RL4RLA: Teaching ML to Discover Randomized Linear Algebra Algorithms Through Curriculum Design and Graph-Based Search
Pith reviewed 2026-05-20 12:48 UTC · model grok-4.3
The pith
Reinforcement learning can automatically discover interpretable randomized linear algebra algorithms from basic primitives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RL4RLA automates the discovery of interpretable, symbolic RLA algorithms by training an agent to compose basic linear algebra primitives into complete procedures. A numerical curriculum progressively increments problem difficulty to encode domain-specific inductive bias, and Monte Carlo Graph Search optimizes exploration by identifying and merging equivalent partial algorithms. This combination enables the recovery of state-of-the-art methods such as sketch-and-precondition solvers, Randomized Kaczmarz, and Newton Sketch, along with the generation of algorithms tuned for specific accuracy, speed, and stability requirements.
What carries the argument
Numerical curriculum that progressively increments problem difficulty paired with Monte Carlo Graph Search that merges equivalent partial algorithms to guide reinforcement learning exploration.
If this is right
- Algorithms can be produced that are explicitly symbolic and therefore directly implementable and verifiable.
- The method can generate variants optimized for chosen balances among accuracy, speed, and numerical stability.
- Automation reduces dependence on manual expert design for a growing class of algorithms in large-scale computation.
Where Pith is reading between the lines
- Similar curriculum and graph-search techniques could be applied to discover algorithms in neighboring areas such as numerical optimization or differential equation solvers.
- Integrating the output algorithms into existing software libraries would allow direct measurement of runtime gains on large matrices.
- Scaling the search to higher-dimensional or more constrained problem families might reveal entirely novel algorithm structures.
Load-bearing premise
The numerical curriculum progressively increments problem difficulty to encode inductive bias specific to the RLA domain and that Monte Carlo Graph Search sufficiently optimizes exploration by identifying and merging equivalent partial algorithms.
What would settle it
Training the system on overdetermined linear systems and checking whether it rediscovers the Randomized Kaczmarz method or only inferior alternatives would directly test the central claim.
Figures







read the original abstract
Randomized linear algebra (RLA) algorithms are a modern class of numerical linear algebra techniques that play an essential role in scientific computing and machine learning, with broad and growing adoption. However, their discovery remains mostly a manual process that requires deep expert knowledge and inspiration. While Reinforcement Learning (RL) offers a pathway to automation, standard approaches struggle with sparse reward landscapes and vast search spaces inherent to high-performing RLA algorithms. In this paper, we present RL4RLA, a general RL framework that automates the discovery of interpretable, symbolic RLA algorithms. Unlike black-box approaches, our method builds explicit algorithms from basic linear algebra primitives, ensuring verifiable and implementable representations. To enable efficient discovery, we introduce: (1) a numerical curriculum that progressively increments problem difficulty to encode inductive bias specific to the RLA domain; (2) Monte Carlo Graph Search, which optimizes exploration by identifying and merging equivalent partial algorithms. We demonstrate that RL4RLA rediscovers state-of-the-art methods, including sketch-and-precondition solvers, Randomized Kaczmarz, and Newton Sketch, and can be targeted to produce algorithms optimized for specific trade-offs between accuracy, speed, and stability. Code is available at https://github.com/Tim-Xiong/RL4RLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RL4RLA, a reinforcement learning framework that automates discovery of interpretable symbolic randomized linear algebra (RLA) algorithms from basic linear algebra primitives. It employs a numerical curriculum that progressively increases problem difficulty to inject RLA-specific inductive bias and Monte Carlo Graph Search to optimize exploration via merging of equivalent partial algorithms. The central claims are that this approach rediscovers state-of-the-art methods including sketch-and-precondition solvers, Randomized Kaczmarz, and Newton Sketch, while also enabling targeting for trade-offs among accuracy, speed, and stability.
