Spatial Blindness in Whole-Slide Multiple Instance Learning
Pith reviewed 2026-05-20 14:42 UTC · model grok-4.3
The pith
Many strong whole-slide MIL models keep nearly the same accuracy after patch coordinates are randomly permuted, showing they rely on feature composition rather than spatial layout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
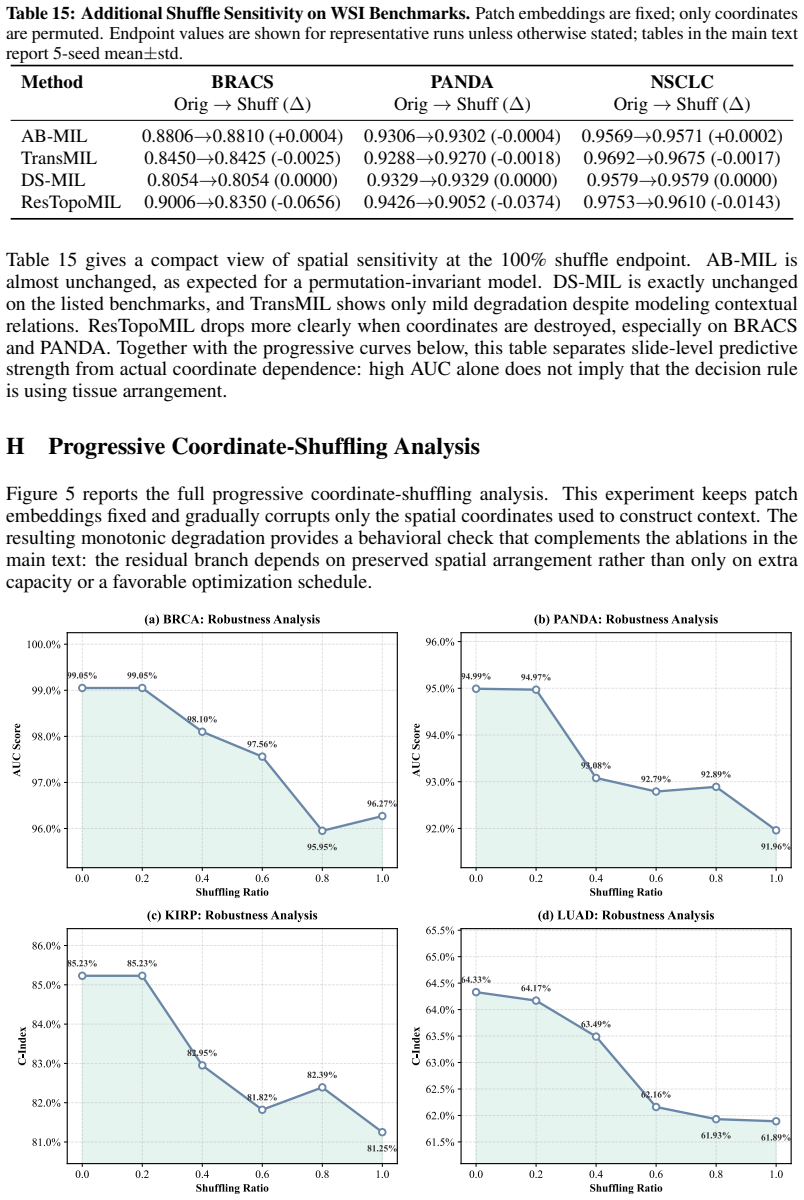
The paper establishes that many context-aware MIL architectures for whole-slide images are spatially blind because their slide-level predictions remain largely unchanged when patch coordinates are permuted. It traces the cause to early optimization toward dense appearance statistics under slide supervision. ResTopoMIL addresses the issue with a two-stage procedure: first training and freezing a permutation-invariant prototype histogram, then letting a lightweight graph branch learn the residual spatial signal under an explicit coordinate-shuffling constraint during training. This produces higher classification and survival accuracy on nine benchmarks, makes performance drop under coordinate-
What carries the argument
The ResTopoMIL two-stage training that first fits and freezes a permutation-invariant prototype histogram then trains a lightweight graph branch on the residual under a coordinate-shuffling constraint.
