Few-shot Multi-Task Learning of Linear Invariant Features with Meta Subspace Pursuit
Pith reviewed 2026-05-23 20:49 UTC · model grok-4.3
The pith
Meta Subspace Pursuit learns the invariant low-rank subspace shared across multiple linear tasks with provable guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the assumption that model coefficients across tasks share an invariant low-rank component, the Meta Subspace Pursuit algorithm provably learns this invariant subspace, with both algorithmic and statistical guarantees established for the multi-task linear model setup.
What carries the argument
Meta Subspace Pursuit (Meta-SP), an iterative algorithm that identifies the common low-rank subspace shared by task coefficients.
If this is right
- The algorithm converges to the true shared subspace as the number of tasks and samples grows.
- Statistical rates bound the error in the recovered features and downstream task predictions.
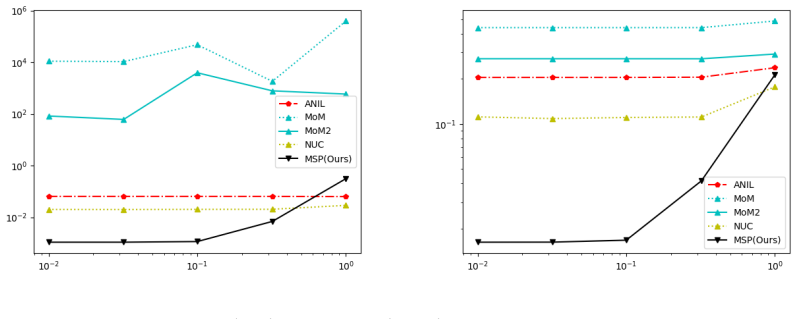
- The procedure yields better few-shot performance than model-agnostic alternatives on linear tasks satisfying the low-rank assumption.
- The guarantees apply directly to the stylized multi-task linear regression setting considered.
Where Pith is reading between the lines
- The subspace recovery step could be inserted as a preprocessing module before applying other meta-learning updates on non-linear models.
- If the low-rank component is only approximately shared, the method might still provide useful initializations whose quality degrades gracefully with the approximation error.
- The same pursuit idea could be tested on sequential task arrival, where each new task refines the current estimate of the invariant subspace.
Load-bearing premise
The coefficients of the linear models for different tasks share an invariant low-rank component.
What would settle it
A controlled simulation in which the shared subspace is known in advance but Meta-SP fails to recover it at the claimed rate when sample sizes and task counts meet the paper's conditions.
Figures














read the original abstract
Data scarcity poses a serious threat to modern machine learning and artificial intelligence, as their practical success typically relies on the availability of big datasets. One effective strategy to mitigate the issue of insufficient data is to first harness information from other data sources possessing certain similarities in the study design stage, and then employ the multi-task or meta learning framework in the analysis stage. In this paper, we focus on multi-task (or multi-source) linear models whose coefficients across tasks share an invariant low-rank component, a popular structural assumption considered in the recent multi-task or meta learning literature. Under this assumption, we propose a new algorithm, called Meta Subspace Pursuit (abbreviated as Meta-SP), that provably learns this invariant subspace shared by different tasks. Under this stylized setup for multi-task or meta learning, we establish both the algorithmic and statistical guarantees of the proposed method. Extensive numerical experiments are conducted, comparing Meta-SP against several competing methods, including popular, off-the-shelf model-agnostic meta learning algorithms such as ANIL. These experiments demonstrate that Meta-SP achieves superior performance over the competing methods in various aspects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Meta Subspace Pursuit (Meta-SP) for few-shot multi-task linear regression where task coefficient vectors share an invariant low-rank component. Under this structural assumption, the method is claimed to recover the shared subspace with both algorithmic convergence guarantees and statistical recovery bounds; extensive experiments compare it favorably to baselines including ANIL on synthetic and real data.
Significance. If the recovery guarantees hold, the work supplies a concrete, theoretically supported algorithm for exploiting shared low-rank structure across tasks in the few-shot regime, which is a common modeling choice in multi-task and meta-learning literature. The combination of subspace pursuit with meta-learning steps and the reported empirical gains over model-agnostic baselines constitute a modest but useful contribution.
major comments (2)
- [§4.2, Theorem 2] §4.2, Theorem 2: the statistical recovery bound for the subspace distance appears to require the number of tasks T to grow with the ambient dimension d; this dependence is not stated explicitly in the theorem statement and may limit applicability in the few-shot multi-task setting where T is moderate.
