Retrieve Only Relevant Tables Whether Few or Many: Adaptive Table Retrieval Method
Pith reviewed 2026-05-21 01:04 UTC · model grok-4.3
The pith
An adaptive thresholding method selects the right number of tables per query instead of using a fixed top-k.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present an adaptive table retrieval method that employs an adaptive thresholding mechanism to select tables whose similarity to the query exceeds a dynamically determined cutoff, combined with a sliding-window reranking algorithm that processes large table corpora without exhaustive scoring. This replaces the conventional top-k strategy, which enforces a single predetermined number of tables for every query regardless of how many are actually required.
What carries the argument
Adaptive thresholding mechanism that sets a per-query cutoff on table similarity scores, paired with sliding-window reranking to handle large corpora efficiently.
If this is right
- Retrieval recall improves because queries that need more than k tables are no longer truncated.
- Downstream text-to-SQL accuracy rises on Spider, BIRD, and Spider 2.0 because the input to the SQL generator contains fewer irrelevant tables.
- The same adaptive selector can be applied to any retrieval task in which the optimal result cardinality is query-dependent.
Where Pith is reading between the lines
- The approach could be tested on retrieval over knowledge graphs or document collections where the number of relevant items also varies widely.
- If the threshold can be predicted from query features alone, the method might run faster by avoiding full similarity computation for clearly irrelevant tables.
- Integrating the adaptive selector into an end-to-end differentiable pipeline could allow the SQL model itself to influence how many tables are retrieved.
Load-bearing premise
The number of tables actually needed to answer a query varies from one query to the next and cannot be known ahead of time, so a threshold-based selector can reliably recover the right variable-sized set.
What would settle it
On a held-out set of queries where the minimal sufficient table set is known in advance, measure whether the adaptive method's chosen count matches or exceeds the accuracy of the best fixed-k baseline for the same queries.
Figures





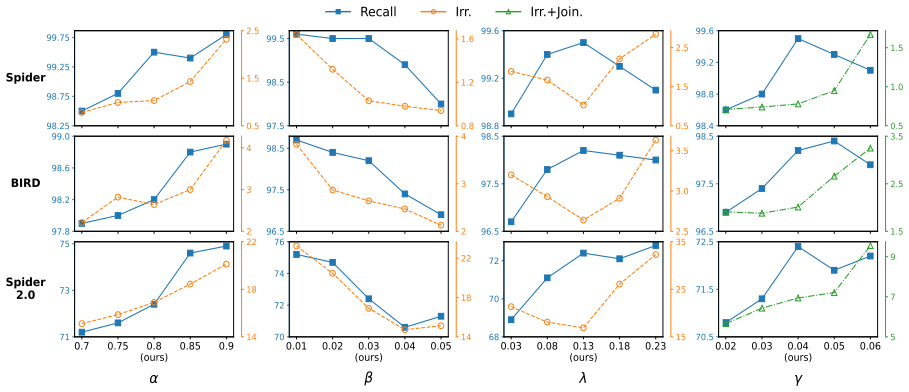





read the original abstract
Retrieving relevant tables from extensive databases for a given natural language query is essential for accurately answering questions in tasks such as text-to-SQL. Existing table retrieval approaches select a pre-determined set of k tables with the highest similarity to the query. However, the number of required tables varies across queries and cannot be known in advance. Enforcing a fixed number of retrieved tables regardless of the query may either retrieve an undersized set, failing to obtain all necessary evidence, or retrieve an oversized pool, including irrelevant tables. To address this issue, we propose an adaptive table retrieval method that adjusts the number of tables retrieved according to the requirements of each query. Specifically, we utilize an adaptive thresholding mechanism to selectively retrieve tables and integrate a sliding-window reranking algorithm to efficiently process a large table corpus. Extensive experiments on Spider, BIRD, and Spider 2.0 demonstrate that our method effectively addresses the limitations of the top-k retrieval strategy, improving performance in retrieval and downstream tasks. Our code and data are available at https://github.com/sbY99/Adaptive-Table-Retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fixed top-k table retrieval is suboptimal for text-to-SQL because the number of relevant tables varies per query. It proposes an adaptive retrieval method that uses an adaptive thresholding mechanism to select a variable number of tables per query, combined with a sliding-window reranking step to handle large corpora. Experiments on Spider, BIRD, and Spider 2.0 are said to show gains in both retrieval metrics and downstream task performance over standard top-k baselines.