Load-bearing premise
The assumption that freezing a permutation-invariant prototype histogram leaves a clean residual signal that a lightweight graph branch can learn under coordinate-shuffling constraint without losing critical appearance information or introducing optimization conflicts.
What would settle it
Training ResTopoMIL on the nine benchmarks and then measuring slide-level AUC after permuting patch coordinates; if the AUC stays nearly unchanged, the claim that the method restores spatial sensitivity is false.
Figures







read the original abstract
Whole-slide MIL models are often called context-aware once graphs, Transform ers, or state-space modules are placed above patch embeddings. We show that this label can be deceptive. On pathology tasks where tissue architecture is part of the diagnostic signal, several strong MIL baselines retain nearly unchanged slide level AUC after patch coordinates are permuted. Their predictions are accurate, but largely compositional. We refer to this failure mode as spatial blindness. Our explanation is optimization-based: dense appearance statistics are learned early under slide-level supervision, leaving weak gradients for sparse spatial relations. ResTopoMIL addresses the issue by first fitting a permutation-invariant prototype histogram and then freezing it while a lightweight graph branch learns the residual under a coordinate-shuffling constraint. The architecture is simple by design; the intervention is in how the spatial branch is trained. Across 9 public WSI bench marks, ResTopoMIL improves classification and survival prediction with 1.15M parameters, restores sensitivity to coordinate perturbation, and gives stronger lo calization evidence on CAMELYON-16.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard whole-slide MIL models for pathology are often spatially blind: strong baselines retain nearly unchanged slide-level AUC after patch coordinates are permuted, indicating that predictions rely on dense compositional appearance statistics rather than tissue architecture. ResTopoMIL addresses this by first fitting a permutation-invariant prototype histogram on appearance embeddings, freezing it, and training a lightweight graph branch on the residual under an explicit coordinate-shuffling constraint. The approach is shown to restore permutation sensitivity while improving classification and survival prediction across 9 WSI benchmarks with only 1.15M parameters and yielding stronger localization on CAMELYON-16.
Significance. If the central claim and experimental results hold, the work identifies a previously under-appreciated optimization failure mode in spatial MIL modules and supplies a simple, low-parameter training intervention that demonstrably increases spatial awareness. The explicit permutation test, multi-benchmark gains, and localization evidence would make the contribution practically relevant for computational pathology tasks where architecture is diagnostically important.
major comments (2)
- The load-bearing assumption that freezing the permutation-invariant prototype histogram cleanly isolates a spatial residual (leaving only sparse relations for the graph branch) is not sufficiently supported. If appearance clusters are regionally biased (e.g., tumor vs. stroma), the frozen histogram may remove information the graph needs; conversely, residual appearance correlations could still be exploited post-shuffle. An ablation or prototype-distribution analysis is required to substantiate that the residual is genuinely spatial.
- The permutation test establishing spatial blindness (retained AUC after coordinate permutation) is central to the diagnosis, yet the manuscript provides no details on the permutation procedure, number of permutations performed, exact data splits used, or statistical tests confirming that AUC changes are insignificant. Without these, the claim that baselines are 'largely compositional' rests on unverified experimental details.
minor comments (2)
- Abstract: 'bench marks' should be written as a single word 'benchmarks'.
- The description of the graph branch training under the shuffling constraint would benefit from an explicit statement of the loss terms and how the coordinate-shuffling constraint is enforced during optimization.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight areas where our presentation of the methodology and experiments can be strengthened. We respond to each major comment below and will incorporate the suggested clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: The load-bearing assumption that freezing the permutation-invariant prototype histogram cleanly isolates a spatial residual (leaving only sparse relations for the graph branch) is not sufficiently supported. If appearance clusters are regionally biased (e.g., tumor vs. stroma), the frozen histogram may remove information the graph needs; conversely, residual appearance correlations could still be exploited post-shuffle. An ablation or prototype-distribution analysis is required to substantiate that the residual is genuinely spatial.
