Best Segmentation Buddies for Image-Shape Correspondence
Pith reviewed 2026-05-20 11:07 UTC · model grok-4.3
The pith
Distilling 2D vision features onto 3D shapes lets Best Segmentation Buddies match image segments to corresponding 3D parts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
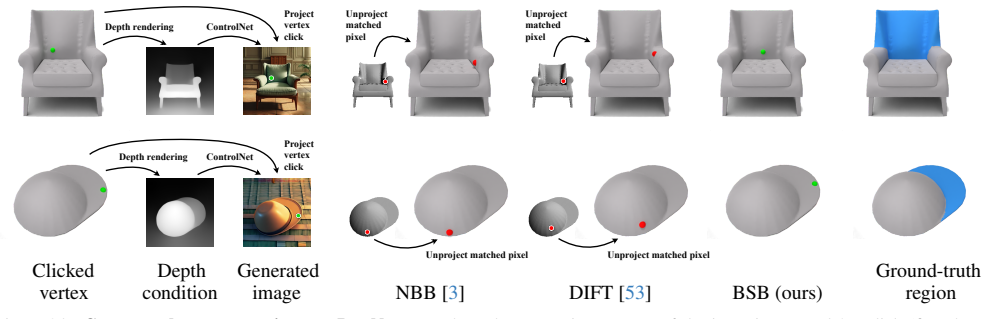
The central claim is that distilling deep visual features from a 2D vision model onto the 3D shape surface allows computation of feature similarity between image pixels and shape vertices. Identifying Best Segmentation Buddies—vertices whose most similar image pixel lies within the image segmentation region—enables reliable discovery of vertices in semantically corresponding shape parts across substantial differences in appearance, geometry, and viewpoint. The distilled features are also used to segment the shape directly in 3D, bootstrapping the correspondence process.
What carries the argument
Best Segmentation Buddies: 3D shape vertices whose nearest feature match in the 2D image falls inside the given image segment, used to locate semantically corresponding parts.
If this is right
- The approach produces accurate and semantically meaningful correspondences for a wide range of image-shape pairs.
- Distilled 3D features from a 2D image segmentation model can be used to segment the untextured 3D shape directly.
- Correspondence remains reliable even when appearance, geometry, and viewpoint vary substantially.
- The bootstrapping step reduces reliance on manual 3D annotations by transferring 2D segmentation knowledge.
Where Pith is reading between the lines
- The same distillation step could be applied frame-by-frame to video, yielding time-consistent 3D part labels.
- The method supplies semantic anchors that might improve registration of 3D scans to casual photographs.
- Testing the buddies on shapes that contain fine surface details or holes would show where feature transfer begins to break.
- Because the 3D segmentation step needs no extra labels, the pipeline could help create large-scale labeled 3D datasets from existing 2D image collections.
Load-bearing premise
The assumption that feature similarity after distillation will place the nearest image pixel inside the correct semantic segment rather than being dominated by viewpoint or geometric differences.
What would settle it
On a collection of image-3D pairs that have hand-labeled ground-truth corresponding segments, count how often the identified Best Segmentation Buddies land outside the correct semantic region; if the error rate is no better than random selection the central claim is false.
Figures






















read the original abstract
Finding correspondences is a fundamental and extensively researched problem in computer vision and graphics. In this work, we examine the underexplored task of estimating segmentation-to-segmentation correspondence between images in the wild and untextured 3D shapes. This task is highly challenging due to substantial differences in appearance, geometry, and viewpoint. Our approach bridges the cross-modality gap by linking pixels in the image segment to vertices in the corresponding semantic part of the 3D shape. To achieve this, we first distill deep visual features from a 2D vision model onto the 3D shape surface, allowing for the computation of feature similarity between image pixels and shape vertices. Then, we identify Best Segmentation Buddies, vertices whose most similar image pixel lies within the image segmentation region, enabling the reliable discovery of vertices in semantically corresponding shape parts. Finally, we leverage distilled 3D features from the 2D image segmentation model to segment the shape directly in 3D, bootstrapping the correspondence process. We demonstrate the generality and robustness of our approach across a wide range of image-shape pairs, showcasing accurate and semantically meaningful correspondences. Our project page is at https://threedle.github.io/bsb/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a pipeline for segmentation-to-segmentation correspondence between in-the-wild 2D images and untextured 3D shapes. It distills features from a pretrained 2D vision model onto the 3D surface, defines Best Segmentation Buddies as the 3D vertices whose nearest image pixel (by distilled feature distance) lies inside a given 2D segment, and uses the resulting correspondences to bootstrap direct 3D segmentation from the image segment. The authors claim the method produces accurate, semantically meaningful matches across large differences in appearance, geometry, and viewpoint.
