SparseSAM: Structured Sparsification of Activations in Segment Anything Models
Pith reviewed 2026-05-20 13:40 UTC · model grok-4.3
The pith
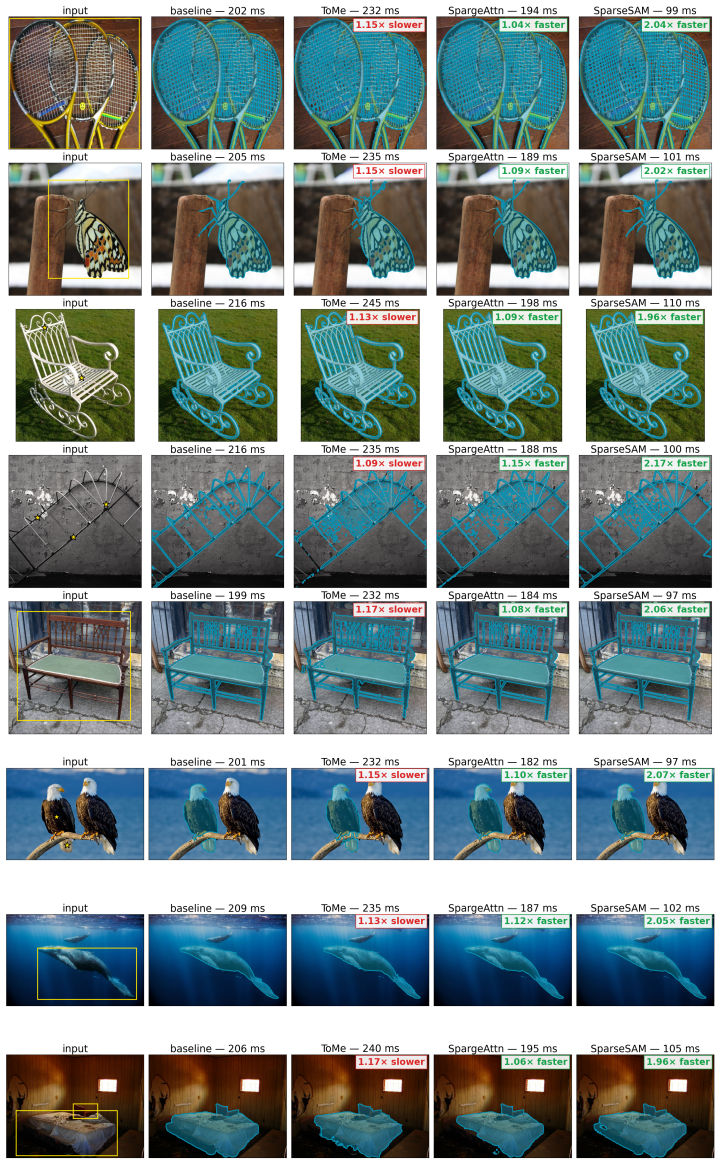
SparseSAM applies structured sparsification to SAM's activations for 2x faster inference and 2.8x memory savings with under 0.03 mIoU loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SparseSAM introduces Stripe-Sort Attention that converts dense attention into static sparse patterns via a deterministic Z-order permutation and pairs it with a Residual-Consistency MLP that routes only informative tokens through the MLP while sending the rest down the residual path, yielding 2x faster inference and 2.8x memory reduction across four benchmarks while limiting mIoU loss to 0.004 at 0.4 density and 0.021 at 0.3 density.
What carries the argument
Stripe-Sort Attention with Z-order permutation for static hardware-friendly sparse attention patterns, together with Residual-Consistency MLP for selective token routing that preserves information flow without dynamic overhead.
If this is right
- At 0.4 density the method loses only 0.004 mIoU on the benchmarks.
- At 0.3 density the accuracy loss is 0.021, which is 2.10 times smaller than the loss from token merging.
- Inference speed doubles while memory footprint shrinks by a factor of 2.8.
- The approach works without retraining or fine-tuning on existing SAM checkpoints.
Where Pith is reading between the lines
- The static sparse patterns created by Z-order permutation could map directly onto sparse matrix accelerators for additional speedups.
- Because the method is training-free it can be inserted into any deployed SAM pipeline as a drop-in replacement.
- Similar structured sparsification might extend to other ViT-based segmentation or detection models that share the same encoder bottleneck.
- Combining SparseSAM with quantization could produce even larger efficiency gains at the cost of one extra hyper-parameter.
Load-bearing premise
The fixed Z-order reordering and residual bypass for some tokens are assumed to retain enough information for accurate open-vocabulary segmentation even at low densities and without any model retraining.
