On the convergence of doubly stochastic Primal-Dual Hybrid Gradient Method
Pith reviewed 2026-05-20 09:41 UTC · model grok-4.3
The pith
A doubly stochastic primal-dual hybrid gradient method achieves O(1/K) ergodic convergence for convex saddle-point problems with randomized block updates on both sides.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The doubly stochastic primal-dual hybrid gradient method performs randomized block updates on both primal and dual variables and establishes an O(1/K) ergodic convergence rate for the expected restricted primal-dual gap under suitable blockwise step-size conditions in the general convex setting; its restarted variant achieves linear convergence of the outer iterates under a quadratic growth condition in the smoothed primal-dual gap.
What carries the argument
The doubly stochastic primal-dual hybrid gradient method (DSPDHG), which extends classical PDHG by independently selecting random blocks for primal and dual updates at each iteration.
If this is right
- The method reduces exactly to deterministic PDHG when every block is selected at each step.
- The method reduces to one-sided stochastic variants when randomization occurs on only the primal or only the dual side.
- A restarted outer-loop version delivers linear convergence once a quadratic growth condition holds for the smoothed gap.
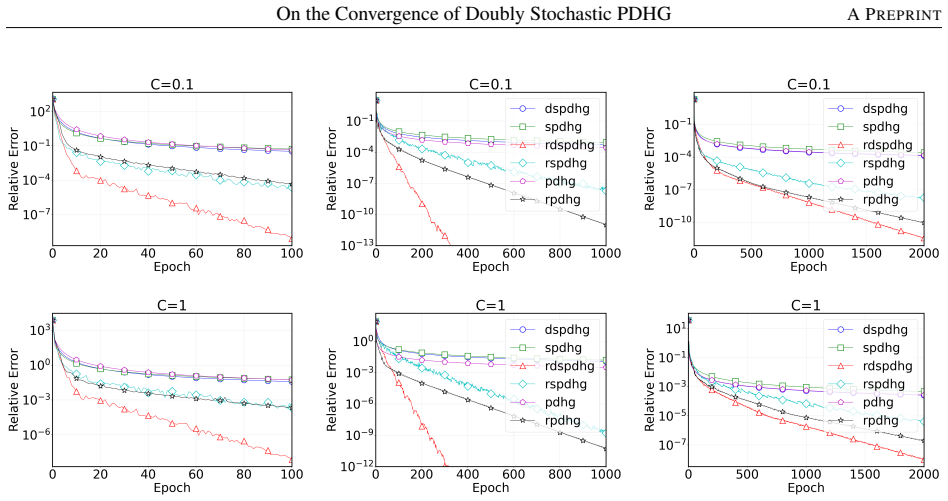
- Practical runs with standard step sizes match or exceed the speed of PDHG, SPDHG, and their restarted forms on large instances.
Where Pith is reading between the lines
- The same block-randomization idea could be applied to other primal-dual splitting schemes to obtain similar rates without full-vector updates.
- The analysis suggests that two-sided stochasticity preserves the same asymptotic rate as one-sided stochasticity when step sizes are chosen blockwise.
- Linear convergence under quadratic growth may extend to problems where the gap satisfies a local error bound rather than strict quadratic growth.
Load-bearing premise
Suitable blockwise step-size conditions exist that make the convergence rate hold even when blocks are chosen randomly.
What would settle it
Numerical runs on a standard convex-concave saddle-point test problem where the measured expected restricted primal-dual gap after K iterations fails to decrease proportionally to 1/K when the stated blockwise step-size rules are followed.
Figures

read the original abstract
We study a block-structured class of convex-concave saddle-point problems in which both the primal and dual variables admit natural separable decompositions. Motivated by large-scale applications where a full update on either side can be computationally expensive, we propose a doubly stochastic primal--dual hybrid gradient method (DSPDHG) that performs randomized block updates on both primal and dual variables.The method extends classical PDHG and stochastic PDHG (SPDHG) schemes in a unified manner:it reduces to deterministic PDHG when all blocks are selected and to one-sided stochastic variants when only one side is randomized. For the general convex setting, we establish an $\mathcal{O}(1/K)$ ergodic convergence rate for the expected restricted primal--dual gap under suitable blockwise step-size conditions. We further analyze a restarted variant of DSPDHG under a quadratic growth condition in terms of the smoothed primal-dual gap. Under this regularity assumption, we prove linear convergence of the restarted outer iterates. Numerical evidence is provided to show that restarted DSPDHG with standard step sizes demonstrates competitive practical performance compared with PDHG, SPDHG, and their restarted variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the doubly stochastic primal-dual hybrid gradient (DSPDHG) method for block-structured convex-concave saddle-point problems, performing randomized block updates on both primal and dual variables. It reduces to classical PDHG when all blocks are selected and to one-sided stochastic variants otherwise. For the general convex case the paper claims an O(1/K) ergodic rate on the expected restricted primal-dual gap under suitable blockwise step-size conditions; under an additional quadratic-growth assumption it further claims linear convergence of the restarted outer iterates measured in the smoothed primal-dual gap. Numerical experiments are presented to illustrate practical competitiveness with PDHG, SPDHG and their restarted versions.
