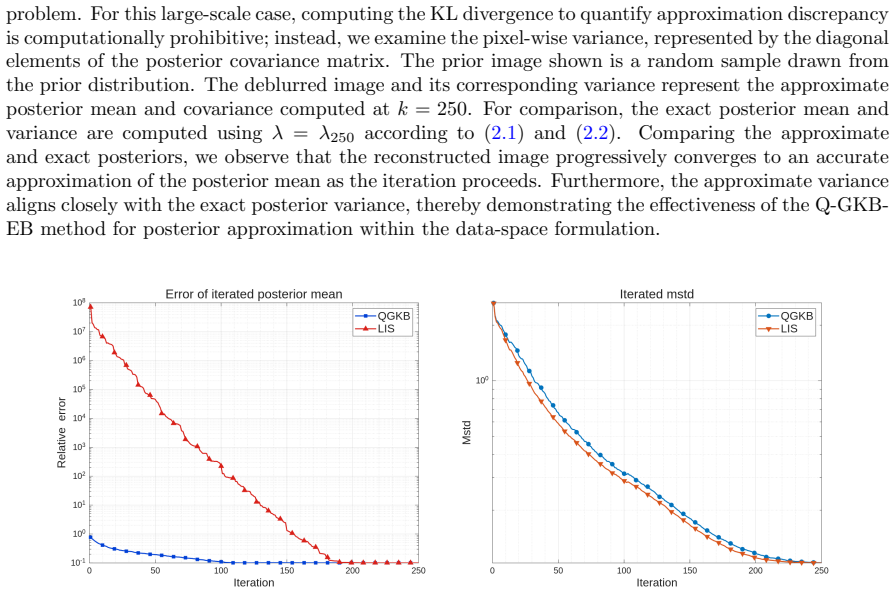
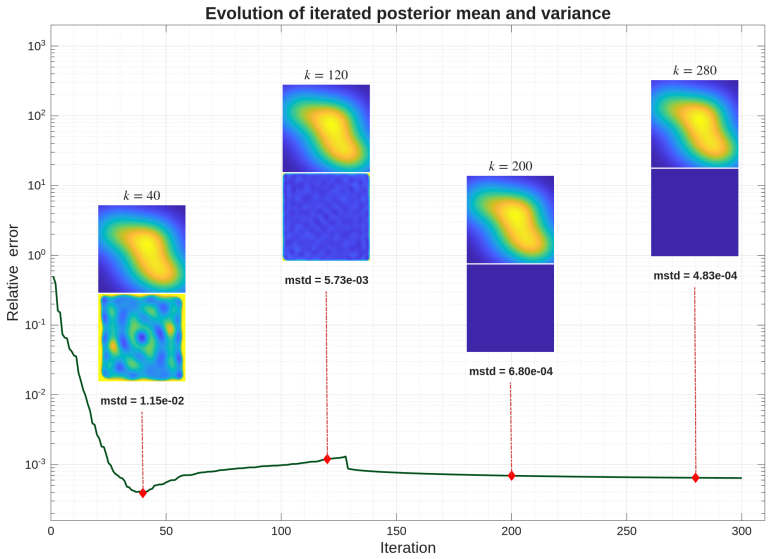
Data-informed posterior approximation for Bayesian linear inverse problems
Pith reviewed 2026-05-21 02:49 UTC · model grok-4.3
The pith
In Bayesian linear inverse problems the prior-to-posterior update is confined to an isometric embedding of a low-dimensional data space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We rigorously characterize an intrinsically low-dimensional data space, establish its isometric embedding into the parameter space, and show that the prior-to-posterior update is confined to a data-informed subspace. This perspective allows posterior inference to be carried out in a reduced data-informed subspace. Based on this formulation, we propose a quotient-space Golub-Kahan bidiagonalization method to construct data-informed Krylov subspaces, and integrate empirical Bayesian inference into the iterative framework, enabling simultaneous hyperparameter estimation and posterior approximation in a matrix-free manner.
What carries the argument
isometric embedding of the intrinsically low-dimensional data space into the parameter space that confines the prior-to-posterior update
Load-bearing premise
The data-informed subspace remains low-dimensional and the isometric embedding preserves the essential posterior information without significant truncation error.
