Dual-Prompt CLIP with Hybrid Visual Encoders for Occluded Person Re-Identification
Pith reviewed 2026-05-20 06:32 UTC · model grok-4.3
The pith
Dual prompts in CLIP capture full pedestrian semantics despite occlusions for better re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their DPL-ReID model, featuring a Dual Prompt Learning strategy for capturing complete pedestrian semantics via textual cues and robustness to occlusion, a Real-World Occlusion Augmentation method to simulate realistic occlusions, and a Weighted Gated Feature Fusion using LSNet for guiding the CLIP visual encoder, achieves state-of-the-art performance on occluded person re-identification benchmarks.
What carries the argument
The Dual Prompt Learning (Dual-PL) strategy combined with Real-World Occlusion Augmentation (RWOA) and Weighted Gated Feature Fusion (WGFF) mechanism.
If this is right
- Improved robustness in matching partially visible pedestrians across camera views.
- More comprehensive feature representations generated by the CLIP visual encoder.
- Enhanced training through enrichment of occluded samples with realistic simulations.
- State-of-the-art results on benchmark occluded ReID datasets.
Where Pith is reading between the lines
- Similar dual-prompt techniques could be explored for other partial information tasks in computer vision, such as recognizing objects under heavy clutter.
- Extending the occlusion library with more diverse real-world examples might increase the model's applicability to varied environments like urban streets or indoor spaces.
- The approach opens possibilities for integrating additional modalities, like depth information, to further mitigate occlusion effects.
Load-bearing premise
That the proposed Real-World Occlusion Augmentation realistically simulates the occlusion scenarios found in the real world.
What would settle it
If experiments on occluded ReID datasets using occlusions not covered by the provided occlusion instance library show that DPL-ReID does not outperform existing methods, this would challenge the effectiveness of the augmentation and overall approach.
Figures









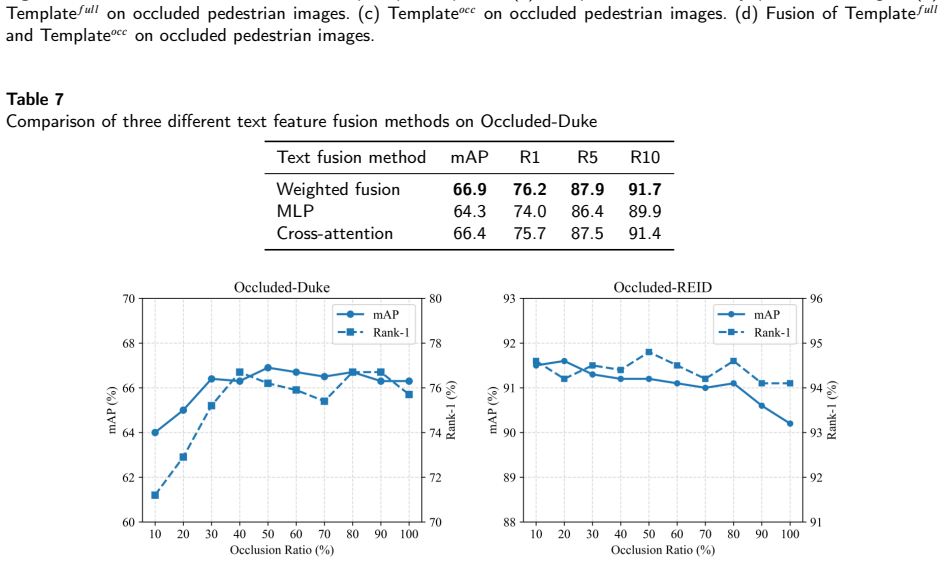



read the original abstract
Occluded person re-identification focuses on matching partially visible pedestrians across multiple camera views. However, occlusions disrupt body-region cues, thereby complicating cross-view matching. Most person ReID methods built on pretrained vision-language models only focus on enhancing prompt-based feature learning while ignoring the semantic information of occluders. Based on the success of CLIP-ReID, we propose a novel Dual Prompt Learning ReID (DPL-ReID) model for occluded person ReID. It incorporates a Dual Prompt Learning (Dual-PL) strategy, which can utilize textual cues to capture complete pedestrian semantics and keep robustness against occlusion, and a Real-World Occlusion Augmentation (RWOA) method that realistically simulates occlusion scenarios encountered in real word to enrich occluded samples. In addition, we also design a Weighted Gated Feature Fusion (WGFF) method, which in corporates LSNet to capture global information and act as a feature-gating mechanism. This mechanism can effectively guide the CLIP visual encoder toward generating more comprehensive feature representations. Extensive experiments on several benchmark occluded ReID datasets show that our proposed DPL-ReID achieves the state-of-the art performance. The occlusion instance library are available at https://github.com/stone-qiao/DPL-ReID.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DPL-ReID, a CLIP-based model for occluded person re-identification. It introduces Dual Prompt Learning (Dual-PL) to leverage textual cues for complete pedestrian semantics robust to occlusion, Real-World Occlusion Augmentation (RWOA) to simulate and enrich occluded training samples from an instance library, and Weighted Gated Feature Fusion (WGFF) that uses LSNet to capture global information and gate features for more comprehensive CLIP visual encoder representations. The paper reports state-of-the-art results on several occluded ReID benchmarks and releases the occlusion library.
