Efficient Knowledge Graph Accuracy Evaluation
Pith reviewed 2026-05-24 17:20 UTC · model grok-4.3
The pith
Cluster sampling and stratification cut the human cost of knowledge graph accuracy evaluation by up to 60 percent on static graphs and 80 percent on evolving graphs while preserving statistical guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed framework forms clusters of triples that share annotation cost, applies cluster sampling within a stratified or weighted design, and thereby obtains unbiased accuracy estimates whose variance is controlled with fewer individual annotations. For evolving graphs the same cost structure is exploited by maintaining a stratified sample across updates or by using a weighted reservoir that admits efficient insertions and deletions while retaining the original sampling probabilities.
What carries the argument
Cluster sampling over cost-correlated groups of triples, combined with stratification and weighted two-stage sampling, to reduce the number of annotations required for a given precision of the accuracy estimate.
If this is right
- Accuracy estimates retain the same statistical validity and confidence intervals as uniform sampling.
- The same designs apply without modification to both static and incrementally updated knowledge graphs.
- Total annotation cost drops by up to 60 percent for static evaluation and up to 80 percent for evolving evaluation at unchanged quality.
- Stratification by triple type or source further reduces variance for the same sample size.
Where Pith is reading between the lines
- More frequent accuracy audits become feasible during knowledge-graph construction because each audit consumes less annotator time.
- The same cost-clustering idea could be tested on other annotation tasks whose cost structure exhibits locality, such as entity linking or relation extraction.
- If clusters can be discovered automatically from the graph structure rather than supplied by domain experts, the method becomes more widely deployable.
- An adaptive variant that re-stratifies after an initial pilot sample could be examined to further tighten cost bounds.
Load-bearing premise
Annotation cost is sufficiently correlated within identifiable clusters that sampling whole clusters reduces total annotations without introducing bias in the accuracy estimate.
What would settle it
Running both the proposed cluster-sampling estimator and a full census on the same knowledge graph and observing whether the accuracy point estimate falls outside the claimed confidence interval more often than the nominal error rate.
Figures







read the original abstract
Estimation of the accuracy of a large-scale knowledge graph (KG) often requires humans to annotate samples from the graph. How to obtain statistically meaningful estimates for accuracy evaluation while keeping human annotation costs low is a problem critical to the development cycle of a KG and its practical applications. Surprisingly, this challenging problem has largely been ignored in prior research. To address the problem, this paper proposes an efficient sampling and evaluation framework, which aims to provide quality accuracy evaluation with strong statistical guarantee while minimizing human efforts. Motivated by the properties of the annotation cost function observed in practice, we propose the use of cluster sampling to reduce the overall cost. We further apply weighted and two-stage sampling as well as stratification for better sampling designs. We also extend our framework to enable efficient incremental evaluation on evolving KG, introducing two solutions based on stratified sampling and a weighted variant of reservoir sampling. Extensive experiments on real-world datasets demonstrate the effectiveness and efficiency of our proposed solution. Compared to baseline approaches, our best solutions can provide up to 60% cost reduction on static KG evaluation and up to 80% cost reduction on evolving KG evaluation, without loss of evaluation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an efficient sampling and evaluation framework for estimating the accuracy of large-scale knowledge graphs. Motivated by observed properties of the annotation cost function, it employs cluster sampling along with weighted, two-stage, and stratified variants to minimize human annotation costs while providing strong statistical guarantees. The framework is extended to incremental evaluation on evolving KGs via stratified sampling and a weighted reservoir sampling variant. Experiments on real-world datasets report up to 60% cost reduction for static KGs and 80% for evolving KGs without loss of evaluation quality compared to baselines.
Significance. If the claimed cost reductions hold while preserving unbiased estimators and valid confidence intervals, the work would meaningfully advance practical KG development by lowering the barrier to frequent accuracy assessments. The focus on both static and evolving scenarios, combined with experiments on real-world data, strengthens its potential impact; reproducible experimental setups would further enhance its value.
major comments (2)
- [Abstract] Abstract and methods: the central claim of cost reduction without loss of evaluation quality rests on cluster sampling exploiting intra-cluster homogeneity in the annotation cost function; however, no formal characterization or sensitivity analysis of this property is provided, leaving open whether the savings generalize or are dataset-specific.
- [Experiments] The assertion of 'strong statistical guarantee' requires explicit handling of variance inflation inherent to cluster sampling (relative to simple random sampling at fixed sample size); without reported comparisons of estimator variance or confidence-interval coverage against baselines, it is unclear whether quality is truly preserved.
minor comments (2)
- Notation for sampling designs (e.g., cluster weights, stratification variables) should be introduced consistently with a dedicated notation table or section to aid reproducibility.
- Clarify how error bars or variance estimates are computed in the reported results to allow direct verification of the 'no loss of quality' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and commit to revisions that strengthen the statistical foundations and empirical support of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods: the central claim of cost reduction without loss of evaluation quality rests on cluster sampling exploiting intra-cluster homogeneity in the annotation cost function; however, no formal characterization or sensitivity analysis of this property is provided, leaving open whether the savings generalize or are dataset-specific.