Significance. If the rediscoveries are independently verified and the framework generalizes beyond the curriculum's guidance, the work could meaningfully advance automated algorithm design in numerical linear algebra by reducing dependence on manual expert insight. The emphasis on symbolic, verifiable representations and the public code release are strengths that support reproducibility and potential adoption in scientific computing and ML pipelines.
major comments (2)
- [Abstract] Abstract: The numerical curriculum is stated to 'progressively increments problem difficulty to encode inductive bias specific to the RLA domain'. This design choice appears load-bearing for the central claim of discovery from basic primitives with minimal domain knowledge. If the curriculum stages (e.g., choices of matrix dimensions, conditioning, or accuracy thresholds) are constructed to mirror iteration patterns of known algorithms such as Kaczmarz or sketch-and-precondition, rediscovery reduces to curriculum verification rather than unbiased search. A concrete clarification or ablation replacing the RLA-specific curriculum with a generic difficulty schedule is needed to substantiate independence.
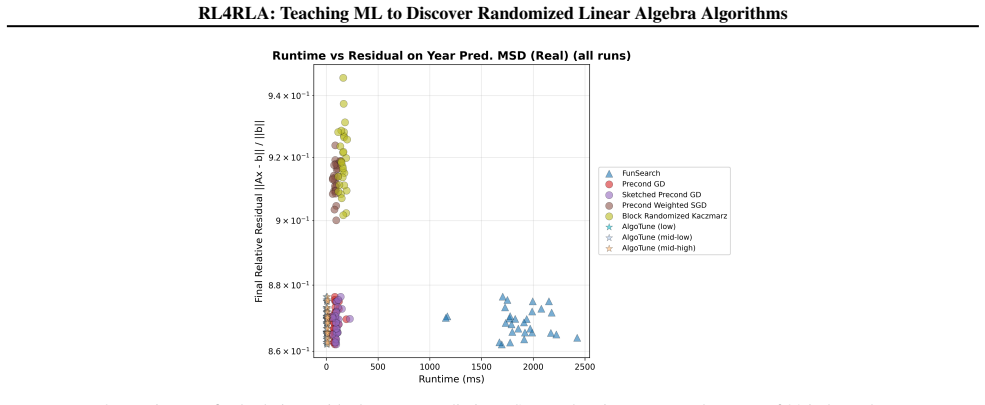
- [Abstract] Abstract: The demonstration that RL4RLA 'rediscovers state-of-the-art methods' requires explicit performance tables or figures comparing the discovered algorithms against published baselines on standard metrics (e.g., iteration counts, residual norms, runtime). Without such verification or ablations showing that Monte Carlo Graph Search plus equivalence merging is responsible for the rediscoveries, the empirical support for the framework's effectiveness remains incomplete.
minor comments (2)
- The abstract mentions 'Code is available at https://github.com/Tim-Xiong/RL4RLA' but does not specify the exact commit or release tag used for the reported experiments; this should be added for reproducibility.
- Notation for the state representation and reward function in the RL formulation should be introduced with explicit definitions early in the methods section to aid readers unfamiliar with the graph-search augmentation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that strengthen the empirical grounding and independence claims of RL4RLA without overstating the current results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The numerical curriculum is stated to 'progressively increments problem difficulty to encode inductive bias specific to the RLA domain'. This design choice appears load-bearing for the central claim of discovery from basic primitives with minimal domain knowledge. If the curriculum stages (e.g., choices of matrix dimensions, conditioning, or accuracy thresholds) are constructed to mirror iteration patterns of known algorithms such as Kaczmarz or sketch-and-precondition, rediscovery reduces to curriculum verification rather than unbiased search. A concrete clarification or ablation replacing the RLA-specific curriculum with a generic difficulty schedule is needed to substantiate independence.
Authors: We agree that the curriculum's design requires explicit justification to support claims of minimal domain knowledge. The stages are defined using general numerical properties (increasing matrix dimensions from 100 to 5000, condition numbers from 1 to 10^6, and target residual thresholds) drawn from standard linear algebra benchmarks rather than direct replication of any specific algorithm's iteration structure. To address the concern directly, the revised manuscript will include a detailed table specifying each curriculum stage's parameters and an ablation replacing the RLA-tuned schedule with a purely size-based generic progression. Results from this ablation will be reported to quantify how much the domain-specific elements accelerate discovery versus enabling it. revision: yes
-
Referee: [Abstract] Abstract: The demonstration that RL4RLA 'rediscovers state-of-the-art methods' requires explicit performance tables or figures comparing the discovered algorithms against published baselines on standard metrics (e.g., iteration counts, residual norms, runtime). Without such verification or ablations showing that Monte Carlo Graph Search plus equivalence merging is responsible for the rediscoveries, the empirical support for the framework's effectiveness remains incomplete.