Significance. If the central performance claims hold after addressing validation gaps, the work would advance occluded ReID by combining vision-language prompting with targeted augmentation and hybrid encoding. The provision of the occlusion instance library and the focus on semantic handling of occluders represent concrete contributions that could support reproducibility and further research in robust cross-view matching.
major comments (2)
- [§3.2] §3.2 (RWOA description): The assertion that RWOA 'realistically simulates occlusion scenarios encountered in real world' is load-bearing for the SOTA claim, yet no quantitative validation is supplied (e.g., histograms of occlusion area ratios, spatial location heatmaps, or frequency of occlusion types) against the target benchmarks such as Occluded-Duke or Occluded-ReID. Without such comparison, performance gains may reflect dataset-specific fitting rather than improved generalization.
- [Experiments] Experiments section (tables reporting Rank-1/mAP): The abstract and method claims assert SOTA, but the manuscript must include explicit baseline comparisons, ablation studies isolating Dual-PL, RWOA, and WGFF, and error analysis on failure cases to substantiate the central performance result.
minor comments (2)
- [Abstract] Abstract: 'in corporates' should be 'incorporates'; 'real word' should be 'real world'; 'The occlusion instance library are available' should be 'is available'.
- [§3.3] Notation: Define the weighting function and gating operation in WGFF explicitly (e.g., the precise form of the LSNet output used as gate) to avoid ambiguity in the feature fusion equation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing honest responses and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (RWOA description): The assertion that RWOA 'realistically simulates occlusion scenarios encountered in real world' is load-bearing for the SOTA claim, yet no quantitative validation is supplied (e.g., histograms of occlusion area ratios, spatial location heatmaps, or frequency of occlusion types) against the target benchmarks such as Occluded-Duke or Occluded-ReID. Without such comparison, performance gains may reflect dataset-specific fitting rather than improved generalization.
Authors: We acknowledge the referee's point that quantitative validation would provide stronger support for the realism claim of RWOA. The method constructs occlusions using an instance library drawn from real-world images, but we agree that direct distributional comparisons to the benchmarks are valuable. In the revised manuscript, we will add a new analysis subsection under §3.2 (or as supplementary material) that includes histograms of occlusion area ratios, spatial location heatmaps, and frequency counts of occlusion types (e.g., upper-body, lower-body, side occlusions), directly comparing RWOA-augmented samples against the statistics of Occluded-Duke and Occluded-ReID. This will help demonstrate that performance improvements stem from better alignment with real occlusion distributions rather than overfitting. revision: yes
-
Referee: [Experiments] Experiments section (tables reporting Rank-1/mAP): The abstract and method claims assert SOTA, but the manuscript must include explicit baseline comparisons, ablation studies isolating Dual-PL, RWOA, and WGFF, and error analysis on failure cases to substantiate the central performance result.