Significance. If the central claim holds, the work would provide a practical bridge for cross-modal semantic correspondence without requiring texture or dense alignment, which is useful for graphics and vision applications involving untextured meshes. The distillation-plus-nearest-neighbor formulation is conceptually simple and leverages existing 2D models, but its value rests on whether the distilled features actually confer the claimed semantic invariance.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the claim that Best Segmentation Buddies 'reliably discover vertices in semantically corresponding shape parts' is load-bearing, yet the manuscript supplies no quantitative metrics, success rates, or error analysis on any dataset to show that nearest-neighbor matches exceed a viewpoint/geometry baseline.
- [§4] §4 (experiments): no ablation is reported that isolates the distillation step from simply projecting raw 2D features onto the 3D surface; without this comparison it is impossible to verify that the nearest-pixel relation is driven by semantic part identity rather than residual viewpoint or surface-normal effects.
minor comments (2)
- [§3] The notation for feature similarity and the exact distillation procedure (e.g., which layers are used, how projection is performed) could be stated more explicitly with a short equation or pseudocode.
- [Figures] Figure captions and the project-page reference should include the specific image-shape pairs and ground-truth segments used for qualitative demonstration.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional quantitative evaluation and ablation studies as suggested.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the claim that Best Segmentation Buddies 'reliably discover vertices in semantically corresponding shape parts' is load-bearing, yet the manuscript supplies no quantitative metrics, success rates, or error analysis on any dataset to show that nearest-neighbor matches exceed a viewpoint/geometry baseline.
Authors: We agree that the load-bearing claim would benefit from quantitative support. The current manuscript focuses on qualitative demonstrations across diverse in-the-wild image-shape pairs to show semantic correspondence. In the revision we will add quantitative metrics, including precision/recall for vertex-to-segment matching and error analysis on a test set of image-shape pairs with ground-truth annotations, with explicit comparison to a viewpoint/geometry baseline that omits distilled features. revision: yes
-
Referee: [§4] §4 (experiments): no ablation is reported that isolates the distillation step from simply projecting raw 2D features onto the 3D surface; without this comparison it is impossible to verify that the nearest-pixel relation is driven by semantic part identity rather than residual viewpoint or surface-normal effects.
Authors: We concur that isolating the distillation step is necessary to confirm its role in semantic invariance. The revised manuscript will include an ablation that directly compares the full pipeline (with distilled features) against a variant that projects raw 2D features onto the 3D surface without distillation, measuring the impact on nearest-neighbor correspondence accuracy and semantic consistency. revision: yes
Circularity Check
No circularity: pipeline uses external pretrained model and explicit definitions without self-referential reductions.
full rationale
The paper presents a methodological pipeline: distill features from an external 2D vision model onto 3D surfaces, then define Best Segmentation Buddies via nearest-neighbor feature similarity within given 2D segments, and bootstrap 3D segmentation. No equations, fitted parameters, or self-citations are shown that would make the discovered correspondences equivalent to inputs by construction. The approach depends on independent external components and is not a closed derivation that reduces outputs to renamed inputs or prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep visual features extracted by a pretrained 2D vision model remain semantically meaningful when transferred to vertices of an untextured 3D mesh.
