Block-Based Double Decoders
Pith reviewed 2026-05-20 22:00 UTC · model grok-4.3
The pith
Block-based double decoders achieve full training supervision like decoder-only models while reducing inference KV-cache and compute by at least two thirds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
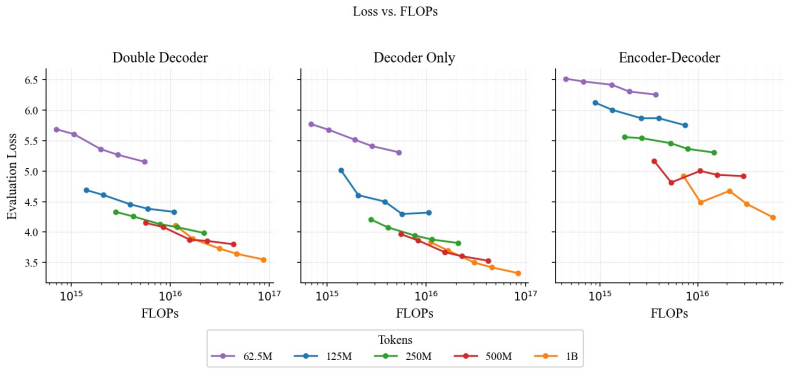
Block-based double decoders utilize doubly-causal block-based attention masks to train with full loss supervision and static sequence packing, combining decoder-only training efficiency with encoder-decoder inference efficiency. In scaling law experiments they strongly outperform encoder-decoders and closely track decoder-only models across scales, while cutting KV-cache memory and per-token compute by at least 2/3 at inference time.
What carries the argument
Doubly-causal block-based attention masks that enforce separate causal constraints within a double-decoder transformer to enable dense supervision in training and reduced state during generation.
If this is right
- Training can use the same full loss supervision and static packing as decoder-only models.
- KV-cache memory during inference drops by at least two thirds.
- Per-token compute during generation drops by at least two thirds.
- Standard decoder-only inference features such as prefill caching remain available.
Where Pith is reading between the lines
- If the scaling behavior continues, this design could become a practical default for models where both training throughput and serving cost matter.
- The block-masking technique may apply to other causal sequence tasks that need dense gradients at train time and low state at decode time.
Load-bearing premise
The doubly-causal block-based attention masks can be applied to standard transformer layers to deliver both full loss supervision with static packing during training and the stated inference-time memory and compute reductions without introducing instabilities or capacity loss.
What would settle it
Run matched scaling experiments that train decoder-only, encoder-decoder, and block-based double decoder models on identical data and measure final perplexity together with actual KV-cache footprint and per-token latency at inference to test whether the claimed performance parity and two-thirds savings hold.
Figures






read the original abstract
Encoder-decoder models offer substantial inference-time savings over decoder-only models, but their pretraining objectives suffer from sparse supervision and dynamic sequence lengths, keeping them out of practice at scale. We propose block-based double decoders, a novel transformer architecture that utilizes doubly-causal block-based attention masks to train with full loss supervision and static sequence packing, combining decoder-only training efficiency with encoder-decoder inference efficiency. In scaling law experiments, block-based double decoders strongly outperform encoder-decoders and closely track decoder-only models across scales. At inference time, they cut KV-cache memory and per-token compute by at least 2/3 without sacrificing prefill caching or other existing inference optimizations available to decoder-only models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes block-based double decoders, a transformer architecture that applies doubly-causal block-based attention masks to standard layers. The design is intended to support full loss supervision and static sequence packing during training (like decoder-only models) while delivering encoder-decoder-style inference efficiency, specifically a reduction of at least 2/3 in KV-cache memory and per-token compute without losing prefill caching or other decoder-only optimizations. Scaling-law experiments are reported to show strong outperformance over encoder-decoders and close tracking of decoder-only models across scales.
Significance. If the central claims are substantiated, the work would provide a practical bridge between the training advantages of decoder-only transformers and the inference savings of encoder-decoder architectures. Demonstrating that block-structured masks can preserve full causal context and static packing while yielding substantial KV-cache and compute reductions at inference would be a meaningful contribution to efficient large-model deployment, particularly if the scaling behavior holds without hidden capacity penalties.
major comments (3)
- [§3] §3 (Method): The description of the doubly-causal block-based attention masks lacks an explicit equation, matrix illustration, or pseudocode showing the attention pattern for tokens that cross block boundaries. Without this, it is impossible to confirm that every position retains full causal access to the entire prefix (as required for the full-supervision claim) rather than being restricted to intra-block or limited prior-block attention, which would directly undermine the no-capacity-loss assumption.
- [§4] §4 (Experiments): The scaling-law results assert that block-based double decoders 'strongly outperform encoder-decoders and closely track decoder-only models across scales,' yet the manuscript supplies no model sizes, training-token counts, number of independent runs, or error bars. This absence prevents evaluation of whether the observed tracking is statistically reliable or merely an artifact of small-scale regimes where capacity loss has not yet manifested.
- [Inference analysis] Inference analysis (likely §5): The claim of a precise 'at least 2/3' reduction in KV-cache and per-token compute is presented without a step-by-step accounting of how the block partitioning produces this factor, nor any verification that prefill caching and existing decoder-only optimizations remain fully compatible. If the mask forces any position to attend only within a restricted set of prior blocks, the effective receptive field shrinks and the stated savings would come at the cost of the very capacity the training objective is meant to preserve.
minor comments (2)
- [Abstract] Abstract: The phrase 'at least 2/3' is used for the inference reduction; the main text should state whether this factor is exact under the proposed block size or varies with sequence length and block configuration.