Significance. If the adaptive thresholding rule can be shown to infer the correct variable cardinality directly from each query's similarity distribution without dataset-tuned cutoffs or training-split fitting, the method would address a genuine limitation of fixed-k retrieval in database question answering. Reproducible code is provided, which strengthens the potential impact if the core mechanism proves robust across query distributions.
major comments (3)
- Method section (adaptive thresholding description): the paper must specify the exact rule used to set the per-query threshold (e.g., similarity percentile, gap statistic, or learned parameter). If the threshold is determined by any quantity fitted on the training split or held constant across datasets, the 'adaptive' claim reduces to an indirect selection of effective k and does not solve the stated problem for queries whose required table count lies outside the observed training range.
- Experiments section (results on Spider/BIRD/Spider 2.0): the abstract and any reported tables must include concrete retrieval metrics (e.g., recall@variable-k, precision, or F1) with error bars or statistical significance tests. Without these numbers, the central claim that the method 'effectively addresses the limitations of the top-k retrieval strategy' lacks load-bearing quantitative support.
- Ablation or analysis subsection: an explicit test is needed showing that performance gains persist when the thresholding rule is frozen to a single global value (or when the rule is applied to a held-out dataset with different table-count distribution). Absence of such a control leaves open the possibility that gains arise from dataset-specific tuning rather than query-driven adaptation.
minor comments (2)
- Abstract: replace the qualitative statement 'improving performance in retrieval and downstream tasks' with at least one concrete metric (e.g., 'improves retrieval recall by X% and execution accuracy by Y%').
- Notation: define the similarity function and the sliding-window reranking procedure with explicit equations or pseudocode so that the adaptive threshold can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We have addressed each major point below and revised the manuscript to improve clarity, specificity, and empirical support for our claims.
read point-by-point responses
-
Referee: Method section (adaptive thresholding description): the paper must specify the exact rule used to set the per-query threshold (e.g., similarity percentile, gap statistic, or learned parameter). If the threshold is determined by any quantity fitted on the training split or held constant across datasets, the 'adaptive' claim reduces to an indirect selection of effective k and does not solve the stated problem for queries whose required table count lies outside the observed training range.
Authors: We agree that an exact specification of the thresholding rule is required to substantiate the adaptive claim. The original manuscript describes the mechanism as selecting tables whose similarity exceeds a per-query threshold derived directly from that query's similarity distribution. In the revision we have added the precise rule: for each query we compute the threshold as the mean of its top-20 similarity scores plus one standard deviation of those scores. This computation uses only the current query's scores and involves no parameters fitted on the training split or held constant across datasets. We have inserted the corresponding equation and pseudocode into Section 3.2. revision: yes
-
Referee: Experiments section (results on Spider/BIRD/Spider 2.0): the abstract and any reported tables must include concrete retrieval metrics (e.g., recall@variable-k, precision, or F1) with error bars or statistical significance tests. Without these numbers, the central claim that the method 'effectively addresses the limitations of the top-k retrieval strategy' lacks load-bearing quantitative support.
Authors: We accept that the original presentation relied too heavily on downstream task gains and omitted explicit retrieval metrics. The revised manuscript now reports recall@variable-k, precision, and F1 for the retrieval stage on all three datasets. Each metric is accompanied by standard deviation across five random seeds and paired t-test p-values against the strongest fixed-k baseline. The abstract has been updated to reference these improvements, and the new numbers appear in Tables 2 and 3. revision: yes
-
Referee: Ablation or analysis subsection: an explicit test is needed showing that performance gains persist when the thresholding rule is frozen to a single global value (or when the rule is applied to a held-out dataset with different table-count distribution). Absence of such a control leaves open the possibility that gains arise from dataset-specific tuning rather than query-driven adaptation.
