Catalog-based detection of unrecognized blends in deep optical ground based imaging
Pith reviewed 2026-05-25 08:17 UTC · model grok-4.3
The pith
Machine learning on catalog colors, magnitudes and sizes can flag 30 to 80 percent of unrecognized blends while rejecting 10 to 50 percent of all detected galaxies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Catalog-based machine learning algorithms can identify approximately 30% to 80% of unrecognized blends in the ground-based COSMOS catalog while rejecting 10% to 50% of detected galaxies, using only colors, magnitudes, and size information, with HST data serving as the truth label. Some blends remain hard to flag from catalog data alone. The approach improves sample purity and yields similar performance with optical bands only.
What carries the argument
Machine learning classifiers (Self Organizing Map, Random Forest, k-Nearest Neighbors, Anomaly Detection) trained on 9-band photometry plus i-band flux_radius to separate unrecognized blends from single objects.
If this is right
- The methods can be used to improve sample purity for cosmological analyses.
- Performance remains similar when only optical bands and size information are available.
- Algorithms targeting color outliers remove photo-z outliers more effectively than blend-targeted algorithms.
- The approach offers a cleaner galaxy sample with lower blending rates for surveys such as LSST, potentially improving cosmological parameter constraints at moderate cost to precision.
- Catalog-level information alone suffices to flag a useful fraction of blends without high-resolution imaging.
Where Pith is reading between the lines
- If domain shift proves small, the same trained models could be applied directly to LSST catalog data without new high-resolution labels.
- The technique might be stacked with existing deblending or morphological cuts to raise overall blend recovery above the reported 30-80 percent range.
- Retraining on survey-specific photometry could mitigate any generalization loss when moving beyond the COSMOS field.
Load-bearing premise
The HST-based labels accurately identify unrecognized blends in the ground-based COSMOS catalog, and the trained models generalize to other fields and surveys without significant domain shift.
What would settle it
A test set from an independent ground-based field with new HST or equivalent high-resolution truth labels that yields blend detection rates outside the 30-80 percent range at comparable rejection fractions would falsify the performance numbers.
Figures



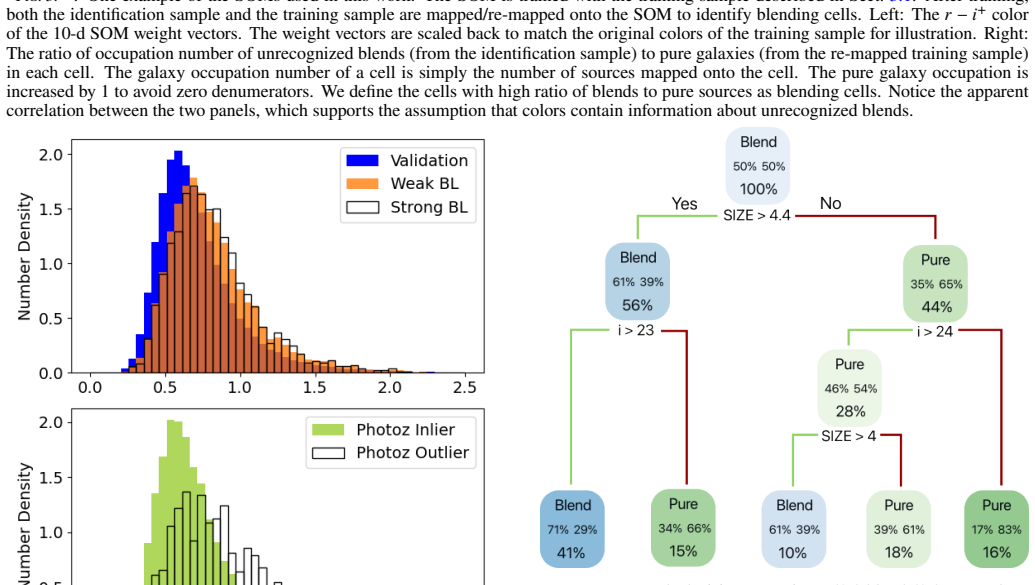











read the original abstract
In deep, ground-based imaging, about 15%-30% of object detections are expected to correspond to two or more true objects - these are called ``unrecognized blends''. We use Machine Learning algorithms to detect unrecognized blends in deep ground-based photometry using only catalog-level information: colors, magnitude, and size. We compare the performance of Self Organizing Map, Random Forest, k-Nearest Neighbors, and Anomaly Detection algorithms. We test all algorithms on 9-band ($uBVri^{+}z^{++}YJH$) and 1-size (flux_radius in $\textit{i}$-band) measurements of the ground-based COSMOS catalog, and use COSMOS HST data as the truth for unrecognized blend. We find that 17% of objects in the ground-based COSMOS catalog are unrecognized blends. We show that some unrecognized blends can be identified as such using only catalog-level information; but not all blends can be easily identified. Nonetheless, our methods can be used to improve sample purity, and can identify approximately 30% to 80% of unrecognized blends while rejecting 10% to 50% of all detected galaxies (blended or unblended). The results are similar when only optical bands ($uBVri^{+}z^{++}$) and the size information is available. We also investigate the ability of these algorithms to remove photo-z outliers (identified with spectroscopic redshifts), and find that algorithms targeting color outliers perform better than algorithms targeting unrecognized blends. Our method can offer a cleaner galaxy sample with lower blending rates for future cosmological surveys such as the Legacy Survey of Space and Time (LSST), and can potentially improve the accuracy on cosmological parameter constraints at a moderate cost of precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that machine learning algorithms (Self Organizing Map, Random Forest, k-Nearest Neighbors, Anomaly Detection) applied to catalog-level colors, magnitudes, and sizes from 9-band (or optical-only) ground-based COSMOS photometry can detect unrecognized blends, using HST data as truth labels. It reports that 17% of ground-based detections are unrecognized blends and that the methods recover approximately 30% to 80% of them while rejecting 10% to 50% of all detected galaxies, with potential benefits for sample purity and photo-z outlier removal in surveys like LSST.
