VSCD: Video-based Scene Change Detection in Unaligned Scenes
Pith reviewed 2026-05-21 05:08 UTC · model grok-4.3
The pith
A query-centric model detects pixel-wise changes in unsynchronized videos of indoor scenes by aligning local patches and fusing confidence-weighted features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
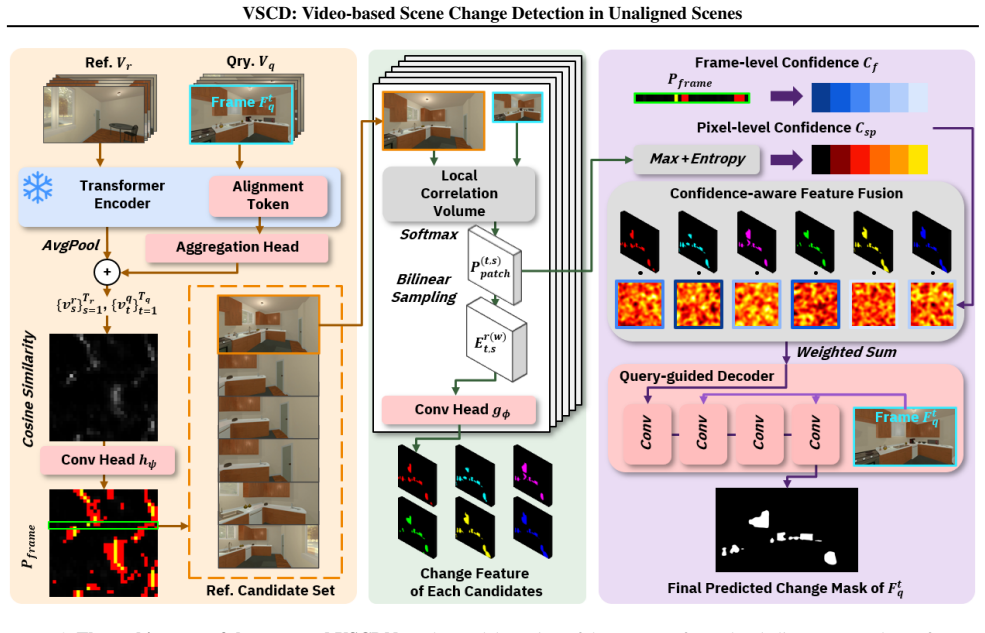
By training directly on change-mask labels, the model implicitly learns temporal matching. It takes multiple reference frames, aligns their features to the query via local patch correspondence, fuses per-candidate change features with frame-level and patch-level confidence, and decodes a high-resolution pixel-wise change mask for each query frame.
What carries the argument
The query-centric multi-reference model that performs alignment through local patch correspondence and fuses change features using confidence scores at frame and patch levels.
If this is right
- Outperforms strong image-based and video-based baselines on the introduced benchmark.
- Transfers to real-world settings as shown by deployment on a mobile robot.
- Supports two downstream tasks: visual surveillance and object incremental learning.
- Handles large numbers of appearing and disappearing objects between the reference and query videos.
Where Pith is reading between the lines
- Extending the approach to outdoor or longer-duration videos could test the limits of patch-based alignment under greater appearance variation.
- Integrating this change detection into broader robotic mapping systems might enable more robust lifelong learning without explicit map updates.
- The implicit learning from supervision suggests that separate optical flow or registration modules could be avoided in similar video understanding tasks.
- Evaluating on datasets with significant lighting changes would reveal if the current fusion strategy generalizes beyond the simulated and real test sets provided.
Load-bearing premise
Local patch correspondence between query and reference features produces reliable alignment and change decisions under fully unconstrained camera motion and large temporal gaps.
What would settle it
Running the model on a set of real videos featuring very large viewpoint shifts or time gaps not represented in the training data and checking whether the predicted pixel-wise change masks match human annotations.
