Modality-Decoupled Online Recursive Editing
Pith reviewed 2026-05-21 08:41 UTC · model grok-4.3
The pith
M-ORE separates text and visual updates in online MLLM editing to cut cross-modal conflicts and long-term interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
M-ORE is derived from a unified proximal-projection formulation and admits a closed-form update with a Sherman-Morrison recursion, yielding constant per-edit overhead. It maintains module-wise locality statistics for the text stack and the visual projector to avoid visually dominated update shaping and performs continual updates in a fixed orthogonal low-rank edit subspace via a Sherman-Morrison recursion to mitigate long-horizon interference.
What carries the argument
Modality-decoupled recursive update that keeps separate locality statistics for text and visual modules and recurses inside one fixed orthogonal low-rank edit subspace.
If this is right
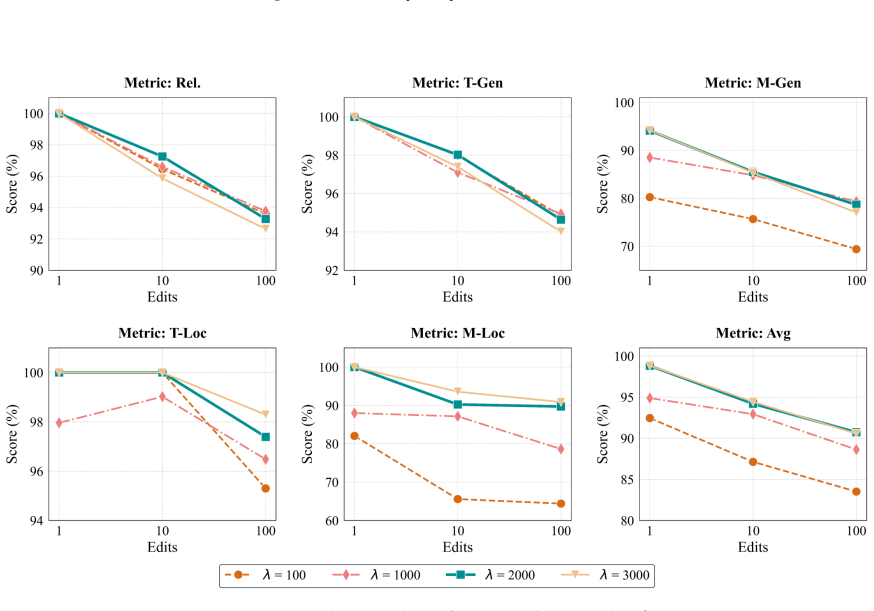
- Reliability, generality, and locality all rise over strong baselines on several MLLM backbones.
- Quality-efficiency trade-off improves because each edit costs constant compute and memory.
- Cross-modal conflicts shrink by isolating visual projector statistics from text-stack statistics.
- Long-horizon interference drops because every update stays inside the same orthogonal low-rank space.
Where Pith is reading between the lines
- The same separation of statistics could be tested on other multimodal architectures that combine language with images or video.
- If the fixed subspace remains effective after hundreds of edits, the method might support continuous deployment without periodic full resets.
- The recursive form might let practitioners swap in different locality measures without changing the overall update rule.
Load-bearing premise
Keeping module-wise statistics separate for text and vision is enough to stop visual signals from dominating the update direction, and confining all edits to one fixed low-rank subspace prevents interference from building up across many corrections.
What would settle it
A controlled run on an MLLM where a long sequence of edits is applied and locality scores drop or interference rises at the same rate as in baseline editors despite using the decoupled statistics and fixed subspace.
Figures















read the original abstract
Online model editing for multimodal large language models (MLLMs) requires assimilating a stream of corrections under tight compute and memory budgets. Yet editors developed for text-only LLMs often degrade on MLLMs: visually dominant activations skew the statistics that shape updates, causing cross-modal conflict, while sequential writes become entangled in a shared edit space and amplify long-horizon interference, causing inter-edit interference. To address these, we propose M-ORE, a modality-decoupled online recursive editor for lifelong MLLM adaptation. M-ORE is derived from a unified proximal-projection formulation and admits a closed-form update with a Sherman-Morrison recursion, yielding constant per-edit overhead. It maintains module-wise locality statistics for the text stack and the visual projector to avoid visually dominated update shaping and performs continual updates in a fixed orthogonal low-rank edit subspace via a Sherman-Morrison recursion to mitigate long-horizon interference. Experiments on multiple MLLM backbones and online editing benchmarks show that our M-ORE method consistently improves reliability, generality, and locality over strong baselines, while achieving favorable quality-efficiency scaling. Our code is publicly available at https://github.com/lab-klc/M-ORE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces M-ORE, a modality-decoupled online recursive editor for lifelong adaptation of multimodal large language models. Derived from a proximal-projection formulation, it provides a closed-form update via Sherman-Morrison recursion with constant per-edit cost. The method maintains separate locality statistics for the text stack and visual projector to counteract visually dominated shaping and performs continual updates inside a fixed orthogonal low-rank edit subspace to reduce long-horizon inter-edit interference. Experiments across multiple MLLM backbones and online editing benchmarks report consistent gains in reliability, generality, and locality together with favorable quality-efficiency scaling.