Authors: We agree that further empirical support is needed to confirm that the frozen prototype histogram isolates a primarily spatial residual. In the revised manuscript we will add an ablation that trains the graph branch both with and without freezing the histogram, and we will include a prototype-distribution analysis that visualizes the spatial distribution of the learned prototypes across tissue regions (tumor versus stroma) on CAMELYON-16. These additions will directly address the concern about possible residual appearance correlations and will also note the limitation when appearance clusters are strongly regionally biased. revision: yes
-
Referee: The permutation test establishing spatial blindness (retained AUC after coordinate permutation) is central to the diagnosis, yet the manuscript provides no details on the permutation procedure, number of permutations performed, exact data splits used, or statistical tests confirming that AUC changes are insignificant. Without these, the claim that baselines are 'largely compositional' rests on unverified experimental details.
Authors: We acknowledge that the experimental protocol for the permutation test was under-specified. The revised Methods section will explicitly describe the procedure (random coordinate shuffling while preserving the multiset of patch embeddings), state that five independent permutations were performed per slide, confirm that the same train/validation/test splits as the main experiments were used, and report paired t-tests across slides showing that AUC differences for the baselines are statistically insignificant (p > 0.05). These details will be added to both the main text and the supplementary material. revision: yes
Circularity Check
No circularity: training schedule is an empirical intervention, not a self-referential derivation
full rationale
The paper presents ResTopoMIL as an optimization procedure—fitting a permutation-invariant prototype histogram on appearance embeddings, freezing it, and training a lightweight graph branch on the residual under a coordinate-shuffling constraint—rather than a closed-form derivation or mathematical claim. No equations are provided that reduce the final performance or sensitivity metric to the inputs by construction. The central observations (unchanged AUC after permutation in baselines) and improvements are evaluated empirically across 9 WSI benchmarks with explicit metrics, and no self-citations are used to justify uniqueness theorems or ansatzes. The approach is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dense appearance statistics are learned early under slide-level supervision, leaving weak gradients for sparse spatial relations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ResTopoMIL addresses the issue by first fitting a permutation-invariant prototype histogram and then freezing it while a lightweight graph branch learns the residual under a coordinate-shuffling constraint.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A coordinate-shuffling operator π keeps {h_i} fixed and permutes {p_i}. This preserves composition but destroys adjacency and tissue architecture.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of pathology informatics , volume=
Review of the current state of whole slide imaging in pathology , author=. Journal of pathology informatics , volume=. 2011 , publisher=
work page 2011
-
[2]
The Journal of pathology , volume=
Computational pathology in cancer diagnosis, prognosis, and prediction--present day and prospects , author=. The Journal of pathology , volume=. 2023 , publisher=
work page 2023
-
[3]
Nature Reviews Bioengineering , volume=
Artificial intelligence for digital and computational pathology , author=. Nature Reviews Bioengineering , volume=. 2023 , publisher=
work page 2023
-
[4]
Artificial intelligence , volume=
Solving the multiple instance problem with axis-parallel rectangles , author=. Artificial intelligence , volume=. 1997 , publisher=
work page 1997
-
[5]
Advances in neural information processing systems , volume=
A framework for multiple-instance learning , author=. Advances in neural information processing systems , volume=
-
[6]
Clinical-grade computational pathology using weakly supervised deep learning on whole slide images , author=. Nature medicine , volume=. 2019 , publisher=
work page 2019
-
[7]
Nature biomedical engineering , volume=
Data-efficient and weakly supervised computational pathology on whole-slide images , author=. Nature biomedical engineering , volume=. 2021 , publisher=
work page 2021
-
[8]
Microenvironmental regulation of tumor progression and metastasis , author=. Nature medicine , volume=. 2013 , publisher=
work page 2013
-
[9]
Frontiers in Oncology , volume=
Computational image analysis identifies histopathological image features associated with somatic mutations and patient survival in gastric adenocarcinoma , author=. Frontiers in Oncology , volume=. 2021 , publisher=
work page 2021
-
[10]
Nature communications , volume=
Predicting gastric cancer outcome from resected lymph node histopathology images using deep learning , author=. Nature communications , volume=. 2021 , publisher=
work page 2021
-
