of real agents.
- Combining EPIC-Bench scores with direct robot trials could test how well benchmark performance predicts physical-world success.
- Architectural changes that strengthen spatial and relational reasoning may be required beyond current scaling approaches.
- The benchmark could be adapted to evaluate grounding in other agent domains such as manipulation in cluttered or changing environments.
Load-bearing premise
The 23 tasks and their annotation masks genuinely isolate visual grounding from linguistic priors and correctly represent the three core stages of embodied interaction.
What would settle it
If leading VLMs achieve near-perfect accuracy across all 23 tasks in EPIC-Bench yet continue to fail in actual robot navigation and manipulation experiments, the benchmark would not be measuring the claimed perceptual bottlenecks.
Figures
















read the original abstract
While large vision-language models (VLMs) are increasingly adopted as the perceptual backbone for embodied agents, existing benchmarks often rely on question-answering or multiple-choice formats. These protocols allow models to exploit linguistic priors rather than demonstrating genuine visual grounding. To address this, we present EPIC-Bench, Embodied PerceptIon BenChmark, a fine-grained grounding benchmark designed to systematically evaluate the visual perceptual capabilities of VLMs in real-world embodied environments. Comprising 6.6k meticulously annotated tuples (Image, Text, Mask), EPIC-Bench spans 23 fine-grained tasks across three core stages of the embodied interaction pipeline: Target Localization, Navigation, and Manipulation. Extensive evaluations of over 89 leading VLMs reveal that while advanced reasoning models show promise, current VLMs universally struggle with complex visual-text alignment for physical interactions. Specifically, models exhibit critical bottlenecks in multi-target counting, part-whole relationship understanding, and affordance region detection. EPIC-Bench provides a robust foundation and actionable insights for advancing the next generation of vision-driven embodied models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EPIC-Bench, a benchmark of 6.6k (Image, Text, Mask) tuples spanning 23 fine-grained tasks across Target Localization, Navigation, and Manipulation stages of embodied interaction. It evaluates 89 VLMs and claims that current models universally struggle with complex visual-text alignment for physical interactions, with critical bottlenecks in multi-target counting, part-whole relationship understanding, and affordance region detection.
Significance. If the tasks and annotations successfully isolate visual grounding, the scale of the evaluation across 89 models would provide a useful foundation and specific, actionable failure modes for improving vision-driven embodied agents.
major comments (2)
- [§3] §3 (Benchmark Construction): The central claim that observed failures reflect perceptual deficits in visual-text alignment rather than linguistic priors depends on the 23 tasks and masks genuinely preventing exploitation of training-data co-occurrences or scene statistics. No text-only baselines, semantically mismatched prompts, or image-ablation results are reported despite the abstract's statement that the benchmark addresses QA-style linguistic shortcuts; this is load-bearing for interpreting navigation and manipulation stage results.
- [§4] §4 (Evaluation): Inter-annotator agreement and details on how the annotation masks were constructed to isolate the three core stages are not provided, leaving open the possibility that high-level linguistic cues suffice for above-chance performance and undermining the identification of specific bottlenecks such as multi-target counting.
minor comments (2)
- [Abstract and §2] The abstract and §2 could more explicitly contrast EPIC-Bench against prior embodied benchmarks (e.g., by citing specific differences in format and controls).
- [§3] Notation for the (Image, Text, Mask) tuples is clear but could include a small illustrative example figure early in §3 to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us clarify the strengths and limitations of EPIC-Bench. We provide point-by-point responses below and commit to revisions that address the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The central claim that observed failures reflect perceptual deficits in visual-text alignment rather than linguistic priors depends on the 23 tasks and masks genuinely preventing exploitation of training-data co-occurrences or scene statistics. No text-only baselines, semantically mismatched prompts, or image-ablation results are reported despite the abstract's statement that the benchmark addresses QA-style linguistic shortcuts; this is load-bearing for interpreting navigation and manipulation stage results.
Authors: We agree that explicit controls for linguistic shortcuts are important to substantiate our claims about perceptual deficits. The benchmark's use of mask-based annotations for fine-grained tasks like multi-target counting and affordance detection is intended to require genuine visual grounding beyond co-occurrence statistics. To address this directly, we will add text-only baselines, semantically mismatched prompt experiments, and image-ablation results to the revised version of the paper. revision: yes
-
Referee: [§4] §4 (Evaluation): Inter-annotator agreement and details on how the annotation masks were constructed to isolate the three core stages are not provided, leaving open the possibility that high-level linguistic cues suffice for above-chance performance and undermining the identification of specific bottlenecks such as multi-target counting.