Authors: We acknowledge that the current description of rediscoveries would benefit from quantitative head-to-head comparisons. The revised version will add tables and figures reporting iteration counts, residual norms, and wall-clock runtime for the discovered symbolic algorithms versus the original published implementations of sketch-and-precondition, Randomized Kaczmarz, and Newton Sketch on the same test matrices. We will also include ablations that disable Monte Carlo Graph Search or equivalence merging while keeping the curriculum fixed, thereby isolating their contribution to reaching the rediscovered solutions within the reported search budgets. revision: yes
Circularity Check
No circularity: RL framework uses explicit curriculum and search without reducing outputs to inputs by construction
full rationale
The paper presents RL4RLA as an empirical RL search method that builds algorithms from basic linear algebra primitives using a numerical curriculum for domain bias and Monte Carlo Graph Search for exploration. Rediscovery of known methods (sketch-and-precondition, Randomized Kaczmarz, Newton Sketch) is framed as validation of the automated process rather than a fitted prediction or self-referential derivation. No equations, self-citations, or uniqueness theorems are invoked that collapse the claimed discovery back to predefined targets by construction. The curriculum explicitly encodes RLA-specific inductive bias as a design choice, not a hidden tautology, and the overall method remains self-contained and externally verifiable via the released code.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RL4RLA framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
numerical curriculum that progressively increments problem difficulty to encode inductive bias specific to the RLA domain
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Monte Carlo Graph Search, which optimizes exploration by identifying and merging equivalent partial algorithms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Discovering faster matrix multiplication algorithms with reinforcement learning , author=. Nature , volume=. 2022 , publisher=
work page 2022
-
[2]
International conference on machine learning , pages=
Automl-zero: Evolving machine learning algorithms from scratch , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[4]
Fine-tuning Large Language Model for Automated Algorithm Design
Fine-tuning large language model for automated algorithm design , author=. arXiv preprint arXiv:2507.10614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2505.18602 , year=
LLM-Meta-SR: Learning to Evolve Selection Operators for Symbolic Regression , author=. arXiv preprint arXiv:2505.18602 , year=
-
[6]
arXiv preprint arXiv:2508.11703 , year=
Data-Driven Discovery of Interpretable Kalman Filter Variants through Large Language Models and Genetic Programming , author=. arXiv preprint arXiv:2508.11703 , year=
-
[7]
arXiv preprint arXiv:2504.05108 , year=
Algorithm discovery with llms: Evolutionary search meets reinforcement learning , author=. arXiv preprint arXiv:2504.05108 , year=
-
[9]
Dreamcoder: Bootstrapping inductive program synthesis with wake-sleep library learning , author=. Proceedings of the 42nd acm sigplan international conference on programming language design and implementation , pages=
-
[10]
Discovering faster matrix multiplication algorithms with reinforcement learning , author=. Nature , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Cola: Exploiting compositional structure for automatic and efficient numerical linear algebra , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Learning formal mathematics from intrinsic motivation , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in neural information processing systems , volume=
Symbolic discovery of optimization algorithms , author=. Advances in neural information processing systems , volume=
-
[14]
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[15]
Faster sorting algorithms discovered using deep reinforcement learning , author=. Nature , volume=. 2023 , publisher=
work page 2023
-
[16]
