FinTagging: Benchmarking LLMs for Extracting and Structuring Financial Information
Pith reviewed 2026-05-22 02:20 UTC · model grok-4.3
The pith
Large language models extract numbers from financial reports accurately but cannot reliably map them to the full US GAAP taxonomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
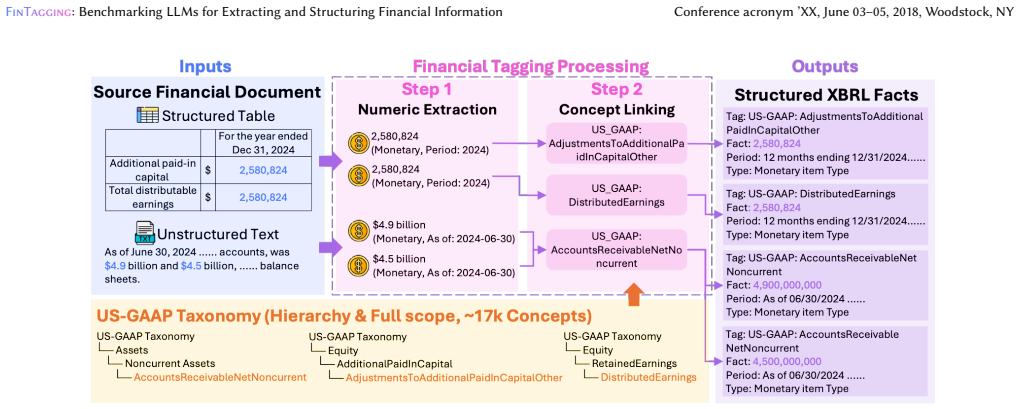
The authors claim that decomposing XBRL tagging into FinNI for identifying entities and types from heterogeneous financial documents and FinCL for mapping those entities onto the full US GAAP taxonomy produces a more realistic evaluation. Under zero-shot conditions, diverse LLMs generalize across extraction tasks yet exhibit clear failures in fine-grained concept linking, which demonstrates limitations in their ability to perform structure-aware reasoning within the financial domain.
What carries the argument
The two-stage decomposition into Financial Numeric Identification (FinNI) and Financial Concept Linking (FinCL) that separates extraction from taxonomy alignment and enables targeted measurement of each capability.
If this is right
- LLMs can serve as reliable first-pass extractors for financial numbers and types but will still need supplementary methods or human review for correct taxonomy assignment.
- Existing single-step classification benchmarks underestimate the difficulty of real XBRL work and should be replaced by structure-aware, full-scope tests.
- Domain-specific structure awareness remains a bottleneck for LLMs in regulated reporting tasks.
- Zero-shot performance gaps between extraction and linking highlight the need for better integration of hierarchical taxonomy knowledge.
Where Pith is reading between the lines
- Tools built on these models could reduce manual effort in initial data gathering while still requiring expert validation for concept accuracy.
- The benchmark setup could be extended to measure how retrieval-augmented or fine-tuned models close the linking gap.
- Similar two-stage tests might reveal parallel limitations in other regulated domains that use large taxonomies, such as legal or medical coding.
Load-bearing premise
Splitting the tagging process into separate numeric identification and concept-linking stages faithfully reflects how XBRL tagging actually occurs in practice.
What would settle it
A direct test in which the same LLMs achieve high accuracy on full-scope concept linking when run on complete, real-world financial reports that already carry verified XBRL tags.
Figures










read the original abstract
Accurate interpretation of numerical data in financial reports is critical for markets and regulators. Although XBRL (eXtensible Business Reporting Language) provides a standard for tagging financial figures, mapping thousands of facts to over 10k US GAAP concepts remains costly and error prone. Existing benchmarks oversimplify this task as flat, single step classification over small subsets of concepts, ignoring the hierarchical semantics of the taxonomy and the structured nature of financial documents. Consequently, these benchmarks fail to evaluate Large Language Models (LLMs) under realistic reporting conditions. To bridge this gap, we introduce FinTagging, the first comprehensive benchmark for structure aware and full scope XBRL tagging. We decompose the complex tagging process into two subtasks: (1) FinNI (Financial Numeric Identification), which extracts entities and types from heterogeneous contexts including text and tables; and (2) FinCL (Financial Concept Linking), which maps extracted entities to the full US GAAP taxonomy. This two stage formulation enables a fair assessment of LLMs' capabilities in numerical reasoning and taxonomy alignment. Evaluating diverse LLMs in zero shot settings reveals that while models generalize well in extraction, they struggle significantly with fine grained concept linking, highlighting critical limitations in domain specific structure aware reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinTagging, the first comprehensive benchmark for structure-aware XBRL tagging of financial reports. It decomposes the task into FinNI (extracting numeric entities and types from text/tables) and FinCL (mapping to the full US GAAP taxonomy of over 10k concepts), then evaluates diverse LLMs in zero-shot settings. The central finding is that models generalize well on extraction but struggle significantly with fine-grained concept linking, which the authors attribute to critical limitations in domain-specific structure-aware reasoning.
