AgentSteerTTS: A Multi-Agent Closed-Loop Framework for Composite-Instruction Text-to-Speech
Pith reviewed 2026-05-20 21:11 UTC · model grok-4.3
The pith
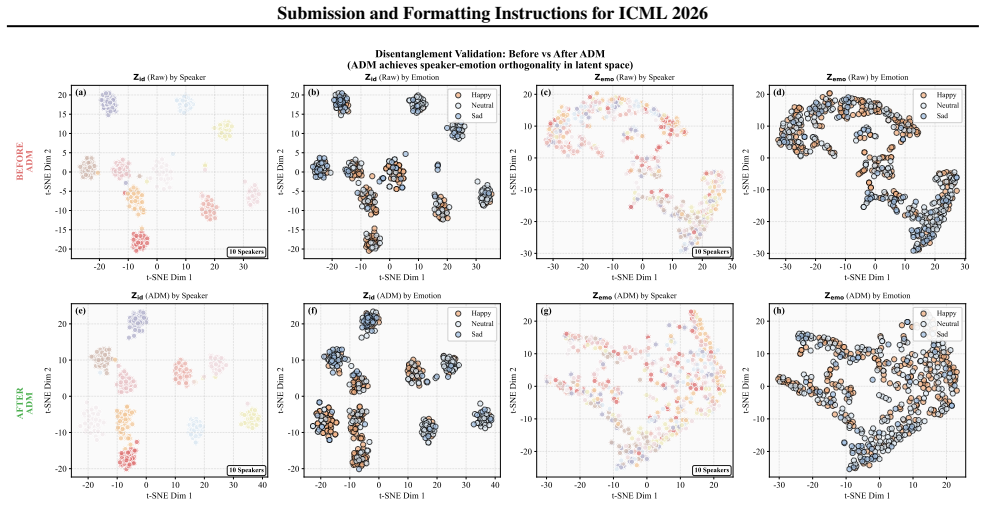
A multi-agent closed-loop framework separates speaker identity from emotion and anchors composite text intents to acoustic prototypes for more faithful TTS output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentSteerTTS is a multi-agent closed-loop framework for intent-faithful expressive control of composite instructions in TTS. An adversarial disentanglement agent mitigates speaker-emotion leakage by learning separable identity and emotion-prosody subspaces with leakage-suppressing regularization. A Dual-Stream Anchoring Controller grounds abstract intents using a large-scale acoustic prototype library, where a Retrieval Agent selects expressive anchors and a Synthesis Agent fuses them into continuous control vectors via gated attention. A Fast-Slow Feedback Agent refines output intensity through latent gradient correction and resolves semantic-acoustic mismatches using high-level perceptual
What carries the argument
The multi-agent closed-loop framework that combines an adversarial disentanglement agent for subspace separation, a dual-stream anchoring controller with retrieval and synthesis agents over an acoustic prototype library, and a fast-slow feedback agent for refinement.
If this is right
- Yields consistent and significant improvements to baselines on a composite-instruction benchmark and public test sets.
- Reduces speaker-emotion leakage through regularization in the disentanglement stage.
- Improves grounding of abstract intents by fusing selected anchors from the acoustic prototype library.
- Resolves semantic-acoustic mismatches via the fast-slow feedback mechanism.
Where Pith is reading between the lines
- The closed-loop structure could support iterative refinement in live applications where a user corrects the output mid-generation.
- Scaling the prototype library with more diverse recordings might extend coverage to rarer composite intents not seen in training.
- Similar agent decomposition might apply to other conditional generation tasks such as controllable video synthesis from mixed instructions.
Load-bearing premise
The framework assumes an adversarial disentanglement agent can reliably learn separable identity and emotion-prosody subspaces without residual leakage and that the acoustic prototype library provides sufficient coverage for grounding arbitrary composite intents.
What would settle it
Run the composite-instruction benchmark with outputs evaluated for measurable leakage between speaker identity and emotion-prosody features; if leakage remains high or scores show no consistent gain over baselines, the central claim does not hold.