Significance. If the stated rates are rigorously established with explicit, practical step-size rules, the work supplies a unified convergence theory for doubly stochastic primal-dual schemes that is directly relevant to large-scale saddle-point problems. The linear-rate result under quadratic growth and the provision of numerical evidence are positive features; the main significance hinges on whether the blockwise step-size conditions can be satisfied without knowledge of unknown constants or without forcing steps that shrink with the number of blocks.
major comments (2)
- [§3] §3 (General convex convergence): the O(1/K) ergodic bound on the expected restricted primal-dual gap is stated to hold under 'suitable blockwise step-size conditions' for randomized block selections. The explicit form of these conditions (in terms of block Lipschitz constants of the coupling operator, block probabilities, or norms of the blocks) is not given, nor is it shown that feasible choices exist that remain independent of the number of blocks and do not degrade the rate below O(1/K). This is load-bearing for the central claim.
- [§4] §4 (Restarted variant): the linear convergence statement for the restarted outer iterates is proved under a quadratic-growth condition on the smoothed primal-dual gap. It is unclear whether the quadratic-growth assumption is imposed on the original or the smoothed problem and how the smoothing parameter enters the linear rate; without this clarification the result cannot be directly compared with existing restarted PDHG analyses.
minor comments (3)
- [Abstract] The abstract and introduction should explicitly state whether the blockwise step-size rule reduces to the standard PDHG rule when each side consists of a single block.
- [Notation section] Notation for the restricted primal-dual gap versus the smoothed gap should be made uniform across theorems and proofs.
- [Numerical experiments] Numerical section: the step sizes actually used in the experiments should be reported and compared with the theoretical blockwise conditions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and will incorporate clarifications and explicit derivations into the revised version.
read point-by-point responses
-
Referee: [§3] §3 (General convex convergence): the O(1/K) ergodic bound on the expected restricted primal-dual gap is stated to hold under 'suitable blockwise step-size conditions' for randomized block selections. The explicit form of these conditions (in terms of block Lipschitz constants of the coupling operator, block probabilities, or norms of the blocks) is not given, nor is it shown that feasible choices exist that remain independent of the number of blocks and do not degrade the rate below O(1/K). This is load-bearing for the central claim.
Authors: We agree that the step-size conditions merit a more explicit treatment. In the current manuscript, Assumption 3.1 states the blockwise conditions in terms of the local Lipschitz constants L_{ij} of the coupling operator blocks and the selection probabilities p_i, q_j; Theorem 3.2 then derives the O(1/K) ergodic rate on the expected restricted gap under these conditions. To address the concern directly, the revision will include a new remark (or corollary) that constructs concrete, practical step-size rules: for example, set the primal step sizes τ_i = 1/(2 max_j L_{ij}/p_i) and dual step sizes σ_j = 1/(2 max_i L_{ij}/q_j). These choices depend only on per-block quantities and the local probabilities; because the probabilities sum to one, the resulting constants remain independent of the total number of blocks. Consequently the ergodic rate stays O(1/K) without degradation. We will also verify that these rules reduce correctly to the classical PDHG step-size condition when all blocks are selected with probability one. revision: yes
-
Referee: [§4] §4 (Restarted variant): the linear convergence statement for the restarted outer iterates is proved under a quadratic-growth condition on the smoothed primal-dual gap. It is unclear whether the quadratic-growth assumption is imposed on the original or the smoothed problem and how the smoothing parameter enters the linear rate; without this clarification the result cannot be directly compared with existing restarted PDHG analyses.