Authors: Thank you for this observation. We will include inter-annotator agreement statistics for the mask annotations in the revised manuscript. Furthermore, we will provide additional details in the supplementary material on the annotation protocol used to construct the masks for the Target Localization, Navigation, and Manipulation stages, ensuring that the tasks isolate visual perceptual capabilities as claimed. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain or fitted predictions
full rationale
The paper introduces EPIC-Bench as an empirical evaluation benchmark comprising 6.6k annotated (Image, Text, Mask) tuples across 23 tasks. Its claims rest on direct performance measurements of 89 existing VLMs rather than any mathematical derivation, parameter fitting, or prediction step. No equations, self-citations, or ansatzes are invoked to define or force the reported bottlenecks in counting, part-whole relations, or affordance detection; those observations are externally falsifiable against the released benchmark data. The work therefore contains no load-bearing step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 23 tasks across Target Localization, Navigation, and Manipulation accurately represent core embodied interaction stages without allowing exploitation of linguistic priors.
Reference graph
Works this paper leans on
-
[1]
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
Scannet: Richly-annotated 3d reconstructions of indoor scenes.Preprint, arXiv:1702.04405. Dima Damen, Hazel Doughty, Giovanni Maria Farinella, and et al. 2018. Scaling egocentric vision: The epic- kitchens dataset.Preprint, arXiv:1804.02748. Ronghao Dang, Jiayan Guo, Bohan Hou, Sicong Leng, Kehan Li, Xin Li, Jiangpin Liu, Yunxuan Mao, Zhikai Wang, Yuqian ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
RoboNet: Large-Scale Multi-Robot Learning
Robonet: Large-scale multi-robot learning. Preprint, arXiv:1910.11215. Google DeepMind. 2025. Gemini 3: A new era of intelligence. https://blog.google/ products-and-platforms/products/gemini/ gemini-3/. Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. 2024. Embspatial-bench: Bench- marking spatial understanding for embodied tasks with lar...
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[3]
Step3-vl-10b technical report.Preprint, arXiv:2601.09668. Drew A. Hudson and Christopher D. Manning. 2019. Gqa: A new dataset for real-world visual reason- ing and compositional question answering.Preprint, arXiv:1902.09506. Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. 2026. Omnispatial: Towards comprehen...
-
[4]
Beyond the destination: A novel benchmark for exploration-aware embodied question answering. Preprint, arXiv:2503.11117. Justin Johnson, Bharath Hariharan, Laurens van der Maaten, and et al. 2016. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning.Preprint, arXiv:1612.06890. Justin Kerr, Chung Min Kim, Ken Goldberg, Ang...
-
[5]
InarXiv preprint arXiv:2311.00899
Robovqa: Multimodal long-horizon reasoning for robotics. InarXiv preprint arXiv:2311.00899. Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, and et al. 2016. Hollywood in homes: Crowdsourcing data collection for activity understanding.Preprint, arXiv:1604.01753. Aaditya Singh, Adam Fry, Adam Perelman, and et al. 2025. Openai gpt-5 system card.Preprint, arX...
-
[6]
Weiyun Wang, Zhangwei Gao, Lixin Gu, and et al
Bridgedata v2: A dataset for robot learning at scale.Preprint, arXiv:2308.12952. Weiyun Wang, Zhangwei Gao, Lixin Gu, and et al
-
[7]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3.5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency. Preprint, arXiv:2508.18265. Chi Xie, Zhao Zhang, Yixuan Wu, Feng Zhu, Rui Zhao, and Shuang Liang. 2023. Described object detection: Liberating object detection with flexible expressions. Preprint, arXiv:2307.12813. Rui Yang, Hanyang Chen, Junyu Zhang, and et ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
RoboRefer: Towards spatial referring with rea- soning in vision-language models for robotics,
Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. Preprint, arXiv:2506.04308. Jinguo Zhu, Weiyun Wang, Zhe Chen, and et al. 2025. Internvl3: Exploring advanced training and test- time recipes for open-source multimodal models. Preprint, arXiv:2504.10479. A Benchmark Examples In this section, we present detailed ex...
-
[9]
**Image** - An RGB image of the scene
-
[10]
**Target Object Description** - The detailed description of the target object to be localized. Based on the image and the target object description, you need to localize all the target objects in the image. Notice, there might be multiple or none target objects in the image. The number of the objects in your answer should be accurate and consistent with t...