Figures


















read the original abstract
While existing text-to-speech (TTS) models exhibit high expressiveness, fine-grained control over composite instructions remains challenging due to the structural mismatch between discrete textual intents and continuous acoustic realizations. Inspired by human cognitive decoupling, we introduce AgentSteerTTS, a multi-agent closed-loop framework designed for intent-faithful expressive control of composite instructions. First, in our framework, an adversarial disentanglement agent mitigates speaker-emotion leakage by learning separable identity and emotion-prosody subspaces with leakage-suppressing regularization. Next, a Dual-Stream Anchoring Controller grounds abstract intents using a large-scale acoustic prototype library: a Retrieval Agent selects expressive anchors, while a Synthesis Agent fuses them into continuous control vectors via gated attention. Finally, a Fast-Slow Feedback Agent refines output intensity through latent gradient correction and resolves semantic-acoustic mismatches using high-level perceptual critique. Experiments on a composite-instruction benchmark and public test sets show that AgentSteerTTS yields consistent and significant improvements to the baselines, demonstrating the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AgentSteerTTS, a multi-agent closed-loop framework for composite-instruction text-to-speech synthesis. It first employs an adversarial disentanglement agent to learn separable identity and emotion-prosody subspaces via leakage-suppressing regularization. A Dual-Stream Anchoring Controller then grounds abstract intents by retrieving expressive anchors from a large-scale acoustic prototype library and fusing them into control vectors with gated attention. A Fast-Slow Feedback Agent refines intensity via latent gradient correction and resolves mismatches with perceptual critique. Experiments on a composite-instruction benchmark and public test sets are reported to yield consistent and significant improvements over baselines.
Significance. If the disentanglement produces cleanly separable subspaces and the prototype library provides sufficient coverage, the framework could meaningfully advance fine-grained, intent-faithful control in expressive TTS, addressing the discrete-to-continuous mismatch that limits current models. The closed-loop multi-agent structure and explicit anchoring mechanism represent a distinct architectural choice that, if validated, may generalize to other conditional generation tasks.
major comments (2)
- [Abstract and §3.1 (adversarial disentanglement agent)] The central claim of consistent improvements rests on the adversarial disentanglement agent producing cleanly separable subspaces. The abstract and method description mention leakage-suppressing regularization, yet no quantitative verification (e.g., correlation coefficients, mutual information, or orthogonality metrics between identity and emotion-prosody embeddings) is provided to confirm residual leakage is negligible in the regimes required for composite instructions. If leakage persists, the Dual-Stream Anchoring Controller cannot ground intents independently, undermining the reported gains.
- [§4 (Experiments)] The experimental results assert 'consistent and significant improvements' on a composite-instruction benchmark and public test sets, but the manuscript provides no tabulated metrics, baseline comparisons, error bars, or statistical tests in the visible description. This absence makes it impossible to evaluate effect sizes or rule out post-hoc selection effects.
minor comments (2)
- [§3.2] Clarify the precise definition and training objective of the gated attention fusion in the Synthesis Agent, including any hyper-parameters that control the balance between retrieved anchors.
- [§3.2] Provide details on the scale, construction, and coverage statistics of the large-scale acoustic prototype library to substantiate the claim that it supports arbitrary composite intents.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating the specific revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3.1 (adversarial disentanglement agent)] The central claim of consistent improvements rests on the adversarial disentanglement agent producing cleanly separable subspaces. The abstract and method description mention leakage-suppressing regularization, yet no quantitative verification (e.g., correlation coefficients, mutual information, or orthogonality metrics between identity and emotion-prosody embeddings) is provided to confirm residual leakage is negligible in the regimes required for composite instructions. If leakage persists, the Dual-Stream Anchoring Controller cannot ground intents independently, undermining the reported gains.
Authors: We agree that quantitative verification of subspace separability is essential to support the claims. In the revised manuscript we will add explicit metrics, including Pearson correlation coefficients, mutual information estimates, and orthogonality measures (e.g., cosine similarity or Gram-matrix off-diagonal norms) computed between the identity and emotion-prosody embeddings on both training and held-out composite-instruction data. These additions will directly demonstrate that residual leakage is negligible under the conditions used for the reported experiments. revision: yes
-
Referee: [§4 (Experiments)] The experimental results assert 'consistent and significant improvements' on a composite-instruction benchmark and public test sets, but the manuscript provides no tabulated metrics, baseline comparisons, error bars, or statistical tests in the visible description. This absence makes it impossible to evaluate effect sizes or rule out post-hoc selection effects.