- [§3.3, Eq. (8)] §3.3, Eq. (8): the alternating minimization step for the low-rank component is analyzed under exact subspace knowledge, yet the algorithm description interleaves subspace estimation with coefficient updates; the proof sketch does not quantify the error propagation from the initial subspace estimate to the final coefficients.
minor comments (2)
- [§2] Notation for the shared subspace U is introduced in §2 but reused without redefinition in the algorithm pseudocode; a single consistent definition would improve readability.
- [Figure 3] Figure 3 caption does not specify the number of random seeds or error bars; adding this information would strengthen the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [§4.2, Theorem 2] the statistical recovery bound for the subspace distance appears to require the number of tasks T to grow with the ambient dimension d; this dependence is not stated explicitly in the theorem statement and may limit applicability in the few-shot multi-task setting where T is moderate.
Authors: We appreciate this observation. The statistical bound in Theorem 2 does require a scaling condition on T relative to d (specifically, T scaling at least linearly with d up to logarithmic factors to obtain the stated high-probability rate). We agree that this dependence should be stated explicitly rather than left implicit. In the revision we will update the statement of Theorem 2 to include the explicit condition on T and add a short paragraph discussing its implications for moderate T in the few-shot regime. revision: yes
-
Referee: [§3.3, Eq. (8)] the alternating minimization step for the low-rank component is analyzed under exact subspace knowledge, yet the algorithm description interleaves subspace estimation with coefficient updates; the proof sketch does not quantify the error propagation from the initial subspace estimate to the final coefficients.
Authors: This comment correctly identifies a presentational gap. Section 3.3 analyzes the alternating minimization for the coefficients under a fixed (exact) subspace as an intermediate building block. The overall guarantee in Section 4 combines this with the subspace estimation result, but the current proof sketch does not explicitly bound how the initial subspace error propagates through the interleaved updates. We will expand the proof to include a quantitative error-propagation argument showing that the total error is controlled by the sum of the subspace estimation error and the per-iteration optimization error, under the stated assumptions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces Meta-SP under an explicit low-rank invariant component assumption for multi-task linear models and derives algorithmic plus statistical guarantees from that stylized setup. No quoted steps reduce a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology; the central claims rest on the problem formulation rather than re-labeling inputs as outputs. This is the normal case of a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coefficients across tasks share an invariant low-rank component
Forward citations
Cited by 1 Pith paper
-
Near-optimal and Efficient First-Order Algorithm for Multi-Task Learning with Shared Linear Representation
A new first-order algorithm for multi-task learning with shared linear representation achieves near-optimal error rates in constant iterations, improving existing methods by a factor of k.
Reference graph
Works this paper leans on
-
[1]
Multitask learning via shared features: Algorithms and hardness
Konstantina Bairaktari, Guy Blanc, Li-Yang Tan, Jonathan Ullman, and Lydia Zakynthinou. Multitask learning via shared features: Algorithms and hardness. In The Thirty Sixth Annual Conference on Learning Theory , pages 747--772. PMLR, 2023
work page 2023
-
[2]
Iterative hard thresholding for compressed sensing
Thomas Blumensath and Mike E Davies. Iterative hard thresholding for compressed sensing. Applied and Computational Harmonic Analysis , 27(3):265--274, 2009
work page 2009
-
[3]
Trace norm regularization for multi-task learning with scarce data
Etienne Boursier, Mikhail Konobeev, and Nicolas Flammarion. Trace norm regularization for multi-task learning with scarce data. In Conference on Learning Theory , pages 1303--1327. PMLR, 2022
work page 2022
-
[4]
St \'e phane Boucheron, G \'a bor Lugosi, and Olivier Bousquet. Concentration inequalities. In Summer School on Machine Learning , pages 208--240. Springer, 2003
work page 2003
-
[5]