LLM4Solver: Large Language Model for Efficient Algorithm Design of Combinatorial Optimization Solver , author=
-
[17]
arXiv preprint arXiv:2412.07186 , year=
Monte Carlo Tree Search based Space Transfer for Black-box Optimization , author=. arXiv preprint arXiv:2412.07186 , year=
-
[18]
arXiv preprint arXiv:2405.15383 , year=
Generating code world models with large language models guided by monte carlo tree search , author=. arXiv preprint arXiv:2405.15383 , year=
-
[19]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[20]
Advances in neural information processing systems , volume=
Learning to learn by gradient descent by gradient descent , author=. Advances in neural information processing systems , volume=
-
[21]
International Conference on Machine Learning , pages=
The clrs algorithmic reasoning benchmark , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[22]
2006 47th annual IEEE symposium on foundations of computer science (FOCS'06) , pages=
Improved approximation algorithms for large matrices via random projections , author=. 2006 47th annual IEEE symposium on foundations of computer science (FOCS'06) , pages=. 2006 , organization=
work page 2006
-
[23]
SIAM Journal on Computing , volume=
Fast Monte Carlo algorithms for matrices I: Approximating matrix multiplication , author=. SIAM Journal on Computing , volume=. 2006 , publisher=
work page 2006
-
[24]
Drineas, Petros and Mahoney, Michael W and Cristianini, Nello , journal=. On the Nystr
-
[25]
SIAM Journal on Matrix Analysis and Applications , volume=
Relative-error CUR matrix decompositions , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2008 , publisher=
work page 2008
-
[26]
Journal of the ACM (JACM) , volume=
Low-rank approximation and regression in input sparsity time , author=. Journal of the ACM (JACM) , volume=. 2017 , publisher=
work page 2017
-
[27]
Sketching as a tool for numerical linear algebra , author=. Foundations and Trends. 2014 , publisher=
work page 2014
-
[28]
Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions , author=. SIAM review , volume=. 2011 , publisher=
work page 2011
-
[29]
SIAM Journal on Scientific Computing , volume=
Blendenpik: Supercharging LAPACK's least-squares solver , author=. SIAM Journal on Scientific Computing , volume=. 2010 , publisher=
work page 2010
-
[30]
LSRN: A Parallel Iterative Solver for Strongly Over- or Under-Determined Systems , author=. 2012 , eprint=
work page 2012
-
[31]
SIAM Journal on computing , volume=
The fast Johnson--Lindenstrauss transform and approximate nearest neighbors , author=. SIAM Journal on computing , volume=. 2009 , publisher=
work page 2009
-
[32]
Communications of the ACM , volume=
RandNLA: randomized numerical linear algebra , author=. Communications of the ACM , volume=. 2016 , publisher=
work page 2016
-
[33]
Randomized numerical linear algebra: Foundations and algorithms , author=. Acta Numerica , volume=. 2020 , publisher=
work page 2020
-
[34]
Randomized algorithms for matrices and data , author=. Foundations and Trends. 2011 , publisher=
work page 2011
-
[35]
SIAM Journal on Optimization , volume=
Newton sketch: A near linear-time optimization algorithm with linear-quadratic convergence , author=. SIAM Journal on Optimization , volume=. 2017 , publisher=
work page 2017
-
[36]
Journal of Fourier Analysis and Applications , volume=
A randomized Kaczmarz algorithm with exponential convergence , author=. Journal of Fourier Analysis and Applications , volume=. 2009 , publisher=
work page 2009
-
[37]
Advances in neural information processing systems , volume=
Stochastic gradient descent, weighted sampling, and the randomized Kaczmarz algorithm , author=. Advances in neural information processing systems , volume=
-
[38]
Random Structures & Algorithms , volume=
An elementary proof of a theorem of Johnson and Lindenstrauss , author=. Random Structures & Algorithms , volume=. 2003 , publisher=
work page 2003
-
[39]
Proceedings of the forty-fifth annual ACM symposium on Theory of computing , pages=
Low-distortion subspace embeddings in input-sparsity time and applications to robust linear regression , author=. Proceedings of the forty-fifth annual ACM symposium on Theory of computing , pages=
