Context Memorization for Efficient Long Context Generation
Pith reviewed 2026-05-20 10:35 UTC · model grok-4.3
The pith
A training-free lookup memory of precomputed attention states lets LLMs retain long prefixes without fading influence or full recomputation at each step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
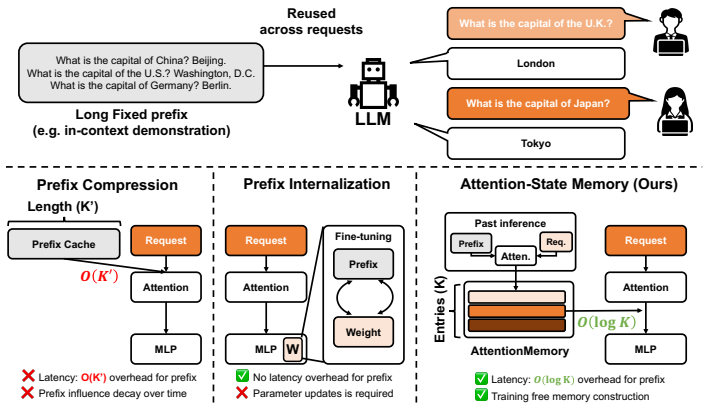
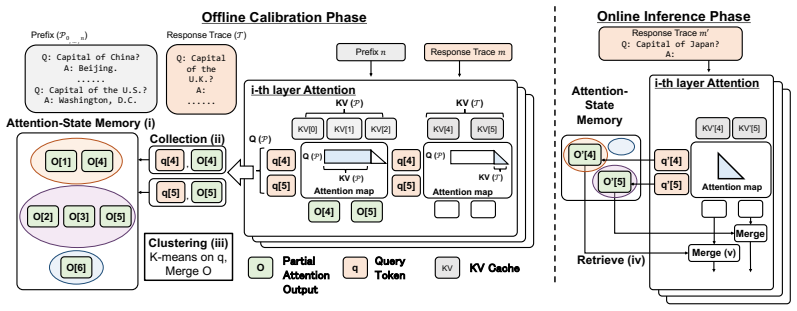
The paper claims that storing precomputed attention states between prefix tokens and query tokens in a lightweight lookup memory can substitute for computing full attention over the entire prefix at every generation step. Because the states are external and fixed, prefix influence remains constant rather than decaying, and computation cost stays independent of prefix length after the initial precomputation.
What carries the argument
attention-state memory: a lookup-based store of precomputed attention states between prefix and query tokens that replaces full attention computation over the prefix.
If this is right
- Accuracy exceeds in-context learning on ManyICLBench for LLaMA-3.1-8B at memory budgets between 1K and 8K tokens.
- Attention computation latency drops by a factor of 1.36 at 8K token budgets.
- Performance on the NBA benchmark exceeds full-attention retrieval-augmented generation while using only 20 percent of the memory.
- Prefix influence stays constant throughout generation because states are held externally rather than recomputed inside the model.
- Prefixes can be added or changed without any gradient-based retraining of the underlying model.
Where Pith is reading between the lines
- The memory could support live updates to system instructions or few-shot examples in deployed chat systems without reloading weights.
- Similar precomputation might reduce costs when prefixes contain structured data such as tables or code repositories.
- The technique could combine with existing context compression methods to reach even longer effective contexts.
- Energy use in data-center inference might fall if attention over repeated prefixes is replaced by lookups.
Load-bearing premise
The stored attention states between prefix and query tokens can replace full attention over the prefix without introducing errors that harm task performance.
What would settle it
A new long-context task where accuracy with the memory method falls below plain in-context learning at a 4K token budget would show the replacement does not hold.