Authors: The motivation for cluster sampling is indeed empirical, based on the observed intra-cluster homogeneity of annotation costs (detailed in Section 3 of the manuscript). While we do not provide a formal theoretical characterization (as the degree of homogeneity depends on KG structure and may not admit a simple closed form), the experiments demonstrate consistent savings across multiple real-world KGs. In revision we will add a sensitivity analysis that varies cluster definition, intra-cluster cost correlation, and homogeneity levels to better assess generalizability. revision: partial
-
Referee: [Experiments] The assertion of 'strong statistical guarantee' requires explicit handling of variance inflation inherent to cluster sampling (relative to simple random sampling at fixed sample size); without reported comparisons of estimator variance or confidence-interval coverage against baselines, it is unclear whether quality is truly preserved.
Authors: Cluster sampling does introduce a design effect that can inflate variance relative to simple random sampling at the same sample size. Our estimators remain unbiased under the sampling design, and the reported confidence intervals use the corresponding variance estimators for the chosen design. However, the manuscript does not include explicit side-by-side comparisons of estimator variance or empirical coverage rates versus baselines. We will add these comparisons (including variance ratios and Monte-Carlo coverage simulations) to the experimental section in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical validation independent of inputs
full rationale
The paper proposes a sampling framework (cluster, weighted, two-stage, stratified) motivated by observed annotation cost properties and extends it to evolving KGs via stratified and reservoir sampling variants. Cost reductions (60%/80%) and quality preservation are reported from experiments on real-world datasets, not from any closed-form derivation or parameter fit that reduces to the input data by construction. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described chain. Standard sampling theory supplies the unbiasedness/variance guarantees; the cost savings are an empirical outcome under the stated preconditions rather than a tautology. This is the normal non-circular case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotation cost function has properties observed in practice that justify cluster sampling for cost reduction
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cost(G′) = |E′| · c1 + |G′| · c2 where E′ is the set of distinct ids
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Efficient Knowledge Graph Accuracy Evaluation
INTRODUCTION Over the past few years, we have seen an increasing number of large-scale KGs with millions of relational facts in the format of RDF triples (subject,predicate,object). Examples include DBPe- dia [1], Y AGO [15, 5], NELL [25], Knowledge-Vault [13], etc. However, the KG construction processes are far from perfect, so these KGs may contain many...
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[2]
Formally, G = {t | t : (s, p,o)}
PRELIMINARIES 2.1 Knowledge Graphs We model knowledge graph G as a set of triples in the form of (subject, predicate, object), denoted by (s, p,o). Formally, G = {t | t : (s, p,o)}. For example, in tuple (/m/02mjmr, /people/person- /place of birth, /m/02hrh0 ), /m/02mjmr is the Freebase id for Barack Obama, and /m/02hrh0 is the id for Honolulu. Each entit...
-
[3]
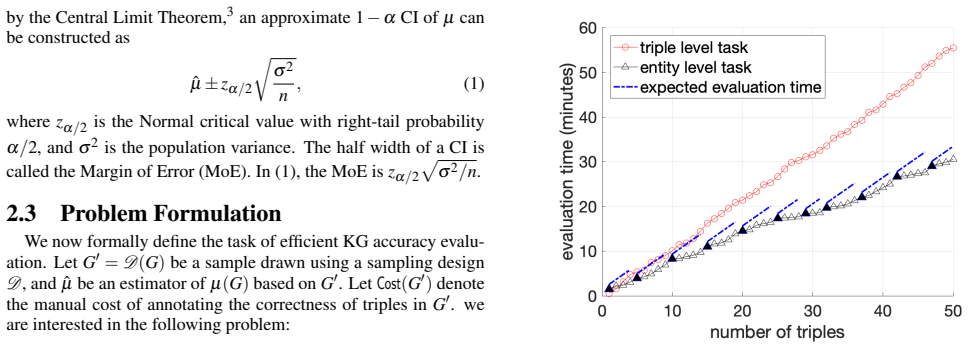
EV ALUATION COST MODEL Prior research typically ignores the evaluation time needed by manual annotations. In this section, we study human annotators’ performance on different evaluation tasks and propose a cost func- tion that approximates the manual annotation time. Analytically and empirically, we argue that annotating triples in groups of enti- ties is...
-
[4]
There are two evaluation procedures
EV ALUATION FRAMEWORK In a nutshell, our evaluation framework is shown in Fig 2. There are two evaluation procedures. Static Evaluation conducts efficient and high-quality accuracy evaluation on static KGs. It works as the following iterative proce- dure, sharing the same spirit as in Online Aggregation [20]: • Step 1: Sample Collector selects a small batc...
-
[5]
There are two sampling strategies to evaluate the quality of KGs: Table 2: Notations
SAMPLING DESIGN The sampling design is the core component of the framework. There are two sampling strategies to evaluate the quality of KGs: Table 2: Notations. N Number of entity clusters in G Mi Size of the ith entity cluster M = ∑N i=1 Mi Total number of triples in G n Number of entity clusters in the sample m Maximum number of triples to draw within ...
