AtelierEval: Agentic Evaluation of Humans & LLMs as Text-to-Image Prompters
Pith reviewed 2026-05-22 05:35 UTC · model grok-4.3
The pith
AtelierEval benchmarks the prompting proficiency of humans and multimodal LLMs for text-to-image generation across 360 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AtelierEval is the first unified benchmark that quantifies prompting proficiency for text-to-image systems across 360 expert-crafted tasks grounded in a cognitive view and a taxonomy of real-world challenges, with a dual interface for humans and MLLMs. AtelierJudge, a skill-based memory-augmented agentic evaluator, produces subjective and objective scores for prompt-image pairs and achieves a Spearman correlation of 0.79 with human experts. Benchmarking 8 MLLMs against 48 human users across 4 T2I backends validates the benchmark as a diagnostic tool and reveals the superiority of mimicry over planning.
What carries the argument
AtelierJudge, a skill-based memory-augmented agentic evaluator that assigns subjective and objective scores to prompt-image pairs.
If this is right
- Prompting proficiency can be measured independently of the downstream text-to-image model's quality.
- The same 360 tasks and dual interface allow direct comparison of human and MLLM prompting performance.
- Mimicry-based prompting strategies produce higher-scoring results than planning-based strategies.
- Future prompter designs should incorporate image-augmented methods rather than text-only planning.
Where Pith is reading between the lines
- The benchmark could be adapted to track individual user improvement in prompting over repeated practice sessions.
- Similar task taxonomies might apply to evaluating prompting in other generative domains such as video or audio synthesis.
- Training data for MLLMs could be augmented with high-scoring prompt-image pairs identified by the judge to improve their prompting ability.
Load-bearing premise
The 360 expert-crafted tasks, organized by a taxonomy of real-world challenges and a cognitive view across three categories, are representative enough to diagnose general prompting proficiency.
What would settle it
A replication on an independent set of prompting tasks that produces substantially different model or human rankings, or that drops AtelierJudge's correlation with fresh human experts below 0.65.
Figures

















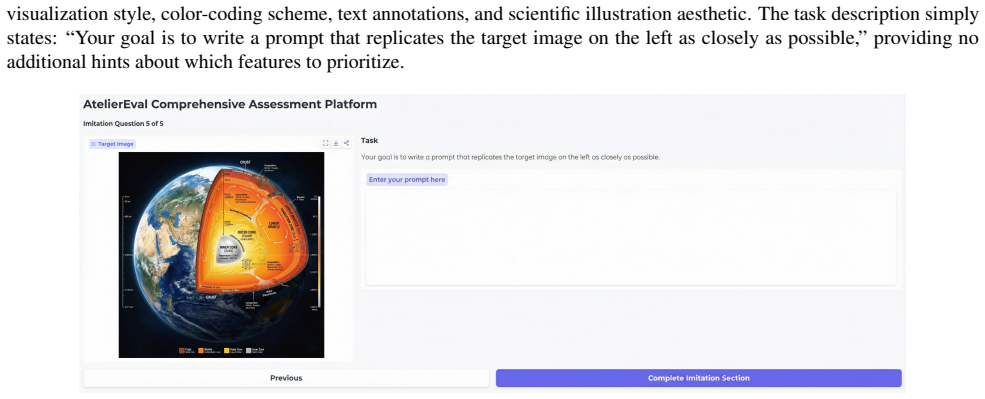
read the original abstract
Text-to-image (T2I) systems increasingly rely on upstream prompters, either humans or multimodal large language models (MLLMs), to translate user intent into detailed prompts. Yet current benchmarks fix the prompt and only evaluate T2I models, leaving the prompting proficiency of this upstream component entirely unmeasured. We introduce AtelierEval, the first unified benchmark that quantifies prompting proficiency across 360 expert-crafted tasks. Grounded in a cognitive view, it spans three task categories and instantiates tasks using a taxonomy of real-world challenges, with a dual interface for both humans and MLLMs. To enable scalable and reliable evaluation, we propose AtelierJudge, a skill-based, memory-augmented agentic evaluator. It produces subjective and objective scores for prompt-image pairs, achieving a Spearman correlation of 0.79 with human experts, approaching human performance. Extensive experiments benchmark 8 MLLMs against 48 human users across 4 T2I backends, validate AtelierEval as a robust diagnostic tool, and reveal the superiority of mimicry over planning, advocating for an image-augmented direction for future prompters. Our work is released to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AtelierEval, the first unified benchmark for quantifying prompting proficiency of humans and MLLMs in text-to-image generation across 360 expert-crafted tasks spanning three cognitive categories and a taxonomy of real-world challenges. It proposes AtelierJudge, a skill-based memory-augmented agentic evaluator that produces subjective and objective scores for prompt-image pairs and achieves a Spearman correlation of 0.79 with human experts. Experiments benchmark 8 MLLMs against 48 humans across 4 T2I backends, validate the benchmark as a diagnostic, and conclude that mimicry outperforms planning, advocating image-augmented prompters.