-
[40]
Numerische mathematik , volume=
Gaussian elimination is not optimal , author=. Numerische mathematik , volume=. 1969 , publisher=
work page 1969
-
[41]
arXiv preprint arXiv:2403.03183 , year=
How Well Can Transformers Emulate In-context Newton's Method? , author=. arXiv preprint arXiv:2403.03183 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Transformers learn to implement preconditioned gradient descent for in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
International Conference on Machine Learning , pages=
Learning preconditioners for conjugate gradient PDE solvers , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[45]
International Conference on Machine Learning , pages=
A deep conjugate direction method for iteratively solving linear systems , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[48]
Advances in Neural Information Processing Systems , volume=
Learning-based low-rank approximations , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Monte-carlo tree search , author=
-
[50]
Asian Conference on Machine Learning , pages=
Monte-carlo graph search: the value of merging similar states , author=. Asian Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
- [51]
-
[52]
Knowledge-Based Systems , volume=
UCD: Upper Confidence bound for rooted Directed acyclic graphs , author=. Knowledge-Based Systems , volume=. 2012 , publisher=
work page 2012
- [53]
-
[54]
Ailon, N. and Chazelle, B. The fast johnson--lindenstrauss transform and approximate nearest neighbors. SIAM Journal on computing, 39 0 (1): 0 302--322, 2009
work page 2009
-
[55]
W., Pfau, D., Schaul, T., Shillingford, B., and De Freitas, N
Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., Shillingford, B., and De Freitas, N. Learning to learn by gradient descent by gradient descent. Advances in neural information processing systems, 29, 2016
work page 2016
-
[56]
Blendenpik: Supercharging lapack's least-squares solver
Avron, H., Maymounkov, P., and Toledo, S. Blendenpik: Supercharging lapack's least-squares solver. SIAM Journal on Scientific Computing, 32 0 (3): 0 1217--1236, 2010
work page 2010
-
[57]
Bertin-Mahieux, T. Year Prediction MSD . UCI Machine Learning Repository, 2011. DOI : https://doi.org/10.24432/C50K61
-
[58]
Chaslot, G. M. J.-B. C. Monte-carlo tree search. 2010
work page 2010
-
[59]
Symbolic discovery of optimization algorithms
Chen, X., Liang, C., Huang, D., Real, E., Wang, K., Pham, H., Dong, X., Luong, T., Hsieh, C.-J., Lu, Y., et al. Symbolic discovery of optimization algorithms. Advances in neural information processing systems, 36: 0 49205--49233, 2023
work page 2023
-
[60]
Clarkson, K. L. and Woodruff, D. P. Low-rank approximation and regression in input sparsity time. Journal of the ACM (JACM), 63 0 (6): 0 1--45, 2017
work page 2017
-
[61]
Drineas, P. and Mahoney, M. W. Randnla: randomized numerical linear algebra. Communications of the ACM, 59 0 (6): 0 80--90, 2016
work page 2016
-
[62]
Drineas, P., Kannan, R., and Mahoney, M. W. Fast monte carlo algorithms for matrices i: Approximating matrix multiplication. SIAM Journal on Computing, 36 0 (1): 0 132--157, 2006
work page 2006
-
[63]
Ellis, K., Wong, C., Nye, M., Sabl \'e -Meyer, M., Morales, L., Hewitt, L., Cary, L., Solar-Lezama, A., and Tenenbaum, J. B. Dreamcoder: Bootstrapping inductive program synthesis with wake-sleep library learning. In Proceedings of the 42nd acm sigplan international conference on programming language design and implementation, pp.\ 835--850, 2021
work page 2021
-
[64]
Fawzi, A., Balog, M., Huang, A., Hubert, T., Romera-Paredes, B., Barekatain, M., Novikov, A., R. Ruiz, F. J., Schrittwieser, J., Swirszcz, G., et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 610 0 (7930): 0 47--53, 2022
work page 2022
-
[65]
Halko, N., Martinsson, P.-G., and Tropp, J. A. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review, 53 0 (2): 0 217--288, 2011
work page 2011
-
[66]
H \"a usner, P., \"O ktem, O., and Sj \"o lund, J. Neural incomplete factorization: learning preconditioners for the conjugate gradient method. arXiv preprint arXiv:2305.16368, 2023
-
[67]