Significance. If the central claims are substantiated, the work supplies an efficient, constant-overhead mechanism for online editing of MLLMs that explicitly separates modalities and controls subspace drift. The closed-form recursive update, public code release, and multi-backbone evaluation constitute concrete strengths that would support reproducibility and practical deployment.
major comments (2)
- [§3] §3 (proximal-projection derivation and Sherman-Morrison recursion): the argument that a fixed orthogonal low-rank subspace suffices to eliminate long-horizon interference rests on the unstated assumption that the initial basis vectors remain linearly independent from all subsequent edit directions across both text and visual modules. No re-orthogonalization step or rank-adaptation mechanism is described; when visual activations dominate the covariance, even modest drift can re-introduce the cross-modal conflict the method claims to avoid.
- [Experimental section] Experimental section (locality metrics and benchmark protocol): the reported improvements in locality are presented without accompanying statistical significance tests or explicit description of the data-exclusion rules used to compute the metrics. Because the central claim of reduced inter-edit interference depends on these quantities, the absence of verifiable protocol details prevents independent confirmation of the gains.
minor comments (2)
- [Abstract] The abstract states that the method achieves 'favorable quality-efficiency scaling' yet does not define the concrete quality and efficiency metrics plotted in the scaling figures.
- [§3.1] Notation for the module-wise locality statistics (text stack versus visual projector) is introduced without an explicit equation linking the two separate covariance estimates to the final update direction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating planned revisions to strengthen the work.
read point-by-point responses
-
Referee: [§3] §3 (proximal-projection derivation and Sherman-Morrison recursion): the argument that a fixed orthogonal low-rank subspace suffices to eliminate long-horizon interference rests on the unstated assumption that the initial basis vectors remain linearly independent from all subsequent edit directions across both text and visual modules. No re-orthogonalization step or rank-adaptation mechanism is described; when visual activations dominate the covariance, even modest drift can re-introduce the cross-modal conflict the method claims to avoid.
Authors: We appreciate the referee highlighting this implicit assumption in the proximal-projection derivation. The fixed orthogonal low-rank subspace is initialized once from the initial edit directions and all subsequent updates are performed strictly inside it via the Sherman-Morrison recursion, which by design keeps new edits orthogonal to prior ones within the subspace. Modality decoupling maintains separate statistics for text and visual modules precisely to limit visual dominance from propagating into the shared subspace. We agree that sustained linear independence across modules is assumed without explicit re-orthogonalization (to preserve constant overhead and the fixed-subspace property). In the revision we will expand §3 to state this assumption explicitly, discuss its validity under the low-rank constraint, and note the theoretical possibility of drift in extreme cases. revision: yes
-
Referee: [Experimental section] Experimental section (locality metrics and benchmark protocol): the reported improvements in locality are presented without accompanying statistical significance tests or explicit description of the data-exclusion rules used to compute the metrics. Because the central claim of reduced inter-edit interference depends on these quantities, the absence of verifiable protocol details prevents independent confirmation of the gains.