Significance. If the central claims hold, this provides the first systematic diagnostic for the upstream prompting component in T2I pipelines, which is currently unmeasured by existing benchmarks that fix prompts and evaluate only the generator. The agentic evaluator approaching human-level agreement and the empirical finding favoring mimicry over planning could guide design of future prompters; releasing the benchmark and tasks supports reproducible research in human-AI creative collaboration.
major comments (2)
- [Task construction / §3] Task construction section: the claim that the 360 tasks form a robust general diagnostic for prompting proficiency rests on the expert-defined taxonomy and cognitive categories being representative, yet the manuscript provides no quantitative coverage analysis (e.g., embedding similarity to real user prompt corpora, diversity metrics on length/complexity, or external validation against uncurated logs). This is load-bearing for both the 0.79 correlation and the mimicry-superiority result.
- [AtelierJudge evaluation / §4] Evaluation of AtelierJudge: the abstract and results report Spearman ρ=0.79 with human experts but supply no details on task construction rules, exclusion criteria, inter-rater reliability statistics, or statistical controls for the correlation; without these, it is impossible to assess whether the agreement supports the claim that AtelierJudge approaches human performance.
minor comments (2)
- [§4] Notation for subjective vs. objective scores in AtelierJudge should be defined explicitly with an equation or table rather than described only in prose.
- [Results figures] Figure captions for the benchmark results should include exact sample sizes and confidence intervals for the reported correlations and superiority claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the manuscript's claims about task representativeness and evaluation transparency. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Task construction / §3] Task construction section: the claim that the 360 tasks form a robust general diagnostic for prompting proficiency rests on the expert-defined taxonomy and cognitive categories being representative, yet the manuscript provides no quantitative coverage analysis (e.g., embedding similarity to real user prompt corpora, diversity metrics on length/complexity, or external validation against uncurated logs). This is load-bearing for both the 0.79 correlation and the mimicry-superiority result.
Authors: We agree that quantitative validation of the task set's coverage would strengthen the generalizability claims. While the tasks were constructed by experts using a taxonomy derived from documented real-world T2I challenges and cognitive categories, the manuscript does not include the suggested metrics. In the revised version, we will add: (i) diversity statistics on task length, complexity, and category distribution; (ii) embedding similarity analysis comparing the 360 tasks to samples from public prompt corpora (e.g., LAION-Aesthetics or DiffusionDB); and (iii) a brief discussion of how the taxonomy aligns with observed user prompt patterns. These additions will directly support the diagnostic value of the benchmark and the reported results. revision: yes
-
Referee: [AtelierJudge evaluation / §4] Evaluation of AtelierJudge: the abstract and results report Spearman ρ=0.79 with human experts but supply no details on task construction rules, exclusion criteria, inter-rater reliability statistics, or statistical controls for the correlation; without these, it is impossible to assess whether the agreement supports the claim that AtelierJudge approaches human performance.
Authors: We concur that additional methodological details are necessary to allow readers to evaluate the reliability of the 0.79 correlation. The current manuscript reports the aggregate result but omits the protocol specifics. In the revision, we will insert a new subsection (or expand §4) that specifies: the rules and criteria used to select the subset of tasks for the expert comparison study; any exclusion criteria applied to tasks or raters; inter-rater reliability statistics (e.g., intraclass correlation coefficient or Fleiss' kappa); and statistical controls or significance testing performed on the Spearman correlation. This will provide the transparency needed to substantiate the claim that AtelierJudge approaches human-level agreement. revision: yes
Circularity Check
No significant circularity; empirical benchmark anchored to external human comparisons
full rationale
This is an empirical benchmark paper with no mathematical derivation chain or fitted parameters that loop back on themselves. AtelierJudge's reported Spearman correlation of 0.79 is obtained via direct comparison against independent human expert ratings on prompt-image pairs, providing external validation rather than self-referential construction. The 360 tasks are defined via an expert taxonomy and cognitive categories, but evaluation outcomes (including mimicry superiority) are measured experimentally against human baselines and multiple T2I backends, not derived from the taxonomy by definition. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the load-bearing claims. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A cognitive view of prompting that spans three task categories and a taxonomy of real-world challenges
invented entities (2)
-
AtelierEval
no independent evidence
-
AtelierJudge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Includes details about Gemini 3 Pro capabilities and evaluation. Gu, J., Han, Z., Chen, S., Beirami, A., He, B., Zhang, G., Liao, R., Qin, Y ., Tresp, V ., and Torr, P. A systematic sur- vey of prompt engineering on vision-language foundation models.arXiv preprint arXiv:2307.12980, 2023. Guilford, J. P.The Nature of Human Intelligence. McGraw- Hill, New Y...