Authors: The quadratic-growth assumption (Assumption 4.1) is imposed directly on the smoothed primal-dual gap function G_ε, not on the original unsmoothed gap; this is stated explicitly in Section 4 and used in Theorem 4.2. The smoothing parameter ε appears in the linear rate through the strong-convexity modulus of G_ε, which is at least ε/2 in the appropriate norm; the contraction factor of the restarted outer iterates is then of the form 1 − Θ(min{μ, ε}), where μ is the quadratic-growth constant. In the revision we will add a short comparison paragraph noting that this dependence is analogous to the smoothing parameter in restarted PDHG analyses (e.g., the rate degrades gracefully as ε → 0 but remains linear for any fixed positive ε). We will also clarify that the restarted scheme is applied to the smoothed problem while the inner DSPDHG iterations use the original (unsmoothed) operator. revision: yes
Circularity Check
Derivation is self-contained via standard convex analysis of block updates.
full rationale
The paper establishes the O(1/K) ergodic rate for the expected restricted primal-dual gap directly from the DSPDHG update rules under explicitly stated blockwise step-size conditions, and derives linear convergence of the restarted variant from the quadratic growth assumption on the smoothed gap. These steps rely on standard Lyapunov-style arguments for primal-dual methods and do not reduce to fitted parameters, self-definitions, or load-bearing self-citations. The blockwise conditions are part of the theorem hypotheses rather than presupposed results, and the analysis extends classical PDHG/SPDHG without circular renaming or ansatz smuggling. The derivation remains independent of the target rates.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption The problem is convex-concave with natural separable block decompositions for primal and dual variables.
- domain assumption Suitable blockwise step-size conditions hold.
- domain assumption Quadratic growth condition on the smoothed primal-dual gap.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For the general convex setting, we establish an O(1/K) ergodic convergence rate for the expected restricted primal-dual gap under suitable blockwise step-size conditions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further analyze a restarted variant of DSPDHG under a quadratic growth condition in terms of the smoothed primal-dual gap.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jacob M Aguirre, Diego Cifuentes, Vincent Guigues, Renato DC Monteiro, Victor Hugo Nascimento, and Arnesh Sujanani. cuhallar: A gpu accelerated low-rank augmented lagrangian method for large-scale semidefinite programming.arXiv preprint arXiv:2505.13719, 2025
-
[2]
Random extrapolation for primal-dual coordinate descent
Ahmet Alacaoglu, Olivier Fercoq, and V olkan Cevher. Random extrapolation for primal-dual coordinate descent. InInternational conference on machine learning, pages 191–201. PMLR, 2020
work page 2020
-
[3]
Ahmet Alacaoglu, Olivier Fercoq, and V olkan Cevher. On the convergence of stochastic primal-dual hybrid gradient.SIAM Journal on Optimization, 32(2):1288–1318, 2022
work page 2022
-
[4]
David Applegate, Mateo Díaz, Oliver Hinder, Haihao Lu, Miles Lubin, Brendan O’Donoghue, and Warren Schudy. Practical large-scale linear programming using primal-dual hybrid gradient.Advances in Neural Information Processing Systems, 34:20243–20257, 2021
work page 2021
-
[5]
Ehrhardt, Peter Richtárik, and Carola-Bibiane Schönlieb
Antonin Chambolle, Matthias J. Ehrhardt, Peter Richtárik, and Carola-Bibiane Schönlieb. Stochastic primal-dual hybrid gradient algorithm with arbitrary sampling and imaging applications.SIAM Journal on Optimization, 28(4):2783–2808, 2018
work page 2018
-
[6]
Antonin Chambolle and Thomas Pock. A first-order primal-dual algorithm for convex problems with applications to imaging.Journal of mathematical imaging and vision, 40:120–145, 2011
work page 2011
-
[7]
On the ergodic convergence rates of a first-order primal–dual algorithm
