MARS: Technical Report for the CASTLE Challenge at EgoVis 2026
Pith reviewed 2026-05-20 11:20 UTC · model grok-4.3
The pith
MARS frames the CASTLE Challenge as an agentic evidence-selection task over multimodal sources and video summaries to answer 185 questions across four days of activity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
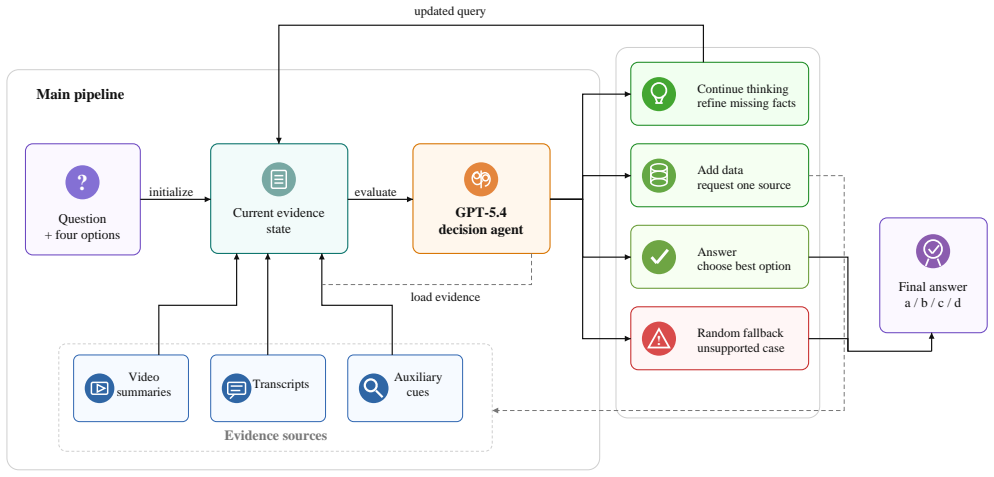
MARS treats the CASTLE task as an agentic evidence-selection problem over multimodal sources rather than a purely text-only pipeline. It builds evidence memories from videos and transcripts converted to captions and summaries plus four auxiliary sources, then uses a GPT-5.4 decision agent at inference time to choose whether to continue reasoning, request a specific missing modality, produce an answer, or fall back to random when evidence remains insufficient.
What carries the argument
The GPT-5.4 decision agent that selects among actions of continuing reasoning, requesting a modality, answering, or random fallback based on evidence memories built from primary and auxiliary sources.
Load-bearing premise
Converting long videos into captions and DeepSeek-based summaries preserves the temporal evidence required to answer the questions without critical loss of detail.
What would settle it
Compare accuracy on time-sensitive questions when using the summary-based memories versus a version that ingests original video segments directly for the same questions.
Figures
read the original abstract
This report presents MARS, short for Multimodal Agentic Reasoning with Source selection, our system for the CASTLE Challenge at EgoVis 2026. Participants must answer 185 closed-form questions over the CASTLE 2024 dataset. In contrast to prior single-video egocentric benchmarks, CASTLE requires reasoning over four days of activity, 15 synchronized perspectives, official transcripts, and multiple auxiliary modalities, including personal photos, auxiliary videos, gaze, thermal imagery, and heartrate measurements. MARS therefore treats the task as an agentic evidence-selection problem over multimodal sources rather than a purely text-only pipeline. MARS first follows the official CASTLE directory organization to build evidence memories from two primary sources, videos and transcripts, and four auxiliary sources, gaze, heartrate, photos, and thermal imagery. Long videos are converted into captions and DeepSeek-based summaries only because CASTLE videos are too long to fit directly into the model context for every question; this step compresses temporal evidence while keeping photos and other auxiliary media available as source-specific evidence. At inference time, a GPT-5.4 decision agent repeatedly chooses whether to continue reasoning, request a specific missing modality, produce an answer, or fall back to a random option when the evidence remains insufficient. The resulting system achieved second place on the final CASTLE Challenge leaderboard. Our codes are available at https://github.com/Hyu-Zhang/MARS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MARS, a multimodal agentic reasoning system for the CASTLE Challenge at EgoVis 2026. It describes constructing evidence memories from four days of synchronized multi-view videos (compressed via captioning and DeepSeek summarization), official transcripts, and auxiliary modalities including gaze, heartrate, photos, and thermal imagery. At inference, a GPT-5.4-based decision agent selects sources, requests missing modalities, or answers 185 closed-form questions, with the system achieving second place on the final leaderboard. Code is released at the provided GitHub link.