Learning-based low-rank approximations
Indyk, P., Vakilian, A., and Yuan, Y. Learning-based low-rank approximations. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[68]
Pac subset selection in stochastic multi-armed bandits
Kalyanakrishnan, S., Tewari, A., Auer, P., and Stone, P. Pac subset selection in stochastic multi-armed bandits. In ICML, volume 12, pp.\ 655--662, 2012
work page 2012
-
[69]
Kaneda, A., Akar, O., Chen, J., Kala, V. A. T., Hyde, D., and Teran, J. A deep conjugate direction method for iteratively solving linear systems. In International Conference on Machine Learning, pp.\ 15720--15736. PMLR, 2023
work page 2023
-
[70]
Leurent, E. and Maillard, O.-A. Monte-carlo graph search: the value of merging similar states. In Asian Conference on Machine Learning, pp.\ 577--592. PMLR, 2020
work page 2020
- [71]
-
[72]
Li, Y., Chen, P. Y., Du, T., and Matusik, W. Learning preconditioners for conjugate gradient pde solvers. In International Conference on Machine Learning, pp.\ 19425--19439. PMLR, 2023
work page 2023
-
[73]
Mahoney, M. W. Randomized algorithms for matrices and data. Foundations and Trends in Machine Learning , 3 0 (2): 0 123--224, 2011
work page 2011
-
[74]
Mankowitz, D. J., Michi, A., Zhernov, A., Gelmi, M., Selvi, M., Paduraru, C., Leurent, E., Iqbal, S., Lespiau, J.-B., Ahern, A., et al. Faster sorting algorithms discovered using deep reinforcement learning. Nature, 618 0 (7964): 0 257--263, 2023
work page 2023
-
[75]
LSRN: A Parallel Iterative Solver for Strongly Over- or Under-Determined Systems
Meng, X., Saunders, M. A., and Mahoney, M. W. Lsrn: A parallel iterative solver for strongly over- or under-determined systems, 2012. URL https://arxiv.org/abs/1109.5981
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[76]
Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm
Needell, D., Srebro, N., and Ward, R. Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm. Advances in neural information processing systems, 27, 2014
work page 2014
-
[77]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, A., V \ u , N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J., Mehrabian, A., et al. Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Pilanci, M. and Wainwright, M. J. Newton sketch: A near linear-time optimization algorithm with linear-quadratic convergence. SIAM Journal on Optimization, 27 0 (1): 0 205--245, 2017
work page 2017
-
[79]
K., Krupke, D., Kidger, P., Sajed, T., Stellato, B., Park, J., et al
Press, O., Amos, B., Zhao, H., Wu, Y., Ainsworth, S. K., Krupke, D., Kidger, P., Sajed, T., Stellato, B., Park, J., et al. Algotune: Can language models speed up general-purpose numerical programs? arXiv preprint arXiv:2507.15887, 2025
-
[80]
Automl-zero: Evolving machine learning algorithms from scratch
Real, E., Liang, C., So, D., and Le, Q. Automl-zero: Evolving machine learning algorithms from scratch. In International conference on machine learning, pp.\ 8007--8019. PMLR, 2020
work page 2020
-
[81]
Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M. P., Dupont, E., Ruiz, F. J., Ellenberg, J. S., Wang, P., Fawzi, O., et al. Mathematical discoveries from program search with large language models. Nature, 625 0 (7995): 0 468--475, 2024
work page 2024
-
[82]
Ucd: Upper confidence bound for rooted directed acyclic graphs
Saffidine, A., Cazenave, T., and M \'e hat, J. Ucd: Upper confidence bound for rooted directed acyclic graphs. Knowledge-Based Systems, 34: 0 26--33, 2012
work page 2012
-
[83]
Improved approximation algorithms for large matrices via random projections
Sarlos, T. Improved approximation algorithms for large matrices via random projections. In 2006 47th annual IEEE symposium on foundations of computer science (FOCS'06), pp.\ 143--152. IEEE, 2006
work page 2006
-
[84]
Gaussian elimination is not optimal
Strassen, V. Gaussian elimination is not optimal. Numerische mathematik, 13 0 (4): 0 354--356, 1969
work page 1969
-
[85]
Strohmer, T. and Vershynin, R. A randomized kaczmarz algorithm with exponential convergence. Journal of Fourier Analysis and Applications, 15 0 (2): 0 262--278, 2009
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.