A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization
Samuel Burer and Renato DC Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization. Mathematical Programming , 95(2):329--357, 2003
work page 2003
-
[6]
A systematic review on data scarcity problem in deep learning: solution and applications
Aayushi Bansal, Rewa Sharma, and Mamta Kathuria. A systematic review on data scarcity problem in deep learning: solution and applications. ACM Computing Surveys (CSUR) , 54(10s):1--29, 2022
work page 2022
-
[7]
Statistics for high-dimensional data: methods, theory and applications
Peter B \"u hlmann and Sara van de Geer. Statistics for high-dimensional data: methods, theory and applications . Springer Science & Business Media, 2011
work page 2011
-
[8]
A singular value thresholding algorithm for matrix completion
Jian-Feng Cai, Emmanuel J Cand \`e s, and Zuowei Shen. A singular value thresholding algorithm for matrix completion. SIAM Journal on Optimization , 20(4):1956--1982, 2010
work page 1956
-
[9]
Alexandra Carpentier and Arlene KH Kim. An iterative hard thresholding estimator for low rank matrix recovery with explicit limiting distribution. Statistica Sinica , 28(3):1371--1393, 2018
work page 2018
-
[10]
Polynomial time guarantees for the B urer- M onteiro method
Diego Cifuentes and Ankur Moitra. Polynomial time guarantees for the B urer- M onteiro method. In Proceedings of the 36th International Conference on Neural Information Processing Systems , pages 23923--23935, 2022
work page 2022
-
[11]
MAML and ANIL provably learn representations
Liam Collins, Aryan Mokhtari, Sewoong Oh, and Sanjay Shakkottai. MAML and ANIL provably learn representations. In International Conference on Machine Learning , pages 4238--4310. PMLR, 2022
work page 2022
-
[12]
_1 -magic: Recovery of sparse signals via convex programming
Emmanuel Candes and Justin Romberg. _1 -magic: Recovery of sparse signals via convex programming. Technical report, California Institute of Technology, 2005
work page 2005
-
[13]
Decoding by linear programming
Emmanuel J Candes and Terence Tao. Decoding by linear programming. IEEE Transactions on Information Theory , 51(12):4203--4215, 2005
work page 2005
-
[14]
Few-shot learning via learning the representation, provably
Simon Shaolei Du, Wei Hu, Sham M Kakade, Jason D Lee, and Qi Lei. Few-shot learning via learning the representation, provably. In International Conference on Learning Representations , 2020
work page 2020
-
[15]
Universality of approximate message passing with semirandom matrices
Rishabh Dudeja, Yue M Lu, and Subhabrata Sen. Universality of approximate message passing with semirandom matrices. The Annals of Probability , 51(5):1616--1683, 2023
work page 2023
-
[16]
Subspace pursuit for compressive sensing signal reconstruction
Wei Dai and Olgica Milenkovic. Subspace pursuit for compressive sensing signal reconstruction. IEEE Transactions on Information Theory , 55(5):2230--2249, 2009
work page 2009
-
[17]
High dimensional robust M -estimation: Asymptotic variance via approximate message passing
David Donoho and Andrea Montanari. High dimensional robust M -estimation: Asymptotic variance via approximate message passing. Probability Theory and Related Fields , 166(3):935--969, 2016
work page 2016
-
[18]
Adaptive and robust multi-task learning
Yaqi Duan and Kaizheng Wang. Adaptive and robust multi-task learning. The Annals of Statistics , 51(5):2015--2039, 2023
work page 2015
-
[19]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning , pages 1126--1135. PMLR, 2017
work page 2017
-
[20]
M \'a rio AT Figueiredo, Robert D Nowak, and Stephen J Wright. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE Journal of Selected Topics in Signal Processing , 1(4):586--597, 2007
work page 2007
-
[21]
Hard thresholding pursuit: an algorithm for compressive sensing
Simon Foucart. Hard thresholding pursuit: an algorithm for compressive sensing. SIAM Journal on Numerical Analysis , 49(6):2543--2563, 2011
work page 2011
-
[22]
Probabilistic model-agnostic meta-learning
Chelsea Finn, Kelvin Xu, and Sergey Levine. Probabilistic model-agnostic meta-learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages 9537--9548, 2018
work page 2018
-
[23]
Convergence of fixed-point continuation algorithms for matrix rank minimization
Donald Goldfarb and Shiqian Ma. Convergence of fixed-point continuation algorithms for matrix rank minimization. Foundations of Computational Mathematics , 11(2):183--210, 2011
work page 2011
-
[24]
Overcoming data scarcity with transfer learning