Figures


read the original abstract
Modern large language model (LLM) applications increasingly rely on long conditioning prefixes to control model behavior at inference time. While prefix-augmented inference is effective, it incurs two structural limitations: i) the prefix's influence fades as generation proceeds, and ii) attention computation over the prefix scales linearly with its length. Existing approaches either keep the prefix in attention while compressing it, or internalize it into model parameters through gradient-based training. The former still attends to the prefix at inference, while the latter is training-intensive and ill-suited to prefix updates. To address these issues, we propose attention-state memory, a training-free approach that externalizes the prefix into a lightweight, lookup-based memory of precomputed attention states between prefix and query tokens. On ManyICLBench with LLaMA-3.1-8B, our method improves accuracy over in-context learning at 1K-8K memory budgets while reducing attention latency by 1.36x at 8K, and surpasses full-attention RAG performance on NBA benchmark using only 20% of its memory footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes attention-state memory, a training-free approach that externalizes long conditioning prefixes into a lightweight lookup-based memory of precomputed attention states between prefix and query tokens. It reports accuracy gains over in-context learning on ManyICLBench with LLaMA-3.1-8B at 1K-8K memory budgets, 1.36x attention latency reduction at 8K, and outperformance of full-attention RAG on the NBA benchmark using 20% of the memory footprint.
Significance. If the precomputed states can substitute for full attention without material approximation error, the method offers a practical, training-free route to preserving prefix influence during long generations while cutting linear attention costs, which would be useful for controllable long-context applications.
major comments (2)
- [Abstract] Abstract: The accuracy and latency claims rest on the assumption that the lookup-based memory of precomputed attention states can replace full prefix attention at every generation step without introducing accumulating approximation errors for new query vectors. The manuscript provides no verification (e.g., attention-map or logit equivalence checks) that this substitution preserves the original distribution across varying generation lengths.
- [Method] Method description: No explicit statement is given on whether the stored states are exact KV projections, attention outputs, or further approximations, nor on how retrieval integrates with the evolving key/value cache during autoregressive generation; this detail is load-bearing for confirming that the reported 1.36x latency gain and accuracy improvements are not artifacts of an inexact replacement.
minor comments (1)
- [Abstract] Abstract: The phrase 'surpasses full-attention RAG performance ... using only 20% of its memory footprint' would benefit from a brief parenthetical clarifying whether the 20% figure refers to total memory or only the attention-related component.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and provide additional verification.
read point-by-point responses
-
Referee: [Abstract] Abstract: The accuracy and latency claims rest on the assumption that the lookup-based memory of precomputed attention states can replace full prefix attention at every generation step without introducing accumulating approximation errors for new query vectors. The manuscript provides no verification (e.g., attention-map or logit equivalence checks) that this substitution preserves the original distribution across varying generation lengths.
Authors: We appreciate the referee highlighting the importance of verifying that the substitution introduces no material accumulating errors. Our reported accuracy gains on ManyICLBench and outperformance on the NBA benchmark (with 20% memory) provide indirect evidence that any approximation does not degrade the output distribution in practice. Nevertheless, we agree that direct checks would strengthen the claims. In the revision we will add attention-map visualizations and logit-distribution equivalence tests (e.g., KL divergence) between full prefix attention and attention-state memory at multiple generation lengths. revision: yes
-
Referee: [Method] Method description: No explicit statement is given on whether the stored states are exact KV projections, attention outputs, or further approximations, nor on how retrieval integrates with the evolving key/value cache during autoregressive generation; this detail is load-bearing for confirming that the reported 1.36x latency gain and accuracy improvements are not artifacts of an inexact replacement.