invented entities (1)
-
Best Segmentation Buddies
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zero-Shot 3D Shape Correspon- dence
Ahmed Abdelreheem, Abdelrahman Eldesokey, Maks Ovs- janikov, and Peter Wonka. Zero-Shot 3D Shape Correspon- dence. InSIGGRAPH Asia 2023 Conference Papers, pages 1–11, New York, NY , USA, 2023. Association for Comput- ing Machinery. 1, 4
work page 2023
-
[2]
SATR: Zero-Shot Semantic Segmentation of 3D Shapes
Ahmed Abdelreheem, Ivan Skorokhodov, Maks Ovsjanikov, and Peter Wonka. SATR: Zero-Shot Semantic Segmentation of 3D Shapes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 3
work page 2023
-
[3]
Kfir Aberman, Jing Liao, Mingyi Shi, Dani Lischinski, Bao- quan Chen, and Daniel Cohen-Or. Neural Best-Buddies: Sparse Cross-Domain Correspondence.ACM Transactions on Graphics (TOG), 37(4):1–14, 2018. 1, 2, 3, 7, 17, 18, 20
work page 2018
-
[4]
Training-Free Open-V ocabulary Segmentation with Offline Diffusion- Augmented Prototype Generation
Luca Barsellotti, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Training-Free Open-V ocabulary Segmentation with Offline Diffusion- Augmented Prototype Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3689–3699, 2024. 3
work page 2024
-
[5]
D. Boscaini, J. Masci, S. Melzi, M. M. Bronstein, U. Castel- lani, and P. Vandergheynst. Learning Class-Specific Descrip- tors for Deformable Shapes Using Localized Spectral Con- volutional Networks.Computer Graphics Forum, 34(5):13– 23, 2015. 3
work page 2015
-
[6]
Learning Shape Correspondence with Anisotropic Convolutional Neural Networks
Davide Boscaini, Jonathan Masci, Emanuele Rodol `a, and Michael Bronstein. Learning Shape Correspondence with Anisotropic Convolutional Neural Networks. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2016. 3
work page 2016
-
[7]
BRIEF: Binary Robust Independent Elemen- tary Features
Michael Calonder, Vincent Lepetit, Christophe Strecha, and Pascal Fua. BRIEF: Binary Robust Independent Elemen- tary Features. InEuropean conference on computer vision (ECCV), pages 778–792. Springer, 2010. 3
work page 2010
-
[8]
BAE-NET: Branched Autoen- coder for Shape Co-Segmentation
Zhiqin Chen, Kangxue Yin, Matthew Fisher, Siddhartha Chaudhuri, and Hao Zhang. BAE-NET: Branched Autoen- coder for Shape Co-Segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8490–8499, 2019. 3
work page 2019
-
[9]
3D Highlighter: Localizing Regions on 3D Shapes via Text Descriptions
Dale Decatur, Itai Lang, and Rana Hanocka. 3D Highlighter: Localizing Regions on 3D Shapes via Text Descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 20930–20939,
-
[10]
3D Paintbrush: Local Stylization of 3D Shapes with Cas- caded Score Distillation
Dale Decatur, Itai Lang, Kfir Aberman, and Rana Hanocka. 3D Paintbrush: Local Stylization of 3D Shapes with Cas- caded Score Distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4473–4483, 2024. 3, 13
work page 2024
-
[11]
3D PixBrush: Image-Guided Local Texture Synthesis.arXiv preprint arXiv:2507.03731, 2025
Dale Decatur, Itai Lang, Kfir Aberman, and Rana Hanocka. 3D PixBrush: Image-Guided Local Texture Synthesis.arXiv preprint arXiv:2507.03731, 2025. 8
-
[12]
Unsuper- vised Template-assisted Point Cloud Shape Correspondence Network
Jiacheng Deng, Jiahao Lu, and Tianzhu Zhang. Unsuper- vised Template-assisted Point Cloud Shape Correspondence Network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5250–5259, 2024. 3
work page 2024
-
[13]
Deep Geometric Functional Maps: Robust Feature Learning for Shape Correspondence
Nicolas Donati, Abhishek Sharma, and Maks Ovsjanikov. Deep Geometric Functional Maps: Robust Feature Learning for Shape Correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8589–8598, 2020. 1, 3
work page 2020
-
[14]
Beyond Cartesian Representations for Local Descriptors
Patrick Ebel, Anastasiia Mishchuk, Kwang Moo Yi, Pascal Fua, and Eduard Trulls. Beyond Cartesian Representations for Local Descriptors. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 253–262, 2019. 3
work page 2019
-
[15]
Deep Shells: Unsupervised Shape Corre- spondence with Optimal Transport
Marvin Eisenberger, Aysim Toker, Laura Leal-Taix ´e, and Daniel Cremers. Deep Shells: Unsupervised Shape Corre- spondence with Optimal Transport. InAdvances in Neural Information Processing Systems, pages 10491–10502. Cur- ran Associates, Inc., 2020. 3
work page 2020
-
[16]
DensePose: Dense Human Pose Estimation in the Wild
Rıza Alp G ¨uler, Natalia Neverova, and Iasonas Kokkinos. DensePose: Dense Human Pose Estimation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 4
work page 2018
-
[17]
