Mixture-of-Experts Can Surpass Dense LLMs Under Strictly Equal Resource
Pith reviewed 2026-05-21 23:59 UTC · model grok-4.3
The pith
An MoE model with activation rate in an optimal region outperforms its dense counterpart under identical total parameters, training compute, and data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under strictly equal total parameter count, training compute, and data budget, an MoE model whose activation rate lies in an optimal region outperforms a dense model of equivalent resources. This optimal activation region remains consistent across different model scales. The claim is established through systematic architecture exploration followed by large-scale training runs that isolate the effect of activation rate while holding every other resource fixed.
What carries the argument
The optimal activation rate region, which sets the fraction of experts activated per token to maximize performance at fixed total model capacity.
If this is right
- MoE models can achieve higher performance than dense models without any increase in total parameters, compute, or data when activation rate is set inside the optimal region.
- The stability of the optimal region across scales supplies a practical rule for choosing activation rates in larger MoE designs.
- Reusing training data can substitute for additional data to reach the performance gains associated with higher data budgets.
- Equal-resource comparisons show that architectural sparsity, when tuned correctly, can be strictly superior to dense density under the same constraints.
Where Pith is reading between the lines
- If the optimal region persists at frontier scales, scaling strategies may shift from uniform size increases toward deliberate control of per-token activation fractions.
- The result invites tests of whether analogous optimal regions appear in other sparse or routed architectures beyond standard MoE.
- Dynamic adjustment of activation rate during training could be explored to keep models inside the high-performance band without changing total capacity.
Load-bearing premise
Training procedure, optimizer settings, data ordering, and evaluation protocol are identical between the MoE and dense runs, with no hidden advantages from MoE-specific code or extra hyperparameter search.
What would settle it
A controlled run of an MoE model and its dense counterpart at matched total parameters, compute, and data, with the MoE activation rate inside the claimed optimal region, that shows the MoE failing to exceed the dense model's benchmark scores.
Figures




read the original abstract
Mixture-of-Experts (MoE) language models dramatically expand model capacity and achieve remarkable performance without increasing per-token compute. However, can MoEs surpass dense architectures under strictly equal resource constraints -- that is, when the total parameter count, training compute, and data budget are identical? This question remains under-explored despite its significant practical value and potential. In this paper, we propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design that maximizes the performance. Based on this, we subsequently find that an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes. Although additional amount of data turns out to be a trade-off for enhanced performance, we show that this can be resolved via reusing data. We validate our findings through extensive experiments, training nearly 200 language models at 2B scale and over 50 at 7B scale, cumulatively processing 50 trillion tokens. All model checkpoints are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Mixture-of-Experts (MoE) models can outperform dense LLMs under strictly equal resource constraints (identical total parameter count, training compute, and data budget). After optimizing MoE architecture, the authors identify an optimal activation-rate region that yields superior performance; this region is consistent across scales. Data reuse is used to balance any compute trade-offs. The claim is supported by training nearly 200 models at 2B scale and over 50 at 7B scale (cumulatively 50T tokens), with all checkpoints released.
Significance. If the empirical result is robust, it would have substantial implications for scaling laws and efficient LLM design by showing that sparse activation can deliver gains without extra parameters, FLOPs, or unique data. The volume of trained models and public checkpoint release are clear strengths that aid reproducibility.
major comments (3)
- [Experimental Setup / Training Procedure] The central claim of strictly equal training compute is load-bearing. With total parameters fixed and activation rate r < 1, per-token FLOPs for MoE are lower than for the dense baseline. The abstract states that the 'additional amount of data' trade-off is resolved via 'reusing data,' but the experimental setup section does not specify whether the dense models receive the same number of epochs or whether data reuse is applied identically to both architectures. Without this, apparent gains could arise from differential data exposure rather than architecture.
- [Results and Analysis (2B and 7B experiments)] Results sections reporting superiority in the optimal activation region provide no error bars, standard deviations across runs, or statistical significance tests. Given that the optimal region appears identified from the same set of training runs used to demonstrate outperformance, post-hoc selection bias cannot be ruled out and weakens confidence in the cross-scale consistency claim.
- [Scaling Experiments] Table or figure presenting the optimal activation region (likely in the scaling-consistency subsection) should include side-by-side performance deltas for both 2B and 7B models at matched activation rates to demonstrate that the region is not an artifact of scale-specific hyperparameter tuning.
minor comments (2)
- [Introduction] Clarify the precise definition of 'activation rate' and how it is measured (e.g., average active experts per token) in the first paragraph of the introduction for readers outside the MoE subfield.