-
[2]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Association for Computational Linguistics, 2020. Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E. L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., Ho, J., Fleet, D. J., and Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s00146-025-02667-2 2020
-
[3]
Textual convergence:transforming, compressing, and reconciling constraints that are already present in Otext into a single executable prompt (reformatting, reordering, aggregating, resolving conflicts)
-
[4]
Intent-driven expansion:injecting additional structure, detail, and style into p that is not specified in Otext or Oimg but is consistent with the abstract intentI
-
[5]
keep the composition but change the mood
Visual-to-textual encoding:describing aspects of Oimg (composition, layout, style, key objects) in text so that they can be realized byM. By construction, every non-trivial contribution to p must belong to exactly one of these three cases: it either reorganizes information already in Otext, introduces new information from I, or encodes information from Oi...
work page 1999
-
[6]
Impossible to execute reliably
Instructional Clarity(Grammar, logic, lack of ambiguity, structure) •1 (Failure):Incoherent, contradictory, or grammatically broken. Impossible to execute reliably. •2 (Poor):Significant confusion or conflicting instructions. Logic is hard to follow. • 3 (Acceptable):Understandable but contains minor ambiguities or loose sentence structure. Requires some ...
-
[7]
Lacks any detail beyond the core subject
Creative Elaboration(Richness, detail, sensory specificity) •1 (Empty):Bare minimum description. Lacks any detail beyond the core subject. •2 (Generic):Uses clich ´ed descriptions. Details are vague (e.g., ”nice background”). •3 (Basic):Provides standard details (color, size) but lacks imagination or sensory depth. •4 (Detailed):Good use of adjectives and...
-
[8]
Terminology Proficiency(Use of visual/artistic vocabulary, model-agnosticism) •1 (Poor):Uses wrong terms, relies on “magic words” (e.g., “4k”, “trending”), or non-visual text. •2 (Naive):Uses artistic terms incorrectly or relies heavily on engine-specific syntax (e.g., –v 6.0) inside the text. •3 (Average):Uses basic visual terms correctly (e.g., “oil pai...
-
[9]
Intent Formalization(Translating abstract goals into concrete visual specs) •1 (Abstract):Pastes abstract concepts (e.g., “a sad vibe”) directly without visual translation. •2 (Mostly Abstract):Slight attempt at visual description, but mostly relies on the model to interpret feelings. •3 (Mixed):Partially translates intent but relies on some abstract desc...
-
[10]
34 AtelierEval •2 (Weak):The mood is barely present or confusing
Mood & Atmosphere(Emotional tone, consistency with intent) •1 (Mismatch):The image conveys the completely wrong emotion or has no discernible atmosphere. 34 AtelierEval •2 (Weak):The mood is barely present or confusing. •3 (Generic):The mood is somewhat aligned but weak or inconsistent. Lacks strong emotional impact. •4 (Strong):The atmosphere is clear an...
-
[11]
Visual Composition(Structure, balance, focus, depth) •1 (Chaotic):Cluttered, lacks a focal point, or poor spatial arrangement. Hard to parse. •2 (Unbalanced):Elements feel randomly placed. Poor use of space. •3 (Standard):Functional composition. Center-focused or basic rule-of-thirds, but lacks depth or dynamic flow. •4 (Good):Clear focal point and good b...
-
[12]
Looks washed out or oversaturated
Color & Lighting(Harmony, direction, saturation, physics) •1 (Bad):Clashing colors, flat lighting, or physically impossible shadows. Looks washed out or oversaturated. •2 (Dull):Colors are muddy or lighting makes the subject hard to see. •3 (Passable):Lighting is logical but flat. Colors are acceptable but not distinct or strictly harmonized. •4 (Cohesive...
-
[13]
Technical Flawlessness(Artifacts, distortions, anatomy, rendering) • 1 (Broken):Severe artifacts (mangled hands, extra limbs), blurred boundaries, or distinct digital noise. Unusable. •2 (Obvious Flaws):Distracting distortions or mutations are immediately visible. • 3 (Minor Flaws):Generally good, but contains noticeable small artifacts, slight perspectiv...