What would settle it
A concrete numerical experiment in which the posterior mean or covariance obtained from the reduced data-informed subspace differs substantially from a reference posterior computed in the full parameter space would falsify the central claim.
Figures












read the original abstract
Computing posterior distributions in large-scale Bayesian linear inverse problems is challenging due to the high dimensionality of the parameter space. In this work, we develop a data-informed framework that shifts the computational focus from the parameter space to the data space. We rigorously characterize an intrinsically low-dimensional data space, establish its isometric embedding into the parameter space, and show that the prior-to-posterior update is confined to a data-informed subspace. This perspective allows posterior inference to be carried out in a reduced data-informed subspace. Based on this formulation, we propose a quotient-space Golub--Kahan bidiagonalization method to construct data-informed Krylov subspaces, and integrate empirical Bayesian inference into the iterative framework, enabling simultaneous hyperparameter estimation and posterior approximation in a matrix-free manner. Numerical experiments on representative problems support the theoretical framework and demonstrate the effectiveness of the resulting method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a data-informed framework for posterior approximation in large-scale Bayesian linear inverse problems. It rigorously characterizes an intrinsically low-dimensional data space, establishes its isometric embedding into the parameter space, and shows that the prior-to-posterior update is confined to this data-informed subspace. Based on this, the authors propose a quotient-space Golub-Kahan bidiagonalization method to build data-informed Krylov subspaces and integrate empirical Bayesian inference for simultaneous hyperparameter estimation and matrix-free posterior approximation. Numerical experiments on representative problems are included to support the claims.
Significance. If the theoretical characterization and isometric embedding hold under the paper's assumptions, the work offers a promising shift from high-dimensional parameter space to lower-dimensional data space for Bayesian inverse problems, potentially improving scalability in applications such as imaging or parameter estimation. The matrix-free iterative approach combined with empirical Bayes is a practical strength, and the numerical results indicate effectiveness. Explicit error bounds or operator conditions would further strengthen the significance.
major comments (2)
- [Theoretical framework] Theoretical framework section: The central claim that the data-informed subspace remains intrinsically low-dimensional and that the isometric embedding preserves essential posterior information without significant truncation error lacks explicit bounds, singular-value decay assumptions on the forward map, or discretization conditions. This is load-bearing for the applicability to the target class of inverse problems, as the abstract and framework rely on it for the reduced-space inference.
- [Quotient-space Golub-Kahan bidiagonalization] Section on the quotient-space Golub-Kahan bidiagonalization: The construction of data-informed Krylov subspaces via the quotient-space method requires clarification on how the isometry is maintained during iteration and whether truncation in the bidiagonalization introduces errors that propagate to the posterior approximation; this directly affects the matrix-free claim.
minor comments (2)
- [Abstract] Abstract: The description of numerical experiments could briefly note the specific inverse problems considered (e.g., dimensions or forward operators) to better contextualize the support for the theoretical framework.
- [Notation and definitions] Notation: Ensure consistent use of symbols for the data-informed subspace and embedding operator across sections to avoid potential confusion in the reduced-space formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical framework] Theoretical framework section: The central claim that the data-informed subspace remains intrinsically low-dimensional and that the isometric embedding preserves essential posterior information without significant truncation error lacks explicit bounds, singular-value decay assumptions on the forward map, or discretization conditions. This is load-bearing for the applicability to the target class of inverse problems, as the abstract and framework rely on it for the reduced-space inference.
Authors: We agree that the manuscript would benefit from more explicit quantitative statements. The current theoretical framework characterizes the data-informed subspace as the range of the adjoint of the forward operator composed with the prior covariance and establishes the isometric embedding via the inner-product structure induced by the prior. However, we acknowledge that explicit a priori error bounds in terms of singular-value decay and discretization error estimates are not stated. In the revised manuscript we will add a new subsection containing such bounds under standard assumptions on the decay of the singular values of the discretized forward map and on the mesh size. This will make the load-bearing claims fully quantitative while preserving the matrix-free character of the method. revision: yes
-
Referee: [Quotient-space Golub-Kahan bidiagonalization] Section on the quotient-space Golub-Kahan bidiagonalization: The construction of data-informed Krylov subspaces via the quotient-space method requires clarification on how the isometry is maintained during iteration and whether truncation in the bidiagonalization introduces errors that propagate to the posterior approximation; this directly affects the matrix-free claim.