Maxwell L Hutchinson, Erin Antono, Brenna M Gibbons, Sean Paradiso, Julia Ling, and Bryce Meredig. Overcoming data scarcity with transfer learning. arXiv preprint arXiv:1711.05099 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Universality of regularized regression estimators in high dimensions
Qiyang Han and Yandi Shen. Universality of regularized regression estimators in high dimensions. The Annals of Statistics , 51(4):1799--1823, 2023
work page 2023
-
[26]
Fixed-point continuation for _1 -minimization: Methodology and convergence
Elaine T Hale, Wotao Yin, and Yin Zhang. Fixed-point continuation for _1 -minimization: Methodology and convergence. SIAM Journal on Optimization , 19(3):1107--1130, 2008
work page 2008
-
[27]
Yanhao Jin, Krishnakumar Balasubramanian, and Debashis Paul. Meta-learning with generalized ridge regression: High-dimensional asymptotics, optimality and hyper-covariance estimation. arXiv preprint arXiv:2403.19720 , 2024
-
[28]
Guaranteed rank minimization via singular value projection
Prateek Jain, Raghu Meka, and Inderjit Dhillon. Guaranteed rank minimization via singular value projection. Advances in Neural Information Processing Systems , 23, 2010
work page 2010
-
[29]
Meta-learning for mixed linear regression
Weihao Kong, Raghav Somani, Zhao Song, Sham Kakade, and Sewoong Oh. Meta-learning for mixed linear regression. In International Conference on Machine Learning , pages 5394--5404. PMLR, 2020
work page 2020
-
[30]
Efficient and guaranteed rank minimization by atomic decomposition
Kiryung Lee and Yoram Bresler. Efficient and guaranteed rank minimization by atomic decomposition. In 2009 IEEE International Symposium on Information Theory , pages 314--318. IEEE, 2009
work page 2009
-
[31]
Admira: Atomic decomposition for minimum rank approximation
Kiryung Lee and Yoram Bresler. Admira: Atomic decomposition for minimum rank approximation. IEEE Transactions on Information Theory , 56(9):4402--4416, 2010
work page 2010
-
[32]
Transformers as algorithms: Generalization and stability in in-context learning
Yingcong Li, Muhammed Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. Transformers as algorithms: Generalization and stability in in-context learning. In International Conference on Machine Learning , pages 19565--19594. PMLR, 2023
work page 2023
-
[33]
Improved bounds for multi-task learning with trace norm regularization
Weiwei Liu. Improved bounds for multi-task learning with trace norm regularization. In The Thirty Sixth Annual Conference on Learning Theory , pages 700--714. PMLR, 2023
work page 2023
-
[34]
On the limited memory BFGS method for large scale optimization
Dong C Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization. Mathematical Programming , 45(1-3):503--528, 1989
work page 1989
-
[35]
Understanding optimal feature transfer via a fine-grained bias-variance analysis
Yufan Li, Subhabrata Sen, and Ben Adlam. Understanding optimal feature transfer via a fine-grained bias-variance analysis. arXiv preprint arXiv:2404.12481 , 2024
-
[36]
Low-rank semidefinite programming: Theory and applications
Alex Lemon, Anthony Man-Cho So, and Yinyu Ye. Low-rank semidefinite programming: Theory and applications. Foundations and Trends in Optimization , 2(1-2):1--156, 2016
work page 2016
-
[37]
Interior-point method for nuclear norm approximation with application to system identification
Zhang Liu and Lieven Vandenberghe. Interior-point method for nuclear norm approximation with application to system identification. SIAM Journal on Matrix Analysis and Applications , 31(3):1235--1256, 2010
work page 2010
-
[38]
Qi Liu, Han Zhou, Lin Liu, Xi Chen, Ruixin Zhu, and Zhiwei Cao. Multi-target QSAR modelling in the analysis and design of HIV - HCV co-inhibitors: an in-silico study. BMC Bioinformatics , 12(1):1--20, 2011
work page 2011
-
[39]
Sparse principal component analysis and iterative thresholding
Zongming Ma. Sparse principal component analysis and iterative thresholding. The Annals of Statistics , 41(2):772--801, 2013
work page 2013
-
[40]
Coherence analysis of iterative thresholding algorithms
Arian Maleki. Coherence analysis of iterative thresholding algorithms. In 2009 47th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages 236--243. IEEE, 2009
work page 2009
-
[41]
Fixed point and B regman iterative methods for matrix rank minimization
Shiqian Ma, Donald Goldfarb, and Lifeng Chen. Fixed point and B regman iterative methods for matrix rank minimization. Mathematical Programming , 128(1-2):321--353, 2011