-
[11]
You need to detect all the ground areas in the image
**Image** - An RGB image of the scene. You need to detect all the ground areas in the image. Your localization answer must be precise, and try to maximize the Intersection over Union (IOU) with the Ground Truth as much as possible. You should return multiple bounding boxes if the ground areas are separated by non- ground areas. +Response format [C.2→GD] G...
-
[12]
**Two Images** - The first image is the original image from the first/third perspective, the second image is the overlay image of the target area on the first image
-
[13]
**Target Area Description** - The detailed description of the target area/areas. Based on the scene image and the overlay image of the target area and the target area description, you need to find the feasible path to reach the target area/from one target area to another target area in the scene image. The path should start from the place where the pictur...
-
[14]
**Three Images** - The first image is the original scene from one perspective, the second image is the overlay image of the reference areas in the first image, and the third is the image of the original scene from a different perspective. Based on the first and second images, you need to locate and count the targets in image 3 matching references in image...
-
[15]
**Two Images** - The first image is the original image, the second image is the overlay image of the reference object on the first image
-
[17]
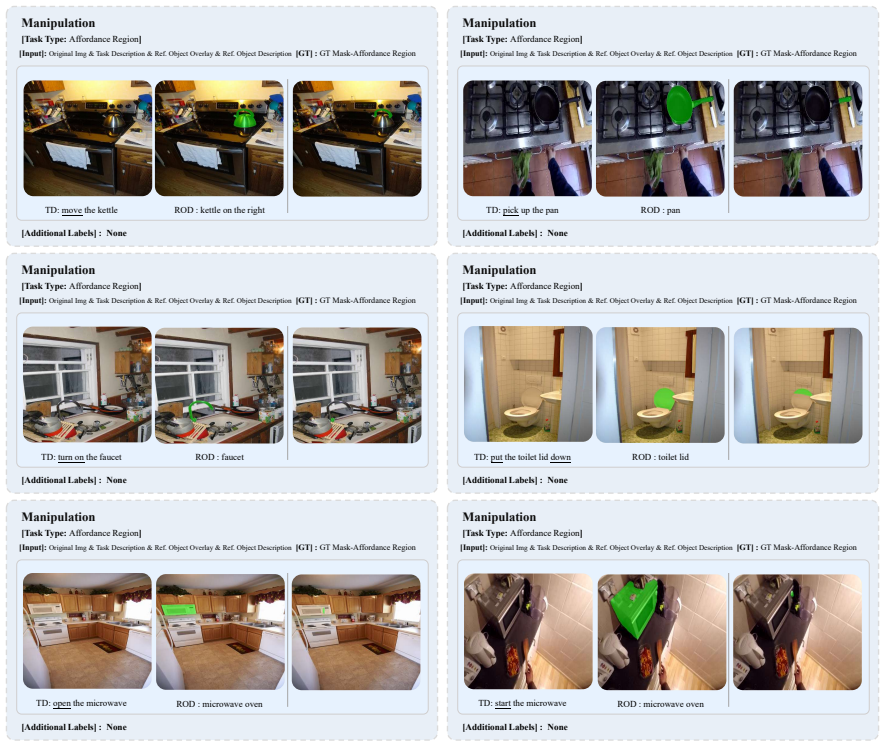
**Task Description** - The detailed description of the task description. You need to localize the Affordance Region of the reference object that can be used to complete the task in the first image. Your answer must be precise, and try to maximize the Intersection over Union (IOU) with the Ground Truth as much as possible. +Response format [C.2→AR] Afforda...
-
[18]
**Two Images** - The first one is the image of the scene, the second one is the overlay image of the reference object on the scene image
-
[19]
**Reference Object Description** - The detailed description of the reference object/objects. Based on the scene image and the overlay image and the reference object description, you need to find all the target objects that are DIRECTLY in contact with the reference object/DIRECTLY and SIMULTANEOUSLY in contact with ALL reference objects/DIRECTLY in contac...
-
[20]
**Two Images** - The first image is the original scene image, the second image is the overlay image of the reference object on the first image
-
[21]
**Reference Object Description** - The detailed description of the reference object
-
[22]
**Placement Region Description** - The detailed description of the placement region. You need to localize the Placement Region in the scene image based on Placement Region Description. And return whether the placement region can be used for the reference object based on the size, stability, or other reasonable factors in the scene image and overlay image....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.