Significance. If the central performance claims hold after validation, the catalog-only approach would provide a practical, low-overhead tool for reducing blending-induced biases in cosmological analyses from wide-field ground-based data. The use of external HST truth labels is a methodological strength that avoids circularity in the detection task itself.
major comments (3)
- [Abstract and results sections] Abstract and results: the quoted recovery rates (30% to 80% blend identification at 10% to 50% rejection) are presented without error bars, cross-validation statistics, train/test split details, or explicit methodology for computing the fractions, which directly undermines assessment of the central performance claim.
- [Data and validation sections] HST labeling procedure: the manuscript treats COSMOS HST deblending as definitive ground truth for unrecognized blends without any quantified error rate, agreement metric with ground-based footprints, or sensitivity test to HST depth/seeing differences; this assumption is load-bearing for all reported metrics.
- [Discussion and conclusions] Generalization to LSST: no domain-shift experiments are described (all training/testing occurs within the single COSMOS field), yet the conclusion emphasizes applicability to other surveys and depths; this leaves the primary claimed use case untested.
minor comments (2)
- [Abstract] The statement that '17% of objects in the ground-based COSMOS catalog are unrecognized blends' lacks a reference to the exact selection or counting procedure used to obtain this fraction.
- [Methods] Clarify whether the anomaly detection and SOM implementations use the same feature normalization and hyperparameter choices as the supervised methods, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments on our manuscript. We have reviewed each major point carefully and provide point-by-point responses below, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract and results sections] Abstract and results: the quoted recovery rates (30% to 80% blend identification at 10% to 50% rejection) are presented without error bars, cross-validation statistics, train/test split details, or explicit methodology for computing the fractions, which directly undermines assessment of the central performance claim.
Authors: We agree that additional statistical details are needed for a full assessment of the performance claims. The original manuscript describes the algorithms and overall approach but does not prominently report error bars, explicit train/test split ratios, or the precise fraction computation method. In the revised manuscript we will add error bars computed via 5-fold cross-validation, specify the data partitioning procedure, and include a methods subsection detailing how the recovery and rejection fractions are calculated from the confusion matrices. These changes will be reflected in both the abstract and results sections. revision: yes
-
Referee: [Data and validation sections] HST labeling procedure: the manuscript treats COSMOS HST deblending as definitive ground truth for unrecognized blends without any quantified error rate, agreement metric with ground-based footprints, or sensitivity test to HST depth/seeing differences; this assumption is load-bearing for all reported metrics.
Authors: The referee correctly notes that the HST-based labels are treated as ground truth without quantified uncertainty. While HST resolution is the standard reference for blend identification in COSMOS, we did not include an error-rate estimate or sensitivity tests in the submitted version. We will revise the data and validation sections to add a dedicated paragraph discussing the limitations of this assumption, citing existing literature on HST deblending completeness where available, and performing a limited sensitivity check by varying the HST magnitude limit used for truth labels. Full external validation of HST label errors would require additional datasets beyond the scope of the current work. revision: partial
-
Referee: [Discussion and conclusions] Generalization to LSST: no domain-shift experiments are described (all training/testing occurs within the single COSMOS field), yet the conclusion emphasizes applicability to other surveys and depths; this leaves the primary claimed use case untested.