Oshri Halimi, Or Litany, Emanuele Rodola, Alex M. Bron- stein, and Ron Kimmel. Unsupervised Learning of Dense Shape Correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 3
work page 2019
-
[18]
MeshCNN: A Network with an Edge.ACM Transactions on Graphics, 38(4):1–12,
Rana Hanocka, Amir Hertz, Noa Fish, Raja Giryes, Shachar Fleishman, and Daniel Cohen-Or. MeshCNN: A Network with an Edge.ACM Transactions on Graphics, 38(4):1–12,
-
[19]
Unsupervised Semantic Correspondence Using Stable Diffu- sion
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. Unsupervised Semantic Correspondence Using Stable Diffu- sion. InAdvances in Neural Information Processing Systems, pages 8266–8279. Curran Associates, Inc., 2023. 15
work page 2023
-
[20]
COTR: Correspondence Trans- former for Matching Across Images
Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasac- chi, and Kwang Moo Yi. COTR: Correspondence Trans- former for Matching Across Images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6207–6217, 2021. 3
work page 2021
-
[21]
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans. Graph., 42(4):139– 1, 2023. 8
work page 2023
-
[22]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment Anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023. 2, 4, 6, 14, 15
work page 2023
-
[23]
PifPaf: Composite Fields for Human Pose Estimation
Sven Kreiss, Lorenzo Bertoni, and Alexandre Alahi. PifPaf: Composite Fields for Human Pose Estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 4
work page 2019
-
[24]
Canonical Surface Mapping via Geometric Cycle Consis- tency
Nilesh Kulkarni, Abhinav Gupta, and Shubham Tulsiani. Canonical Surface Mapping via Geometric Cycle Consis- tency. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 2202–2211,
-
[25]
Nilesh Kulkarni, Abhinav Gupta, David F. Fouhey, and Shubham Tulsiani. Articulation-Aware Canonical Surface Mapping. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 4
work page 2020
-
[26]
DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction
Itai Lang, Dvir Ginzburg, Shai Avidan, and Dan Raviv. DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction. InProceedings of the International Confer- ence on 3D Vision (3DV), pages 1442–1451, 2021. 3
work page 2021
-
[27]
iSeg: Interactive 3D Segmentation via Interac- tive Attention
Itai Lang, Fei Xu, Dale Decatur, Sudarshan Babu, and Rana Hanocka. iSeg: Interactive 3D Segmentation via Interac- tive Attention. InSIGGRAPH Asia 2024 Conference Papers, page 1–11. Association for Computing Machinery, 2024. 2, 3, 4, 5, 6, 7, 16
work page 2024
-
[28]
SRFeat: Learning Locally Accurate and Globally Consistent Non- Rigid Shape Correspondence
Lei Li, Souhaib Attaiki, and Maks Ovsjanikov. SRFeat: Learning Locally Accurate and Globally Consistent Non- Rigid Shape Correspondence. In2022 International Con- ference on 3D Vision (3DV), pages 144–154, 2022. 3
work page 2022
-
[29]
Or Litany, Tal Remez, Emanuele Rodol`a, Alex M. Bronstein, and Michael M. Bronstein. Deep Functional Maps: Struc- tured Prediction for Dense Shape Correspondence. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5660–5668. IEEE Computer Society,
-
[30]
OpenShape: Scaling Up 3D Shape Representation To- wards Open-World Understanding
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xu- anlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. OpenShape: Scaling Up 3D Shape Representation To- wards Open-World Understanding. InAdvances in Neural Information Processing Systems, pages 44860–44879. Cur- ran Associates, Inc., 2023. 4
work page 2023
-
[31]
PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image- Language Models
Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, and Hao Su. PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image- Language Models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 21736–21746, 2023. 3
work page 2023
-
[32]
David G Lowe. Distinctive Image Features from Scale- Invariant Keypoints.International Journal of Computer Vi- sion, 60(2):91–110, 2004. 3
work page 2004
-
[33]
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holyn- ski, and Trevor Darrell. Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence. In Advances in Neural Information Processing Systems, 2023. 15
work page 2023
-
[34]
Bronstein, and Pierre Vandergheynst
Jonathan Masci, Davide Boscaini, Michael M. Bronstein, and Pierre Vandergheynst. Geodesic Convolutional Neural Networks on Riemannian Manifolds. InProceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, pages 37–45, 2015. 3
work page 2015
-
[35]
SHREC 2019: Matching Humans with Different Connectivity