Authors: We acknowledge that the current presentation lacks sufficient tabular detail for independent evaluation. In the revised version we will include comprehensive result tables that report all objective and subjective metrics for AgentSteerTTS and every baseline, together with standard deviations or confidence intervals, and p-values from appropriate statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests with multiple-comparison correction). This will allow readers to assess effect sizes and rule out selection bias. revision: yes
Circularity Check
No circularity: empirical validation of multi-agent TTS framework
full rationale
The paper describes an architectural framework consisting of an adversarial disentanglement agent, Dual-Stream Anchoring Controller with retrieval and synthesis agents, and Fast-Slow Feedback Agent. Effectiveness is asserted solely through experimental improvements on a composite-instruction benchmark and public test sets, with no mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claim to its own inputs by construction. The description remains self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work in a circular manner.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
work page 2024
-
[2]
Mini-Gemini: Mining the Potential of Multi-Modality Vision Language Models , year=
Li, Yanwei and Zhang, Yuechen and Wang, Chengyao and Zhong, Zhisheng and Chen, Yixin and Chu, Ruihang and Liu, Shaoteng and Jia, Jiaya , journal=. Mini-Gemini: Mining the Potential of Multi-Modality Vision Language Models , year=
-
[3]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =. 2023 , volume =
work page 2023
-
[4]
Kang, Bin and Chen, Bin and Wang, Junjie and Li, Yulin and Zhao, Junzhi and Wang, Junle and Tian, Zhuotao , title =. 2025 , booktitle =
work page 2025
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month =
Zhang, Dong and Li, Shimin and Zhang, Xin and Zhan, Jun and Wang, Pengyu and Zhou, Yaqian and Qiu, Xipeng , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , month =. 2023 , pages =
work page 2023
-
[8]
and King, Irwin and others , title =
Cui, Wenqian and Yu, Dianzhi and Jiao, Xiaoqi and Meng, Ziqiao and Zhang, Guangyan and Wang, Qichao and Guo, Steven Y. and King, Irwin and others , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2025 , pages =
work page 2025
-
[9]
Proceedings of the International Conference on Machine Learning , month =
Ju, Zeqian and Wang, Yuancheng and Shen, Kai and He, Lei and Tan, Xu and Liu, Eric and Leng, Yichong and Zhao, Sheng and Qin, Tao and Bian, Jiang , title =. Proceedings of the International Conference on Machine Learning , month =. 2024 , pages =
work page 2024
-
[10]
Gao, Xiaoxue and Chen, Yiming and Yue, Xianghu and Tsao, Yu and Chen, Nancy F. , journal=. TTSlow: Slow Down Text-to-Speech With Efficiency Robustness Evaluations , year=
-
[11]
Yang, Guanrou and Yang, Chen and Chen, Qian and Ma, Ziyang and Chen, Wenxi and Wang, Wen and Wang, Tianrui and others , title =. 2025 , booktitle =
work page 2025
-
[12]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers , year=
Chen, Sanyuan and Wang, Chengyi and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and others , journal=. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers , year=
-
[13]
InstructTTSEval: Benchmarking Complex Natural-Language Instruction Following in Text-to-Speech Systems , author=. 2025 , eprint=
work page 2025
-
[14]
IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System , author=. 2025 , eprint=
work page 2025
-
[15]
Proceedings of the 38th International Conference on Machine Learning , pages =
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
work page 2021
-
[16]
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale , volume =
Le, Matthew and Vyas, Apoorv and Shi, Bowen and Karrer, Brian and Sari, Leda and Moritz, Rashel and others , booktitle =. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale , volume =
-
[17]
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis , year=
Li, Yinghao Aaron and Han, Cong and Mesgarani, Nima , journal=. StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis , year=
-
[18]
IEEE Transactions on Neural Networks and Learning Systems , year =
