Spacetime Optimal-Transport Attention for Visuo-Haptic Imitation Learning of Contact-Rich Manipulation
Pith reviewed 2026-05-21 06:55 UTC · model grok-4.3
The pith
Spacetime Optimal-Transport Attention fuses vision, force, and proprioception signals using entropy-regularized optimal transport to replace standard attention and improve success on contact-rich robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
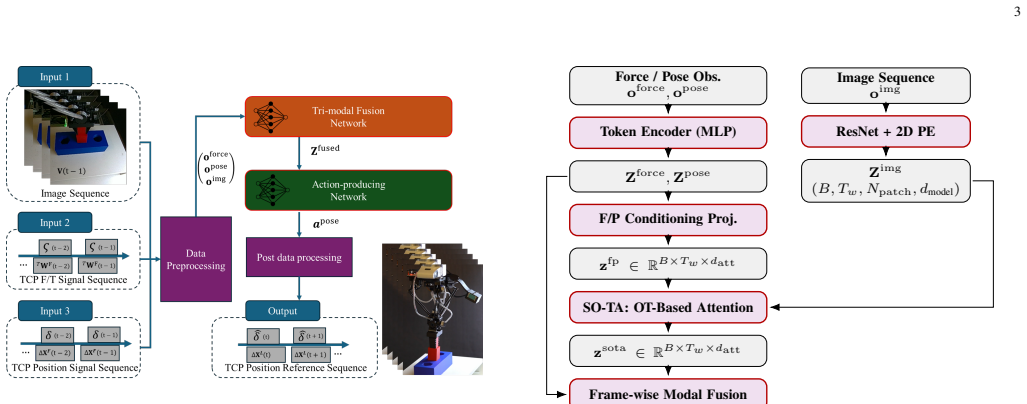
Spacetime Optimal-Transport Attention replaces softmax-normalized patch attention with an entropy-regularized optimal transport alignment between force-pose-derived sub-queries and visual patches. Explicit marginal constraints supply a structured inductive bias that produces conditioning-aware spatial selection stable across illumination changes, distractors, and partial occlusions. When embedded in a diffusion-based sequence policy, the resulting controller reaches 100 percent success on tight peg-in-hole assembly and retains 82.5 percent success under combined visual perturbations where a concatenation baseline falls to 43.5 percent.
What carries the argument
Spacetime Optimal-Transport Attention (SO-TA), an entropy-regularized optimal transport alignment that maps force-pose sub-queries onto visual patches while enforcing marginal constraints to guide attention mass toward task-relevant regions.
If this is right
- SO-TA reaches 100 percent success on tight peg-in-hole versus 93 percent for cross-attention at matched capacity.
- The method retains 82.5 percent success under illumination, distractor, and partial-occlusion perturbations while a concatenation baseline drops to 43.5 percent.
- OT-derived patch heatmaps and leave-one-out modality-influence ratios supply phase-dependent diagnostics for contact-rich behavior.
- The same backbone applies to connector insertion and curved-surface mark erasing without modality-specific redesign.
Where Pith is reading between the lines
- The phase-dependent selection visible in OT heatmaps could be used to diagnose and correct policy failures during deployment on new contact-rich tasks.
- Because the transport formulation is largely parameter-free once marginals are set, the approach may transfer to other multi-modal settings where one modality supplies sparse but reliable conditioning signals.
- The reported robustness to visual noise suggests the method could lower the volume of visual data augmentation needed during training for outdoor or unstructured environments.
Load-bearing premise
Entropy-regularized optimal transport supplies a stable spatial selection bias that stays effective across illumination changes, distractors, and partial occlusions without introducing instabilities or requiring task-specific retuning of the transport cost or marginals.
What would settle it
Running the same peg-in-hole trials with the marginal constraints removed or with a different transport cost and observing whether success rate falls below the 93 percent cross-attention baseline or whether robustness to perturbations collapses.