-
[14]
Go through EVERY checklist item. Do not skip any item. 37 AtelierEval
-
[15]
For each item, output 1 if the requirement is clearly and explicitly specified in the prompt; otherwise output 0
-
[17]
Do NOT add, remove, or modify any checklist item text. Required Output Format (example): {“Checklist item text 1”: 1, “Checklist item text 2”: 0} Now read the prompt carefully and output ONLY the JSON object. Image Objective Skill Template System Prompt:You are a strict visual checklist evaluator. You MUST follow these rules: • You MUST evaluate EACH chec...
- [18]
-
[19]
For each item, output 1 if the requirement is clearly satisfied by the image; otherwise output 0
-
[20]
Your final answer MUST be ONLY a single valid JSON object
-
[21]
Do NOT add, remove, or modify any checklist item text. Required Output Format (example): {“Checklist item text 1”: 1, “Checklist item text 2”: 0} Now examine the image and output ONLY the JSON object. 38 AtelierEval K. Model Hyperparameters MLLMs.The following hyperparameters are shared by all MLLMs used in our experiments, both when acting as prompters a...
work page 2025
-
[22]
INTRODUCTION You are invited to participate in an academic study aimed at establishing a standardized benchmark for evaluatingPrompting Proficiencyin the era of Generative AI. Your participation will provide critical data to understand how humans translate visual intent into textual instructions compared to AI. This study is conducted entirely in English ...
-
[23]
PROCEDURES If you agree to participate in this study, you will be asked to complete the following steps: • Pre-Test Screening:You will first complete a brief questionnaire (approx. 5–10 minutes) regarding your experience with Text-to-Image tools and background. This ensures you meet the study’s criteria and allows us to categorize participants into “Novic...
work page 1920
-
[24]
RISKS • Risks:As approved by the IRB, the risks associated with this study are minimal. You may experience some stress or frustration if the generated images do not meet your expectations, which is a common occurrence in generative AI. All provided images and task descriptions are screened to eliminate any harmful contents. You may contact us if you find ...
-
[25]
COMPENSATION Upon completion of all 30 tasks and the questionnaires, novice participants will receive a compensation of 12 USD (or the equivalent in local currency), while skilled participants will receive 50 USD. Payments can be processed via Amazon Gift Card, Zelle, Alipay, or WeChat Pay, with the specific method to be coordinated with each participant ...
-
[26]
• Anonymous Access:To ensure your anonymity, you will not use your personal HuggingFace account
CONFIDENTIALITY We will take strict measures to protect your privacy. • Anonymous Access:To ensure your anonymity, you will not use your personal HuggingFace account. You will be provided with a uniformly assigned, anonymous HuggingFace account to access HuggingFace Space for the Gradio-based user interface for the tasks. The credentials for this account ...
-
[27]
You may withdraw at any time without penalty
VOLUNTARYPARTICIPATION Your participation is voluntary. You may withdraw at any time without penalty. T.2. Pre-Test Questionnaire The following questionnaire was administered to screen and assign participants.This questionnaire is designed to understand your background to ensure you meet the participation criteria for this study and to assign you to the m...
-
[28]
A cat sitting on a bench, sunny day
Knowledge Check: Which of the following concepts can you confidently explain or use? (Check all that apply) This helps us gauge your technical and artistic depth. •Technical:Seed / Randomness •Technical:CFG Scale (Classifier-Free Guidance) •Technical:Checkpoints / Base Models / LoRA / Embeddings / Textual Inversion •Artistic:Composition Rules (e.g., Rule ...
-
[29]
Ecological realism:Simulates the unpredictable variety of real-world creative demands that professional prompters encounter in practice. U.3. Task Type Interfaces Having authenticated and understood the overall assessment structure, participants proceed to the core evaluation component. The following subsections describe the three task types that particip...
-
[30]
Realistic task scenarios:All tasks are grounded in authentic professional use cases, from creative briefs to technical specifications to visual reproduction challenges
-
[31]
Professional-grade interface:The Gradio-based UI mirrors industry-standard text-to-image platforms, ensuring participants interact with familiar design patterns and workflows
-
[32]
Authentic cognitive demands:Time constraints, task complexity, and the need for multifaceted decision-making reflect real-world prompting scenarios
-
[33]
Naturalistic interaction patterns:Participants construct prompts without artificial restrictions, using their own vocabulary, style, and problem-solving approaches. The combination of randomized task presentation and comprehensive data collection enables rigorous assessment of prompting proficiency across multiple skill dimensions while controlling for po...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.