Authors: The current experiments section already reports comparisons against multiple state-of-the-art occluded ReID methods (including recent CLIP-based approaches) and includes ablation studies on the proposed components. To more rigorously address the referee's request, we will revise the experiments section to (1) expand the baseline table with additional recent methods for clearer SOTA positioning, (2) present more granular ablation tables that isolate the incremental contribution of Dual-PL, RWOA, and WGFF (including combinations and individual removals), and (3) add a dedicated error analysis subsection that categorizes and discusses representative failure cases across the benchmarks, along with qualitative visualizations. These changes will be incorporated in the revised version. revision: yes
Circularity Check
No circularity: empirical method with independent components and external benchmarks
full rationale
The paper presents DPL-ReID as a composite of three explicitly introduced modules (Dual-PL, RWOA, WGFF) built on top of a pretrained CLIP backbone and evaluated on standard occluded ReID benchmarks. No equations, parameter-fitting steps, or derivation chains appear in the provided text that would reduce a claimed result to its own inputs by construction. The sole citation to prior CLIP-ReID work is used only to motivate the starting point, not to justify a uniqueness theorem or load-bearing assumption. Performance claims rest on reported experimental outcomes rather than any self-referential prediction or renaming of known patterns. This is the normal, non-circular case for an applied CV architecture paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained CLIP visual and text encoders supply transferable features suitable for occluded ReID when augmented with prompts and gating
Reference graph
Works this paper leans on
-
[1]
Improved Regularization of Convolutional Neural Networks with Cutout
Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552 . Dosovitskiy, A.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 . Fu,D.,Chen,D.,Bao,J.,Yang,H.,Yuan,L.,Zhang,L.,Li,H.,Chen,D.,2021.Unsupervisedpre-trainingforpersonre-identification,in:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14750–14759. Gao, S., Wang, J., Lu, H., Liu, Z.,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Pose-guided visible part matching for occluded person reid, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11744–11752. Han,S.,Liu,D.,Zhang,Z.,Ming,D.,2023. Spatialcomplementaryandself-repairlearningforoccludedpersonre-identification. Neurocomputing 546, 126360. He, K., Gkioxari, G., Dollár, P., Girshick, R.,
work page 2023
-
[4]
Mask r-cnn, in: Proceedings of the IEEE international conference on computer vision, pp. 2961–2969. He,K.,Zhang,X.,Ren,S.,Sun,J.,2016. Deepresiduallearningforimagerecognition,in:ProceedingsoftheIEEEconferenceoncomputervision and pattern recognition, pp. 770–778. He, S., Chen, W., Wang, K., Luo, H., Wang, F., Jiang, W., Ding, H.,
work page 2016
-
[5]
IEEE transactions on information forensics and security 19, 120–132
Region generation and assessment network for occluded person re- identification. IEEE transactions on information forensics and security 19, 120–132. He,S.,Luo,H.,Wang,P.,Wang,F.,Li,H.,Jiang,W.,2021. Transreid:Transformer-basedobjectre-identification,in:ProceedingsoftheIEEE/CVF international conference on computer vision, pp. 15013–15022. Huang, K., Azfar...
work page 2021
-
[6]
arXiv preprint arXiv:2509.03032
Background matters too: A language-enhanced adversarial framework for person re-identification. arXiv preprint arXiv:2509.03032 . Huang, X., Belongie, S.J.,
-
[7]
Arbitrary style transfer in real-time with adaptive instance normalization. 2017 IEEE International Conference on Computer Vision (ICCV) , 1510–1519URL:https://api.semanticscholar.org/CorpusID:6576859. Ji,Z.,Cheng,D.,Feng,K.,2025. Exploringstrongertransformerrepresentationlearningforoccludedpersonre-identification. MultimediaSystems 31,
work page 2017
-
[8]
Jia,M.,Cheng,X.,Zhai,Y.,Lu,S.,Ma,S.,Tian,Y.,Zhang,J.,2021
URL:https://doi.org/10.1007/s00530-025-01986-0, doi:10.1007/s00530-025-01986-0. Jia,M.,Cheng,X.,Zhai,Y.,Lu,S.,Ma,S.,Tian,Y.,Zhang,J.,2021. Matchingonsets:Conqueroccludedpersonre-identificationwithoutalignment, in: Proceedings of the AAAI conference on artificial intelligence, pp. 1673–1681. Kumar Singh, K., Jae Lee, Y.,
-
[9]
Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization, in: Proceedings of the IEEE international conference on computer vision, pp. 3524–3533. Li,S.,Sun,L.,Li,Q.,2023. Clip-reid:exploitingvision-languagemodelforimagere-identificationwithoutconcretetextlabels,in:Proceedingsof the AAAI conference on artificia...