work page 2011
-
[42]
The benefit of multitask representation learning
Andreas Maurer, Massimiliano Pontil, and Bernardino Romera-Paredes. The benefit of multitask representation learning. Journal of Machine Learning Research , 17(81):1--32, 2016
work page 2016
-
[43]
Sparse approximate solutions to linear systems
Balas K Natarajan. Sparse approximate solutions to linear systems. SIAM Journal on Computing , 24(2):227--234, 1995
work page 1995
-
[44]
Co S a MP : Iterative signal recovery from incomplete and inaccurate samples
Deanna Needell and Joel A Tropp. Co S a MP : Iterative signal recovery from incomplete and inaccurate samples. Applied and Computational Harmonic Analysis , 26(3):301--321, 2009
work page 2009
-
[45]
Invariant models for causal transfer learning
Mateo Rojas-Carulla, Bernhard Sch \"o lkopf, Richard Turner, and Jonas Peters. Invariant models for causal transfer learning. Journal of Machine Learning Research , 19(36):1--34, 2018
work page 2018
-
[46]
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization
Benjamin Recht, Maryam Fazel, and Pablo A Parrilo. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Review , 52(3):471--501, 2010
work page 2010
-
[47]
Rapid learning or feature reuse? T owards understanding the effectiveness of MAML
Aniruddh Raghu, Maithra Raghu, Samy Bengio, and Oriol Vinyals. Rapid learning or feature reuse? T owards understanding the effectiveness of MAML . In International Conference on Learning Representations , 2020
work page 2020
-
[48]
Gilbert W Stewart and Ji-Guang Sun. Matrix perturbation theory . Academic Press, 1990
work page 1990
-
[49]
A framework to characterize performance of LASSO algorithms
Mihailo Stojnic. A framework to characterize performance of lasso algorithms. arXiv preprint arXiv:1303.7291 , 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[50]
Precise error analysis of regularized M -estimators in high dimensions
Christos Thrampoulidis, Ehsan Abbasi, and Babak Hassibi. Precise error analysis of regularized M -estimators in high dimensions. IEEE Transactions on Information Theory , 64(8):5592--5628, 2018
work page 2018
-
[51]
Learning from similar linear representations: Adaptivity, minimaxity, and robustness
Ye Tian, Yuqi Gu, and Yang Feng. Learning from similar linear representations: Adaptivity, minimaxity, and robustness. arXiv preprint arXiv:2303.17765 , 2023
-
[52]
Provable meta-learning of linear representations
Nilesh Tripuraneni, Chi Jin, and Michael Jordan. Provable meta-learning of linear representations. In International Conference on Machine Learning , pages 10434--10443. PMLR, 2021
work page 2021
-
[53]
Statistically and computationally efficient linear meta-representation learning
Kiran K Thekumparampil, Prateek Jain, Praneeth Netrapalli, and Sewoong Oh. Statistically and computationally efficient linear meta-representation learning. In Proceedings of the 35th International Conference on Neural Information Processing Systems , pages 18487--18500, 2021
work page 2021
-
[54]
An introduction to matrix concentration inequalities
Joel A Tropp. An introduction to matrix concentration inequalities. Foundations and Trends in Machine Learning , 8(1-2):1--230, 2015
work page 2015
-
[55]
On the conditions used to prove oracle results for the L asso
Sara A van de Geer and Peter B \"u hlmann. On the conditions used to prove oracle results for the L asso. Electronic Journal of Statistics , 3:1360--1392, 2009
work page 2009
-
[56]
An automatic inequality prover and instance optimal identity testing
Gregory Valiant and Paul Valiant. An automatic inequality prover and instance optimal identity testing. SIAM Journal on Computing , 46(1):429--455, 2017
work page 2017
-
[57]
First-order ANIL provably learns representations despite overparametrisation
O g uz Y \"u ksel, Etienne Boursier, and Nicolas Flammarion. First-order ANIL provably learns representations despite overparametrisation. In NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning , 2023
work page 2023
-
[58]
Bregman iterative algorithms for _1 -minimization with applications to compressed sensing
Wotao Yin, Stanley Osher, Donald Goldfarb, and Jerome Darbon. Bregman iterative algorithms for _1 -minimization with applications to compressed sensing. SIAM Journal on Imaging Sciences , 1(1):143--168, 2008
work page 2008
-
[59]
A survey on multi-task learning
Yu Zhang and Qiang Yang. A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering , 34(12):5586--5609, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.