Antonin Chambolle and Thomas Pock. On the ergodic convergence rates of a first-order primal–dual algorithm. Mathematical Programming, 159(1):253–287, 2016
work page 2016
-
[8]
Libsvm: A library for support vector machines.ACM Trans
Chih-Chung Chang and Chih-Jen Lin. Libsvm: A library for support vector machines.ACM Trans. Intell. Syst. Technol., 2(3), May 2011
work page 2011
-
[9]
Kaihuang Chen, Defeng Sun, Yancheng Yuan, Guojun Zhang, and Xinyuan Zhao. Hpr-lp: An implementation of an hpr method for solving linear programming.arXiv preprint arXiv:2408.12179, 2024
-
[10]
Kaihuang Chen, Defeng Sun, Yancheng Yuan, Guojun Zhang, and Xinyuan Zhao. Hpr-qp: A dual halpern peaceman-rachford method for solving large-scale convex composite quadratic programming.arXiv preprint arXiv:2507.02470, 2025
-
[11]
Lijun Ding, Haihao Lu, and Jinwen Yang. New understandings and computation on augmented lagrangian methods for low-rank semidefinite programming.arXiv preprint arXiv:2505.15775, 2025
-
[12]
Quadratic error bound of the smoothed gap and the restarted averaged primal-dual hybrid gradient
Olivier Fercoq. Quadratic error bound of the smoothed gap and the restarted averaged primal-dual hybrid gradient. arXiv preprint arXiv:2206.03041, 2022
-
[13]
Cardinal optimizer (copt) user guide.arXiv preprint arXiv:2208.14314, 2022
Dongdong Ge, Qi Huangfu, Zizhuo Wang, Jian Wu, and Yinyu Ye. Cardinal optimizer (copt) user guide.arXiv preprint arXiv:2208.14314, 2022
-
[14]
Qiushi Han, Chenxi Li, Zhenwei Lin, Caihua Chen, Qi Deng, Dongdong Ge, Huikang Liu, and Yinyu Ye. A low-rank admm splitting approach for semidefinite programming.arXiv preprint arXiv:2403.09133, 2024
-
[15]
Qiushi Han, Zhenwei Lin, Hanwen Liu, Caihua Chen, Qi Deng, Dongdong Ge, and Yinyu Ye. Accelerating low-rank factorization-based semidefinite programming algorithms on gpu.arXiv preprint arXiv:2407.15049, 2024
-
[16]
Yicheng Huang, Wanyu Zhang, Hongpei Li, Dongdong Ge, Huikang Liu, and Yinyu Ye. Restarted primal-dual hybrid conjugate gradient method for large-scale quadratic programming.arXiv preprint arXiv:2405.16160, 2024
-
[17]
A practical GPU-enhanced matrix- free primal-dual method for large-scale conic programs, 2025
Zhenwei Lin, Zikai Xiong, Dongdong Ge, and Yinyu Ye. Pdcs: A primal-dual large-scale conic programming solver with gpu enhancements.arXiv preprint arXiv:2505.00311, 2025. 24 On the Convergence of Doubly Stochastic PDHGA PREPRINT
-
[18]
Huikang Liu, Yicheng Huang, Hongpei Li, Dongdong Ge, and Yinyu Ye. Pdhcg: A scalable first-order method for large-scale competitive market equilibrium computation, 2025
work page 2025
- [19]
-
[20]
arXiv preprint arXiv:2407.19689
Haihao Lu and Jinwen Yang. Pdot: A practical primal-dual algorithm and a gpu-based solver for optimal transport. arXiv preprint arXiv:2407.19689, 2024
-
[21]
Restarted Halpern PDHG for linear programming
Haihao Lu and Jinwen Yang. Restarted halpern pdhg for linear programming.arXiv preprint arXiv:2407.16144, 2024
-
[22]
Haihao Lu and Jinwen Yang. A practical and optimal first-order method for large-scale convex quadratic programming.Mathematical Programming, pages 1–38, 2025
work page 2025
-
[23]
Cody Melcher, Afrooz Jalilzadeh, and Erfan Yazdandoost Hamedani. Linear convergence of a unified primal–dual algorithm for convex–concave saddle point problems with quadratic growth. 2025
work page 2025
-
[24]
Doubly Stochastic Primal-Dual Coordinate Method for Bilinear Saddle-Point Problem
Adams Wei Yu, Qihang Lin, and Tianbao Yang. Doubly stochastic primal-dual coordinate method for bilinear saddle-point problem.arXiv preprint arXiv:1508.03390, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Solving large multicommodity network flow problems on gpus.arXiv preprint arXiv:2501.17996, 2025
Fangzhao Zhang and Stephen Boyd. Solving large multicommodity network flow problems on gpus.arXiv preprint arXiv:2501.17996, 2025
-
[26]
Guojun Zhang, Zhexuan Gu, Yancheng Yuan, and Defeng Sun. Hot: An efficient halpern accelerating algorithm for optimal transport problems.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 25
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.