What would settle it
Applying SparseSAM at 0.3 density on the four segmentation benchmarks and measuring an mIoU drop larger than 0.021 relative to the dense baseline would falsify the minimal-accuracy-loss claim.
Figures











read the original abstract
The Segment Anything Model (SAM) achieves strong open-vocabulary segmentation, but its ViT-based image encoders dominate inference latency and memory. Existing activation compression methods, such as token merging, reduce the token length to process, yet introduce non-trivial runtime overhead and encounter catastrophic quality drop under high compression. Other methods applying Sparse Attention focus on attention alone, leaving the MLP fully dense and capping achievable speedup. We propose SparseSAM, a (i) training-free structured sparsification framework that jointly accelerates attention and MLP layers while preserving token identity. SparseSAM introduces (ii) Stripe-Sort Attention, which uses a deterministic Z-order permutation to transform dense attention into static hardware-friendly sparse patterns, eliminating dynamic masking overhead. SparseSAM further introduces a (iii) Residual-Consistency MLP that routes only informative tokens through the MLP while propagating remaining tokens through the residual pathway. Across four segmentation benchmarks, SparseSAM loses only 0.004 mIoU at a 0.4 density and 0.021 mIoU at 0.3, a 2.10x reduction in accuracy loss versus token merging advances, while achieving 2x faster inference and 2.8x memory reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SparseSAM, a training-free structured sparsification framework for the Segment Anything Model (SAM) ViT encoder. It proposes Stripe-Sort Attention, which applies a deterministic Z-order permutation to convert dense attention into static hardware-friendly sparse patterns, and Residual-Consistency MLP, which routes only informative tokens through the MLP while propagating others via the residual pathway. The paper reports that across four segmentation benchmarks, SparseSAM incurs only 0.004 mIoU loss at 0.4 density and 0.021 mIoU loss at 0.3 density (a 2.10x reduction in accuracy loss versus token merging), while delivering 2x faster inference and 2.8x memory reduction.
Significance. If the empirical results and information-preservation claims hold, the work would offer a practical, retraining-free route to accelerate and compress SAM for open-vocabulary segmentation, addressing a key bottleneck in deploying large ViT-based models under latency and memory constraints.
major comments (3)
- [Abstract] Abstract: the headline claim that the modules 'preserve token identity' and maintain 'exact feature statistics the SAM decoder was trained on' is load-bearing for all reported mIoU figures, yet the text supplies neither a derivation nor an ablation demonstrating that the fixed Z-order permutation respects the original ViT positional encodings or that the routing criterion discards only non-critical tokens under arbitrary prompts.
- [Method (Stripe-Sort Attention)] Method description of Stripe-Sort Attention: the assertion that the deterministic Z-order permutation 'eliminates dynamic masking overhead' while preserving spatial locality is central to the speedup claim, but no analysis is given of how the reordering interacts with the frozen decoder's learned positional biases.
- [Experiments] Experimental results: the reported mIoU deltas (0.004 at density 0.4, 0.021 at 0.3) and the 2.10x accuracy-loss reduction versus baselines are presented without error bars, run counts, or statistical tests, which prevents verification of the cross-benchmark stability asserted in the abstract.
minor comments (1)
- [Abstract] The term 'density' is introduced without an immediate parenthetical definition (e.g., retained token fraction); adding this would aid readers unfamiliar with the compression literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the modules 'preserve token identity' and maintain 'exact feature statistics the SAM decoder was trained on' is load-bearing for all reported mIoU figures, yet the text supplies neither a derivation nor an ablation demonstrating that the fixed Z-order permutation respects the original ViT positional encodings or that the routing criterion discards only non-critical tokens under arbitrary prompts.
Authors: We agree that explicit justification is warranted. In the revised manuscript we will add a derivation in Section 3.1 showing that the deterministic Z-order permutation is a fixed invertible reordering within stripes that preserves relative spatial locality and therefore aligns with the frozen decoder's positional encodings. We will also include a new ablation (Appendix C) evaluating the Residual-Consistency routing criterion on a diverse set of prompts drawn from all four benchmarks, confirming that discarded tokens contribute negligibly to final mIoU. These additions directly support the reported accuracy figures. revision: yes
-
Referee: [Method (Stripe-Sort Attention)] Method description of Stripe-Sort Attention: the assertion that the deterministic Z-order permutation 'eliminates dynamic masking overhead' while preserving spatial locality is central to the speedup claim, but no analysis is given of how the reordering interacts with the frozen decoder's learned positional biases.