work page 2023
-
[10]
Microsoft coco: Common objects in context, in: European conference on computer vision, Springer. pp. 740–755. Liu,Z.,Lin,Y.,Cao,Y.,Hu,H.,Wei,Y.,Zhang,Z.,Lin,S.,Guo,B.,2021. Swintransformer:Hierarchicalvisiontransformerusingshiftedwindows, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022. Miao, J., Wu, Y., Liu, P...
work page 2021
-
[11]
Pose-guided feature alignment for occluded person re-identification, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 542–551. Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G.,Askell,A.,Mishkin,P.,Clark,J.,etal.,2021.Learningtransferable visual models from natural language supervision, in: International ...
work page 2021
-
[12]
International journal of computer vision 115, 211–252
Imagenet large scale visual recognition challenge. International journal of computer vision 115, 211–252. Selvaraju,R.R.,Cogswell,M.,Das,A.,Vedantam,R.,Parikh,D.,Batra,D.,2017. Grad-cam:Visualexplanationsfromdeepnetworksviagradient- based localization, in: Proceedings of the IEEE international conference on computer vision, pp. 618–626. Song, Y., Liu, S.,
work page 2017
-
[13]
arXiv preprint arXiv:2401.07469
A deep hierarchical feature sparse framework for occluded person re-identification. arXiv preprint arXiv:2401.07469 . :Preprint submitted to Elsevier Page 16 of 17 Sun, H., Chen, Z., Yan, S., Xu, L., 2019a. Mvp matching: A maximum-value perfect matching for mining hard samples, with application to person re-identification.2019IEEE/CVFInternationalConferen...
-
[14]
Aanet: Attribute attention network for person re-identifications. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 7127–7136URL:https://api.semanticscholar.org/CorpusID:195823196. Wang,A.,Chen,H.,Lin,Z.,Han,J.,Ding,G.,2025a. Lsnet:Seelarge,focussmall,in:ProceedingsoftheComputerVisionandPatternRecognition Conference, pp. 9718–97...
work page 2019
-
[15]
IEEE Transactions on Multimedia 26, 8529–8542
Feature completion transformer for occluded person re-identification. IEEE Transactions on Multimedia 26, 8529–8542. Wang, Z., Zhu, F., Tang, S., Zhao, R., He, L., Song, J., 2022b. Feature erasing and diffusion network for occluded person re-identification, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4754–476...
work page 2022
-
[16]
arXiv preprint arXiv:2110.09408
Hrformer: High-resolution transformer for dense prediction. arXiv preprint arXiv:2110.09408 . Yun,S.,Han,D.,Oh,S.J.,Chun,S.,Choe,J.,Yoo,Y.,2019. Cutmix:Regularizationstrategytotrainstrongclassifierswithlocalizablefeatures,in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 6023–6032. Zhang, Z., Han, S., Liu, D., Ming, D.,
-
[17]
Zheng, K., Lan, C., Zeng, W., Liu, J., Zhang, Z., Zha, Z.J.,
URL:https://doi.org/10.1016/j.neucom.2024.127442, doi:10.1016/j.neucom.2024.127442. Zheng, K., Lan, C., Zeng, W., Liu, J., Zhang, Z., Zha, Z.J.,
-
[18]
Person Re-identification Meets Image Search
Person re-identification meets image search. arXiv preprint arXiv:1502.02171 . Zheng, Z., Zheng, L., Yang, Y.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2508.04998
Attribute guidance with inherent pseudo-label for occluded person re-identification. arXiv preprint arXiv:2508.04998 . Zhong, Z., Zheng, L., Kang, G., Li, S., Yang, Y.,
-
[20]
Occluded person re-identification, in: 2018 IEEE international conference on multimedia and expo (ICME), IEEE. pp. 1–6. :Preprint submitted to Elsevier Page 17 of 17
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.