[11]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Whole slide images are 2d point clouds: Context-aware survival prediction using patch-based graph convolutional networks , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2021 , organization=
work page 2021
-
[12]
Medical image analysis , volume=
Hierarchical graph representations in digital pathology , author=. Medical image analysis , volume=. 2022 , publisher=
work page 2022
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
Representation learning of histopathology images using graph neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[14]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[15]
Advances in neural information processing systems , volume=
Transmil: Transformer based correlated multiple instance learning for whole slide image classification , author=. Advances in neural information processing systems , volume=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scaling vision transformers to gigapixel images via hierarchical self-supervised learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
International Conference on Learning Representations , year=
Efficiently Modeling Long Sequences with Structured State Spaces , author=. International Conference on Learning Representations , year=
-
[18]
International conference on medical image computing and computer-assisted intervention , pages=
Mambamil: Enhancing long sequence modeling with sequence reordering in computational pathology , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2024 , organization=
work page 2024
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
2dmamba: Efficient state space model for image representation with applications on giga-pixel whole slide image classification , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
The pitfalls of simplicity bias in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[22]
European conference on computer vision , pages=
Unsupervised learning of visual representations by solving jigsaw puzzles , author=. European conference on computer vision , pages=. 2016 , organization=
work page 2016
-
[23]
Advances in Neural Information Processing Systems , volume=
Gradient starvation: A learning proclivity in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Medical image analysis , volume=
Weakly supervised histopathology cancer image segmentation and classification , author=. Medical image analysis , volume=. 2014 , publisher=
work page 2014
-
[25]
Classifying and segmenting microscopy images with deep multiple instance learning , author=. Bioinformatics , volume=. 2016 , publisher=
work page 2016
-
[26]
2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017) , pages=
Classifying histopathology whole-slides using fusion of decisions from deep convolutional network on a collection of random multi-views at multi-magnification , author=. 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017) , pages=. 2017 , organization=
work page 2017
-
[27]
2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) , pages=
Multiple instance learning of deep convolutional neural networks for breast histopathology whole slide classification , author=. 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) , pages=. 2018 , organization=
work page 2018
-
[28]
IEEE transactions on cybernetics , volume=
Weakly supervised deep learning for whole slide lung cancer image analysis , author=. IEEE transactions on cybernetics , volume=. 2019 , publisher=
work page 2019
-
[29]
Nature communications , volume=
An annotation-free whole-slide training approach to pathological classification of lung cancer types using deep learning , author=. Nature communications , volume=. 2021 , publisher=
work page 2021
-
[30]
International conference on machine learning , pages=
Attention-based deep multiple instance learning , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dtfd-mil: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Multiple instance learning framework with masked hard instance mining for whole slide image classification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Interventional bag multi-instance learning on whole-slide pathological images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
European conference on computer vision , pages=
Attention-challenging multiple instance learning for whole slide image classification , author=. European conference on computer vision , pages=. 2024 , organization=
work page 2024
-
[36]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
AEM: attention entropy maximization for multiple instance learning based whole slide image classification , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
work page 2025
-
[37]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Rethinking multiple instance learning for whole slide image classification: A good instance classifier is all you need , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2024 , publisher=
work page 2024
-
[38]
Proceedings of Machine Learning Research , volume=
Do Multiple Instance Learning Models Transfer? , author=. Proceedings of Machine Learning Research , volume=. 2025 , publisher=
work page 2025
-
[39]
International Conference on Machine Learning , pages=