Figures






read the original abstract
Detecting what has changed in an environment is essential for long-term autonomy, yet most change detection settings assume fixed viewpoints, mild misalignment, or only a few changed objects. We introduce Video-based Scene Change Detection (VSCD), which predicts a pixel-wise change mask for each query frame, given a reference and a query RGB video of the same indoor space recorded at different times under unconstrained camera motion. The two videos are not temporally synchronized, and many object instances may appear or disappear. To study this setting, we build a large-scale benchmark with over 1.1 million frames annotated with pixel-accurate change masks, together with a real-world test set for evaluating transfer beyond simulation. We propose a query-centric multi-reference model that learns temporal matching implicitly from change-mask supervision, aligns candidate reference features to the query via local patch correspondence, and fuses per-candidate change features using frame-level and patch-level confidence before decoding a high-resolution mask once per frame. Our approach achieves state-of-the-art performance against strong image- and video-based baselines, and we validate its real-world impact by deploying it on a mobile robot for two downstream applications -- visual surveillance and object incremental learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Video-based Scene Change Detection (VSCD), a task that requires predicting a pixel-wise change mask for each query frame given an unsynchronized reference RGB video and query RGB video of the same indoor scene under fully unconstrained camera motion. It contributes a new large-scale benchmark with over 1.1 million frames annotated with pixel-accurate change masks plus a real-world test set, and proposes a query-centric multi-reference architecture that learns temporal matching implicitly from supervision, aligns reference features to the query via local patch correspondence, fuses per-candidate change features using frame-level and patch-level confidence scores, and decodes a high-resolution mask. The work reports state-of-the-art quantitative results against image- and video-based baselines and demonstrates deployment on a mobile robot for visual surveillance and object incremental learning.
Significance. If the reported performance gains prove robust, the work would meaningfully advance change detection for long-term robot autonomy by relaxing the common assumptions of fixed viewpoints, synchronized capture, and limited object changes. The scale of the introduced benchmark constitutes a substantial community resource, and the real-robot deployment provides direct evidence of downstream utility. The empirical nature of the approach, however, means its significance hinges on whether the local-patch alignment and fusion strategy reliably handles the stated challenges of repetitive textures, specular surfaces, and large viewpoint shifts.
major comments (2)
- [§3.2] §3.2 (Alignment and fusion): The central claim that local patch correspondence produces reliable alignment and change decisions rests on an assumption that may not hold under large unconstrained viewpoint shifts and temporal gaps; indoor scenes with repetitive textures can yield ambiguous correspondences, and the manuscript provides no explicit geometric constraints, global optimization, or targeted failure-case analysis to mitigate this risk.
- [Table 2] Table 2 and §4.2: The SOTA performance numbers are presented without sufficient ablation on the contribution of the multi-reference fusion (frame-level vs. patch-level confidence) or on the effect of reference video length; without these controls it is difficult to confirm that the gains are attributable to the query-centric design rather than dataset-specific tuning.
minor comments (2)
- [Abstract] Abstract and §2: The exact train/validation/test splits and annotation protocol for the 1.1 million frames are not stated, which would improve reproducibility and allow readers to assess potential label noise.
- [Figure 3] Figure 3: The qualitative examples would benefit from explicit indication of the magnitude of camera motion and temporal gap between reference and query sequences to illustrate the operating regime.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for the detailed feedback. We have carefully considered the major comments and provide point-by-point responses below. Revisions have been made to incorporate additional analyses and ablations to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Alignment and fusion): The central claim that local patch correspondence produces reliable alignment and change decisions rests on an assumption that may not hold under large unconstrained viewpoint shifts and temporal gaps; indoor scenes with repetitive textures can yield ambiguous correspondences, and the manuscript provides no explicit geometric constraints, global optimization, or targeted failure-case analysis to mitigate this risk.