Authors: We agree the method section should be more explicit. The stored states are the exact precomputed attention outputs (attention-weighted value sums between prefix keys and query vectors), not raw KV projections or further approximations. During generation, for each new query we retrieve the matching precomputed state via lookup and substitute it for the prefix-attention computation while continuing to maintain the standard KV cache only for newly generated tokens. We will revise the Method section with a precise description, pseudocode, and an updated figure clarifying this integration to substantiate the latency and accuracy results. revision: yes
Circularity Check
No circularity: empirical engineering method with external benchmark validation
full rationale
The paper proposes attention-state memory as a training-free engineering technique that stores precomputed attention states for prefix-query pairs and uses lookup during generation. No equations, fitted parameters, or first-principles derivations are presented that would reduce reported accuracy or latency gains to the method's own inputs by construction. Claims rest on direct comparisons against in-context learning and full-attention RAG on ManyICLBench and NBA benchmarks, which are independent external evaluations. This satisfies the self-contained criterion against external benchmarks, yielding no load-bearing self-citations or definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention mechanism computes pairwise interactions between prefix and query tokens
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
attention-state memory, a training-free approach that externalizes the prefix into a lightweight, lookup-based memory of precomputed attention states between prefix and query tokens
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By the online-softmax identity [30, 11], this merge process itself is lossless
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930–76966, 2024
work page 2024
-
[2]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
work page 2023
-
[3]
Lessons from building claude code: Prompt caching is everything
Anthropic. Lessons from building claude code: Prompt caching is everything. https://claude.com/blog/ lessons-from-building-claude-code-prompt-caching-is-everything , April
-
[4]
Accessed: 2026-05-07
work page 2026
-
[5]
SIEVE: Sample-Efficient Parametric Learning from Natural Language
Parth Asawa, Alexandros G Dimakis, and Matei Zaharia. Sieve: Sample-efficient parametric learning from natural language.arXiv preprint arXiv:2604.02339, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[7]
Don’t do rag: When cache-augmented generation is all you need for knowledge tasks
Brian J Chan, Chao-Ting Chen, Jui-Hung Cheng, and Hen-Hsen Huang. Don’t do rag: When cache-augmented generation is all you need for knowledge tasks. InCompanion Proceedings of the ACM on Web Conference 2025, pages 893–897, 2025
work page 2025
-
[8]
Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, and Robert Tjarko Lange. Text-to-lora: Instant transformer adaption.arXiv preprint arXiv:2506.06105, 2025
-
[9]
Doc-to-lora: Learning to instantly internalize contexts.arXiv preprint arXiv:2602.15902, 2026
Rujikorn Charakorn, Edoardo Cetin, Shinnosuke Uesaka, and Robert Tjarko Lange. Doc-to-lora: Learning to instantly internalize contexts.arXiv preprint arXiv:2602.15902, 2026
-
[10]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3829–3846, 2023
work page 2023
-
[11]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[13]
In-context autoencoder for context compression in a large language model
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model.arXiv preprint arXiv:2307.06945, 2023
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Squeezed attention: Accelerating long context length llm inference
Coleman Richard Charles Hooper, Sehoon Kim, Hiva Mohammadzadeh, Monishwaran Mah- eswaran, Sebastian Zhao, June Paik, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. Squeezed attention: Accelerating long context length llm inference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages...
work page 2025
-
[16]
Whiteningbert: An easy unsupervised sentence embedding approach
Junjie Huang, Duyu Tang, Wanjun Zhong, Shuai Lu, Linjun Shou, Ming Gong, Daxin Jiang, and Nan Duan. Whiteningbert: An easy unsupervised sentence embedding approach. InFindings of the association for computational linguistics: EMNLP 2021, pages 238–244, 2021
work page 2021
-
[17]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence, 33(1):117–128, 2010. 10
work page 2010
-
[18]
Llmlingua: Compress- ing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compress- ing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023
work page 2023
-
[19]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shufan Liu, Xuanzhe Liu, and Xin Jin. Ragcache: Efficient knowledge caching for retrieval-augmented generation.ACM Transactions on Computer Systems, 44(1):1–27, 2025
work page 2025
-
[20]