Authors: We appreciate the request for clarification. The quotient-space formulation performs the bidiagonalization entirely in the data space; the isometry is maintained at every step by construction because the inner products are taken with respect to the data-space metric induced by the noise covariance and the prior is used only to map the resulting basis vectors back to the parameter space via the adjoint operator. Truncation after k steps produces a rank-k approximation whose error is controlled by the residual of the bidiagonalization process. In the revised version we will insert a short paragraph (and, if space permits, a brief lemma) that explicitly states how the isometry is preserved iteration by iteration and that bounds the propagation of the truncation error into the posterior covariance and mean. These additions will also reinforce the matrix-free nature of the overall algorithm. revision: yes
Circularity Check
No significant circularity; framework builds on standard linear algebra and Bayesian tools
full rationale
The paper's central claims involve characterizing a low-dimensional data space and its isometric embedding into parameter space for Bayesian linear inverse problems, using quotient-space Golub-Kahan bidiagonalization and empirical Bayesian inference. These steps rely on established operator theory, Krylov subspace methods, and standard Bayesian updating without reducing any prediction or result to a fitted parameter or self-citation by construction. The abstract and framework present the low-dimensionality as a rigorous characterization under typical assumptions on the forward map, not as a tautology or renamed input. No load-bearing step equates outputs to inputs via definition or self-referential fitting. Minor self-citation risk exists in any iterative method paper but is not central here. Derivation remains self-contained against external benchmarks like standard SVD-based dimension reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The data space is intrinsically low-dimensional for the class of linear inverse problems considered
- domain assumption An isometric embedding of the data space into the parameter space exists and preserves the update
Reference graph
Works this paper leans on
-
[1]
Extreme-scale UQ for Bayesian inverse problems governed by PDEs
Tan Bui-Thanh, Carsten Burstedde, Omar Ghattas, James Martin, Georg Stadler, and Lucas C Wilcox. Extreme-scale UQ for Bayesian inverse problems governed by PDEs. InSC’12: Pro- ceedings of the international conference on high performance computing, networking, storage and analysis, pages 1–11. IEEE, 2012
work page 2012
-
[2]
Tan Bui-Thanh, Omar Ghattas, James Martin, and Georg Stadler. A computational framework for infinite-dimensional Bayesian inverse problems part I: The linearized case, with application to global seismic inversion.SIAM Journal on Scientific Computing, 35(6):A2494–A2523, 2013. 30
work page 2013
- [3]
-
[4]
London: Chapman and Hall, 1997
Bradley P Carlin and Thomas A Louis.Bayes and empirical Bayes methods for data analysis. London: Chapman and Hall, 1997
work page 1997
-
[5]
Noe Angelo Caruso and Paolo Novati. Convergence analysis of LSQR for compact operator equations.Linear Algebra and its Applications, 583:146–164, 2019
work page 2019
-
[6]
J Chung and A K Saibaba. Generalized hybrid iterative methods for large-scale Bayesian inverse problems.SIAM Journal on Scientific Computing, 39(5):S24–S46, 2017
work page 2017
-
[7]
Julianne Chung and Silvia Gazzola. Computational methods for large-scale inverse problems: a survey on hybrid projection methods.SIAM Review, 66(2):205–284, 2024
work page 2024
-
[8]
A weighted-GCV method for Lanczos- hybrid regularization.Electr