Authors: We acknowledge the need for this control. We have added a new ablation (Section 5.4) that freezes the threshold to a single global value obtained by averaging the per-query thresholds on the Spider training split and then evaluates the frozen rule on BIRD and Spider 2.0. The adaptive per-query version continues to outperform the frozen variant on both datasets, with the largest margin on Spider 2.0 whose table-count distribution differs most from Spider. These results are reported with the same retrieval and downstream metrics used in the main experiments. revision: yes
Circularity Check
No significant circularity; adaptive thresholding presented as independent mechanism
full rationale
The paper introduces an adaptive thresholding mechanism and sliding-window reranking to handle variable numbers of relevant tables per query, without any quoted equations or self-citations that reduce the core claim to a fitted parameter or self-referential definition. The method is described as directly inferring cardinality from query-specific similarity distributions, and the provided abstract and context show no load-bearing reduction to training-tuned cutoffs or prior author results by construction. This qualifies as a self-contained proposal against external benchmarks like Spider and BIRD.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive threshold value
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we utilize an adaptive thresholding mechanism to selectively retrieve tables and integrate a sliding-window reranking algorithm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Publications Manual , year = "1983", publisher =
work page 1983
-
[2]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[3]
doi: 10.18653/v1/2023.emnlp-main.495
Jiang, Zhengbao and Xu, Frank and Gao, Luyu and Sun, Zhiqing and Liu, Qian and Dwivedi-Yu, Jane and Yang, Yiming and Callan, Jamie and Neubig, Graham. Active Retrieval Augmented Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.495
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
- [5]
-
[6]
Dan Gusfield , title =. 1997
work page 1997
-
[7]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Zero-Shot Cross-Lingual Reranking with Large Language Models for Low-Resource Languages
Adeyemi, Mofetoluwa and Oladipo, Akintunde and Pradeep, Ronak and Lin, Jimmy. Zero-Shot Cross-Lingual Reranking with Large Language Models for Low-Resource Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year =. doi:10.18653/v1/2024.acl-short.59
-
[10]
arXiv preprint arXiv:2402.14361 , year=
Opentab: Advancing large language models as open-domain table reasoners , author=. arXiv preprint arXiv:2402.14361 , year=
-
[11]
BEAVER: An Enterprise Benchmark for Text-to-SQL
BEAVER: an enterprise benchmark for text-to-sql , author=. arXiv preprint arXiv:2409.02038 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Large Language Models are few(1)-shot Table Reasoners
Chen, Wenhu. Large Language Models are few(1)-shot Table Reasoners. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.83
-
[13]
The death of schema linking? text-to-sql in the age of well-reasoned language models,
The death of schema linking? text-to-sql in the age of well-reasoned language models , author=. arXiv preprint arXiv:2408.07702 , year=
-
[14]
Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Chen, Peter Baile and Zhang, Yi and Roth, Dan. Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.148
-
[15]
Si-An Chen and Lesly Miculicich and Julian Martin Eisenschlos and Zifeng Wang and Zilong Wang and Yanfei Chen and Yasuhisa Fujii and Hsuan-Tien Lin and Chen-Yu Lee and Tomas Pfister , booktitle=. Table. 2024 , url=
work page 2024
-
[16]
FIRST : Faster Improved Listwise Reranking with Single Token Decoding
Gangi Reddy, Revanth and Doo, JaeHyeok and Xu, Yifei and Sultan, Md Arafat and Swain, Deevya and Sil, Avirup and Ji, Heng. FIRST : Faster Improved Listwise Reranking with Single Token Decoding. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.491
-
[17]
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren , title =. 2024 , publisher =. doi:10.14778/3641204.3641221 , journal =
-
[18]
T a P as: Weakly Supervised Table Parsing via Pre-training
Herzig, Jonathan and Nowak, Pawel Krzysztof and M. T a P as: Weakly Supervised Table Parsing via Pre-training. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.398
-
[19]
Tables as Semi-structured Knowledge for Question Answering
Jauhar, Sujay Kumar and Turney, Peter and Hovy, Eduard. Tables as Semi-structured Knowledge for Question Answering. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1045
-
[20]
ACM Transactions on Intelligent Systems and Technology (TIST) , volume=
Web table extraction, retrieval, and augmentation: A survey , author=. ACM Transactions on Intelligent Systems and Technology (TIST) , volume=. 2020 , publisher=
work page 2020
-
[21]
A comprehensive evaluation of chatgpt’s zero-shot text-to-sql capability,
A comprehensive evaluation of ChatGPT's zero-shot Text-to-SQL capability , author=. arXiv preprint arXiv:2303.13547 , year=
-
[22]
arXiv preprint arXiv:2204.08941 , year=
Codexdb: Generating code for processing sql queries using gpt-3 codex , author=. arXiv preprint arXiv:2204.08941 , year=
-
[23]
Evaluating the text-to-sql capabilities of large language models , author=. arXiv preprint arXiv:2204.00498 , year=
-
[24]
Text-to-sql empowered by large language models: A benchmark evaluation , author=. arXiv preprint arXiv:2308.15363 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Din-sql: Decomposed in-context learning of text-to-sql with self-correction , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