Figures











read the original abstract
Contact-rich manipulation tasks such as tight-clearance insertion, connector mating, polishing, and surface-conforming wiping remain difficult for data-driven controllers because they couple discontinuous contact dynamics, partial observability, and strict safety constraints. No single sensing modality suffices: vision supplies global context before contact, force/torque (F/T) feedback governs interaction after contact, and proprioceptive pose provides a consistent kinematic backbone. Most prior imitation-learning policies for contact-rich tasks operate on uni- or bi-modal signals, and the few that fuse three modalities typically adopt off-the-shelf attention modules with no explicit prior on how attention mass should be distributed across task-relevant regions. We present Spacetime Optimal-Transport Attention (SO-TA), a tri-modal fusion backbone that replaces softmax-normalized patch attention by an entropy-regularized Optimal Transport (OT) alignment between force-pose-derived sub-queries and visual patches. Explicit marginal constraints act as a structured inductive bias for contact-rich tasks, encouraging conditioning-aware spatial selection that is stable across illumination, distractors, and partial occlusion. SO-TA is paired with a diffusion-based sequence policy mapping observation windows to pose-action chunks. We evaluate SO-TA on three real-robot tasks: tight peg-in-hole assembly, BCM wiring-connector insertion, and curved-surface mark erasing. With ~200 rollouts per condition, SO-TA reaches 100% success on tight peg-in-hole versus 93% for cross-attention at matched capacity, and retains 82.5% success under illumination, distractor, and partial-occlusion perturbations where a concatenation baseline drops to 43.5%. OT-derived patch heatmaps and leave-one-out modality-influence ratios provide interpretable, phase-dependent diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spacetime Optimal-Transport Attention (SO-TA), a tri-modal fusion backbone for visuo-haptic imitation learning of contact-rich manipulation tasks. It replaces standard softmax attention with entropy-regularized optimal transport alignment between force-pose sub-queries and visual patches, using explicit marginal constraints as a structured inductive bias to encourage conditioning-aware spatial selection. SO-TA is combined with a diffusion-based sequence policy and evaluated on three real-robot tasks (tight peg-in-hole assembly, BCM wiring-connector insertion, curved-surface mark erasing), reporting 100% success on nominal tight peg-in-hole versus 93% for cross-attention at matched capacity, and 82.5% success under illumination/distractor/partial-occlusion perturbations versus 43.5% for a concatenation baseline, with ~200 rollouts per condition. Interpretable diagnostics via OT-derived patch heatmaps and modality-influence ratios are also provided.
Significance. If the central claims hold after addressing experimental verification gaps, the work introduces a principled inductive bias via entropy-regularized OT for multi-modal attention in robotics, potentially improving robustness to visual perturbations in contact-rich tasks without requiring per-condition retuning. The inclusion of phase-dependent interpretable diagnostics (OT heatmaps and leave-one-out ratios) strengthens the contribution by enabling analysis of modality influence across task phases. The approach addresses a genuine gap in fusing vision, force/torque, and proprioception for discontinuous contact dynamics.
major comments (2)
- [Experimental evaluation] Experimental evaluation: The performance claims (100% vs. 93% nominal success; 82.5% vs. 43.5% under perturbations) rest on ~200 rollouts per condition but provide no error bars, statistical significance tests, details on rollout collection protocol, or confirmation that hyperparameters were not tuned post-hoc. This leaves open whether the reported gaps reflect the OT structure or experimental variability.
- [Method description and robustness experiments] Method and robustness claims: The central assertion that entropy-regularized OT marginal constraints supply a stable, conditioning-aware spatial selection bias effective across illumination, distractor, and partial-occlusion changes without new instabilities or task-specific retuning lacks explicit verification. No sensitivity study or statement confirms that the cost matrix construction and marginal vectors were held identical between nominal peg-in-hole trials and the three perturbation conditions; if per-condition adjustment occurred, the performance advantage could be attributable to optimization rather than the OT inductive bias.
minor comments (2)
- The abstract mentions 'three real-robot tasks' but does not explicitly list the success metrics or perturbation definitions in the opening summary; adding one sentence would improve clarity for readers.
- Notation for the OT cost matrix and marginal vectors could be introduced earlier with a small equation block to aid readers unfamiliar with entropy-regularized transport in attention contexts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below. Where clarifications or additional analyses are warranted, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation: The performance claims (100% vs. 93% nominal success; 82.5% vs. 43.5% under perturbations) rest on ~200 rollouts per condition but provide no error bars, statistical significance tests, details on rollout collection protocol, or confirmation that hyperparameters were not tuned post-hoc. This leaves open whether the reported gaps reflect the OT structure or experimental variability.
