MARR: Module-Adaptive Residual Reconstruction for Low-Bit Post-Training Quantization
Pith reviewed 2026-05-20 12:52 UTC · model grok-4.3
The pith
Per-module scaling coefficients balance residual error correction against Hessian bias in low-bit quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multiplying each module's residual by its own scaling coefficient reduces the Hessian-approximation bias tied to residual strength while still correcting accumulated layer-wise error, and a PID-based update driven by reconstruction error supplies a stable, search-free way to set that coefficient for every module.
What carries the argument
Module-specific scaling coefficient for the residual term, adaptively refined by a PID controller that uses reconstruction error as feedback.
If this is right
- Up to 20.2 percent performance lift on LLMs compared with prior residual-reconstruction methods.
- Up to 4.6 percent relative improvement on vision transformers under the same low-bit regime.
- No need for expensive per-module grid search to choose the scaling values.
- Stable coefficient estimates obtained solely from reconstruction-error feedback during the quantization process.
Where Pith is reading between the lines
- The same per-module adaptive correction idea could be tested in other compression settings that rely on layer-wise approximations.
- If the PID loop converges reliably across model families, it may serve as a lightweight online tuner for any reconstruction-based optimizer.
- Measuring how strongly the optimal coefficient correlates with module depth or activation statistics would clarify when the module dependence is strongest.
Load-bearing premise
The trade-off between accumulated-error correction and residual-related HA bias is module-dependent and can be stably controlled by a PID-based update that uses reconstruction error as feedback without introducing instabilities or requiring per-module search.
What would settle it
Low-bit quantization runs in which the PID-tuned per-module coefficients produce no accuracy gain or even degrade results relative to a single global scaling factor on standard LLM and ViT test sets would falsify the claim.
Figures
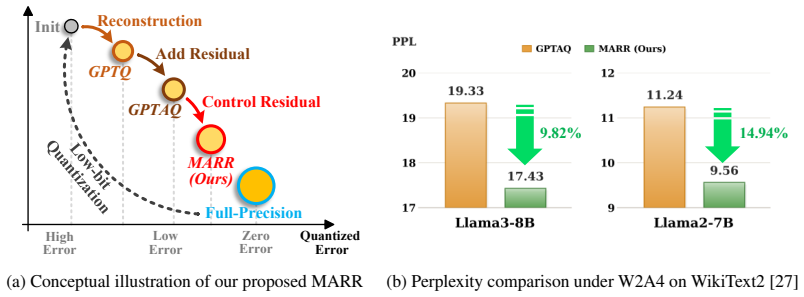








read the original abstract
Recently, residual reconstruction-based model quantization methods have achieved promising performance in low-bit post-training quantization (PTQ) by introducing cross-layer residuals to reduce error accumulated from previous layers.However, these residuals may also introduce additional bias arising from the Hessian-approximation (HA) assumption underlying reconstruction-based PTQ, leading to suboptimal quantization performance.In this work, we analyze that multiplying the residual term by a scaling coefficient provides a direct way to mitigate the HA bias associated with residual strength, while preserving accumulated-error correction. More importantly, we observe that this trade-off is module-dependent, making a single global residual strength insufficient to balance effective correction and residual-related bias across modules.Based on these observations, we propose Module-Adaptive Residual Reconstruction (MARR), which assigns a module-specific scaling coefficient to adaptively balance accumulated-error correction and residual-related HA bias for each module.To avoid expensive per-module coefficient search and obtain a stable coefficient estimate, we design a Proportional-Integral-Derivative (PID)-based adaptive update strategy that uses reconstruction error as feedback to progressively refine this coefficient. Experiments on several typical large language models (LLMs) and vision transformers (ViTs) demonstrate the effectiveness of MARR under low-bit quantization (less than or equal to 4-bit), achieving up to 20.2% performance gains on LLMs and up to 4.6% relative gains on ViTs over the residual reconstruction state-of-the-art methods.Code will be made publicly available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Module-Adaptive Residual Reconstruction (MARR) for low-bit post-training quantization. It identifies that residual reconstruction in PTQ methods introduces a module-dependent trade-off between correcting accumulated errors from previous layers and mitigating bias from the Hessian approximation (HA) assumption. To address this, MARR introduces module-specific scaling coefficients for the residual terms, updated adaptively via a PID controller that uses reconstruction error as feedback. This is claimed to avoid per-module search while achieving up to 20.2% performance improvements on LLMs and 4.6% on ViTs compared to state-of-the-art residual reconstruction methods.