- [Figures 3-5] Ensure all figures showing loss curves or performance vs. activation rate have consistent axis scaling and legend placement across the 2B and 7B panels.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of experimental clarity, statistical reporting, and cross-scale analysis that we will address to strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experimental Setup / Training Procedure] The central claim of strictly equal training compute is load-bearing. With total parameters fixed and activation rate r < 1, per-token FLOPs for MoE are lower than for the dense baseline. The abstract states that the 'additional amount of data' trade-off is resolved via 'reusing data,' but the experimental setup section does not specify whether the dense models receive the same number of epochs or whether data reuse is applied identically to both architectures. Without this, apparent gains could arise from differential data exposure rather than architecture.
Authors: We agree that explicit documentation of the data and compute equalization procedure is necessary to support the central claim. The manuscript intended to enforce identical total training compute and data budgets for both architectures by applying any required data reuse (multiple epochs) uniformly. However, we acknowledge that the experimental setup section does not provide sufficient detail on this point. In the revision, we will expand the relevant section to explicitly state that both MoE and dense models are trained for the same number of epochs over the shared data corpus, with data reuse applied identically to both to maintain strictly equal data exposure and total compute. revision: yes
-
Referee: [Results and Analysis (2B and 7B experiments)] Results sections reporting superiority in the optimal activation region provide no error bars, standard deviations across runs, or statistical significance tests. Given that the optimal region appears identified from the same set of training runs used to demonstrate outperformance, post-hoc selection bias cannot be ruled out and weakens confidence in the cross-scale consistency claim.
Authors: We appreciate the concern regarding statistical robustness and potential selection bias. Given the scale of the study (nearly 250 models and 50T tokens), full multi-seed replication for every configuration was not feasible. In the revision we will add error bars and standard deviations for all configurations where multiple independent runs were performed, and we will include a clearer description of how the optimal activation region was first identified on a subset of runs before being validated on the full set. While we cannot retroactively add statistical tests to every single-run result, the observed consistency of the optimal region across two independent scales provides additional support for the finding. revision: partial
-
Referee: [Scaling Experiments] Table or figure presenting the optimal activation region (likely in the scaling-consistency subsection) should include side-by-side performance deltas for both 2B and 7B models at matched activation rates to demonstrate that the region is not an artifact of scale-specific hyperparameter tuning.
Authors: We agree that a direct comparative presentation would better demonstrate cross-scale consistency. In the revised manuscript we will add or augment the relevant table/figure in the scaling-consistency subsection to show side-by-side performance numbers and deltas for the 2B and 7B models at identical activation rates, allowing readers to verify that the optimal region and performance gains are not driven by scale-specific tuning. revision: yes
Circularity Check
Empirical training results with minor self-citation not load-bearing for central claim
full rationale
The paper reports direct experimental outcomes from training nearly 200 models at 2B scale and over 50 at 7B scale on 50T tokens total. The core finding—that an optimal activation-rate region allows MoE to outperform dense models under matched total parameters, compute, and data—is an observed result from these runs rather than a closed derivation. No equations or steps reduce a prediction to a fitted input by construction. Self-citations to prior MoE scaling literature exist but are not invoked as uniqueness theorems or ansatzes that force the main result; the optimal region is located via the new experiments themselves. This qualifies as at most minor non-load-bearing self-citation, yielding score 2 with no circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- optimal activation rate region
axioms (1)
- domain assumption Training dynamics and final performance are comparable when total parameter count, FLOPs, and token count are matched between architectures.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
DECO: Sparse Mixture-of-Experts with Dense-Comparable Performance on End-Side Devices
DECO sparse MoE matches dense Transformer performance at 20% expert activation with a 3x hardware inference speedup.
-
DECO: Sparse Mixture-of-Experts with Dense-Comparable Performance on End-Side Devices
DECO matches dense model performance at 20% expert activation via ReLU-based routing with learnable scaling and the NormSiLU activation, plus a 3x real-hardware speedup.
-
DECO: Sparse Mixture-of-Experts with Dense-Comparable Performance on End-Side Devices
DECO is a sparse MoE architecture with ReLU-based routing, learnable expert scaling, and NormSiLU activation that matches dense Transformer performance at 20% expert activation and delivers 2.93x speedup on Jetson AGX Orin.