Significance. If the reported performance holds under scrutiny, the work illustrates a practical engineering approach to long-horizon multimodal egocentric reasoning by combining source selection with agentic control, which could inform future systems for extended activity understanding. The explicit code release supports reproducibility and is a clear strength for a challenge report.
major comments (2)
- [evidence memory construction (abstract and system description)] The description of evidence memory construction states that long videos are converted to captions and DeepSeek-based summaries because raw footage exceeds context limits, while claiming this step 'compresses temporal evidence' without critical loss. No verification, ablation, or error analysis is supplied to confirm that ordering, duration, or cross-perspective timing required by the 185 questions is retained after summarization. This step is load-bearing for the second-place claim, as the skeptic note correctly identifies.
- [inference-time agent and overall results] The report provides no ablation studies, component-wise error analysis, or quantitative comparisons to baselines or other submissions that would isolate the contribution of the agentic decision process, the choice of auxiliary modalities, or the summarization step. The soundness assessment notes this absence, which limits evaluation of whether the ranking reflects robust design choices.
minor comments (1)
- [inference description] The abstract and system description refer to 'GPT-5.4' without clarifying whether this is a hypothetical or specific model variant; standardizing model nomenclature would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our technical report. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [evidence memory construction (abstract and system description)] The description of evidence memory construction states that long videos are converted to captions and DeepSeek-based summaries because raw footage exceeds context limits, while claiming this step 'compresses temporal evidence' without critical loss. No verification, ablation, or error analysis is supplied to confirm that ordering, duration, or cross-perspective timing required by the 185 questions is retained after summarization. This step is load-bearing for the second-place claim, as the skeptic note correctly identifies.
Authors: We agree that additional verification or error analysis of the summarization step would strengthen the presentation. As this is a concise technical report for a challenge rather than a full research paper, our focus was on documenting the deployed system under tight deadlines. We will revise the manuscript to expand the system description with an explicit discussion of potential limitations in temporal ordering and cross-view timing, along with how the agentic modality-request mechanism is intended to recover critical details when needed. We maintain that direct use of raw video was infeasible due to context constraints. revision: partial
-
Referee: [inference-time agent and overall results] The report provides no ablation studies, component-wise error analysis, or quantitative comparisons to baselines or other submissions that would isolate the contribution of the agentic decision process, the choice of auxiliary modalities, or the summarization step. The soundness assessment notes this absence, which limits evaluation of whether the ranking reflects robust design choices.
Authors: We acknowledge that the lack of ablations and component-wise analysis limits the ability to isolate contributions. Given the challenge setting and associated time and compute constraints, such studies were not feasible during development. We will add a dedicated limitations paragraph to the revised manuscript that discusses the design rationale for the agent and auxiliary modalities, while noting that the released code supports future independent ablations and comparisons by the community. revision: partial
Circularity Check
No circularity; engineering report with empirical leaderboard result
full rationale
The manuscript is a technical report describing an implemented multimodal agentic system for the CASTLE Challenge. It states that long videos are converted to captions and DeepSeek summaries solely because raw footage exceeds context limits, then reports an empirical second-place leaderboard outcome. No derivations, equations, fitted parameters, predictions, or self-citations appear. The performance claim rests on participation in an external benchmark rather than any internal reduction of a result to its own inputs. The summarization step is presented as a pragmatic engineering decision, not a derived or self-referential quantity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Long videos are converted into captions and DeepSeek-based summaries only because CASTLE videos are too long to fit directly into the model context... At inference time, a GPT-5.4 decision agent repeatedly chooses whether to continue reasoning, request a specific missing modality, produce an answer, or fall back to a random option
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The resulting system achieved second place on the final CASTLE Challenge leaderboard
