Complementing reinforcement learning with SFT through logit averaging in the post training of LLMs
Pith reviewed 2026-05-21 06:34 UTC · model grok-4.3
The pith
Averaging logits from a frozen SFT model and a trainable policy improves or matches accuracy in GRPO without KL regularization or a critic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By averaging the logits of a frozen SFT policy and the trainable policy within GRPO updates, the approach couples the two models so that the trainable policy can leverage its reasoning expertise while the frozen SFT maintains formatting advantages, achieving comparable or superior performance on math and knowledge benchmarks without using KL regularization or a critic.
What carries the argument
The logit averaging operation that combines outputs from the frozen reference policy and the trainable policy before policy probability computation in GRPO.
If this is right
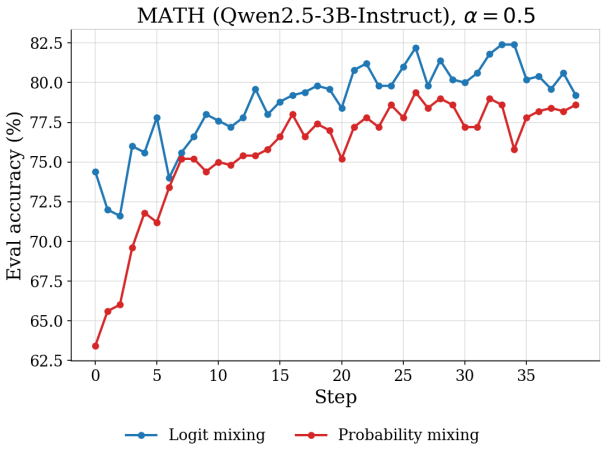
- The method achieves higher or comparable accuracy on MATH, cn-k12, and MMLU relative to canonical KL-regularized GRPO.
- It removes the requirement for a KL regularization term and a critic in the optimization process.
- The coupling through logit averaging preserves SFT formatting advantages during reinforcement learning post-training.
- Training remains stable by directly mixing logits rather than relying on divergence penalties.
Where Pith is reading between the lines
- If this logit averaging proves robust, it could reduce the hyperparameter tuning burden associated with KL coefficients in other RL post-training methods.
- The technique might be extended to other policy optimization algorithms like PPO or DPO to test if similar benefits appear.
- Future work could examine whether the averaging weight can be learned or scheduled dynamically instead of fixed equal weighting.
Load-bearing premise
That averaging logits from the frozen SFT policy and the trainable policy sufficiently couples the models to improve reasoning expertise while preserving formatting advantages without any KL term or critic.
What would settle it
Running the logit-averaged GRPO and the standard KL-regularized GRPO on identical training data, model seeds, and evaluation protocols for MATH, then observing lower accuracy or degraded formatting in the averaged version.
Figures








read the original abstract
We introduce a novel method that averages the logits of a frozen reference policy (e.g., SFT) and a trainable policy, and incorporate the method into Group Relative Policy Optimization (GRPO). In contrast to Reinforcement Learning with Verifiable Rewards (RLVR) methods, our proposal does not involve a Kullback Leibler (KL) regularization or critic; the trainable policy and the reference anchor are coupled through the logit averaging structure to leverage the reasoning expertise of the trainable policy while maintaining the formatting advantage of SFT. Our method is evaluated on MATH, cn-k12, and MMLU, and the results show a higher accuracy or at least comparable accuracy relative to the canonical KL-regularized GRPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes averaging logits between a frozen SFT reference policy and a trainable policy, then incorporating this averaged distribution into Group Relative Policy Optimization (GRPO). The method is positioned as an alternative to standard RLVR approaches that use KL regularization or critics; the averaging is claimed to couple the models so that reasoning gains from the trainable policy are retained while SFT formatting advantages are preserved. Experiments on MATH, cn-k12, and MMLU are reported to yield higher or at least comparable accuracy relative to canonical KL-regularized GRPO.
Significance. If the central coupling mechanism can be shown to work without explicit KL or critic terms, the approach would simplify post-training pipelines and reduce the risk of format degradation during RL. The idea of logit-level anchoring is a lightweight way to transfer formatting behavior, and the reported accuracy parity or gains on three standard reasoning benchmarks would be practically useful if reproducible. The absence of any parameter-free derivation or machine-checked component is noted, but the core empirical claim, if substantiated, would still be of interest to the RLHF/RLVR community.
major comments (3)
- [§4] §4 (Experimental Evaluation): The abstract and results section state higher or comparable accuracy on MATH, cn-k12, and MMLU versus KL-regularized GRPO, yet supply no baselines, number of runs, error bars, statistical tests, or ablation on the logit-averaging weight. Without these, the data cannot be judged to support the claim that averaging alone suffices to preserve formatting while improving reasoning.