Reference graph
Works this paper leans on
-
[1]
Parameters vs flops: Scaling laws for optimal sparsity for mixture-of-experts language models
Samira Abnar, Harshay Shah, Dan Busbridge, Alaaeldin Mohamed Elnouby Ali, Josh Susskind, and Vimal Thilak. Parameters vs flops: Scaling laws for optimal sparsity for mixture-of-experts language models. arXiv preprint arXiv:2501.12370,
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
PIQA: Reasoning about Physical Commonsense in Natural Language
Yonatan Bisk, Rowan Zellers, J Gao, and Y Choi. Piqa: reasoning about physical commonsense in natural language. corr, vol. abs/1911.11641,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture- of-experts language models. arXiv preprint arXiv:2401.06066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI, :, Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, and et al. Deepseek llm: Scaling open-source language models with longtermism, 2024a. URL https: //arxiv.org/abs/2401.02954. DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, and etc. Deepseek-v3 technical report, 2024b. URL https://arxiv.org/abs/2412.19437. ...
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[11]
Are we done with mmlu? CoRR, abs/2406.04127,
10 Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. Are we done with mmlu? arXiv preprint arXiv:2406.04127,
-
[12]
Upcycling large language models into mixture of experts
Ethan He, Abhinav Khattar, Ryan Prenger, Vijay Korthikanti, Zijie Yan, Tong Liu, Shiqing Fan, Ashwath Aithal, Mohammad Shoeybi, and Bryan Catanzaro. Upcycling large language models into mixture of experts. arXiv preprint arXiv:2410.07524,
-
[13]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[14]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Scaling Laws and Interpretability of Learning from Repeated Data
URL https://arxiv.org/abs/ 2205.10487. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yi Hu, Xiaojuan Tang, Haotong Yang, and Muhan Zhang. Case-based or rule-based: How do transformers do the math? In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[17]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
URL https://openreview. net/forum?id=4Vqr8SRfyX. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Sparse upcycling: Training mixture-of-experts from dense checkpoints
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of- experts from dense checkpoints. arXiv preprint arXiv:2212.05055,
-
[20]
RACE: Large-scale ReAding comprehension dataset from examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Martha Palmer, Rebecca Hwa, and Sebastian Riedel, editors, Proceedings of the 2017 Conference on Empirical Methods in Natural Language Pro- cessing, pages 785–794, Copenhagen, Denmark, September
work page 2017
-
[21]
Association for Computational Linguistics. doi: 10.18653/v1/D17-1082. URL https://aclanthology.org/D17-1082/. 11 Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machi...
-
[22]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[23]
CMMLU: Measuring massive multitask language understanding in Chinese
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Predictable scale: Part i–optimal hyperparameter scaling law in large language model pretraining
Houyi Li, Wenzhen Zheng, Jingcheng Hu, Qiufeng Wang, Hanshan Zhang, Zili Wang, Shijie Xuyang, Yuantao Fan, Shuigeng Zhou, Xiangyu Zhang, et al. Predictable scale: Part i–optimal hyperparameter scaling law in large language model pretraining. arXiv preprint arXiv:2503.04715,
-
[25]
A closer look into mixture-of-experts in large language models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, and Jie Fu. A closer look into mixture-of-experts in large language models. arXiv preprint arXiv:2406.18219,
-
[26]
URL https://arxiv.org/ abs/2502.05172. Niklas Muennighoff, Alexander Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin A Raffel. Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36:50358–50376,
-
[27]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URL https://arxiv.org/abs/2412.15115. Alec Radford. Improving language understanding by generative pre-training
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi
URL https://arxiv.org/abs/ 2201.05596. Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM , 64(9):99–106,
-
[31]
SocialIQA: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[32]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[33]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning. arXiv preprint arXiv:2310.16049,
-
[35]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
12 Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Lucas Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Skywork-moe: A deep dive into training techniques for mixture-of-experts language models
Tianwen Wei, Bo Zhu, Liang Zhao, Cheng Cheng, Biye Li, Weiwei Lü, Peng Cheng, Jianhao Zhang, Xiaoyu Zhang, Liang Zeng, et al. Skywork-moe: A deep dive into training techniques for mixture-of-experts language models. arXiv preprint arXiv:2406.06563,
-
[39]
Crowdsourcing Multiple Choice Science Questions
Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. arXiv preprint arXiv:1707.06209,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz- Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. Livebench: A challenging, contamination- free llm benchmark. arXiv preprint arXiv:2406.19314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Yuan 2.0-m32: Mixture of experts with attention router
Shaohua Wu, Jiangang Luo, Xi Chen, Lingjun Li, Xudong Zhao, Tong Yu, Chao Wang, Yue Wang, Fei Wang, Weixu Qiao, et al. Yuan 2.0-m32: Mixture of experts with attention router. arXiv preprint arXiv:2405.17976,
-
[42]
Clue: A chinese language understanding evaluation benchmark
Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. Clue: A chinese language understanding evaluation benchmark. arXiv preprint arXiv:2004.05986,
-
[43]
Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You
URL https://arxiv.org/abs/ 2305.13230. Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You. Openmoe: An early effort on open mixture-of-experts language models. arXiv preprint arXiv:2402.01739,
-
[44]
URL https://arxiv.org/abs/2407.10671. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[45]
Evaluating the Performance of Large Language Models on GAOKAO Benchmark
Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. Evaluating the performance of large language models on gaokao benchmark. arXiv preprint arXiv:2305.12474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts
Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, and Jianfeng Gao. Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts. arXiv preprint arXiv:2407.09590,
-
[47]
Moefication: Transformer feed-forward layers are mixtures of experts
Zhengyan Zhang, Yankai Lin, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. Moefication: Transformer feed-forward layers are mixtures of experts. arXiv preprint arXiv:2110.01786,
-
[48]
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364,
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
14 A Background: Mixture-of-Experts The MoE architecture primarily consists of a gate and several experts. Typically, the gate g(·) is com- posed of a linear layer Wg followed by a Softmax and a Top-K operation, and the experts Ei=1,...N follow the standard FFN structure. The computation of an MoE block can then be represented as follows: y = NX i=1 gi(x)...