Authors: We thank the referee for highlighting this important consideration. Our approach relies on learning temporal matching implicitly from the change mask supervision rather than explicit geometric constraints. The local patch correspondence is combined with confidence-based fusion to handle potential ambiguities arising from repetitive textures or large viewpoint shifts. We recognize that a more detailed failure-case analysis would be beneficial. Accordingly, we have added a new subsection in the revised manuscript discussing challenging cases, including examples with repetitive patterns and large temporal gaps, along with qualitative results showing how the model performs in these scenarios. We have also clarified in §3.2 that while global optimization is not employed, the multi-reference fusion provides robustness through learned confidence scores. revision: partial
-
Referee: [Table 2] Table 2 and §4.2: The SOTA performance numbers are presented without sufficient ablation on the contribution of the multi-reference fusion (frame-level vs. patch-level confidence) or on the effect of reference video length; without these controls it is difficult to confirm that the gains are attributable to the query-centric design rather than dataset-specific tuning.
Authors: We agree that ablations are necessary to isolate the contributions of the proposed components. In the revised manuscript, we have expanded §4.2 and Table 2 with additional ablation studies. Specifically, we compare the full model against variants that disable frame-level confidence, patch-level confidence, or both, demonstrating the incremental benefits of each. Furthermore, we evaluate performance as a function of reference video length, showing that longer references improve results up to a point, consistent with the multi-reference design. These controls support that the performance gains stem from the query-centric architecture rather than tuning alone. revision: yes
Circularity Check
Empirical supervised model with no derivation reducing to self-defined inputs or self-citations
full rationale
The paper presents an end-to-end trained query-centric model that learns temporal matching implicitly from pixel-wise change-mask supervision on a newly introduced benchmark of 1.1M frames. Alignment via local patch correspondence and confidence-based fusion are architectural choices trained directly on the target task rather than derived from equations or prior self-citations. SOTA claims and robot deployment results rest on empirical evaluation against external baselines and a real-world test set, with no load-bearing step that renames a fit as a prediction or imports uniqueness from the authors' own prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local patch correspondence between query and reference features produces usable alignment under unconstrained indoor camera motion
- domain assumption Change-mask supervision is sufficient to train implicit temporal matching without explicit synchronization
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
query-centric multi-reference model that learns temporal matching implicitly from change-mask supervision, aligns candidate reference features to the query via local patch correspondence, and fuses per-candidate change features using frame-level and patch-level confidence
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
frame-level alignment (temporal consistency) across reference and query sequences without trajectory alignment, patch-level correspondence (geometric compensation)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Intelligence & Robotics , volume=
Digital twins to embodied artificial intelligence: review and perspective , author=. Intelligence & Robotics , volume=. 2025 , publisher=
work page 2025
-
[2]
The plastic human brain cortex , author=. Annu. Rev. Neurosci. , volume=. 2005 , publisher=
work page 2005
-
[3]
Developmental Behavioral Neuroscience , pages=
Induction of brain structure by experience: Substrates for cognitive development , author=. Developmental Behavioral Neuroscience , pages=. 2013 , publisher=
work page 2013
-
[4]
How the body shapes the way we think: a new view of intelligence , author=. 2006 , publisher=
work page 2006
-
[5]
Psychology of Learning and Motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of Learning and Motivation , volume=. 1989 , publisher=
work page 1989
-
[6]
IEEE Transactions on Cognitive and Developmental Systems , volume=
Cbcl-pr: A cognitively inspired model for class-incremental learning in robotics , author=. IEEE Transactions on Cognitive and Developmental Systems , volume=. 2023 , publisher=
work page 2023
-
[7]
Advances in Neural Information Processing Systems , volume=
Few-shot continual active learning by a robot , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
2024 IEEE International Conference on Robotics and Automation , pages=
Interactive continual learning architecture for long-term personalization of home service robots , author=. 2024 IEEE International Conference on Robotics and Automation , pages=. 2024 , organization=