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Qiaohui Chu, Haoyu Zhang, Yisen Feng, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. Technical report for ego4d long-term action anticipation challenge 2025.arXiv preprint arXiv:2506.02550, 2025. 1
-
[2]
Intention-guided cognitive reason- ing for egocentric long-term action anticipation
Qiaohui Chu, Haoyu Zhang, Meng Liu, Yisen Feng, Haoxi- ang Shi, and Liqiang Nie. Intention-guided cognitive reason- ing for egocentric long-term action anticipation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 17436–17444, 2026
work page 2026
-
[3]
Grounded question-answering in long egocentric videos
Shangzhe Di and Weidi Xie. Grounded question-answering in long egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12934–12943, 2024. 1
work page 2024
-
[4]
ObjectNLQ@ Ego4D episodic mem- ory challenge 2024.arXiv preprint arXiv:2406.15778, 2024
Yisen Feng, Haoyu Zhang, Yuquan Xie, Zaijing Li, Meng Liu, and Liqiang Nie. Objectnlq@ ego4d episodic memory challenge 2024.arXiv preprint arXiv:2406.15778, 2024. 1
-
[5]
OSGNet @ Ego4D episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025
Yisen Feng, Haoyu Zhang, Qiaohui Chu, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. Osgnet@ ego4d episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025
-
[6]
Object-shot enhanced grounding network for egocentric video
Yisen Feng, Haoyu Zhang, Meng Liu, Weili Guan, and Liqiang Nie. Object-shot enhanced grounding network for egocentric video. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24190–24200, 2025. 1
work page 2025
-
[7]
Ego-exo4d: Understanding skilled human activity from first- and third-person perspec- tives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, et al. Ego-exo4d: Understanding skilled human activity from first- and third-person perspec- tives. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 19383–19400,
-
[8]
Bi-directional het- erogeneous graph hashing towards efficient outfit recom- mendation
Weili Guan, Xuemeng Song, Haoyu Zhang, Meng Liu, Chung-Hsing Yeh, and Xiaojun Chang. Bi-directional het- erogeneous graph hashing towards efficient outfit recom- mendation. InProceedings of the 30th ACM international conference on multimedia, pages 268–276, 2022. 1
work page 2022
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024. 1
work page 2024
-
[11]
The castle 2024 dataset: Advancing the art of mul- timodal understanding
Luca Rossetto, Werner Bailer, Duc-Tien Dang-Nguyen, Gra- ham Healy, Bj ¨orn J ´onsson, Onanong Kongmeesub, Hoang- Bao Le, Stevan Rudinac, Klaus Sch¨offmann, Florian Spiess, Allie Tran, Minh-Triet Tran, Quang-Linh Tran, and Cathal Gurrin. The castle 2024 dataset: Advancing the art of mul- timodal understanding. InProceedings of the 33rd ACM In- ternational...
work page 2024
-
[12]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, and Gaoang Wang. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 1
work page 2024
-
[13]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understand- ing with large language model as agent.arXiv preprint arXiv:2403.10517, 2024. 1
-
[14]
Retrieval-augmented egocentric video captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. Retrieval-augmented egocentric video captioning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13525–13536, 2024. 1
work page 2024
-
[15]
Multimodal dialog system: Rela- tional graph-based context-aware question understanding
Haoyu Zhang, Meng Liu, Zan Gao, Xiaoqiang Lei, Yinglong Wang, and Liqiang Nie. Multimodal dialog system: Rela- tional graph-based context-aware question understanding. In Proceedings of the 29th ACM international conference on multimedia, pages 695–703, 2021
work page 2021
-
[16]
Haoyu Zhang, Meng Liu, Yuhong Li, Ming Yan, Zan Gao, Xiaojun Chang, and Liqiang Nie. Attribute-guided collab- orative learning for partial person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14144–14160, 2023
work page 2023
-
[17]
Multi-factor adaptive vision selec- tion for egocentric video question answering
Haoyu Zhang, Meng Liu, Zixin Liu, Xuemeng Song, Yaowei Wang, and Liqiang Nie. Multi-factor adaptive vision selec- tion for egocentric video question answering. InProceedings of the 41st International Conference on Machine Learning, pages 59310–59328. PMLR, 2024. 1
work page 2024
-
[18]
Hcqa@ ego4d egoschema challenge 2024.arXiv preprint arXiv:2406.15771, 2024
Haoyu Zhang, Yuquan Xie, Yisen Feng, Zaijing Li, Meng Liu, and Liqiang Nie. Hcqa@ ego4d egoschema challenge 2024.arXiv preprint arXiv:2406.15771, 2024. 1, 2
-
[19]
Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding
Haoyu Zhang, Qiaohui Chu, Meng Liu, Haoxiang Shi, Yaowei Wang, and Liqiang Nie. Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 12502–12510, 2026. 1
work page 2026
-
[20]
Uncovering hidden connections: Iterative search and reasoning for video-grounded dialog
Haoyu Zhang, Meng Liu, Yisen Feng, Yaowei Wang, Weili Guan, and Liqiang Nie. Uncovering hidden connections: Iterative search and reasoning for video-grounded dialog. ACM Trans. Inf. Syst., 44(4), 2026. 1
work page 2026
-
[21]
Spatial understand- ing from videos: Structured prompts meet simulation data
Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understand- ing from videos: Structured prompts meet simulation data. Advances in Neural Information Processing Systems, 38: 103202–103229, 2026. 1
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.