work page 2025
-
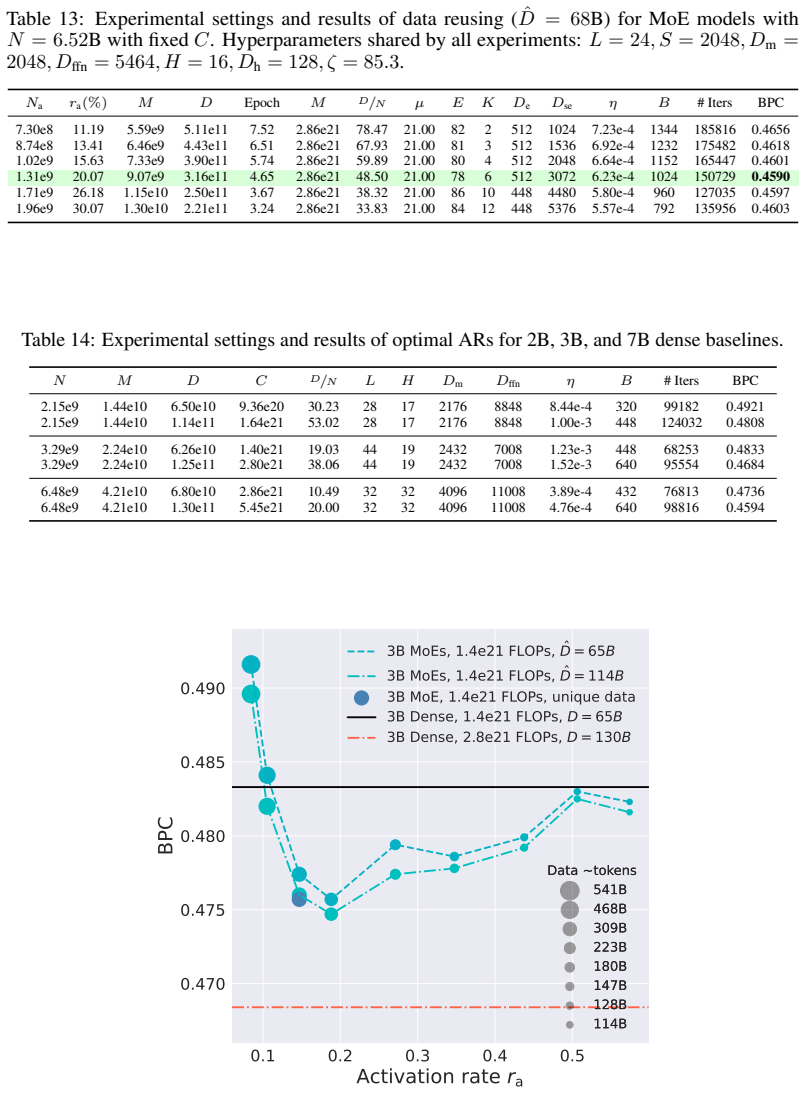
[51]
find that the optimal sparsity increases with model size. Our conclusion regarding a consistent optimal activation rate contradicts the findings of Abnar et al. [2025]. While we believe our findings are reliable, given that our experiments are conducted with strictly controlled variables using optimized backbones and sufficient training data, we acknowled...
