Macro: Enhancing Multilingual Counterfactual Explanations through Alignment-as-Preference Optimization
Pith reviewed 2026-05-13 01:13 UTC · model grok-4.3
The pith
A preference alignment method called Macro improves the validity of multilingual self-generated counterfactual explanations by 12.55 percent on average while maintaining minimality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
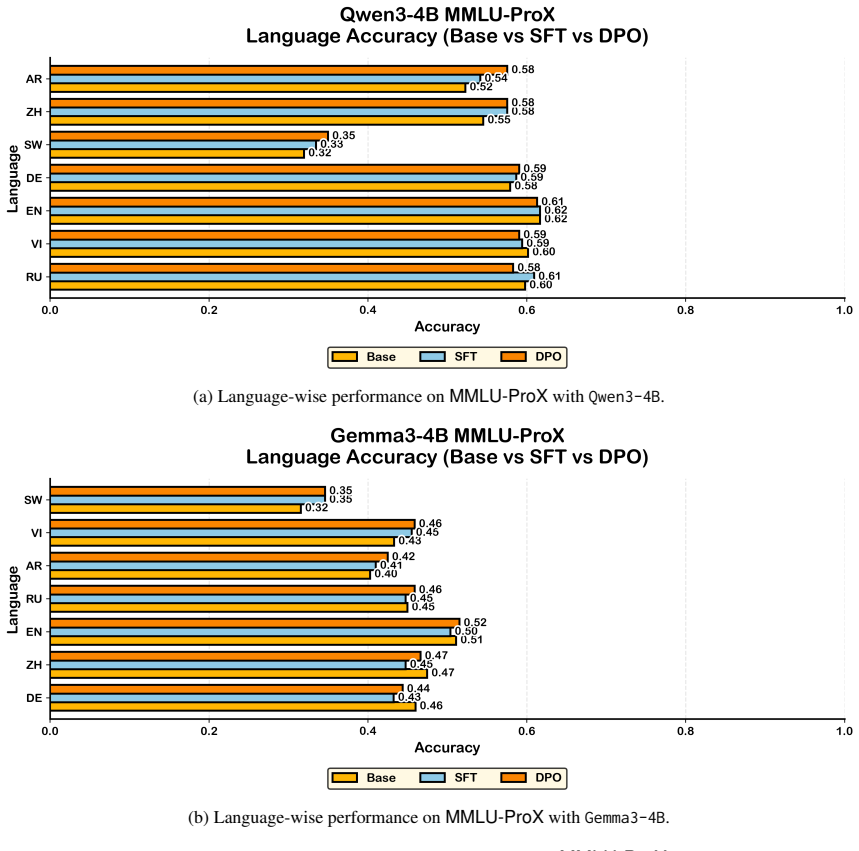
Macro applies Direct Preference Optimization to multilingual SCE generation using a composite scoring function to construct preference pairs that translate the validity-minimality trade-off into training signals. Across four LLMs and seven typologically diverse languages, it improves validity by 12.55% on average over chain-of-thought without degrading minimality, avoids the minimality issues of translation baselines, and surpasses supervised fine-tuning on both metrics, with added benefits in cross-lingual alignment and error reduction.
What carries the argument
Macro, a DPO framework that builds preference pairs via a composite scoring function evaluating both validity and minimality for multilingual counterfactual generation.
If this is right
- Validity of generated explanations increases by 12.55% on average compared to chain-of-thought prompting.
- Minimality is preserved, unlike in translation-based methods that violate it severely.
- Performance on both validity and minimality exceeds that of supervised fine-tuning.
- Cross-lingual perturbation alignment improves and common generation errors decrease.
Where Pith is reading between the lines
- Similar preference optimization could help resolve trade-offs in other LLM explanation or generation tasks.
- Testing Macro on additional low-resource languages might reveal whether the method scales without language-specific adjustments.
- The reliance on a composite score suggests that refining the scoring function could further enhance results in specific domains.
Load-bearing premise
The composite scoring function used to build preference pairs measures the validity and minimality trade-off accurately and without introducing bias across languages and models.
What would settle it
Running the same experiments with Macro on the four LLMs and seven languages and finding no significant average improvement in validity or a degradation in minimality compared to the chain-of-thought baseline would falsify the main claim.