Significance. If validated, the approach could offer an efficient way to enhance quantization performance for large models by adaptively balancing error correction and bias per module without extensive hyperparameter tuning. The observation about module-dependence of the trade-off is a useful insight for the PTQ community, and the PID-based adaptation represents a creative application of control theory to quantization optimization. However, the significance is tempered by the need to confirm that the gains are not artifacts of the adaptation process itself.
major comments (2)
- [3.2 (PID-based Adaptive Update)] The central claim depends on the PID controller producing stable, module-specific scaling coefficients that effectively balance the trade-off. However, the manuscript provides no analysis of PID convergence, no sensitivity experiments on the proportional, integral, and derivative gains, and no demonstration that the trajectories do not oscillate or reduce to a global scalar. This leaves open the possibility that the reported gains arise from per-module flexibility rather than the claimed adaptive mechanism.
- [4 (Experiments)] Table or figure reporting the main results: there is no ablation study comparing MARR's adaptive coefficients to fixed per-module coefficients found by grid search or to a single global coefficient. Such an ablation is necessary to establish that the module-adaptive PID update is load-bearing for the 20.2% and 4.6% relative gains over baselines.
minor comments (2)
- [Abstract] The performance gains are stated as 'up to 20.2%' and 'up to 4.6% relative gains' without specifying the exact evaluation metric (e.g., perplexity, accuracy) or the precise baselines used in each case.
- [Introduction] The description of the HA bias could benefit from a more formal derivation or equation showing how the scaling coefficient directly mitigates the bias while preserving error correction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the module-dependent trade-off observation and the application of control theory to PTQ. We address each major comment below with point-by-point responses and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [3.2 (PID-based Adaptive Update)] The central claim depends on the PID controller producing stable, module-specific scaling coefficients that effectively balance the trade-off. However, the manuscript provides no analysis of PID convergence, no sensitivity experiments on the proportional, integral, and derivative gains, and no demonstration that the trajectories do not oscillate or reduce to a global scalar. This leaves open the possibility that the reported gains arise from per-module flexibility rather than the claimed adaptive mechanism.
Authors: We agree that explicit analysis of PID behavior would strengthen the manuscript. In the revised version we add convergence plots demonstrating that the per-module scaling coefficients stabilize rapidly without oscillation. We also include sensitivity experiments across a range of proportional, integral, and derivative gains, showing that performance remains stable for reasonable hyperparameter choices. Finally, we report the variance of converged coefficients across modules together with trajectory visualizations confirming that the values remain distinctly module-specific and do not collapse to a single global scalar. These additions support that the adaptive feedback mechanism, rather than static per-module assignment alone, contributes to the observed gains. revision: yes
-
Referee: [4 (Experiments)] Table or figure reporting the main results: there is no ablation study comparing MARR's adaptive coefficients to fixed per-module coefficients found by grid search or to a single global coefficient. Such an ablation is necessary to establish that the module-adaptive PID update is load-bearing for the 20.2% and 4.6% relative gains over baselines.
Authors: We concur that this ablation is necessary to isolate the contribution of the PID-based adaptation. We have added the requested comparison to the experimental section: (i) MARR with PID-adaptive coefficients, (ii) fixed per-module coefficients obtained via grid search, and (iii) a single global coefficient. The new results show that fixed per-module coefficients improve upon the global baseline, yet the PID-adaptive version yields further consistent gains, indicating that the dynamic, error-feedback update is load-bearing for the reported improvements over prior residual-reconstruction methods. The ablation table and accompanying discussion will appear in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation rests on the observation that residual scaling trades off accumulated-error correction against HA bias in a module-dependent manner, followed by the introduction of a PID controller that updates the scaling coefficient using reconstruction error as feedback. This feedback mechanism is an external adaptive controller applied to the quantization objective rather than a self-definitional loop or a fitted parameter that is then relabeled as a prediction. No equations are presented in which the claimed performance gain reduces by construction to the input reconstruction error, no self-citations load-bear the central premise, and no uniqueness theorem imported from prior author work is invoked. The method therefore remains self-contained against external benchmarks and does not collapse into tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- module-specific scaling coefficients
axioms (1)
- domain assumption The Hessian-approximation assumption in reconstruction-based PTQ introduces bias that is proportional to residual strength.