Authors: We acknowledge that all experiments were confined to the COSMOS field, as it is the only publicly available dataset combining the required deep ground-based multi-band photometry with high-resolution HST imaging for truth labels. No domain-shift tests across fields or depths were performed. In the revised discussion and conclusions we will temper the language on LSST applicability, explicitly state that COSMOS serves as a proof-of-concept with comparable optical depths, and recommend future validation on independent fields. This revision clarifies the current scope without overstating generalizability. revision: yes
Circularity Check
No significant circularity; empirical ML performance against external HST labels
full rationale
The paper trains and evaluates standard supervised and unsupervised ML algorithms (Self Organizing Map, Random Forest, k-Nearest Neighbors, anomaly detection) on ground-based COSMOS catalog features (colors, magnitude, size) with COSMOS HST data serving as independent truth labels for unrecognized blends. Reported metrics (17% blend fraction; 30-80% recovery at 10-50% rejection) are direct empirical comparisons of model outputs to these external labels, not reductions of any equation or fitted parameter to its own inputs by construction. No self-definitional relations, fitted-input-as-prediction steps, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the methodology. The derivation chain is self-contained as a data-driven validation exercise against an external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
0 < mag_best < 26.5 . We keep sources that are up to 2 mags fainter than the base COSMOS sample (ip_MAG_AUTO < 24.5 ) to al- low for blending with fainter sources
-
[2]
The large dif- fuse sources would contaminate the matching process 19 for blends if not removed
0 < flux_radius < 10/0.049 We remove sources with negative flux radii, as well as diffuse sources larger than 10 arcsecs. The large dif- fuse sources would contaminate the matching process 19 for blends if not removed. The flux radius is in units of pixels,andtheHSTACSpixelscale 6is0.049arcsec/pix
-
[3]
mu_class = 1 or 2 . The mu_class parameter is a morphology-based star- galaxy separation flag derived from the MU_MAX and MAG_AUTO parameters from SExtractor. We keep galaxies( mu_class = 1 )andpointsources( mu_class = 2 ), and remove “fake” detections withmu_class = 3. A.2. Ground-Based COSMOS Data We apply the following selections on the ground-based CO...
-
[4]
Sourcesthatsatisfythesecutsarekept
FLAG_COSMOS=1& FLAG_HJMCC=0& FLAG_PETER=0. Sourcesthatsatisfythesecutsarekept. Thefirsttwoflags mark sources within the COSMOS area that also have UltraVISTA coverage. The last flag removes saturated sources and masked areas in optical bands
-
[5]
Photometry flags fromSExtractor
b_FLAGS < 4 . Photometry flags fromSExtractor. We keep sources with b_FLAGS = 0, 1 and 2 , which corresponds to isolatedsources,sourceswithbrightneighbors,andrec- ognized blends, respectively. Herebstands for all of the uBVr𝑖+𝑧++YJH bands; sources that satisfy this cut in all bands are kept
-
[6]
Only unsaturated sources in all bands are kept
b_IMAFLAGS_ISO = 0 . Only unsaturated sources in all bands are kept
-
[7]
We remove non-observations in any bands
b_FLUXERR> -99. We remove non-observations in any bands. There are only 8 of them
-
[8]
We remove sources with negative flux radii
FLUX_RADIUS > 0 . We remove sources with negative flux radii
-
[9]
Sources with extremely low surface brightness are re- moved
ip_FLUX_APER3/FLUX_RADIUS2 < 0.002 . Sources with extremely low surface brightness are re- moved
-
[10]
Morphology classification based on NIR or3.6 µm ob- servation
TYPE = 0 . Morphology classification based on NIR or3.6 µm ob- servation. Only galaxies are kept
-
[11]
ip_MAG_AUTO < 24.5 . This magnitude cut at𝑖+ < 24.5 is limited by the depth of the “truth” catalog – the HST COSMOS catalog. We allow galaxies to blend with sources up to 2 magnitude fainter, and the HST COSMOS catalog is complete at ∼ 26.5
-
[12]
ZPDF > 0 . The COSMOS 30 band photo-z estimated with galaxy SED templates, measured at the median of the likeli- hood distributions. Only sources with positive photo-z measurement are used for training. 6https://hst-docs.stsci.edu/acsdhb/chapter-1-acs-overview/ 1-1-instrument-design-and-capabilities A.3. Spectroscopy Data Weassembleaspectroscopysamplefrom...