Authors: We acknowledge that the manuscript would benefit from greater statistical transparency. In the revised version we will (i) report error bars (standard error of the mean) computed across the ~200 rollouts per condition, (ii) include a statistical significance test (binomial test for success rates and McNemar’s test for paired comparisons against baselines), (iii) add an explicit description of the rollout protocol (randomized trial ordering, independent environment resets, and fixed random seeds), and (iv) state that all hyperparameters were locked after validation-set tuning and were not adjusted after seeing test results. These additions will make clear that the reported performance differences are not attributable to post-hoc optimization. revision: yes
-
Referee: [Method description and robustness experiments] Method and robustness claims: The central assertion that entropy-regularized OT marginal constraints supply a stable, conditioning-aware spatial selection bias effective across illumination, distractor, and partial-occlusion changes without new instabilities or task-specific retuning lacks explicit verification. No sensitivity study or statement confirms that the cost matrix construction and marginal vectors were held identical between nominal peg-in-hole trials and the three perturbation conditions; if per-condition adjustment occurred, the performance advantage could be attributable to optimization rather than the OT inductive bias.
Authors: The OT parameters were in fact held fixed: the cost matrix is constructed from the same feature-distance metric between force-pose sub-queries and visual patches, and the marginal vectors are uniform (scaled only by sequence length) with no condition-specific re-weighting. This fixed configuration was used for both nominal and perturbed peg-in-hole trials. To make this explicit, we will insert a clarifying paragraph in the experimental setup section and add a sensitivity study in the appendix that varies the entropy-regularization coefficient and marginal scaling factors while keeping all other elements unchanged. The study will show that success rates remain stable without per-condition retuning, supporting that the robustness stems from the OT inductive bias rather than hidden optimization adjustments. revision: yes
Circularity Check
No significant circularity; SO-TA is an independent architectural proposal with empirical validation
full rationale
The paper introduces Spacetime Optimal-Transport Attention (SO-TA) as a tri-modal fusion backbone that replaces softmax attention with entropy-regularized optimal transport between force-pose sub-queries and visual patches, using explicit marginal constraints as a structured inductive bias. No equations, derivations, or self-citations are supplied that reduce the claimed performance gains (100% vs 93% success, 82.5% vs 43.5% under perturbations) or robustness properties to fitted parameters, self-defined outputs, or prior author work. The OT mechanism is presented as an external mathematical tool applied to the visuo-haptic setting, and results are reported from real-robot experiments with ~200 rollouts per condition. The central claims rest on this architectural choice and empirical comparisons rather than any self-referential loop or renaming of known results, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entropy-regularized Optimal Transport (OT) alignment between force–pose-derived sub-queries and visual patches. Explicit marginal constraints act as a structured inductive bias
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
min Π≥0 ⟨Π,C⟩ −ε ot H(Π) s.t. Π1=γ, ΠT1=β
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey of robot manipulation in contact,
M. Suomalainen, Y . Karayiannidis, and V . Kyrki, “A survey of robot manipulation in contact,”Robotics and Autonomous Systems, vol. 156, p. 104224, 2022
work page 2022
-
[2]
A survey on imitation learning for contact-rich tasks in robotics,
T. Tsuji, Y . Kato, G. Solak, H. Zhang, T. Petriˇc, F. Nori, and A. Ajoudani, “A survey on imitation learning for contact-rich tasks in robotics,”arXiv preprint arXiv:2506.13498, 2025
-
[3]
Survey of learning-based approaches for robotic in-hand manipulation,
A. I. Weinberg, A. Shirizly, O. Azulay, and A. Sintov, “Survey of learning-based approaches for robotic in-hand manipulation,”Frontiers in Robotics and AI, vol. 11, p. 1455431, 2024
work page 2024
-
[4]
Towards forceful robotic foundation models: A literature survey,
W. Xie and N. Correll, “Towards forceful robotic foundation models: A literature survey,”arXiv preprint arXiv:2504.11827, 2025
-