Billion-scale similarity search with gpus.IEEE transactions on big data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus.IEEE transactions on big data, 7(3):535–547, 2019
work page 2019
-
[21]
Lee, Sangdoo Yun, and Hyun Oh Song
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W Lee, Sangdoo Yun, and Hyun Oh Song. Kvzip: Query-agnostic kv cache compression with context reconstruction.arXiv preprint arXiv:2505.23416, 2025
-
[22]
Efficient knowledge injection in llms via self-distillation.arXiv preprint arXiv:2412.14964, 2024
Kalle Kujanpää, Pekka Marttinen, Harri Valpola, and Alexander Ilin. Efficient knowledge injection in llms via self-distillation.arXiv preprint arXiv:2412.14964, 2024
-
[23]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[24]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[25]
Kenneth Li, Tianle Liu, Naomi Bashkansky, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Measuring and controlling instruction (in) stability in language model dialogs.arXiv preprint arXiv:2402.10962, 2024
-
[26]
Compressing context to enhance inference efficiency of large language models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing context to enhance inference efficiency of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353, 2023
work page 2023
-
[27]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
work page 2024
-
[28]
Aqpim: Break- ing the pim capacity wall for llms with in-memory activation quantization
Kosuke Matsushima, Yasuyuki Okoshi, Masato Motomura, and Daichi Fujiki. Aqpim: Break- ing the pim capacity wall for llms with in-memory activation quantization. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1–17, 2026
work page 2026
-
[29]
Learning to compress prompts with gist tokens
Jesse Mu, Xiang Li, and Noah Goodman. Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36:19327–19352, 2023
work page 2023
-
[30]
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. InFindings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024
work page 2024
-
[31]
Markus N Rabe and Charles Staats. Self-attention does not need o(n2) memory.arXiv preprint arXiv:2112.05682, 2021
-
[32]
Parallel context windows for large language models
Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. Parallel context windows for large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 6383–6402, 2023
work page 2023
-
[33]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023. 11
work page 2023
-
[34]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024
work page 2024
-
[35]
Generative prompt internalization
Haebin Shin, Lei Ji, Yeyun Gong, Sungdong Kim, Eunbi Choi, and Minjoon Seo. Generative prompt internalization. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 7338–7363, 2025
work page 2025
-
[36]
Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
-
[37]
CSAttention: Centroid-Scoring Attention for Accelerating LLM Inference
Chuxu Song, Zhencan Peng, Jiuqi Wei, and Chuanhui Yang. Csattention: Centroid-scoring attention for accelerating llm inference.arXiv preprint arXiv:2604.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. Whitening sentence representations for better semantics and faster retrieval.arXiv preprint arXiv:2103.15316, 2021
-
[39]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019
work page 2019
-
[40]
Efficient llm context distillation.arXiv preprint arXiv:2409.01930, 2024
Rajesh Upadhayaya, Manish Raj Osti, Zachary Smith, and Chritopher Kottmyer. Efficient llm context distillation.arXiv preprint arXiv:2409.01930, 2024
-
[41]
Xinyu Yang, Tianqi Chen, and Beidi Chen. Ape: Faster and longer context-augmented genera- tion via adaptive parallel encoding.arXiv preprint arXiv:2502.05431, 2025
-
[42]
Mac-attention: a match-amend-complete scheme for fast and accurate attention computation
Jinghan Yao, Sam Adé Jacobs, Walid Krichene, Masahiro Tanaka, and Dhabaleswar K Panda. Mac-attention: a match-amend-complete scheme for fast and accurate attention computation. arXiv preprint arXiv:2604.00235, 2026
-
[43]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Xinliang Frederick Zhang and Lu Wang. Tsubasa: Improving long-horizon personalization via evolving memory and self-learning with context distillation.arXiv preprint arXiv:2604.07894, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[46]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024
work page 2024
-
[47]
Rulearena: A benchmark for rule-guided reasoning with llms in real-world scenarios
Ruiwen Zhou, Wenyue Hua, Liangming Pan, Sitao Cheng, Xiaobao Wu, En Yu, and William Yang Wang. Rulearena: A benchmark for rule-guided reasoning with llms in real-world scenarios. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 550–572, 2025
work page 2025
-
[48]
On many-shot in-context learning for long- context evaluation
Kaijian Zou, Muhammad Khalifa, and Lu Wang. On many-shot in-context learning for long- context evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (V olume 1: Long Papers), pages 25605–25639, 2025. 12 Table 4: Lookup key configuration and centroid grouping strategy for LLaMA 3.1-8B. Lookup key configurat...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.