Authors: We will expand the Stripe-Sort Attention subsection to provide the requested analysis. Because the permutation is static and identical for every input, it can be exactly inverted after the sparse attention computation; the residual pathway then restores original token identities before the decoder. We will include a short proof that this composition leaves the positional bias terms unchanged relative to the original dense forward pass, together with a timing breakdown confirming the elimination of dynamic masking cost. The revised text will make the interaction explicit. revision: yes
-
Referee: [Experiments] Experimental results: the reported mIoU deltas (0.004 at density 0.4, 0.021 at 0.3) and the 2.10x accuracy-loss reduction versus baselines are presented without error bars, run counts, or statistical tests, which prevents verification of the cross-benchmark stability asserted in the abstract.
Authors: SparseSAM is fully deterministic and training-free, so each benchmark result has zero run-to-run variance. We will revise the Experiments section to state this explicitly, report a run count of one, and tabulate per-benchmark mIoU values so readers can directly inspect cross-benchmark consistency. Formal error bars and statistical tests are not meaningful under determinism; we will instead emphasize reproducibility and the 2.10x reduction relative to token-merging baselines on the same fixed decoder. revision: partial
Circularity Check
No circularity: empirical mIoU and speedup results are direct measurements, not reductions to fitted inputs or self-citations
full rationale
The paper proposes training-free modules (Stripe-Sort Attention via fixed Z-order permutation and Residual-Consistency MLP with selective routing plus residual bypass) and evaluates them empirically on four segmentation benchmarks. Reported figures (0.004/0.021 mIoU loss at 0.4/0.3 density, 2x inference speedup, 2.8x memory reduction) are presented as observed outcomes versus baselines. No equations, predictions, or load-bearing claims reduce these results to parameters fitted from the same data or to self-citations whose content is unverified. The derivation chain consists of method definitions followed by independent experimental validation; the central performance claims remain falsifiable outside any internal fit.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Deterministic Z-order permutation transforms dense attention into static hardware-friendly sparse patterns without dynamic overhead
- domain assumption Routing only informative tokens through MLP while propagating others via residual pathway preserves model output quality
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Stripe-Sort Attention, which uses a deterministic Z-order permutation to transform dense attention into static hardware-friendly sparse patterns
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Residual-Consistency MLP that routes only informative tokens through the MLP while propagating remaining tokens through the residual pathway
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network.arXiv preprint arXiv:2504.13181, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Zigeng Chen, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Slimsam: 0.1% data makes segment anything slim.Advances in Neural Information Processing Systems, 37:39434–39461, 2024
work page 2024
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[7]
Cihan Erkan and Selim Aksoy. Space-filling curves for modeling spatial context in transformer- based whole slide image classification. InMedical Imaging 2023: Digital and Computational Pathology, volume 12471, pages 416–423. SPIE, 2023
work page 2023
-
[8]
YOLOX: Exceeding YOLO Series in 2021
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021.arXiv preprint arXiv:2107.08430, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Rafael C Gonzalez.Digital image processing. Pearson education india, 2009
work page 2009
-
[10]
Detrs with hybrid matching.arXiv preprint arXiv:2207.13080, 2022
Ding Jia, Yuhui Yuan, Haodi He, Xiaopei Wu, Haojun Yu, Weihong Lin, Lei Sun, Chao Zhang, and Han Hu. Detrs with hybrid matching.arXiv preprint arXiv:2207.13080, 2022
-
[11]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems, 37:52481–52515, 2024
work page 2024
-
[12]
Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. Segment anything in high quality.arXiv preprint arXiv:2306.01567, 2023
-
[13]
Jiamei Kim, Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Marlin: FP16xINT4 LLM inference kernel that can achieve near-ideal 4x speedups up to medium batchsizes.https://github.com/IST-DASLab/marlin, 2023. Accessed: 2026-05-07. 10
work page 2023
-
[14]
Haopeng Li, Shitong Shao, Wenliang Zhong, Zikai Zhou, Lichen Bai, Hui Xiong, and Zeke Xie. Pisa: Piecewise sparse attention is wiser for efficient diffusion transformers.arXiv preprint arXiv:2602.01077, 2026
-
[15]
Expediting large-scale vision transformer for dense prediction without fine-tuning
Weicong Liang, Yuhui Yuan, Henghui Ding, Xiao Luo, Weihong Lin, Ding Jia, Zheng Zhang, Chao Zhang, and Han Hu. Expediting large-scale vision transformer for dense prediction without fine-tuning. InAdvances in Neural Information Processing Systems, volume 35, pages 35462–35477, 2022