Simone Melzi, Riccardo Marin, Emanuele Rodol `a, Umberto Castellani, Jing Ren, Adrien Poulenard, Peter Wonka, and Maks Ovsjanikov. SHREC 2019: Matching Humans with Different Connectivity. InEurographics Workshop on 3D Object Retrieval, page 3. The Eurographics Association,
work page 2019
-
[36]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. InProceedings of the European Conference on Computer Vision (ECCV), pages 405–421, 2020. 8
work page 2020
-
[37]
Working hard to know your neighbor’s mar- gins: Local descriptor learning loss
Anastasiya Mishchuk, Dmytro Mishkin, Filip Radenovic, and Jiri Matas. Working hard to know your neighbor’s mar- gins: Local descriptor learning loss. InAdvances in Neural Information Processing Systems, pages 4826–4837. Curran Associates, Inc., 2017. 3
work page 2017
- [38]
-
[39]
Chang, Li Yi, Sub- arna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Sub- arna Tripathi, Leonidas J. Guibas, and Hao Su. PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchi- cal Part-Level 3D Object Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 909–918, 2019. 6, 7, 16
work page 2019
-
[40]
Continu- ous Surface Embeddings
Natalia Neverova, David Novotny, Marc Szafraniec, Vasil Khalidov, Patrick Labatut, and Andrea Vedaldi. Continu- ous Surface Embeddings. InAdvances in Neural Information Processing Systems, pages 17258–17270. Curran Associates, Inc., 2020. 1, 4, 7
work page 2020
-
[41]
Discovering Rela- tionships between Object Categories via Universal Canoni- cal Maps
Natalia Neverova, Artsiom Sanakoyeu, Patrick Labatut, David Novotny, and Andrea Vedaldi. Discovering Rela- tionships between Object Categories via Universal Canoni- cal Maps. In2021 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 404–413, Los Alamitos, CA, USA, 2021. IEEE Computer Society. 4
work page 2021
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Neural Parts: Learning Expres- sive 3D Shape Abstractions with Invertible Neural Networks
Despoina Paschalidou, Angelos Katharopoulos, Andreas Geiger, and Sanja Fidler. Neural Parts: Learning Expres- sive 3D Shape Abstractions with Invertible Neural Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4521–4530,
-
[45]
Automatic Differentiation in PyTorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Al- ban Desmaison, Luca Antiga, and Adam Lerer. Automatic Differentiation in PyTorch. InNIPS-W, 2017. 6
work page 2017
-
[46]
ASIA: Adaptive 3D Seg- mentation using Few Image Annotations.SIGGRAPH Asia Conference Papers, 2025
Sai Raj Kishore Perla, Aditya V ora, Sauradip Nag, Ali Mahdavi-Amiri, and Hao Zhang. ASIA: Adaptive 3D Seg- mentation using Few Image Annotations.SIGGRAPH Asia Conference Papers, 2025. 7
work page 2025
-
[47]
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. InAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2017. 3
work page 2017
-
[48]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. SAM 2: Segment Anything in Images and Videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Toys4K 3D Object Dataset, 2022
James Matthew Rehg. Toys4K 3D Object Dataset, 2022. https://github.com/rehg-lab/lowshot- shapebias/tree/main/toys4k. 6
work page 2022
-
[50]
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J. Guibas. HuMoR: 3D Hu- man Motion Model for Robust Pose Estimation. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 11488–11499, 2021. 4
work page 2021
-
[51]
ExtrudeNet: Unsupervised Inverse Sketch- and-Extrude for Shape Parsing
Daxuan Ren, Jianmin Zheng, Jianfei Cai, Jiatong Li, and Junzhe Zhang. ExtrudeNet: Unsupervised Inverse Sketch- and-Extrude for Shape Parsing. InProceedings of the 17th European Conference on Computer Vision (ECCV). Springer, 2022. 3
work page 2022
-
[52]
SHIC: Shape-Image Correspondences with no Key- point Supervision
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. SHIC: Shape-Image Correspondences with no Key- point Supervision. InEuropean Conference on Computer Vision, pages 129–145. Springer, 2024. 1, 2, 4, 7
work page 2024
-
[53]
Emergent Correspondence from Image Diffusion
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent Correspondence from Image Diffusion. InAdvances in Neural Information Processing Systems, 2023. 3, 6, 7, 15, 16, 17, 18, 20
work page 2023
-
[54]
SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
Yurun Tian, Xin Yu, Bin Fan, Fuchao Wu, Huub Heijnen, and Vassileios Balntas. SOSNet: Second Order Similarity Regularization for Local Descriptor Learning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11016–11025, 2019. 3
work page 2019
-
[55]
TurboSquid 3D Model Repository, 2021