-
[13]
zCOSMOS(Lillyetal.2009;Knobeletal.2012): zCOS- MOS is a large survey in the COSMOS field conducted with the VIMOS spectrograph on the Very Large Tele- scope (VLT). The survey is designed to characterize the galaxyenvironmentsandproducediagnosticinformation on the galaxies and active galactic nuclei. We download the zCOSMOS DR3 catalog which contains 20689...
work page 2009
-
[14]
DEIMOS (Hasinger et al. 2018; Mallery et al. 2012): The COSMOS DEIMOS Catalog consists of 10718 ob- jects in the COSMOS field, observed through multi- slit spectroscopy with the Deep Imaging Multi-Object Spectrograph (DEIMOS) on the Keck II telescope. We keep sources with a quality flagQ = 2 or 1.5, represent- ing reliable spectroscopic identification or ...
work page 2018
-
[15]
C3R2 (Masters et al. 2017, 2019; Stanford et al. 2021; Euclid Collaboration et al. 2022): The Complete Cali- bration of the Color-Redshift Relation (C3R2) is a spec- troscopicsurveyatdepth 𝑖 ∼ 24.5. C3R2aimstofillout the galaxy color space with spectroscopic redshifts, to provide a firm foundation for photometric-redshift cali- bration for upcoming weak l...
work page 2017
-
[16]
VUDS (Le Fèvre et al. 2015; Tasca et al. 2017): The VIMOS Ultra Deep Survey (VUDS) is a spectroscopic redshiftsurveyof ∼ 10000veryfaintgalaxiestostudythe majorphaseofgalaxyassembly. VUDScovers3separate fields: COSMOS, ECDFS and VVDS-02h, providing an additional 384 sources in the COSMOS field. We keep only 144 sources withzflags = 3 or 4, which havemodera...
work page 2015
-
[17]
DESI EDR (DESI Collaboration et al. 2023): The Early Data Release of the Dark Energy Spectroscopic Instru- ment (DESI) contains 1.2 million extra-galactic sources 7https://irsa.ipac.caltech.edu/data/COSMOS/spectra/z-cosmos/ zCOSMOS_DR3.pdf 20 Fig. 14.—. Comparison of Logarithmic magnitude and asinh Lupti- tude in the COSMOS𝑖+band. The magnitude uncertaint...
work page 2023
-
[18]
The Mahalanobis distance is a measure of how many standard deviations a datum is from a distribution
Elliptical Envelope- EE is an unsupervised algorithm that identifies outliers with a Mahalanobis distance greater than some threshold (Rousseeuw 1984, 1985). The Mahalanobis distance is a measure of how many standard deviations a datum is from a distribution. 𝑑EE = √︃ ( ®𝑥 − ®𝜇)𝑇 𝐶 −1 ( ®𝑥 − ®𝜇). While EE is unsupervised, we use the pure galaxies to estim...
work page 1984
-
[19]
Local Outlier Factor - LOF is an unsupervised al- gorithm that detects outliers by calculating the local density compared to the nearest neighbors for a data point that was first described in Breunig et al. (2000). Any point that has a low density compared to its near- est neighbors is labelled as an outlier. The density in comparisontoitsneighborsisturne...
work page 2000
-
[20]
IsolationForest -“iForest”isfirstdescribedinLiuetal. (2008). iForest is created by creating random splits between the minimum and maximum of a feature and then counting the number of splits it takes to uniquely label a datum, the path length. iForest operates by assumingthatoutlierswillhaveashorterpathlengthto isolate them into a terminal node with no oth...
work page 2008
-
[21]
OneClassSupportVectorMachine -OneClassSVM is described in Schölkopf et al. (2001). This is an unsupervised outlier detector that attempts to create a bounded region (hypersphere) in parameter space that encloses the majority of points which are thought to be inliers. Oneadvantagewiththismethodistheabilityto specify a kernel according to any underlying geo...
work page 2001
-
[22]
10+10, Euclidean: using Euclidean Distance instead of 𝜒2 distance (equation [4]) for training the SOM and for mapping objects onto the SOM
-
[23]
10+10, Blends: using both the pure training sample and the identification sample to train the SOM
-
[24]
Alternative Configurations for RF:
10+10, Counts: Removing cells based on the counts of blends in the cell instead of the ratio of blends to pure galaxies in the cell. Alternative Configurations for RF:
-
[25]
Create a regression forest that outputs a score between 0 to 1
10+10, Regression: using 10 features for training and testing and treating the labels as integers (0 for pure and 1 for blends). Create a regression forest that outputs a score between 0 to 1. The main text uses a classification forest which is then turned into a score by counting the numberoftreesvotingfor“pure”asoutlinedinSect.3.2. This method directly ...
-
[26]
10+10, 2-class: using 10 features for training and test- ing on a classification forest with the labels “pure” and “blend.” The main text gives three labels: “pure”, “weak”, “strong.”
-
[27]
These alternative configurations are displayed in Fig
19+19,trainingwithphotometricuncertainties: using19 features for training and testing with the features being 8 colors, 8 color errors, 1magnitude, 1 magnitude error, and flux radius. These alternative configurations are displayed in Fig. 17. We found no evident change in performance in any cases. ThispaperwasbuiltusingtheOpenJournalofAstrophysics LATEX t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.