Significance. If the two-stage decomposition faithfully captures real XBRL workflows and the FinCL results reflect genuine reasoning deficits rather than prompt or input constraints, the benchmark would provide a valuable, more realistic testbed than prior flat-classification setups. It could guide development of LLMs better suited to hierarchical taxonomies and regulatory reporting, while highlighting gaps in current models' ability to handle large-scale structured financial data.
major comments (2)
- [FinCL task definition] FinCL task definition and prompt construction: the manuscript does not specify how the full US GAAP taxonomy (10k+ concepts) is presented to the models—whether as a flat label list, with explicit parent-child hierarchy, relation encodings, or via retrieval. If the taxonomy is supplied without structural cues or search, the reported low FinCL accuracy may arise from context-window limits or absent navigation mechanisms rather than deficits in structure-aware reasoning, directly weakening the central claim in the abstract and results interpretation.
- [Evaluation and results] Evaluation protocol and controls: the reported results lack details on dataset construction, the precise subset or full taxonomy size used in each test, error analysis by concept granularity or hierarchy depth, and statistical significance of the extraction-vs-linking performance gap. These omissions make it hard to confirm that the 'struggle significantly' conclusion is robust and not an artifact of unreported experimental choices.
minor comments (2)
- [Abstract] Abstract: consider briefly stating the number of LLMs tested and the primary metrics (e.g., F1 or accuracy ranges) to give readers an immediate sense of scale.
- [Throughout] Notation: ensure consistent use of 'FinNI' and 'FinCL' throughout, and clarify whether 'zero-shot' includes any in-context examples of taxonomy structure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to improve clarity and completeness where needed.
read point-by-point responses
-
Referee: [FinCL task definition] FinCL task definition and prompt construction: the manuscript does not specify how the full US GAAP taxonomy (10k+ concepts) is presented to the models—whether as a flat label list, with explicit parent-child hierarchy, relation encodings, or via retrieval. If the taxonomy is supplied without structural cues or search, the reported low FinCL accuracy may arise from context-window limits or absent navigation mechanisms rather than deficits in structure-aware reasoning, directly weakening the central claim in the abstract and results interpretation.
Authors: We agree that the FinCL prompt construction requires explicit description, as the current manuscript does not detail it. In our zero-shot setup, the full 10k+ taxonomy cannot be included in the context window; instead, we retrieve a shortlist of candidate concepts (top-20 by embedding similarity to the extracted entity and its context) and present the LLM with their names, definitions, and immediate parent concepts to supply limited hierarchical cues. We will add a dedicated subsection in the Methods section (and an appendix with exact prompt templates) describing this retrieval-augmented process, the embedding model used, and the absence of full taxonomy traversal. This revision will allow readers to evaluate whether the observed performance gap reflects genuine limitations in structure-aware reasoning or input constraints, while preserving our interpretation that current LLMs lack robust fine-grained taxonomy alignment even under practical retrieval support. revision: yes
-
Referee: [Evaluation and results] Evaluation protocol and controls: the reported results lack details on dataset construction, the precise subset or full taxonomy size used in each test, error analysis by concept granularity or hierarchy depth, and statistical significance of the extraction-vs-linking performance gap. These omissions make it hard to confirm that the 'struggle significantly' conclusion is robust and not an artifact of unreported experimental choices.
Authors: We acknowledge these omissions in the current draft. The dataset comprises numeric entities extracted from a curated set of 10-K filings drawn from the SEC EDGAR database, with ground-truth XBRL tags obtained from official filings; FinCL evaluation uses the full US GAAP taxonomy (~10,500 concepts) but reports performance only on the subset of concepts that appear in the test instances (approximately 800 unique concepts across the evaluation set). We will expand the Experiments section to include: exact dataset construction and split statistics, the precise taxonomy size and per-report concept coverage, a breakdown of errors by hierarchy depth (leaf vs. intermediate vs. root concepts), and statistical significance testing (e.g., McNemar’s test or bootstrap confidence intervals) for the FinNI vs. FinCL performance difference. These additions will be incorporated in the revision to substantiate the robustness of our conclusions. revision: yes
Circularity Check
No circularity in benchmark definition or evaluation results
full rationale
The paper defines a new benchmark by decomposing XBRL tagging into FinNI extraction and FinCL linking subtasks, then reports zero-shot LLM performance on these tasks. No equations, fitted parameters, or first-principles derivations are present; the central claims rest on direct empirical evaluation rather than any reduction to self-defined inputs or self-citation chains. The two-stage formulation is presented as an explicit design choice to enable realistic assessment, not as a result derived from prior self-referential assumptions. This is a standard benchmark paper whose findings are independent of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Conv-FinRe: A Conversational and Longitudinal Benchmark for Utility-Grounded Financial Recommendation
Conv-FinRe is a new benchmark built from real market data and human trajectories that tests LLMs on generating utility-grounded stock rankings over fixed horizons while distinguishing rational analysis from behavioral...