[5]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. C. M. Burchfiel, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” inProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[6]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” inProceedings of Robotics: Science and Systems (RSS), 2023. 8
work page 2023
-
[7]
Behavior transformers: Cloningkmodes with one stone,
N. M. M. Shafiullah, Z. J. Cui, A. Altanzaya, and L. Pinto, “Behavior transformers: Cloningkmodes with one stone,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[8]
Open X-embodiment: Robotic learning datasets and RT-X models,
Q. Vuong, S. Levine, H. R. Walke, K. Pertsch, A. Singh, R. Doshi, C. Xu, J. Luo, L. Tan, D. Shahet al., “Open X-embodiment: Robotic learning datasets and RT-X models,” inTowards Generalist Robots: Learning Paradigms for Scalable Skill Acquisition @ CoRL, 2023
work page 2023
-
[9]
Towards generalist robot learning from internet video: A survey,
R. McCarthy, D. C. H. Tan, D. Schmidt, F. Acero, N. Herr, Y . Du, T. G. Thuruthel, and Z. Li, “Towards generalist robot learning from internet video: A survey,”Journal of Artificial Intelligence Research, vol. 83, 2025
work page 2025
-
[10]
RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot,
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu, “RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot,”arXiv preprint arXiv:2307.00595, 2023
-
[11]
Multimodal machine learning: A survey and taxonomy,
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, pp. 423–443, 2019
work page 2019
-
[12]
Multimodal learning with transformers: A survey,
Y . Du, J. Hu, J. Chen, and Y . Wang, “Multimodal learning with transformers: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
work page 2022
-
[13]
Deep generative models in robotics: A survey on learning from multimodal demonstrations,
J. Urain, A. Mandlekar, Y . Du, M. Shafiullah, D. Xu, K. Fragkiadaki, G. Chalvatzaki, and J. Peters, “Deep generative models in robotics: A survey on learning from multimodal demonstrations,”arXiv preprint arXiv:2408.04380, 2024
-
[14]
A survey of robot learning from demonstration,
B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,”Robotics and Autonomous Systems, vol. 57, no. 5, pp. 469–483, 2009
work page 2009
-
[15]
An algorithmic perspective on imitation learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An algorithmic perspective on imitation learning,”Foundations and Trends in Robotics, vol. 7, no. 1–2, pp. 1–179, 2018
work page 2018
-
[16]
Recent advances in robot learning from demonstration,
H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Recent advances in robot learning from demonstration,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, pp. 297–330, 2020
work page 2020
-
[17]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998– 6008
work page 2017
-
[18]
Multimodal transformer for unaligned multimodal language sequences,
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019, pp. 6558–6569
work page 2019
-
[19]
SoftGrasp: Adaptive grasping for dexterous hand based on multimodal imitation learning,
Y . Li, C. Guo, J. Ren, B. Chen, C. Cheng, H. Zhang, and H. Lu, “SoftGrasp: Adaptive grasping for dexterous hand based on multimodal imitation learning,”Biomimetic Intelligence and Robotics, vol. 5, no. 2, p. 100217, 2025
work page 2025
-
[20]
Learning diffusion policies from demonstrations for compliant contact- rich manipulation,
M. Aburub, C. C. Beltran-Hernandez, T. Kamijo, and M. Hamaya, “Learning diffusion policies from demonstrations for compliant contact- rich manipulation,”arXiv preprint, 2024
work page 2024
-
[21]
Robotic compliant object prying using diffusion policy guided by vision and force obser- vations,
J. H. Kang, S. Joshi, R. Huang, and S. K. Gupta, “Robotic compliant object prying using diffusion policy guided by vision and force obser- vations,”arXiv preprint, 2024
work page 2024
-
[22]
See, hear, and feel: Smart sensory fusion for robotic manipulation,
H. Li, Y . Zhang, J. Zhu, S. Wang, M. A. Lee, H. Xu, E. Adelson, L. Fei- Fei, R. Gao, and J. Wu, “See, hear, and feel: Smart sensory fusion for robotic manipulation,” inProceedings of the 6th Conference on Robot Learning (CoRL), ser. Proceedings of Machine Learning Research, vol. 205, 2023
work page 2023
-
[23]
Visuo-tactile transformers for manipulation,
Y . Chen, M. van der Merwe, A. Sipos, and N. Fazeli, “Visuo-tactile transformers for manipulation,” inProceedings of the 6th Conference on Robot Learning (CoRL), ser. Proceedings of Machine Learning Research, vol. 205, 2023, pp. 2026–2040
work page 2023
-
[24]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei- Fei, A. Garg, and J. Bohg, “Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks,” inIEEE International Conference on Robotics and Automation (ICRA), 2019, pp. 8943–8950
work page 2019
-
[25]
QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation,