How Effective Can Dropout Be in Multiple Instance Learning? , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[40]
arXiv preprint arXiv:2308.10112 , year=
Pdl: Regularizing multiple instance learning with progressive dropout layers , author=. arXiv preprint arXiv:2308.10112 , year=
-
[41]
Proceedings of the AAAI conference on artificial intelligence , volume=
Bag graph: Multiple instance learning using bayesian graph neural networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[42]
Xiong, Yunyang and Zeng, Zhanpeng and Chakraborty, Rudrasis and Tan, Mingxing and Fung, Glenn and Li, Yin and Singh, Vikas , booktitle=. Nystr
-
[43]
The Eleventh International Conference on Learning Representations , year=
Exploring low-rank property in multiple instance learning for whole slide image classification , author=. The Eleventh International Conference on Learning Representations , year=
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A joint spatial and magnification based attention framework for large scale histopathology classification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Higt: Hierarchical interaction graph-transformer for whole slide image analysis , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2023 , organization=
work page 2023
-
[46]
arXiv preprint arXiv:2411.18225 , year=
Paths: A hierarchical transformer for efficient whole slide image analysis , author=. arXiv preprint arXiv:2411.18225 , year=
-
[47]
IEEE transactions on medical imaging , volume=
Navigating through whole slide images with hierarchy, Multi-Object, and Multi-Scale data , author=. IEEE transactions on medical imaging , volume=. 2025 , publisher=
work page 2025
-
[48]
The Twelfth International Conference on Learning Representations , year=
Olga Fourkioti and Matt. The Twelfth International Conference on Learning Representations , year=
-
[49]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Camil: Causal multiple instance learning for whole slide image classification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[50]
Proceedings of the 26th annual international conference on machine learning , pages=
Multi-instance learning by treating instances as non-iid samples , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Multiple instance learning on structured data , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
arXiv preprint arXiv:2308.15474 , year=
A general-purpose self-supervised model for computational pathology , author=. arXiv preprint arXiv:2308.15474 , year=
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Benchmarking self-supervised learning on diverse pathology datasets , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[54]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Visual language pretrained multiple instance zero-shot transfer for histopathology images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Gecko: Gigapixel vision-concept contrastive pretraining in histopathology , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vila-mil: Dual-scale vision-language multiple instance learning for whole slide image classification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
IEEE Transactions on Medical Imaging , year=
Mscpt: Few-shot whole slide image classification with multi-scale and context-focused prompt tuning , author=. IEEE Transactions on Medical Imaging , year=
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Few-Shot Learning from Gigapixel Images via Hierarchical Vision-Language Alignment and Modeling , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI) , pages=
Slide-Level Prompt Learning with Vision Language Models for Few-Shot Multiple Instance Learning in Histopathology , author=. 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI) , pages=. 2025 , organization=
work page 2025
-
[62]
Proceedings of the AAAI conference on artificial intelligence , volume=
Queryable prototype multiple instance learning with vision-language models for incremental whole slide image classification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[63]
Advances in neural information processing systems , volume=
Deep sets , author=. Advances in neural information processing systems , volume=
-
[64]
IEEE Transactions on Artificial Intelligence , volume=
Histogram layers for texture analysis , author=. IEEE Transactions on Artificial Intelligence , volume=. 2021 , publisher=
work page 2021
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Morphological prototyping for unsupervised slide representation learning in computational pathology , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[66]
IEEE transactions on neural networks and learning systems , volume=
Scalable algorithms for multi-instance learning , author=. IEEE transactions on neural networks and learning systems , volume=. 2016 , publisher=
work page 2016
-
[67]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
work page 1948
-
[68]
Bracs: A dataset for breast carcinoma subtyping in h&e histology images , author=. Database , volume=. 2022 , publisher=
work page 2022
-
[69]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer , author=. Jama , volume=
- [70]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.