Julianne Chung, James G Nagy, and Dianne P O’Leary. A weighted-GCV method for Lanczos- hybrid regularization.Electr. Trans. Numer. Anal., 28(29):149–167, 2008
work page 2008
-
[9]
Tiangang Cui, James Martin, Youssef M Marzouk, Antti Solonen, and Alessio Spantini. Likelihood-informed dimension reduction for nonlinear inverse problems.Inverse Problems, 30 (11):114015, 2014
work page 2014
-
[10]
Masoumeh Dashti, Kody JH Law, Andrew M Stuart, and Jochen Voss. Map estimators and their consistency in Bayesian nonparametric inverse problems.Inverse Problems, 29(9):095017, 2013
work page 2013
-
[11]
H. W. Engl, M Hanke, and A Neubauer.Regularization of Inverse Problems. Kluwer Academic Publishers, 2000
work page 2000
-
[12]
H Pearl Flath, Lucas C Wilcox, Volkan Ak¸ celik, Judith Hill, Bart van Bloemen Waanders, and Omar Ghattas. Fast algorithms for Bayesian uncertainty quantification in large-scale linear in- verse problems based on low-rank partial hessian approximations.SIAM Journal on Scientific Computing, 33(1):407–432, 2011
work page 2011
-
[13]
A metric for covariance matrices
Wolfgang F¨ orstner and Boudewijn Moonen. A metric for covariance matrices. InGeodesy-the Challenge of the 3rd Millennium, pages 299–309. Springer, 2003
work page 2003
-
[14]
Joel N Franklin. Well-posed stochastic extensions of ill-posed linear problems.Journal of mathe- matical analysis and applications, 31(3):682–716, 1970
work page 1970
-
[15]
Silvia Gazzola, Per Christian Hansen, and James G Nagy. IR Tools: A MATLAB package of iterative regularization methods and large-scale test problems.Numerical Algorithms, 81(3):773– 811, 2019
work page 2019
-
[16]
Per Christian Hansen.Discrete inverse problems: insight and algorithms. SIAM, 2010
work page 2010
-
[17]
Per Christian Hansen, J G Nagy, and D P O’Leary.Deblurring Images: Matrices, Spectra and Filtering. SIAM, Philadelphia, 2006
work page 2006
-
[18]
Tapio Helin and Martin Burger. Maximum a posteriori probability estimates in infinite- dimensional Bayesian inverse problems.Inverse Problems, 31(8):085009, 2015
work page 2015
-
[19]
Cambridge University Press, 2012
Roger A Horn and Charles R Johnson.Matrix Analysis. Cambridge University Press, 2012
work page 2012
-
[20]
Jari Kaipio and Erkki Somersalo.Statistical and Computational Inverse Problems. Springer, 2006
work page 2006
-
[21]
¨Uber lineare methoden in der wahrscheinlichkeitsrechnung.Ann Acad Sci Fen- nicae, 37:1, 1947
Kari Karhunen. ¨Uber lineare methoden in der wahrscheinlichkeitsrechnung.Ann Acad Sci Fen- nicae, 37:1, 1947
work page 1947
-
[22]
Misha E Kilmer and Dianne P O’Leary. Choosing regularization parameters in iterative methods for ill-posed problems.SIAM Journal on Matrix Analysis and Applications, 22(4):1204–1221, 2001
work page 2001
-
[23]
Konstantinos Zygalakis Kody Law, Andrew Stuart.Data Assimilation: A Mathematical Intro- duction. Springer, 2015
work page 2015
-
[24]
Linear inverse problems for generalised random variables.Inverse problems, 5(4):599–612, 1989
Markku S Lehtinen, Lassi Paivarinta, and Erkki Somersalo. Linear inverse problems for generalised random variables.Inverse problems, 5(4):599–612, 1989
work page 1989
-
[25]
Haibo Li. A preconditioned Krylov subspace method for linear inverse problems with general-form Tikhonov regularization.SIAM Journal on Scientific Computing, 46(4):A2607–A2633, 2024. 31
work page 2024
-
[26]
Haibo Li. Projected Newton method for large-scale Bayesian linear inverse problems.SIAM Journal on Optimization, 35(3):1439–1468, 2025
work page 2025
-
[27]
Wei Li and Olaf A Cirpka. Efficient geostatistical inverse methods for structured and unstructured grids.Water resources research, 42(6), 2006
work page 2006
-
[28]