- [§3.2] §3.2 (GRPO Integration): The manuscript does not specify whether logit averaging is applied only at sampling time or inside the GRPO surrogate objective itself. If the former, policy gradients on the trainable policy could still erode format-critical tokens; the current description leaves the coupling mechanism underspecified and therefore does not yet demonstrate that averaging replaces the role of a KL term.
- [§4.3] §4.3 (Ablations): No ablation is reported that varies the averaging coefficient while holding GRPO group size and reward fixed, nor are separate format-compliance metrics (e.g., LaTeX validity rate or answer-box adherence) provided. Aggregate accuracy alone does not isolate whether the claimed coupling effect is occurring.
minor comments (2)
- [§3] Notation for the averaged logit distribution (softmax of mean logits) should be introduced with an explicit equation and distinguished from the standard policy and reference distributions.
- [§2] The paper should clarify the relationship to prior logit-averaging or ensemble methods in RLHF; a short related-work paragraph would help readers assess novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the changes we will make in the revised version to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation): The abstract and results section state higher or comparable accuracy on MATH, cn-k12, and MMLU versus KL-regularized GRPO, yet supply no baselines, number of runs, error bars, statistical tests, or ablation on the logit-averaging weight. Without these, the data cannot be judged to support the claim that averaging alone suffices to preserve formatting while improving reasoning.
Authors: We agree that the current manuscript would benefit from more complete experimental reporting. The primary baseline is the canonical KL-regularized GRPO as stated in the abstract and Section 4. In the revision we will explicitly report the number of independent runs performed, include error bars on all accuracy figures, add statistical significance tests where appropriate, and incorporate an ablation on the logit-averaging weight to better substantiate the claims. revision: yes
-
Referee: [§3.2] §3.2 (GRPO Integration): The manuscript does not specify whether logit averaging is applied only at sampling time or inside the GRPO surrogate objective itself. If the former, policy gradients on the trainable policy could still erode format-critical tokens; the current description leaves the coupling mechanism underspecified and therefore does not yet demonstrate that averaging replaces the role of a KL term.
Authors: Logit averaging is incorporated inside the GRPO surrogate objective itself rather than only at sampling time. The averaged distribution is used to compute the probabilities that enter the policy-gradient term of the GRPO loss, thereby coupling the trainable policy and the frozen SFT reference at the level of the optimization objective. We will revise §3.2 to state this integration explicitly and to clarify how the mechanism substitutes for an explicit KL term. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): No ablation is reported that varies the averaging coefficient while holding GRPO group size and reward fixed, nor are separate format-compliance metrics (e.g., LaTeX validity rate or answer-box adherence) provided. Aggregate accuracy alone does not isolate whether the claimed coupling effect is occurring.
Authors: We concur that targeted ablations and format-specific metrics would strengthen the evidence for the coupling effect. In the revised manuscript we will add experiments that vary the averaging coefficient while keeping GRPO group size and reward function fixed, and we will report separate format-compliance metrics including LaTeX validity rate and answer-box adherence. revision: yes
Circularity Check
No significant circularity; empirical method proposal with direct benchmark evaluation
full rationale
The paper introduces logit averaging between a frozen SFT reference and trainable policy inside GRPO as an alternative to KL-regularized RLVR, claiming this coupling preserves formatting while improving reasoning. Evaluation consists of direct accuracy measurements on MATH, cn-k12, and MMLU showing results comparable or superior to canonical GRPO. No derivation, first-principles result, fitted parameter, or self-citation chain is present that reduces the reported accuracies to the method inputs by construction. The central claim rests on the empirical outcomes rather than any tautological re-expression of the averaging operation itself. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Averaging logits from the frozen SFT policy and the trainable policy couples the models so that reasoning expertise is leveraged while formatting advantages are maintained.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel method that averages the logits of a frozen reference policy (e.g., SFT) and a trainable policy, and incorporate the method into Group Relative Policy Optimization (GRPO). ... the trainable policy and the reference anchor are coupled through the logit averaging structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reinforcement Learning via Self-Distillation
Jonas H\"ubotter, Frederike L\"ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement Learning via Self-Distillation. arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Geoffrey E. Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation, 14(8):1771--1800, 2002
work page 2002
-
[3]
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. DExperts : Decoding-time controlled text generation with experts and anti-experts. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021
work page 2021
-
[4]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
work page 2023
- [5]
-
[6]
Tomasz Korbak, Ethan Perez, and Christopher L. Buckley. RL with KL penalties is better viewed as B ayesian inference. In Findings of the Association for Computational Linguistics: EMNLP, 2022
work page 2022
-
[7]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Yang Wu, and others. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, and others. DAPO: An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015
work page 2015
-
[11]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
Self-Distillation Enables Continual Learning
Idan Shenfeld, et al. Self-Distillation Enables Continual Learning. 2026
work page 2026
-
[13]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[14]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and others
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and others. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[15]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and others. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and others. DeepSeek-R1 : Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2021
work page 2021
-
[18]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR), 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.