Diffsody: Disentangling Speaker-Invariant Prosody Representations via Diffusion Probabilistic Models , author =. IEEE Transactions on Neural Networks and Learning Systems , year =
-
[19]
Proceedings of Interspeech , year =
DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speech , author =. Proceedings of Interspeech , year =
-
[20]
Self-Refine: Iterative Refinement with Self-Feedback , volume =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and others , booktitle =. Self-Refine: Iterative Refinement with Self-Feedback , volume =
-
[21]
Zhou, Kun and Sisman, Berrak and Liu, Rui and Li, Haizhou , booktitle=. Seen and Unseen Emotional Style Transfer for Voice Conversion with A New Emotional Speech Dataset , year=
- [22]
-
[23]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation , author =. Findings of the Association for Computational Linguistics: ACL 2024 , year =
work page 2024
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
-
[25]
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens , author =. 2024 , eprint =
work page 2024
-
[26]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models , author =. 2024 , eprint =
work page 2024
-
[27]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens , author=. 2025 , eprint=
work page 2025
-
[28]
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech , author =. 2025 , eprint =
work page 2025
-
[29]
International Conference on Learning Representations (ICLR) , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[30]
Multi-agent reinforcement learning for resources allocation optimization: a survey. , author =. Artificial Intelligence Review , year =
-
[31]
Proceedings of the Thirteenth International Conference on Learning Representations , year =
DoF: A Diffusion Factorization Framework for Offline Multi-Agent Reinforcement Learning , author =. Proceedings of the Thirteenth International Conference on Learning Representations , year =
-
[32]
and Cai, Tianhui and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , title =
Zhou, Zewei and Zhao, Seth Z. and Cai, Tianhui and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[33]
Yang, Guanrou and Yang, Chen and Chen, Qian and Ma, Ziyang and Chen, Wenxi and Wang, Wen and Wang, Tianrui and Yang, Yifan and others , title =. 2025 , booktitle =
work page 2025
-
[34]
AlphaAgents: Large Language Model based Multi-Agents for Equity Portfolio Constructions , author=. 2025 , eprint=
work page 2025
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
work page 2025
-
[37]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM , author =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
work page 2025
-
[38]
Gao, Xiaoxue and Zhang, Chen and Chen, Yiming and Zhang, Huayun and Chen, Nancy F. , booktitle=. Emo-DPO: Controllable Emotional Speech Synthesis through Direct Preference Optimization , year=
-
[39]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers , author =. 2023 , eprint =
work page 2023
-
[40]
MM-TTS: A Unified Framework for Multi-Modal Prompt-Based Emotional Text-to-Speech , author =. 2024 , eprint =
work page 2024
- [41]
-
[42]
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context , author =. 2024 , eprint =
work page 2024
- [43]
- [44]
-
[45]
Guiding FastSpeech2 Towards Emotional Text-to-Speech , author =. 2023 , eprint =
work page 2023
-
[46]
An Emotion Speech Synthesis Method Based on VITS , author =. Applied Sciences , year =
-
[47]
Advances in Neural Information Processing Systems (NeurIPS) , year =
GenerSpeech: Towards Style Transfer for Generalizable Out-of-Domain Text-to-Speech , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[48]
Cognition & Emotion , volume =
An Argument for Basic Emotions , author =. Cognition & Emotion , volume =
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , year =
CAMEL: Communicative Agents for ``Mind'' Exploration of Large Language Model Society , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[52]
IEEE International Conference on Multimedia & Expo (ICME) , year =
DialogueAgents: A Hybrid Agent-Based Speech Synthesis Framework for Multi-Party Dialogue , author =. IEEE International Conference on Multimedia & Expo (ICME) , year =
-
[54]
Kang, Bin and Wen, Shaoguo and Bi, Yifei and Wu, Shunlong and Yuan, Xinbin and Shao, Rui and Wang, Junle and Tian, Zhuotao , booktitle =. LongHorizon
-
[55]
Less is More, But Where? Dynamic Token Compression via