-
FinAuditing: A Financial Taxonomy-Structured Multi-Document Benchmark for Evaluating LLMs
FinAuditing is a taxonomy-structured multi-document benchmark with 1,102 instances averaging over 33k tokens from XBRL filings, defining three tasks to evaluate LLMs on financial auditing capabilities.
Reference graph
Works this paper leans on
-
[1]
Dogu Araci. 2019. Finbert: Financial sentiment analysis with pre-trained language models.arXiv preprint arXiv:1908.10063(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Jeya Balaji Balasubramanian, Daniel Adams, Ioannis Roxanis, Amy Berrington de Gonzalez, Penny Coulson, Jonas S Almeida, and Montserrat García-Closas
- [3]
-
[4]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, et al
- [5]
- [6]
-
[7]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL] https://arxiv.org/abs/2501. 12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRRabs/1810.04805 (2018). arXiv:1810.04805 http://arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. A fra...
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Shijie Han, Haoqiang Kang, Bo Jin, Xiao-Yang Liu, and Steve Yang. 2024. XBRL- Agent: Leveraging Large Language Models for Financial Report Analysis. In Proceedings of the 5th ACM International Conference on AI in Finance (ICAIF ’24)
work page 2024
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
-
[14]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
work page 1977
-
[15]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 2200–2209
work page 2021
-
[18]
AI Meta. 2025. The llama 4 herd: The beginning of a new era of natively multi- modal ai innovation.https://ai. meta. com/blog/llama-4-multimodal-intelligence/, checked on4, 7 (2025), 2025
work page 2025
-
[19]
Rajdeep Mukherjee, Abhinav Bohra, Akash Banerjee, Soumya Sharma, Manjunath Hegde, Afreen Shaikh, Shivani Shrivastava, Koustuv Dasgupta, Niloy Ganguly, Saptarshi Ghosh, et al. 2022. Ectsum: A new benchmark dataset for bullet point summarization of long earnings call transcripts.arXiv preprint arXiv:2210.12467 (2022)
- [20]
-
[21]
Jim Richards, Barry Smith, and Ali Saeedi. 2006. An introduction to XBRL. A vailable at SSRN 1007570(2006)
work page 2006
- [22]
- [23]
-
[24]
Soumya Sharma, Subhendu Khatuya, Manjunath Hegde, Afreen Shaikh, Koustuv Dasgupta, Pawan Goyal, and Niloy Ganguly. 2023. Financial numeric extreme labelling: A dataset and benchmarking. InFindings of the Association for Compu- tational Linguistics: ACL 2023. 3550–3561
work page 2023
-
[25]
Soumya Sharma, Tapas Nayak, Arusarka Bose, Ajay Kumar Meena, Koustuv Dasgupta, Niloy Ganguly, and Pawan Goyal. 2022. FinRED: A dataset for relation extraction in financial domain. InCompanion Proceedings of the Web Conference
work page 2022
-
[26]
Marina Sokolova and Guy Lapalme. 2009. A systematic analysis of performance measures for classification tasks.Information processing & management45, 4 (2009), 427–437
work page 2009
-
[27]
Gemma Team. 2024. Gemma. (2024). doi:10.34740/KAGGLE/M/3301
-
[28]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [29]
-
[30]
Richard Zhe Wang. 2023. Standardizing XBRL financial reporting tags with natural language processing.A vailable at SSRN 4613085(2023)
work page 2023
-
[31]
Yan Wang, Jian Wang, Huiyi Lu, Bing Xu, Yijia Zhang, Santosh Kumar Banbhrani, Hongfei Lin, et al. 2022. Conditional probability joint extraction of nested biomed- ical events: design of a unified extraction framework based on neural networks. JMIR Medical Informatics10, 6 (2022), e37804
work page 2022
-
[32]
Ledell Wu, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer
- [33]
- [34]
- [35]
-
[36]
Tat-qa: A question answering benchmark o n a hybrid of tabular and textual content in finance
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A question an- swering benchmark on a hybrid of tabular and textual content in finance.arXiv preprint arXiv:2105.07624(2021). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Yan et al. A Significance analysis To further exami...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.