Figures













read the original abstract
Self-generated counterfactual explanations (SCEs) are minimally modified inputs (minimality) generated by large language models (LLMs) that flip their own predictions (validity), offering a causally grounded approach to unraveling black-box LLM behavior. Yet extending them beyond English remains challenging: existing methods struggle to produce valid SCEs in non-dominant languages, and a persistent trade-off between validity and minimality undermines explanation quality. We introduce Macro, a preference alignment framework that applies Direct Preference Optimization (DPO) to multilingual SCE generation, using a composite scoring function to construct preference pairs that effectively translate the trade-off into measurable preference signals. Experiments across four LLMs and seven typologically diverse languages show that Macro improves validity by 12.55\% on average over the chain-of-thought baseline without degrading minimality, while avoiding the severe minimality violations of the translation-based baseline. Compared to supervised fine-tuning, Macro achieves superior performance on both metrics, confirming that explicit preference optimization is essential for balancing this trade-off. Further analyses reveal that Macro increases cross-lingual perturbation alignment and mitigates common generation errors. Our results highlight preference optimization as a promising direction for enhancing multilingual model explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Macro, a preference alignment framework that applies Direct Preference Optimization (DPO) to multilingual self-generated counterfactual explanation (SCE) generation. Preference pairs are constructed using a composite scoring function that encodes the validity-minimality trade-off; experiments across four LLMs and seven typologically diverse languages report that Macro improves validity by 12.55% on average over a chain-of-thought baseline without degrading minimality, outperforms supervised fine-tuning, and avoids the minimality violations seen in translation-based baselines.
Significance. If the composite scoring function is shown to produce unbiased, language-agnostic preference signals that align with human judgments of explanation quality, the result would be significant for multilingual explainable AI. It would demonstrate that explicit preference optimization can resolve the validity-minimality trade-off more effectively than standard fine-tuning or translation pipelines, with potential implications for cross-lingual model interpretability.
major comments (2)
- [§3.2] §3.2 (Preference Pair Construction): The composite scoring function used to order pairs for DPO is described only at a high level; the explicit formula, the weighting scheme between validity and minimality components, and any cross-lingual or cross-model validation of those weights are not provided. Because the entire DPO training signal depends on the ordering induced by this function, the absence of these details makes it impossible to verify that the reported 12.55% validity gain reflects a genuine improvement rather than an artifact of the scoring rule.
- [§4] §4 (Experiments): The headline result of a 12.55% average validity improvement is presented without language-specific breakdowns, per-model tables, error bars, or statistical significance tests. In addition, the precise operational definitions of the validity and minimality metrics (and how they are computed for non-English inputs) are not stated. These omissions are load-bearing because the central claim is an empirical average over seven typologically diverse languages; without the supporting data it cannot be assessed whether the improvement is uniform or driven by a subset of languages or models.
minor comments (2)
- [Abstract] The abstract and introduction use the acronym 'Macro' without expanding it or briefly glossing its construction.
- [§3] Notation for the validity and minimality scores is introduced without a consolidated table of symbols, making it harder to track how the composite function is assembled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas where additional detail will improve clarity and verifiability. We address each major comment below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Preference Pair Construction): The composite scoring function used to order pairs for DPO is described only at a high level; the explicit formula, the weighting scheme between validity and minimality components, and any cross-lingual or cross-model validation of those weights are not provided. Because the entire DPO training signal depends on the ordering induced by this function, the absence of these details makes it impossible to verify that the reported 12.55% validity gain reflects a genuine improvement rather than an artifact of the scoring rule.
Authors: We agree that the current high-level description in §3.2 leaves important details unspecified. In the revised manuscript we will expand this section to provide the explicit formula for the composite scoring function, the precise weighting scheme applied to the validity and minimality components, and the results of cross-lingual and cross-model validation performed to confirm that the induced preference ordering is stable. These additions will allow readers to reproduce the preference-pair construction and assess whether the reported gains arise from the scoring rule itself. revision: yes
-
Referee: [§4] §4 (Experiments): The headline result of a 12.55% average validity improvement is presented without language-specific breakdowns, per-model tables, error bars, or statistical significance tests. In addition, the precise operational definitions of the validity and minimality metrics (and how they are computed for non-English inputs) are not stated. These omissions are load-bearing because the central claim is an empirical average over seven typologically diverse languages; without the supporting data it cannot be assessed whether the improvement is uniform or driven by a subset of languages or models.
Authors: We acknowledge that §4 would benefit from more granular reporting. In the revision we will add language-specific and per-model tables for both validity and minimality, include error bars, and report statistical significance via paired t-tests. We will also state the operational definitions explicitly: validity is the fraction of generated SCEs that flip the model’s original prediction, and minimality is the normalized token-level edit distance. Both metrics are computed using language-appropriate tokenizers and the same underlying classifier for all languages, ensuring consistent evaluation across the seven typologically diverse languages. These changes will demonstrate that the 12.55 % average improvement is not driven by a subset of languages or models. revision: yes
Circularity Check
No circularity: empirical results from DPO on externally scored pairs
full rationale
The paper's chain consists of (1) defining a composite scorer to rank candidate counterfactuals, (2) building preference pairs from those rankings, (3) running DPO, and (4) measuring validity/minimality gains on held-out test sets across four LLMs and seven languages. None of these steps reduces to its own inputs by construction: the scorer is an input assumption whose correctness is tested by the downstream human-aligned metrics, the DPO objective is standard, and the reported 12.55 % average improvement is an empirical average against independent baselines. No equations, self-definitional loops, fitted-parameter-as-prediction, or load-bearing self-citations appear in the abstract or method description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Composite scoring function accurately reflects the validity-minimality trade-off for preference pair construction
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.