Authors: We agree that statistical significance testing and transparent protocol details are necessary to substantiate the locality claims. In the revised manuscript we will add appropriate statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) to the locality results across benchmarks. We will also provide a clear description of the data-exclusion criteria, exact metric computation formulas, and full benchmark protocol in the experimental section or a new appendix subsection to enable independent verification. revision: yes
Circularity Check
Derivation relies on standard proximal projection and Sherman-Morrison identity; no reduction to inputs
full rationale
The paper states that M-ORE is derived from a unified proximal-projection formulation and admits a closed-form update with Sherman-Morrison recursion. Sherman-Morrison is an external, well-known linear algebra identity independent of the paper's data or fitted parameters. Module-wise locality statistics and the fixed orthogonal low-rank subspace are explicit design choices motivated by the problem of cross-modal interference, not quantities defined in terms of the target predictions or fitted to the evaluation benchmarks. No self-citations, ansatzes, or uniqueness theorems from prior author work are invoked as load-bearing justifications in the provided text. The central claims rest on the proposed mechanisms plus experimental results on external benchmarks, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- edit subspace rank
axioms (1)
- standard math Sherman-Morrison formula yields exact rank-one update recursion
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Lifelong knowledge editing for LLMs with retrieval-augmented continuous prompt learning
Chen, Q., Zhang, T., He, X., Li, D., Wang, C., Huang, L., and Xue’, H. Lifelong knowledge editing for LLMs with retrieval-augmented continuous prompt learning. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 13565– 13580,
work page 2024
-
[3]
Microsoft COCO Captions: Data Collection and Evaluation Server
Chen, Q., Wang, C., Wang, D., Zhang, T., Li, W., and He, X. Lifelong knowledge editing for vision language models with low-rank mixture-of-experts. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 9455–9466, 2025a. Chen, Q., Zhang, T., Wang, C., He, X., Wang, D., and Liu, T. Attribution analysis meets model editing: Ad- ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Cheng, S., Tian, B., Liu, Q., Chen, X., Wang, Y ., Chen, H., and Zhang, N. Can we edit multimodal large lan- guage models? InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 13877–13888,
work page 2023
-
[5]
Editing factual knowl- edge in language models
De Cao, N., Aziz, W., and Titov, I. Editing factual knowl- edge in language models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP),
work page 2021
-
[6]
BERT: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics(NAACL), pp. 4171–4186,
work page 2019
-
[7]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y ., Qin, Y ., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y ., Ji, R., Shan, C., and He, R. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Transformer feed-forward layers are key-value memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. InProceed- ings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5484–5495,
work page 2021
-
[9]
Model editing harms general abilities of large language models: Regularization to the rescue
Gu, J.-C., Xu, H.-X., Ma, J.-Y ., Lu, P., Ling, Z.-H., Chang, K.-W., and Peng, N. Model editing harms general abilities of large language models: Regularization to the rescue. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 16801–16819,
work page 2024
-
[10]
Llms meet multimodal generation and editing: A survey.arXiv preprint arXiv:2405.19334,
He, Y ., Liu, Z., Chen, J., Tian, Z., Liu, H., Chi, X., Liu, R., Yuan, R., Xing, Y ., Wang, W., Dai, J., Zhang, Y ., Xue, W., Liu, Q., Guo, Y ., and Chen, Q. Llms meet multimodal generation and editing: A survey.arXiv preprint arXiv:2405.19334,
-
[11]
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Liang, G., Wang, Z., Hu, J., Zhou, H., Xue, Z., Zhang, J., Xu, D., and Yu, Q. Render-in-the-loop: Vector graph- ics generation via visual self-feedback.arXiv preprint arXiv:2604.20730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Video-llava: Learning united visual representation by alignment before projection
Lin, B., Ye, Y ., Zhu, B., Cui, J., Ning, M., Jin, P., and Yuan, L. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing (EMNLP), pp. 5971–5984,
work page 2024
-
[13]
Chordedit: One-step low-energy transport for image edit- ing.arXiv preprint arXiv:2602.19083,
Lu, L., Chen, X., Guo, M., Li, S., Wang, J., and Shi, Y . Chordedit: One-step low-energy transport for image edit- ing.arXiv preprint arXiv:2602.19083,
-
[14]
Mitchell, E., Lin, C., Bosselut, A., Finn, C., and Manning, C. D. Fast model editing at scale. InProceedings of the International Conference on Learning Representations (ICLR), 2022a. Mitchell, E., Lin, C., Bosselut, A., Manning, C. D., and Finn, C. Memory-based model editing at scale. InProceedings of the International Conference on Machine Learning (ICM...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Shi, Y ., Xie, Y ., Guo, M., Lu, L., Huang, M., Wang, J., Zhu, Z., Xu, B., and Huang, Z. Mmerror: A benchmark for erroneous reasoning in vision-language models.arXiv preprint arXiv:2601.03331,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024a. Wang, P., Li, Z., Zhang, N., Xu, Z., Yao, Y ., Jiang, Y ., Xie, P., Huang, F., and Chen, H. WISE: rethinking the knowl- edge memory...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
A Comprehensive Study of Knowledge Editing for Large Language Models
Zhang, N., Yao, Y ., Tian, B., Wang, P., Deng, S., Wang, M., Xi, Z., Mao, S., Zhang, J., Ni, Y ., Cheng, S., Xu, Z., Xu, X., Gu, J.-C., Jiang, Y ., Xie, P., Huang, F., Liang, L., Zhang, Z., Zhu, X., Zhou, J., and Chen, H. A compre- hensive study of knowledge editing for large language models.arXiv preprint arXiv:2401.01286,
-
[19]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., Mi- haylov, T., Ott, M., Shleifer, S., Shuster, K., Simig, D., Koura, P. S., Sridhar, A., Wang, T., and Zettlemoyer, L. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A Survey of Large Language Models
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models.arXiv preprint arXiv:2303.18223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Zheng, C., Li, L., Dong, Q., Fan, Y ., Wu, Z., Xu, J., and Chang, B. Can we edit factual knowledge by in- context learning? InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4862–4876,
work page 2023
-
[22]
12 Modality-Decoupled Online Recursive Editing Appendix A. Experimental Setup In this section, we provide detailed descriptions of experimental setup, including introduction to datasets, explanation of evaluation metrics and editing objective, discussion of baseline methods and implementation details. A.1. Datasets • E-VQA (Cheng et al., 2023):Designed fo...