Chad Lieberman, Karen Willcox, and Omar Ghattas. Parameter and state model reduction for large-scale statistical inverse problems.SIAM Journal on Scientific Computing, 32(5):2523–2542, 2010
work page 2010
-
[29]
Numerical Mathematics and Scie, 2013
J¨ org Liesen and Zdenek Strakos.Krylov subspace methods: principles and analysis. Numerical Mathematics and Scie, 2013
work page 2013
-
[30]
Finn Lindgren, H˚ avard Rue, and Johan Lindstr¨ om. An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach.Journal of the Royal Statistical Society Series B: Statistical Methodology, 73(4):423–498, 2011
work page 2011
-
[31]
M. Lo` eve.Probability Theory II. Springer New York, NY, 1978
work page 1978
-
[32]
James Martin, Lucas C Wilcox, Carsten Burstedde, and Omar Ghattas. A stochastic Newton MCMC method for large-scale statistical inverse problems with application to seismic inversion. SIAM Journal on Scientific Computing, 34(3):A1460–A1487, 2012
work page 2012
-
[33]
Youssef M Marzouk and Habib N Najm. Dimensionality reduction and polynomial chaos ac- celeration of Bayesian inference in inverse problems.Journal of Computational Physics, 228(6): 1862–1902, 2009
work page 1902
- [34]
-
[35]
Wolfgang Nowak, Sascha Tenkleve, and Olaf A Cirpka. Efficient computation of linearized cross- covariance and auto-covariance matrices of interdependent quantities.Mathematical geology, 35 (1):53–66, 2003
work page 2003
-
[36]
Bayes and empirical Bayes: do they merge? Biometrika, pages 285–302, 2014
Sonia Petrone, Judith Rousseau, and Catia Scricciolo. Bayes and empirical Bayes: do they merge? Biometrika, pages 285–302, 2014
work page 2014
-
[37]
R A Renaut, S Vatankhah, and V E Ardesta. Hybrid and iteratively reweighted regularization by unbiased predictive risk and weighted GCV for projected systems.SIAM Journal on Scientific Computing, 39(2):B221–B243, 2017
work page 2017
-
[38]
Mathias Richter.Inverse Problems: Basics, Theory and Applications in Geophysics. Springer, 2016
work page 2016
-
[39]
Lassi Roininen, Janne MJ Huttunen, and Sari Lasanen. Whittle-Mat´ ern priors for bayesian statistical inversion with applications in electrical impedance tomography.Inverse Probl. Imag., 8(2), 2014
work page 2014
-
[40]
Judith Rousseau and Botond Szabo. Asymptotic behaviour of the empirical Bayes posteriors associated to maximum marginal likelihood estimator.Annals of Statistics, 2017
work page 2017
-
[41]
Yousef Saad.Numerical methods for large eigenvalue problems: revised edition. SIAM, 2011
work page 2011
-
[42]
Arvind K Saibaba, Julianne Chung, and Katrina Petroske. Efficient Krylov subspace methods for uncertainty quantification in large Bayesian linear inverse problems.Numer. Linear Algebra Appl., 27(5):e2325, 2020
work page 2020
-
[43]
Alessio Spantini, Antti Solonen, Tiangang Cui, James Martin, Luis Tenorio, and Youssef Marzouk. Optimal low-rank approximations of Bayesian linear inverse problems.SIAM Journal on Scientific Computing, 37(6):A2451–A2487, 2015
work page 2015
-
[44]
Alessio Spantini, Tiangang Cui, Karen Willcox, Luis Tenorio, and Youssef Marzouk. Goal-oriented optimal approximations of bayesian linear inverse problems.SIAM Journal on Scientific Com- puting, 39(5):S167–S196, 2017
work page 2017
-
[45]
Inverse problems: a Bayesian perspective.Acta Numerica, 19:451–559, 2010
Andrew M Stuart. Inverse problems: a Bayesian perspective.Acta Numerica, 19:451–559, 2010
work page 2010
-
[46]
A N Tikhonov and V Y Arsenin.Solutions of Ill-Posed Problems. Washington, DC, 1977. 32
work page 1977
-
[47]
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learning. MIT press Cambridge, MA, 2006
work page 2006
-
[48]
Andrew TA Wood and Grace Chan. Simulation of stationary Gaussian processes in [0,1]d.Journal of computational and graphical statistics, 3(4):409–432, 1994. 33
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.