Li, Yulin and Gui, Haokun and Fan, Ziyang and Wang, Junjie and Kang, Bin and Chen, Bin and Tian, Zhuotao , journal =. Less is More, But Where? Dynamic Token Compression via
-
[56]
Proceedings of the 14th International Conference on Learning Representations , year =
Efficient Reasoning with Balanced Thinking , author =. Proceedings of the 14th International Conference on Learning Representations , year =
-
[57]
Wang, Junjie and Chen, Bin and Li, Yulin and Kang, Bin and Chen, Yichi and Tian, Zhuotao , booktitle =
-
[58]
Wang, Junjie and Chen, Bin and Kang, Bin and Li, Yulin and Xian, Weizhi and Chen, Yichi and Xu, Yong , booktitle =
-
[60]
Mini-Gemini: Mining the Potential of Multi-Modality Vision Language Models
Li, Yanwei, Zhang, Yuechen, Wang, Chengyao, Zhong, Zhisheng, Chen, Yixin, Chu, Ruihang, Liu, Shaoteng, and Jia, Jiaya. Mini-Gemini: Mining the Potential of Multi-Modality Vision Language Models. IEEE Transactions on Pattern Analysis and Machine Intelligence. pages 1-14. 2025
work page 2025
-
[61]
Li, Junnan, Li, Dongxu, Savarese, Silvio, and Hoi, Steven. BLIP -2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. Proceedings of the 40th International Conference on Machine Learning. 202, pages 19730--19742. 2023
work page 2023
-
[62]
CalibCLIP: Contextual Calibration of Dominant Semantics for Text-Driven Image Retrieval
Kang, Bin, Chen, Bin, Wang, Junjie, Li, Yulin, Zhao, Junzhi, Wang, Junle, and Tian, Zhuotao. CalibCLIP: Contextual Calibration of Dominant Semantics for Text-Driven Image Retrieval. Proceedings of the 33rd ACM International Conference on Multimedia. pages 5140--5149. 2025
work page 2025
-
[63]
Less is More, But Where? Dynamic Token Compression via LLM -Guided Keyframe Prior
Li, Yulin, Gui, Haokun, Fan, Ziyang, Wang, Junjie, Kang, Bin, Chen, Bin, and Tian, Zhuotao. Less is More, But Where? Dynamic Token Compression via LLM -Guided Keyframe Prior. Advances in Neural Information Processing Systems. 38, pages 156861--156904. 2026
work page 2026
-
[64]
Efficient Reasoning with Balanced Thinking
Li, Yulin, Tu, Tengyao, Ding, Li, Wang, Junjie, Zhen, Huiling, Chen, Yixin, Yong, Li, and Tian, Zhuotao. Efficient Reasoning with Balanced Thinking. Proceedings of the 14th International Conference on Learning Representations. 2026
work page 2026
-
[65]
SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
Zhang, Dong, Li, Shimin, Zhang, Xin, Zhan, Jun, Wang, Pengyu, Zhou, Yaqian, and Qiu, Xipeng. SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. Findings of the Association for Computational Linguistics: EMNLP 2023. pages 15757-15773. 2023
work page 2023
-
[66]
AudioPaLM: A Large Language Model That Can Speak and Listen
Rubenstein, Paul K., Asawaroengchai, Chulayuth, Nguyen, Duc Dung, Bapna, Ankur, Borsos, Zal \'a n, and others. AudioPaLM: A Large Language Model That Can Speak and Listen. arXiv preprint arXiv:2306.12925. 2023. arXiv:2306.12925
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Recent Advances in Speech Language Models: A Survey
Cui, Wenqian, Yu, Dianzhi, Jiao, Xiaoqi, Meng, Ziqiao, Zhang, Guangyan, Wang, Qichao, Guo, Steven Y., King, Irwin, and others. Recent Advances in Speech Language Models: A Survey. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pages 13943--13970. 2025
work page 2025
-
[69]
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Ju, Zeqian, Wang, Yuancheng, Shen, Kai, He, Lei, Tan, Xu, Liu, Eric, Leng, Yichong, Zhao, Sheng, Qin, Tao, and Bian, Jiang. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. Proceedings of the International Conference on Machine Learning. pages 59545--59570. 2024
work page 2024
-
[70]
TTSlow: Slow Down Text-to-Speech With Efficiency Robustness Evaluations
Gao, Xiaoxue, Chen, Yiming, Yue, Xianghu, Tsao, Yu, and Chen, Nancy F. TTSlow: Slow Down Text-to-Speech With Efficiency Robustness Evaluations. IEEE Transactions on Audio, Speech and Language Processing. 33, pages 693-704. 2025
work page 2025
-
[71]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chen, Sanyuan, Wang, Chengyi, Wu, Yu, Zhang, Ziqiang, Zhou, Long, Liu, Shujie, Chen, Zhuo, Liu, Yanqing, and others. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 33, pages 705-718. 2025
work page 2025
-
[72]