work page 2023
-
[23]
for E-VQA and manually written prompt templates for E-IC. Visual generality is assessed using reinterpreted images generated by Stable Diffusion 2.1 (Rombach et al., 2022). – Locality:Textual locality is evaluated using NQ (Kwiatkowski et al., 2019), and multimodal locality is evaluated using OK-VQA (Marino et al., 2019), measuring whether unrelated knowl...
work page 2022
-
[24]
IKE.In-Context Knowledge Editing (Zheng et al.,
and the counterfactual model with OPT-125M (Zhang et al., 2022). IKE.In-Context Knowledge Editing (Zheng et al.,
work page 2022
-
[25]
Given a target fact pair (x∗, y∗), IKE retrieves k demonstrations C= {c1,
performs editing byretrieval-augmented in-context prompting, without directly updating model parameters. Given a target fact pair (x∗, y∗), IKE retrieves k demonstrations C= {c1, . . . , ck} from a training set using an unsupervised retriever (e.g., cosine similarity), and concatenates them as in-context examples to guide generation. The demonstrations ar...
work page 2023
-
[26]
to ensure a fair comparison under identical edit scopes. AlphaEdit configuration and multimodal K0.For AlphaEdit, we adopt the hyperparameters recommended in the original paper (Fang et al., 2025). To estimate the retain key set K0 for MLLMs, we build K0 using samples from E-VQA and E-IC (Cheng et al., 2023), so that both visual and textual knowledge are ...
work page 2025
-
[27]
contains 14 evaluation categories. The main paper reports six representative tasks for brevity, while we provide the remaining eight categories here to complete the benchmark: •Artwork: evaluates understanding of artistic images and stylized visual content. •Celebrity: tests recognition and reasoning about well-known public figures in images. •Color: meas...
work page 2000
-
[28]
As shown, flipped cases tend to have smaller pre-edit top1–top2 margins, indicating thatthey lie near fragile decoding boundaries and can be affected by small distributional shifts. For multimodal locality, flipped cases also show higher image similarity to the edited sample, suggesting thatimperfect visual irrelevance and residual visual coupling may con...
-
[29]
Rows shaded in light purple indicateparameter-modifyingmethods
denotes the number of online edits performed. Rows shaded in light purple indicateparameter-modifyingmethods. Model Methods E-VQA E-IC Rel. T-Gen. M-Gen. T-Loc. M-Loc. Avg. Rel. T-Gen. M-Gen. T-Loc. M-Loc. Avg. BLIP2-OPT FT-L1 100.00 100.00 60.00 94.74 100.00 90.95 96.77 95.02 90.72 90.05 68.27 88.16 FT-M1 100.00 96.67 63.33 100.00 73.33 86.67 100.00 100....
-
[30]
27 Modality-Decoupled Online Recursive Editing Orig
In each group, the upper panel is the edit sample and the lower panel is the corresponding locality sample. 27 Modality-Decoupled Online Recursive Editing Orig. Base L1 L16 L31 Target: Goodfellas. Prompt: What Hollywood movie is one of the food dishes named after? Answer (Before Editing): One of the food dishes named after a Hollywood movie is the Pizza H...
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.