Reference graph
Works this paper leans on
-
[1]
AI@Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/blob/ main/MODEL_CARD.md
work page 2024
-
[2]
A pid controller approach for stochastic optimization of deep networks
Wangpeng An, Haoqian Wang, Qingyun Sun, Jun Xu, Qionghai Dai, and Lei Zhang. A pid controller approach for stochastic optimization of deep networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8522–8531, 2018
work page 2018
-
[3]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems, 37:100213–100240, 2024
work page 2024
-
[4]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. doi: 10.1609/aaai.v34i05.6239
-
[5]
Zhuotong Chen, Zihu Wang, Yifan Yang, Qianxiao Li, and Zheng Zhang. Pid control-based self-healing to improve the robustness of large language models.arXiv preprint arXiv:2404.00828, 2024
-
[6]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10558–10578, 2024
work page 2024
-
[7]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2924–2936, Minneapolis, Minn...
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Elias Frantar and Dan Alistarh. Optimal brain compression: A framework for accurate post-training quantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
work page 2022
-
[11]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Ruihao Gong, Xianglong Liu, Yuhang Li, Yunqiang Fan, Xiuying Wei, and Jinyang Guo. Pushing the limit of post-training quantization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[13]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International journal of computer vision, 129(6):1789–1819, 2021
work page 2021
-
[14]
Optimal brain surgeon and general network pruning
Babak Hassibi, David G Stork, and Gregory J Wolff. Optimal brain surgeon and general network pruning. InIEEE international conference on neural networks, pages 293–299. IEEE, 1993
work page 1993
-
[15]
Zhi Jin, Yuwei Qiu, Kaihao Zhang, Hongdong Li, and Wenhan Luo. Mb-taylorformer v2: Improved multi-branch linear transformer expanded by taylor formula for image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[16]
Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, and Eunhyeok Park. Owq: Outlier-aware weight quantization for efficient fine-tuning and inference of large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 13355–13364, 2024. 10
work page 2024
-
[17]
Rethinking Residual Errors in Compensation-based LLM Quantization
Shuaiting Li, Juncan Deng, Kedong Xu, Rongtao Deng, Hong Gu, Minghan Jiang, Haibin Shen, and Kejie Huang. Rethinking residual errors in compensation-based llm quantization.arXiv preprint arXiv:2604.07955, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Brecq: Pushing the limit of post-training quantization by block reconstruction
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. Brecq: Pushing the limit of post-training quantization by block reconstruction.arXiv preprint arXiv:2102.05426, 2021
-
[19]
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. Gptaq: Efficient finetuning- free quantization for asymmetric calibration.arXiv preprint arXiv:2504.02692, 2025
-
[20]
Repq-vit: Scale reparameterization for post- training quantization of vision transformers
Zhikai Li, Junrui Xiao, Lianwei Yang, and Qingyi Gu. Repq-vit: Scale reparameterization for post- training quantization of vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17227–17236, 2023
work page 2023
-
[21]
Hou-I Liu, Marco Galindo, Hongxia Xie, Lai-Kuan Wong, Hong-Han Shuai, Yung-Hui Li, and Wen-Huang Cheng. Lightweight deep learning for resource-constrained environments: A survey.ACM Computing Surveys, 56(10):1–42, 2024
work page 2024
-
[22]
arXiv preprint arXiv:2505.05530 , year=
Kai Liu, Qian Zheng, Kaiwen Tao, Zhiteng Li, Haotong Qin, Wenbo Li, Yong Guo, Xianglong Liu, Linghe Kong, Guihai Chen, et al. Low-bit model quantization for deep neural networks: A survey.arXiv preprint arXiv:2505.05530, 2025
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[24]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Ruijun Ma, Bob Zhang, Yicong Zhou, Zhengming Li, and Fangyuan Lei. Pid controller-guided attention neural network learning for fast and effective real photographs denoising.IEEE transactions on neural networks and learning systems, 33(7):3010–3023, 2021
work page 2021
-
[26]