Kexin Huang, Qian Tu, Liwei Fan, Chenchen Yang, Dong Zhang, Shimin Li, Zhaoye Fei, Qinyuan Cheng, and Xipeng Qiu. InstructTTSEval: Benchmarking Complex Natural-Language Instruction Following in Text-to-Speech Systems. Manuscript. 2025. arXiv:2506.16381
-
[73]
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Yang, Guanrou, Yang, Chen, Chen, Qian, Ma, Ziyang, Chen, Wenxi, Wang, Wen, Wang, Tianrui, and others. EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting. Proceedings of the 33rd ACM International Conference on Multimedia. pages 10748--10757. 2025
work page 2025
-
[74]
Zhou, Siyi, Zhou, Yiquan, He, Yi, Zhou, Xun, Wang, Jinchao, Deng, Wei, and Shu, Jingchen. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech. Manuscript. 2025. arXiv:2506.21619
-
[75]
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Kim, Jaehyeon, Kong, Jungil, and Son, Juhee. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. Proceedings of the 38th International Conference on Machine Learning. 139, pages 5530--5540. 2021
work page 2021
-
[76]
Seen and Unseen Emotional Style Transfer for Voice Conversion with A New Emotional Speech Dataset
Zhou, Kun, Sisman, Berrak, Liu, Rui, and Li, Haizhou. Seen and Unseen Emotional Style Transfer for Voice Conversion with A New Emotional Speech Dataset. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pages 920-924. 2021
work page 2021
-
[77]
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
Le, Matthew, Vyas, Apoorv, Shi, Bowen, Karrer, Brian, Sari, Leda, Moritz, Rashel, and others. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. Advances in Neural Information Processing Systems. 36, pages 14005--14034. 2023
work page 2023
-
[78]
Diffsody: Disentangling Speaker-Invariant Prosody Representations via Diffusion Probabilistic Models
Qu, Leyuan, Zhang, Zhuo, Huang, Xiaoliang, Wen, Ping, Zhang, Rui, Wang, Wen, and others. Diffsody: Disentangling Speaker-Invariant Prosody Representations via Diffusion Probabilistic Models. IEEE Transactions on Neural Networks and Learning Systems. pages 1--12. 2025
work page 2025
-
[79]
Cho, Deok-Hyeon, Oh, Hyung-Seok, Kim, Seung-Bin, and Lee, Seong-Whan. DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speech. Proceedings of Interspeech. pages 4373--4377. 2025
work page 2025
-
[80]
An Argument for Basic Emotions
Ekman, Paul. An Argument for Basic Emotions. Cognition & Emotion. 6(3--4), pages 169--200. 1992
work page 1992
-
[81]
An Emotion Speech Synthesis Method Based on VITS
Zhao, Wei and Yang, Zheng. An Emotion Speech Synthesis Method Based on VITS. Applied Sciences. 13(4), pages 2225. 2023
work page 2023
-
[82]
Guiding FastSpeech2 Towards Emotional Text-to-Speech
Ju, Zeqian and others. Guiding FastSpeech2 Towards Emotional Text-to-Speech. Manuscript. 2023. arXiv:2307.00024
-
[83]
GenerSpeech: Towards Style Transfer for Generalizable Out-of-Domain Text-to-Speech
Zhao, Yue and others. GenerSpeech: Towards Style Transfer for Generalizable Out-of-Domain Text-to-Speech. Advances in Neural Information Processing Systems (NeurIPS). 2022
work page 2022
-
[84]
Self-Refine: Iterative Refinement with Self-Feedback
Madaan, Aman, Tandon, Niket, Gupta, Prakhar, Hallinan, Skyler, Gao, Luyu, Wiegreffe, Sarah, Alon, Uri, and others. Self-Refine: Iterative Refinement with Self-Feedback. Advances in Neural Information Processing Systems. 36, pages 46534--46594. 2023
work page 2023
-
[85]
Salman, Wei-Cheng Lin, and others
Carlos Busso, Reza Lotfian, Kusha Sridhar, Ali N. Salman, Wei-Cheng Lin, and others. The MSP-Podcast Corpus. Manuscript. 2025. arXiv:2509.09791
-
[86]
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation
Ma, Ziyue, Zheng, Zhisheng, Ye, Jiaxin, Li, Jinchao, Gao, Zhifu, Zhang, ShiLiang, and others. emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation. Findings of the Association for Computational Linguistics: ACL 2024. pages 15747--15760. 2024
work page 2024
-
[87]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Chen, Yushen, Niu, Zhikang, Ma, Ziyang, Deng, Keqi, Wang, Chunhui, JianZhao, JianZhao, Yu, Kai, and Chen, Xie. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. pages 6255--6271. 2025
work page 2025
-
[88]
Du, Zhihao, Chen, Qian, Zhang, Shiliang, Hu, Kai, Lu, Heng, Yang, Yexin, Hu, Hangrui, and others. CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens. Manuscript. 2024. arXiv:2407.05407
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.