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, and S. Levine, “QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation,” inConference on Robot Learning (CoRL), 2018, pp. 651– 673
work page 2018
-
[26]
Robotic imitation of human assembly skills using hybrid trajectory and force learning,
Y . Wang, C. C. Beltran-Hernandez, W. Wan, and K. Harada, “Robotic imitation of human assembly skills using hybrid trajectory and force learning,”arXiv preprint, 2021
work page 2021
-
[27]
Robotic paper wrapping by learning force control,
H. Hanai, T. Kiyokawa, W. Wan, and K. Harada, “Robotic paper wrapping by learning force control,”arXiv preprint, 2023
work page 2023
-
[28]
MOMA-Force: Visual-force imitation for real-world mobile manipulation,
T. Yang, Y . Jing, H. Wu, J. Xu, K. Sima, G. Chen, Q. Sima, and T. Kong, “MOMA-Force: Visual-force imitation for real-world mobile manipulation,”arXiv preprint arXiv:2308.03624, 2024
-
[29]
W. Liu, J. Wang, Y . Wang, W. Wang, and C. Lu, “ForceMimic: Force- centric imitation learning with force-motion capture system for contact- rich manipulation,”arXiv preprint, 2024
work page 2024
-
[30]
Multi-modal fusion in contact- rich precise tasks via hierarchical policy learning,
P. Jin, Y . Lin, Y . Tan, T. Li, and W. Yang, “Multi-modal fusion in contact- rich precise tasks via hierarchical policy learning,”arXiv preprint, 2022
work page 2022
-
[31]
Vision-force-fused curriculum learning for robotic contact-rich assembly tasks,
P. Jin, Y . Lin, Y . Song, T. Li, and W. Yang, “Vision-force-fused curriculum learning for robotic contact-rich assembly tasks,”Frontiers in Neurorobotics, vol. 17, p. 1280773, 2023
work page 2023
-
[32]
Play to the score: Stage-guided dynamic multi-sensory fusion for robotic manipulation,
R. Feng, D. Hu, W. Ma, and X. Li, “Play to the score: Stage-guided dynamic multi-sensory fusion for robotic manipulation,” inProceedings of the Conference on Robot Learning (CoRL), 2024
work page 2024
-
[33]
Sinkhorn distances: Lightspeed computation of optimal transport,
M. Cuturi, “Sinkhorn distances: Lightspeed computation of optimal transport,” inAdvances in Neural Information Processing Systems (NeurIPS), 2013
work page 2013
-
[34]
G. Peyr ´e and M. Cuturi,Computational Optimal Transport, ser. Founda- tions and Trends in Machine Learning. Now Publishers, 2019, vol. 11, no. 5–6
work page 2019
-
[35]
Sinkformers: Transformers with doubly stochastic attention,
M. E. Sander, P. Ablin, M. Blondel, and G. Peyr ´e, “Sinkformers: Transformers with doubly stochastic attention,” inProceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS), 2022, pp. 3515–3530
work page 2022
-
[36]
Unlocking slot attention by changing optimal transport costs,
Y . Zhang, D. W. Zhang, S. Lacoste-Julien, G. J. Burghouts, and C. G. M. Snoek, “Unlocking slot attention by changing optimal transport costs,” in Proceedings of the 40th International Conference on Machine Learning (ICML), 2023, pp. 41 931–41 951
work page 2023
-
[37]
OTSeg: Multi-prompt sinkhorn atten- tion for zero-shot semantic segmentation,
K. Kim, Y . Oh, and J. C. Ye, “OTSeg: Multi-prompt sinkhorn atten- tion for zero-shot semantic segmentation,” inEuropean Conference on Computer Vision (ECCV), 2024, pp. 200–217
work page 2024
-
[38]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 6840–6851
work page 2020
-
[39]
Score-based generative modeling through stochastic differ- ential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,”International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[40]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[41]
P. Micikevicius, S. Narang, J. Alben, G. F. Diamos, E. Elsen, D. Garc ´ıa, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” inInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[42]
Delta6: A Low-Cost, 6-DOF Force-Sensing Flexible End-Effector
Y . Feng, W. Huang, C. Qiu, H. Dong, and I.-M. Chen, “Delta6: A low-cost, 6-dof force-sensing flexible end-effector,”arXiv preprint arXiv:2604.06150, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
One Interface, Many Robots: Unified Real-Time Low-Level Motion Planning for Collaborative Arms
Y . Feng, W. Huang, and I.-M. Chen, “One interface, many robots: Unified real-time low-level motion planning for collaborative arms,” arXiv preprint arXiv:2604.08787, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Y . Feng, W. Huang, and I.-M. Chen, “Optimizing small-scale commer- cial automation: Introducing WOS, a low-code solution for robotic arms integration,” inIEEE International Conference on Advanced Intelligent Mechatronics (AIM), 2024, pp. 272–277
work page 2024
-
[45]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5745– 5753
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.