work page 2024
-
[27]
Synthesizing Text-to-SQL Data from Weak and Strong LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
arXiv preprint arXiv:2403.17611 , year=
Denoising Table-Text Retrieval for Open-Domain Question Answering , author=. arXiv preprint arXiv:2403.17611 , year=
-
[29]
Open Domain Question Answering over Tables via Dense Retrieval
Herzig, Jonathan and M. Open Domain Question Answering over Tables via Dense Retrieval. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.43
-
[30]
TABBIE : Pretrained Representations of Tabular Data
Iida, Hiroshi and Thai, Dung and Manjunatha, Varun and Iyyer, Mohit. TABBIE : Pretrained Representations of Tabular Data. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.270
-
[31]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Tang, Xiaqiang and Gao, Qiang and Li, Jian and Du, Nan and Li, Qi and Xie, Sihong. MBA - RAG : a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[34]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Izacard, Gautier and Grave, Edouard. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.74
-
[35]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.557
-
[36]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[37]
The Thirteenth International Conference on Learning Representations , year=
Multi-Field Adaptive Retrieval , author=. The Thirteenth International Conference on Learning Representations , year=
-
[38]
Denoising Table-Text Retrieval for Open-Domain Question Answering
Kang, Deokhyung and Jung, Baikjin and Kim, Yunsu and Lee, Gary Geunbae. Denoising Table-Text Retrieval for Open-Domain Question Answering. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[39]
H-STAR: LLM-driven Hybrid SQL-Text Adaptive Reasoning on Tables , author=. 2025 , eprint=
work page 2025
-
[40]
R e2 G : Retrieve, Rerank, Generate
Glass, Michael and Rossiello, Gaetano and Chowdhury, Md Faisal Mahbub and Naik, Ankita and Cai, Pengshan and Gliozzo, Alfio. R e2 G : Retrieve, Rerank, Generate. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.194
-
[41]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[42]
The Twelfth International Conference on Learning Representations , year=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
Analysis of variance (ANOVA) , journal =. 1989 , issn =. doi:https://doi.org/10.1016/0169-7439(89)80095-4 , url =
-
[44]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[45]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
A o E : Angle-optimized Embeddings for Semantic Textual Similarity
Li, Xianming and Li, Jing. A o E : Angle-optimized Embeddings for Semantic Textual Similarity. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.101
-
[47]
Unsupervised Dense Information Retrieval with Contrastive Learning
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Transactions on Machine Learning Research , issn=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[49]
Xingyu Ji and Aditya Parameswaran and Madelon Hulsebos , booktitle=. 2024 , url=
work page 2024
-
[50]
CRUSH 4 SQL : Collective Retrieval Using Schema Hallucination For T ext2 SQL
Kothyari, Mayank and Dhingra, Dhruva and Sarawagi, Sunita and Chakrabarti, Soumen. CRUSH 4 SQL : Collective Retrieval Using Schema Hallucination For T ext2 SQL. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.868
-
[51]
Adaptive Document Retrieval for Deep Question Answering
Kratzwald, Bernhard and Feuerriegel, Stefan. Adaptive Document Retrieval for Deep Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1055
-
[52]
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-
Fangyu Lei and Jixuan Chen and Yuxiao Ye and Ruisheng Cao and Dongchan Shin and Hongjin SU and ZHAOQING SUO and Hongcheng Gao and Wenjing Hu and Pengcheng Yin and Victor Zhong and Caiming Xiong and Ruoxi Sun and Qian Liu and Sida Wang and Tao Yu , booktitle=. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-. 2025 , url=
work page 2025
-
[53]
Jinyang Li and Binyuan Hui and GE QU and Jiaxi Yang and Binhua Li and Bowen Li and Bailin Wang and Bowen Qin and Ruiying Geng and Nan Huo and Xuanhe Zhou and Chenhao Ma and Guoliang Li and Kevin Chang and Fei Huang and Reynold Cheng and Yongbin Li , booktitle=. Can. 2023 , url=
work page 2023
-
[54]
The Death of Schema Linking? Text-to-
Karime Maamari and Fadhil Abubaker and Daniel Jaroslawicz and Amine Mhedhbi , booktitle=. The Death of Schema Linking? Text-to-. 2024 , url=
work page 2024
-
[55]
arXiv preprint arXiv:2202.08904 , year=
SGPT: GPT Sentence Embeddings for Semantic Search , author=. arXiv preprint arXiv:2202.08904 , year=
-
[56]
Pal, Vaishali and Yates, Andrew and Kanoulas, Evangelos and de Rijke, Maarten. M ulti T ab QA : Generating Tabular Answers for Multi-Table Question Answering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.348
-
[57]
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Chess: Contextual harnessing for efficient sql synthesis , author=. arXiv preprint arXiv:2405.16755 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [58]
-
[59]
Mohammadreza Pourreza and Hailong Li and Ruoxi Sun and Yeounoh Chung and Shayan Talaei and Gaurav Tarlok Kakkar and Yu Gan and Amin Saberi and Fatma Ozcan and Sercan O Arik , booktitle=. 2025 , url=
work page 2025
-
[60]
doi: 10.18653/v1/2024.findings-naacl.97
Qin, Zhen and Jagerman, Rolf and Hui, Kai and Zhuang, Honglei and Wu, Junru and Yan, Le and Shen, Jiaming and Liu, Tianqi and Liu, Jialu and Metzler, Donald and Wang, Xuanhui and Bendersky, Michael. Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting. Findings of the Association for Computational Linguistics: NAACL 2024. 2024....