TurboSquid. TurboSquid 3D Model Repository, 2021. https://www.turbosquid.com/. 6
work page 2021
-
[56]
Prior Knowledge for Part Correspondence.Com- puter Graphics Forum, 30(2):553–562, 2011
Oliver van Kaick, Andrea Tagliasacchi, Oana Sidi, Hao Zhang, Daniel Cohen-Or, Lior Wolf, and Ghassan Hamarneh. Prior Knowledge for Part Correspondence.Com- puter Graphics Forum, 30(2):553–562, 2011. 6
work page 2011
-
[57]
Sclip: Rethinking self- attention for dense vision-language inference,
Feng Wang, Jieru Mei, and Alan Yuille. SCLIP: Rethinking Self-Attention for Dense Vision-Language Inference.arXiv preprint arXiv:2312.01597, 2024. 3
-
[58]
Jinglong Wang, Xiawei Li, Jing Zhang, Qingyuan Xu, Qin Zhou, Qian Yu, Lu Sheng, and Dong Xu. Diffusion Model is Secretly a Training-Free Open V ocabulary Semantic Seg- menter.IEEE Transactions on Image Processing, 34:1895– 1907, 2025. 3
work page 1907
-
[59]
SegGPT: Towards Seg- menting Everything in Context
Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, and Tiejun Huang. SegGPT: Towards Seg- menting Everything in Context. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1130–1140, 2023. 2
work page 2023
-
[60]
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic Graph CNN for Learning on Point Clouds.ACM Trans. Graph., 38(5), 2019. 3
work page 2019
-
[61]
Dense Human Body Correspondences Us- ing Convolutional Networks
Lingyu Wei, Qixing Huang, Duygu Ceylan, Etienne V ouga, and Hao Li. Dense Human Body Correspondences Us- ing Convolutional Networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1544–1553, 2016. 3
work page 2016
-
[62]
3D ShapeNets: A Deep Representation for V olumetric Shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3D ShapeNets: A Deep Representation for V olumetric Shapes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1912–1920, 2015. 3
work page 1912
-
[63]
LIFT: Learned Invariant Feature Transform
Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, and Pascal Fua. LIFT: Learned Invariant Feature Transform. InEuro- pean Conference on Computer Vision (ECCV), pages 467–
-
[64]
Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling. InPro- ceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 19313–19322. IEEE, 2022. 3
work page 2022
-
[65]
PyMAF: 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Hongwen Zhang, Yating Tian, Xinchi Zhou, Wanli Ouyang, Yebin Liu, Limin Wang, and Zhenan Sun. PyMAF: 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop. In2021 IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 11426–11436, 2021. 4
work page 2021
-
[66]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. DINO: DETR with Improved DeNoising Anchor Boxes for End- to-End Object Detection.arXiv preprint arXiv:2203.03605,
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
A Tale of Two Features: Stable Diffusion Comple- ments DINO for Zero-Shot Semantic Correspondence
Junyi Zhang, Charles Herrmann, Junhwa Hur, Luisa Pola- nia Cabrera, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. A Tale of Two Features: Stable Diffusion Comple- ments DINO for Zero-Shot Semantic Correspondence. In Advances in Neural Information Processing Systems, 2023. 15
work page 2023
-
[68]
Adding Conditional Control to Text-to-Image Diffusion Models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 7, 17
work page 2023
-
[69]
Extract Free Dense Labels from CLIP
Chong Zhou, Chen Change Loy, and Bo Dai. Extract Free Dense Labels from CLIP. InProceedings of the 17th Euro- pean Conference on Computer Vision (ECCV), pages 696– 712, Cham, 2022. Springer Nature Switzerland. 3
work page 2022
-
[70]
Thingi10K: A Dataset of 10,000 3D-Printing Models
Qingnan Zhou and Alec Jacobson. Thingi10K: A Dataset of 10,000 3D-Printing Models.arXiv preprint arXiv:1605.04797, 2016. 6
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[71]
Segment Everything Everywhere All at Once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment Everything Everywhere All at Once. In Advances in Neural Information Processing Systems, pages 19769–19782. Curran Associates, Inc., 2023. 2 Best Segmentation Buddies for Image-Shape Correspondence Supplementary Material The followi...
work page 2023
-
[72]
An image of an airplane facing away
with a box input, where the user specifies the top-left and bottom-right coordinates in the image to segment the part maskm 2D p used in our matching scheme. Examples are shown in Fig. 19. Another interface for segmenting the image is text, as we describe next. Text to 3D segmentation.In the main paper, we used a click-based model for segmenting the image...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.