work page 2022
-
[16]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context.arXiv preprint arXiv:1405.0312, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Group fisher pruning for practical network compression
Liyang Liu, Shilong Zhang, Zhanghui Kuang, Aojun Zhou, Jing-Hao Xue, Xinjiang Wang, Yimin Chen, Wenming Yang, Qingmin Liao, and Wayne Zhang. Group fisher pruning for practical network compression. InInternational Conference on Machine Learning, pages 7021–7032. PMLR, 2021
work page 2021
-
[18]
Structured knowledge distillation for semantic segmentation
Yifan Liu, Ke Chen, Chris Liu, Zengchang Qin, Zhenbo Luo, and Jingdong Wang. Structured knowledge distillation for semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2604–2613, 2019
work page 2019
-
[19]
Learning efficient convolutional networks through network slimming
Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming. InProceedings of the IEEE International Conference on Computer Vision, pages 2736–2744, 2017
work page 2017
-
[20]
Ptq4sam: Post-training quantization for segment anything
Chengtao Lv, Hong Chen, Jinyang Guo, Yifu Ding, and Xianglong Liu. Ptq4sam: Post-training quantization for segment anything. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 15941–15951, 2024
work page 2024
-
[21]
International Business Machines Company, 1966
Guy M Morton.A computer oriented geodetic data base and a new technique in file sequencing. International Business Machines Company, 1966
work page 1966
-
[22]
Duy MH Nguyen, Tuan A Tran, Duong Nguyen, Siwei Xie, Trung Q Nguyen, Mai TN Truong, Daniel Palenicek, An T Le, Michael Barz, TrungTin Nguyen, et al. Structsam: Structure-and spectrum-preserving token merging for segment anything models.arXiv preprint arXiv:2603.07307, 2026
-
[23]
Mix-qsam: Mixed-precision quantization of the segment anything model
Navin Ranjan and Andreas Savakis. Mix-qsam: Mixed-precision quantization of the segment anything model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3280–3290, 2025
work page 2025
-
[24]
JZ-Tree: GPU friendly neighbour search and friends-of-friends with dual tree walks in JAX plus CUDA
Jens Stücker, Oliver Hahn, Lukas Winkler, Adrian Gutierrez Adame, and Thomas Flöss. Jz-tree: Gpu friendly neighbour search and friends-of-friends with dual tree walks in jax plus cuda. arXiv preprint arXiv:2604.05885, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Chau Tran, Duy MH Nguyen, Manh-Duy Nguyen, TrungTin Nguyen, Ngan Le, Pengtao Xie, Daniel Sonntag, James Y Zou, Binh Nguyen, and Mathias Niepert. Accelerating transformers with spectrum-preserving token merging.Advances in Neural Information Processing Systems, 37:30772–30810, 2024
work page 2024
-
[26]
Tuan Anh Tran, Duy MH Nguyen, Hoai-Chau Tran, Michael Barz, Khoa D Doan, Roger Watten- hofer, Ngo Anh Vien, Mathias Niepert, Daniel Sonntag, and Paul Swoboda. How many tokens do 3d point cloud transformer architectures really need?arXiv preprint arXiv:2511.05449, 2025
-
[27]
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, and Jiwen Lu. Q-vlm: Post-training quantization for large vision-language models.Advances in Neural Information Processing Systems, 37:114553–114573, 2024
work page 2024
-
[28]
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, et al. Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776, 2025. 11
-
[29]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, et al. Efficientsam: Leveraged masked image pretraining for efficient segment anything.arXiv preprint arXiv:2312.00863, 2023
-
[31]
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, et al. Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation.arXiv preprint arXiv:2505.18875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. Flashinfer: Efficient and customizable attention engine for llm inference serving.arXiv preprint arXiv:2501.01005, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung- Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Jiarui Zhang, Chao Xiang, Haofeng Huang, Jingyan Wei, Haoyuan Xi, Jun Zhu, and Jianfei Chen. Spargeattention: Accurate and training-free sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025
-
[36]
Ahcptq: Accurate and hardware-compatible post-training quantization for segment anything model
Wenlun Zhang, Yunshan Zhong, Shimpei Ando, and Kentaro Yoshioka. Ahcptq: Accurate and hardware-compatible post-training quantization for segment anything model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22383–22392, 2025
work page 2025
-
[37]
arXiv preprint arXiv:2306.12156 (2023) 31
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. Fast segment anything.arXiv preprint arXiv:2306.12156, 2023
-
[38]
Edgesam: Prompt-driven edge-aware segmentation with segment anything.arXiv preprint, 2023
Chong Zhou, Xiangtai Li, Chen Change Loy, and Bo Dai. Edgesam: Prompt-driven edge-aware segmentation with segment anything.arXiv preprint, 2023. 12 A Appendix A.1 Attention Kernel Pseudo Code Algorithm 1A-Shape Windowed FlashAttention-2 with Decomposed 2D Rel-Pos Bias // Attention input with decomposed 2D biasB[q, k]=B H[q, krow]+BW [q, kcol]on aw×wgrid I...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.