work page 2024
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ego4d: Around the world in 3,000 hours of egocentric video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Habitat: A platform for embodied ai research , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
AI2-THOR: An Interactive 3D Environment for Visual AI
Ai2-thor: An interactive 3d environment for visual ai , author=. arXiv preprint arXiv:1712.05474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2017 , publisher=
work page 2017
-
[13]
Advances in Neural Information Processing Systems , volume=
Experience replay for continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
IEEE Transactions on Image Processing , volume=
Image change detection algorithms: a systematic survey , author=. IEEE Transactions on Image Processing , volume=. 2005 , publisher=
work page 2005
-
[15]
Sakurada, Ken and Okatani, Takayuki , year=. Change detection from a street image pair using cnn features and superpixel segmentation , booktitle=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
TransVCL: attention-enhanced video copy localization network with flexible supervision , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
European Conference on Computer Vision , pages=
Self-supervised Video Copy Localization with Regional Token Representation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[18]
IEEE Transactions on Geoscience and Remote Sensing , volume=
A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2021 , publisher=
work page 2021
-
[19]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Asymmetric siamese networks for semantic change detection in aerial images , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2021 , publisher=
work page 2021
-
[20]
A spatial-temporal attention-based method and a new dataset for remote sensing image change detection , author=. Remote Sensing , volume=. 2020 , publisher=
work page 2020
-
[21]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2018 , publisher=
work page 2018
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
Creating xBD: A dataset for assessing building damage from satellite imagery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[23]
Street-view change detection with deconvolutional networks , author=. Autonomous Robots , volume=. 2018 , publisher=
work page 2018
-
[24]
IEEE International Conference on Robotics and Automation , pages=
Weakly supervised silhouette-based semantic scene change detection , author=. IEEE International Conference on Robotics and Automation , pages=. 2020 , organization=
work page 2020
-
[25]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Changesim: Towards end-to-end online scene change detection in industrial indoor environments , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2021 , organization=
work page 2021
-
[26]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Remote sensing image change detection with transformers , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2021 , publisher=
work page 2021
-
[27]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Joint spatio-temporal modeling for semantic change detection in remote sensing images , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2024 , publisher=
work page 2024
-
[28]
25th IEEE International Conference on Image Processing , pages=
Fully convolutional siamese networks for change detection , author=. 25th IEEE International Conference on Image Processing , pages=. 2018 , organization=
work page 2018
-
[29]
IEEE Geoscience and Remote Sensing Letters , volume=
SNUNet-CD: A densely connected Siamese network for change detection of VHR images , author=. IEEE Geoscience and Remote Sensing Letters , volume=. 2021 , publisher=
work page 2021
-
[30]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Intelligent Multimedia Analysis for Security Applications , pages=
Content-based video copy detection--a survey , author=. Intelligent Multimedia Analysis for Security Applications , pages=. 2010 , publisher=
work page 2010
-
[32]
International Telecommunications Symposium , pages=
An annotated video database for abandoned-object detection in a cluttered environment , author=. International Telecommunications Symposium , pages=. 2014 , organization=
work page 2014
-
[33]
IEEE Transactions on Circuits and Systems I: Regular Papers , volume=
Anomaly detection in moving-camera video sequences using principal subspace analysis , author=. IEEE Transactions on Circuits and Systems I: Regular Papers , volume=. 2017 , publisher=
work page 2017
-
[34]
IEEE Transactions on Image Processing , volume=
Domain-transformable sparse representation for anomaly detection in moving-camera videos , author=. IEEE Transactions on Image Processing , volume=. 2019 , publisher=
work page 2019
-
[35]
Signal Processing: Image Communication , volume=
Change detection in moving-camera videos with limited samples using twin-CNN features and learnable morphological operations , author=. Signal Processing: Image Communication , volume=. 2023 , publisher=