Ruijun Ma, Shuyi Li, Bob Zhang, and Haifeng Hu. Meta pid attention network for flexible and efficient real-world noisy image denoising.IEEE Transactions on Image Processing, 31:2053–2066, 2022
work page 2053
-
[27]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Up or down? adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. InInternational conference on machine learning, pages 7197–7206. PMLR, 2020
work page 2020
-
[29]
Mb-taylorformer: Multi-branch efficient transformer expanded by taylor formula for image dehazing
Yuwei Qiu, Kaihao Zhang, Chenxi Wang, Wenhan Luo, Hongdong Li, and Zhi Jin. Mb-taylorformer: Multi-branch efficient transformer expanded by taylor formula for image dehazing. InProceedings of the IEEE/CVF international conference on computer vision, pages 12802–12813, 2023
work page 2023
-
[30]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[31]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015
work page 2015
-
[32]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021. doi: 10.1145/ 3474381
work page 2021
-
[33]
Globally optimal policy gradient algorithms for reinforcement learning with pid control policies
Vipul Kumar Sharma, Wesley A Suttle, and S Sivaranjani. Globally optimal policy gradient algorithms for reinforcement learning with pid control policies. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[34]
A simple and effective pruning approach for large language models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. In12th International Conference on Learning Representations, ICLR 2024, 2024. 11
work page 2024
-
[35]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021
work page 2021
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 10, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Qdrop: Randomly dropping quantization for extremely low-bit post-training quantization
Xiuying Wei, Ruihao Gong, Yuhang Li, Xianglong Liu, and Fengwei Yu. Qdrop: Randomly dropping quantization for extremely low-bit post-training quantization.arXiv preprint arXiv:2203.05740, 2022
-
[38]
Adalog: Post-training quantization for vision transformers with adaptive logarithm quantizer
Zhuguanyu Wu, Jiaxin Chen, Hanwen Zhong, Di Huang, and Yunhong Wang. Adalog: Post-training quantization for vision transformers with adaptive logarithm quantizer. InEuropean Conference on Computer Vision, pages 411–427. Springer, 2024
work page 2024
-
[39]
Zhuguanyu Wu, Shihe Wang, Jiayi Zhang, Jiaxin Chen, and Yunhong Wang. Fima-q: Post-training quantization for vision transformers by fisher information matrix approximation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14891–14900, 2025
work page 2025
-
[40]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
work page 2023
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Liang Yang, Runjie Shi, Qiuliang Zhang, Zhen Wang, Xiaochun Cao, Chuan Wang, et al. Self-supervised graph neural networks via low-rank decomposition.Advances in Neural Information Processing Systems, 36:34295–34307, 2023
work page 2023
-
[43]
Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization. InEuropean conference on computer vision, pages 191–207. Springer, 2022
work page 2022
-
[44]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1472
-
[45]
Decoupled knowledge distillation
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11953–11962, 2022
work page 2022
-
[46]
First-order error matters: Accurate compensation for quantized large language models
Xingyu Zheng, Haotong Qin, Yuye Li, Haoran Chu, Jiakai Wang, Jinyang Guo, Michele Magno, and Xianglong Liu. First-order error matters: Accurate compensation for quantized large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28883–28891, 2026
work page 2026
-
[47]
I&s-vit: An inclusive & stable method for pushing the limit of post-training vits quantization
Yunshan Zhong, Jiawei Hu, Mengzhao Chen, Rongrong Ji, et al. I&s-vit: An inclusive & stable method for pushing the limit of post-training vits quantization.arXiv preprint arXiv:2311.10126, 2023
-
[48]
Yunshan Zhong, You Huang, Jiawei Hu, Yuxin Zhang, and Rongrong Ji. Towards accurate post-training quantization of vision transformers via error reduction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2676–2692, 2025. 12 Appendix A Detailed Hessian-Approximation for Residual Reconstruction We provide the detailed Hessian-approximati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.