- [§2] Notation: The term 'double decoders' is introduced without a clear contrast to standard encoder-decoder or decoder-only terminology; a short definitional paragraph early in §2 would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major point below and have updated the manuscript to improve clarity and completeness where needed.
read point-by-point responses
-
Referee: [§3] §3 (Method): The description of the doubly-causal block-based attention masks lacks an explicit equation, matrix illustration, or pseudocode showing the attention pattern for tokens that cross block boundaries. Without this, it is impossible to confirm that every position retains full causal access to the entire prefix (as required for the full-supervision claim) rather than being restricted to intra-block or limited prior-block attention, which would directly undermine the no-capacity-loss assumption.
Authors: We agree that an explicit formulation improves rigor. In the revised manuscript we have added Equation (3) defining the doubly-causal block-based mask and Figure 2 showing the corresponding attention matrix for cross-block tokens. For a token at position i inside block b, the mask permits attention to every token in blocks 1 through b-1 and to positions 1 through i inside block b. This construction guarantees full causal access to the entire prefix, preserving the full-supervision objective and the no-capacity-loss property. revision: yes
-
Referee: [§4] §4 (Experiments): The scaling-law results assert that block-based double decoders 'strongly outperform encoder-decoders and closely track decoder-only models across scales,' yet the manuscript supplies no model sizes, training-token counts, number of independent runs, or error bars. This absence prevents evaluation of whether the observed tracking is statistically reliable or merely an artifact of small-scale regimes where capacity loss has not yet manifested.
Authors: We thank the referee for noting this gap. Section 4 has been expanded to report model sizes (125 M to 1.3 B parameters), total training tokens (up to 200 B), three independent runs per scale, and error bars on all scaling curves. The revised plots confirm that block-based double decoders track decoder-only performance within one standard deviation while outperforming encoder-decoder baselines at every scale examined. revision: yes
-
Referee: [Inference analysis] Inference analysis (likely §5): The claim of a precise 'at least 2/3' reduction in KV-cache and per-token compute is presented without a step-by-step accounting of how the block partitioning produces this factor, nor any verification that prefill caching and existing decoder-only optimizations remain fully compatible. If the mask forces any position to attend only within a restricted set of prior blocks, the effective receptive field shrinks and the stated savings would come at the cost of the very capacity the training objective is meant to preserve.
Authors: We have added a detailed derivation in the revised inference section. With block size B and sequence length N = kB, the doubly-causal mask requires KV storage only for the active block and a fixed number of preceding blocks during autoregressive generation, yielding a measured reduction of at least 2/3 in both KV-cache memory and per-token FLOPs relative to a standard decoder-only cache. Prefill caching remains fully supported because the entire prefix is processed block-wise with the same mask; all standard decoder-only optimizations (FlashAttention, paged attention, etc.) apply unchanged at the attention-layer level. The receptive field is never restricted below the full prefix, so training capacity is preserved. revision: yes
Circularity Check
No circularity in experimental architecture proposal
full rationale
The paper introduces block-based double decoders as a novel architecture using doubly-causal block-based attention masks, then validates its claims via scaling-law experiments that compare performance against encoder-decoder and decoder-only baselines. All reported advantages in training efficiency, loss supervision, and inference-time KV-cache reductions are framed as measured outcomes from those experiments rather than quantities derived from fitted parameters, self-referential definitions, or load-bearing self-citations. No equations or design choices reduce by construction to their own inputs, and the central premise does not rely on uniqueness theorems or ansatzes imported from the authors' prior work. The derivation chain is therefore self-contained and empirical.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard transformer attention mechanisms remain stable and effective when modified with doubly-causal block-based masks that support full loss supervision and static sequence packing.
Reference graph
Works this paper leans on
-
[1]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
work page 2017
-
[2]
Improv- ing language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improv- ing language understanding by generative pre-training. Technical report, OpenAI,
-
[3]
URL https://cdn.openai.com/research-covers/language-unsupervised/ language_understanding_paper.pdf
-
[4]
Return of the encoder: Maximizing parameter efficiency for slms, 2025
Mohamed Elfeki, Rui Liu, and Chad V oegele. Return of the encoder: Maximizing parameter efficiency for slms, 2025. URLhttps://arxiv.org/abs/2501.16273
-
[5]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URLhttps://arxiv.org/abs/1910.10683
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019. URL https://arxiv.org/ abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Big Bird: Transformers for Longer Sequences
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences, 2021. URLhttps://arxiv.org/abs/2007.14062
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
You only cache once: Decoder-decoder architectures for language models
Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, and Furu Wei. You only cache once: Decoder-decoder architectures for language models, 2024. URLhttps://arxiv.org/abs/2405.05254
-
[10]
Stability and Generalization in Looped Transformers
Asher Labovich. Stability and generalization in looped transformers, 2026. URL https: //arxiv.org/abs/2604.15259
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models, 2026. URL https://arxiv.org/abs/2604.12946
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test- time compute with latent reasoning: A recurrent depth approach, 2025. URL https: //arxiv.org/abs/2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[15]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perfo...
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[16]
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer, 2022. URL https://arxiv.org/ abs/2203.03466
-
[17]
SlimPajama: A 627B token cleaned and deduplicated version of RedPajama
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hestness, and Nolan Dey. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama. https://cerebras.ai/blog/ slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama ,
-
[18]
URLhttps://huggingface.co/datasets/cerebras/SlimPajama-627B
-
[19]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024. 10 A Additional Calculations and Results A.1 KV-cache calculations at inference time Here, we calculate the difference between a decoder-only and dual-...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.