work page 2023
-
[36]
Pixel-Based Change Detection in Moving-Camera Videos Using Twin Convolutional Features on a Data-Constrained Scenario , author=. IEEE Access , year=
-
[37]
Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
Near-duplicate video retrieval with deep metric learning , author=. Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
-
[38]
arXiv preprint arXiv:2105.14566 , year=
CNN retrieval based unsupervised metric learning for near-duplicated video retrieval , author=. arXiv preprint arXiv:2105.14566 , year=
-
[39]
Extremely compact video representation for efficient near-duplicates detection , author=. Pattern Recognition , volume=. 2025 , publisher=
work page 2025
-
[40]
arXiv preprint arXiv:2503.16832 , year=
Joint Self-Supervised Video Alignment and Action Segmentation , author=. arXiv preprint arXiv:2503.16832 , year=
-
[41]
Proceedings of the 29th ACM International Conference on Multimedia , pages=
Video similarity and alignment learning on partial video copy detection , author=. Proceedings of the 29th ACM International Conference on Multimedia , pages=
-
[42]
arXiv preprint arXiv:2305.15679 , year=
A similarity alignment model for video copy segment matching , author=. arXiv preprint arXiv:2305.15679 , year=
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Deep high-resolution representation learning for visual recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2020 , publisher=
work page 2020
-
[44]
IEEE Intelligent Vehicles Symposium , pages=
Dr-tanet: Dynamic receptive temporal attention network for street scene change detection , author=. IEEE Intelligent Vehicles Symposium , pages=
-
[45]
How to reduce change detection to semantic segmentation , author=. Pattern Recognition , volume=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Zero-shot scene change detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Towards generalizable scene change detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[48]
10th International Workshop on the Analysis of Multitemporal Remote Sensing Images , pages=
Deep Siamese multi-scale convolutional network for change detection in multi-temporal VHR images , author=. 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images , pages=. 2019 , organization=
work page 2019
-
[49]
International Conference on Learning Representations , volume=
Simclr: A simple framework for contrastive learning of visual representations , author=. International Conference on Learning Representations , volume=. 2020 , organization=
work page 2020
-
[50]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[51]
International Conference on Machine Learning , pages=
Decaf: A deep convolutional activation feature for generic visual recognition , author=. International Conference on Machine Learning , pages=. 2014 , organization=
work page 2014
- [52]
- [53]
-
[54]
Annual Review of Psychology , volume=
Change detection , author=. Annual Review of Psychology , volume=. 2002 , publisher=
work page 2002
-
[55]
Frontiers in Human Neuroscience , volume=
Visual mismatch negativity: a mini-review of non-pathological studies with special populations and stimuli , author=. Frontiers in Human Neuroscience , volume=. 2022 , publisher=
work page 2022
-
[56]
Robotics: Science and Systems , pages=
Dynamic maps for long-term operation of mobile service robots , author=. Robotics: Science and Systems , pages=
-
[57]
IEEE International Conference on Robotics and Automation , pages=
Long-term 3D map maintenance in dynamic environments , author=. IEEE International Conference on Robotics and Automation , pages=. 2014 , organization=
work page 2014
-
[58]
Safe and robust map updating for long-term operations in dynamic environments , author=. Sensors , volume=. 2023 , publisher=
work page 2023
-
[59]
International Conference on Machine Learning , pages=
Vectormapnet: End-to-end vectorized hd map learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[60]
International Conference on Machine Learning , pages=
Path planning using neural a* search , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[61]
International Conference on Machine Learning , year=
Palm-e: An embodied multimodal language model , author=. International Conference on Machine Learning , year=
-
[62]
International Conference on Machine Learning , pages=
End-to-end active object tracking via reinforcement learning , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[63]
International Journal of Remote Sensing , volume=
Change detection techniques , author=. International Journal of Remote Sensing , volume=. 2004 , publisher=
work page 2004
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[65]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Flownet: Learning optical flow with convolutional networks , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[66]
SAM 2: Segment Anything in Images and Videos
SAM 2: Segment Anything in Images and Videos , author=. arXiv preprint arXiv:2408.00714 , url=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.