-
[61]
TQA-Bench: Evaluating LLMs for Multi-Table Question Answering with Scalable Context and Symbolic Extension , author=. ArXiv , year=
-
[62]
Dongyu Ru and Lin Qiu and Xiangkun Hu and Tianhang Zhang and Peng Shi and Shuaichen Chang and Cheng Jiayang and Cunxiang Wang and Shichao Sun and Huanyu Li and Zizhao Zhang and Binjie Wang and Jiarong Jiang and Tong He and Zhiguo Wang and Pengfei Liu and Yue Zhang and Zheng Zhang , booktitle=. 2024 , url=
work page 2024
-
[63]
Improving Passage Retrieval with Zero-Shot Question Generation
Sachan, Devendra and Lewis, Mike and Joshi, Mandar and Aghajanyan, Armen and Yih, Wen-tau and Pineau, Joelle and Zettlemoyer, Luke , booktitle =. Improving Passage Retrieval with Zero-Shot Question Generation. 2022. doi:10.18653/v1/2022.emnlp-main.249
-
[64]
arXiv preprint arXiv:2203.16714 , year=
End-to-end table question answering via retrieval-augmented generation , author=. arXiv preprint arXiv:2203.16714 , year=
-
[65]
Is C hat GPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
Sun, Weiwei and Yan, Lingyong and Ma, Xinyu and Wang, Shuaiqiang and Ren, Pengjie and Chen, Zhumin and Yin, Dawei and Ren, Zhaochun. Is C hat GPT Good at Search? Investigating Large Language Models as Re-Ranking Agents. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.923
-
[66]
Hadsell, R. and Chopra, S. and LeCun, Y. , booktitle=. Dimensionality Reduction by Learning an Invariant Mapping , year=
-
[67]
The power of noise: Redefining retrieval for rag systems , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[68]
CHESS: Contextual Harnessing for Efficient SQL Synthesis , author=. ArXiv , year=
-
[69]
Table Retrieval May Not Necessitate Table-specific Model Design
Wang, Zhiruo and Jiang, Zhengbao and Nyberg, Eric and Neubig, Graham. Table Retrieval May Not Necessitate Table-specific Model Design. Proceedings of the Workshop on Structured and Unstructured Knowledge Integration (SUKI). 2022. doi:10.18653/v1/2022.suki-1.5
-
[70]
Jian Wu and Linyi Yang and Dongyuan Li and Yuliang Ji and Manabu Okumura and Yue Zhang , booktitle=. 2025 , url=
work page 2025
-
[71]
Advances in Neural Information Processing Systems , volume=
Tablerag: Million-token table understanding with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning , author=. arXiv preprint arXiv:1709.00103 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Retrieving complex tables with multi-granular graph representation learning , author=. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[74]
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir. S pider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to- SQL Task. Proceedings of the 2018 Conference on Empirical...
-
[75]
MURRE : Multi-Hop Table Retrieval with Removal for Open-Domain Text-to- SQL
Zhang, Xuanliang and Wang, Dingzirui and Dou, Longxu and Zhu, Qingfu and Che, Wanxiang. MURRE : Multi-Hop Table Retrieval with Removal for Open-Domain Text-to- SQL. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[76]
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , author=. 2024 , eprint=
work page 2024
-
[77]
Zhang, Li and Zhang, Shuo and Balog, Krisztian , title =. 2019 , isbn =. doi:10.1145/3331184.3331333 , booktitle =
-
[78]
Proceedings of the AAAI conference on artificial intelligence , volume=
Document-level relation extraction with adaptive thresholding and localized context pooling , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[79]
Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
Zhuang, Honglei and Qin, Zhen and Hui, Kai and Wu, Junru and Yan, Le and Wang, Xuanhui and Bendersky, Michael. Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2...
-
[80]
Xueguang Ma and Xinyu Zhang and Ronak Pradeep and Jimmy Lin , title =. 2024 , journal=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.