work page 2025
-
[52]
Symbol Definition D Dataset size in tokens
Table 3: Notation. Symbol Definition D Dataset size in tokens. M Compute (w/o embedding) per token in FLOPs. C Total training compute in FLOPs, i.e., M · D. N Number of non-vocabulary parameters. Na Number of activated parameters. ra Activation rate, i.e., Na/N. Le Number of MoE layers. Ld Number of dense layers. L Number of total layers, i.e., Le + Ld. S...
work page 2022
-
[53]
N N a Dm Dffn L H E K D e Dse µ ζ L 2.15e9 3.67e8 640 1774 34 5 50 4 608 2432 51.30 20.39 1.694 2.15e9 3.69e8 640 1774 37 5 38 3 736 2208 47.15 18.78 1.696 2.14e9 3.69e8 640 1774 49 5 41 3 512 1536 35.20 14.33 1.695 2.14e9 3.67e8 768 2129 20 6 99 8 448 3584 62.42 41.42 1.693 2.15e9 3.69e8 896 2484 15 7 124 10 416 4160 62.21 65.00 1.699 2.15e9 3.68e8 896 2...
work page 1920
-
[54]
Na ra (%) M D C D/N E K D e Dse η B # Iters BPC 1.88e8 8.74 1.68e9 1.14e11 1.92e20 53 89 1 352 352 2.01e-3 672 82833 0.5235 1.88e8 8.74 1.68e9 1.68e11 2.83e20 78 89 1 352 352 2.26e-3 832 98771 0.5159 1.88e8 8.74 1.68e9 3.67e11 6.16e20 170 89 1 352 352 2.87e-3 1344 133187 0.5090 1.88e8 8.74 1.68e9 5.41e11 9.10e20 252 89 1 352 352 3.24e-3 1728 152927 0.5048...
work page 2048
-
[55]
Na ra(%) M D C D/N µ E K D e Dse η B # Iters BPC 1.88e8 8.74 1.70e9 5.41e11 9.18e20 252 22.50 89 1 352 352 3.24e-3 1728 152927 0.5048 2.33e8 10.82 1.96e9 4.68e11 9.19e20 218 22.50 88 2 352 704 3.10e-3 1600 142822 0.4967 3.24e8 15.04 2.50e9 3.75e11 9.38e20 174 22.50 86 4 352 1408 2.89e-3 1344 136378 0.4896 3.68e8 17.11 2.77e9 3.39e11 9.38e20 158 22.50 85 5...
work page 1920
-
[56]
Hyperparameters shared by all experiments: L = 24, S = 2048, Dm = 1408, Dffn = 3904, H = 11, Dh =
Na ra(%) D Epoch M C D/N E K D e Dse η B # Iters BPC 2.78e8 8.46 5.41e11 8.33 2.51e9 1.36e21 164.62 89 1 352 352 3.24e-3 1728 152927 0.4916 3.47e8 10.54 4.68e11 7.20 2.92e9 1.36e21 142.36 88 2 352 704 3.10e-3 1600 142822 0.4841 4.83e8 14.70 3.75e11 5.78 3.74e9 1.40e21 114.19 86 4 352 1408 2.89e-3 1344 136378 0.4774 6.20e8 18.83 3.09e11 4.76 4.56e9 1.41e21...
work page 2048
-
[57]
Hyperparameters shared by all experiments: L = 24, S = 2048, Dm = 2048, Dffn = 5464, H = 16, Dh =
Na ra(%) D Epoch M C D/N E K D e Dse η B # Iters BPC 2.78e8 8.46 5.41e11 4.75 2.51e9 1.36e21 164.62 89 1 352 352 3.24e-3 1728 152927 0.4896 3.47e8 10.54 4.68e11 4.11 2.92e9 1.36e21 142.36 88 2 352 704 3.10e-3 1600 142822 0.4820 4.83e8 14.70 3.75e11 3.29 3.74e9 1.40e21 114.19 86 4 352 1408 2.89e-3 1344 136378 0.4760 6.20e8 18.83 3.09e11 2.71 4.56e9 1.41e21...
work page 2048
-
[58]
Na ra(%) ˆD M C D/N E K D e Dse η B # Iters BPC 7.30e8 11.19 2.56e11 5.59e9 2.86e21 78.47 82 2 512 1024 7.23e-4 1344 185816 0.4591 8.74e8 13.41 2.21e11 6.46e9 2.86e21 67.93 81 3 512 1536 6.92e-4 1232 175482 0.4557 1.02e9 15.63 1.95e11 7.33e9 2.86e21 59.89 80 4 512 2048 6.64e-4 1152 165447 0.4550 1.31e9 20.07 1.58e11 9.07e9 2.87e21 48.50 78 6 512 3072 6.23...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.