-
[6]
In the first stage, we sample entity clusters using WCS
-
[7]
In the second stage, only a small number of triples are se- lected randomly from clusters sampled in the first stage. More specifically, min {MIk ,m} triples are randomly drawn from the k-th sample cluster without replacement. Drawing without replacement in the second stage greatly reduces sampling variances when cluster sizes are comparable or smaller than...
-
[8]
EV ALUATION ON EVOLVING KG We discuss two methods to reduce the annotation cost in esti- mating µ(G + ∆) as a KG evolves from G to G + ∆, one based on reservoir sampling and the other based on stratified sampling. 6.1 Reservoir Incremental Evaluation Reservoir Incremental Evaluation (RS) is based on the reservoir sampling [28] scheme, which stochastically ...
-
[9]
Section 7.1 elaborates the experiment setup
EXPERIMENTS In this section, we comprehensively and quantitatively evaluate the performance of all proposed methods. Section 7.1 elaborates the experiment setup. Section 7.2 focuses on the accuracy evalua- tion on static KGs. We compare the evaluation efficiency and esti- mation quality of various methods on different static KGs with dif- ferent data chara...
-
[10]
RELATED WORK As discussed earlier, SRS is a simple but prevalent method for KG accuracy evaluation. Beyond SRS, Ojha et al. [26] were the first to systematically tackle the problem of efficient accuracy eval- uation of large-scale KGs. One key observation is that, by explor- ing dependencies (i.e., type consistency, Horn-clause coupling con- straints [7, 25...
-
[11]
We presented a general evaluation framework that works on both static and evolving KGs
CONCLUSION In this paper, we have initiated a comprehensive study into the important problem of efficient and reliable knowledge graph ac- curacy evaluation. We presented a general evaluation framework that works on both static and evolving KGs. We devised a suite of sampling techniques for efficient accuracy evaluation on these two scenarios. As demonstrat...
- [12]
- [13]
- [14]
- [15]
-
[16]
https://www.mpi-inf.mpg.de/departments/ databases-and-information-systems/research/ yago-naga
Yago2. https://www.mpi-inf.mpg.de/departments/ databases-and-information-systems/research/ yago-naga
- [17]
- [18]
-
[19]
Probabilistic Similarity Logic
M. Brocheler, L. Mihalkova, and L. Getoor. Probabilistic similarity logic. arXiv preprint arXiv:1203.3469, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[20]
G. Casella and R. L. Berger. Statistical inference, volume 2. Duxbury Pacific Grove, CA, 2002
work page 2002
-
[21]
P. Christen and K. Goiser. Quality and complexity measures for data linkage and deduplication. In Quality measures in data mining, pages 127–151. Springer, 2007
work page 2007
-
[22]
X. Chu, I. F. Ilyas, S. Krishnan, and J. Wang. Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 International Conference on Management of Data, pages 2201–2206. ACM, 2016
work page 2016
-
[23]
T. Dalenius and J. L. Hodges Jr. Minimum variance stratification. Journal of the American Statistical Association, 54(285):88–101, 1959
work page 1959
-
[24]
X. Dong, E. Gabrilovich, G. Heitz, W. Horn, N. Lao, K. Murphy, T. Strohmann, S. Sun, and W. Zhang. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 601–610. ACM, 2014
work page 2014
-
[25]
P. S. Efraimidis and P. G. Spirakis. Weighted random sampling with a reservoir. Information Processing Letters, 97(5):181–185, 2006
work page 2006
- [26]
-
[27]
J. Gao, X. Li, Y . E. Xu, B. Sisman, X. L. Dong, and J. Yang. Efficient knowledge graph accuracy evaluation. Technical report, Duke University, 2019. https://users.cs.duke. edu/~jygao/KG_eval_vldb_full.pdf
work page 2019
- [28]
-
[29]
M. H. Hansen and W. N. Hurwitz. On the theory of sampling from finite populations. The Annals of Mathematical Statistics, 14(4):333–362, 1943
work page 1943
-
[30]
T. Heath and C. Bizer. Linked data: Evolving the web into a global data space. Synthesis lectures on the semantic web: theory and technology, 1(1):1–136, 2011
work page 2011
-
[31]
J. M. Hellerstein, P. J. Haas, and H. J. Wang. Online aggregation. In Acm Sigmod Record, volume 26, pages 171–182. ACM, 1997
work page 1997
-
[32]
N. Lao, T. Mitchell, and W. W. Cohen. Random walk inference and learning in a large scale knowledge base. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 529–539. Association for Computational Linguistics, 2011
work page 2011
-
[33]
H. Li, Y . Li, F. Xu, and X. Zhong. Probabilistic error detecting in numerical linked data. In International Conference on Database and Expert Systems Applications, pages 61–75. Springer, 2015
work page 2015
-
[34]
S. Liu, M. dAquin, and E. Motta. Measuring accuracy of triples in knowledge graphs. In International Conference on Language, Data and Knowledge, pages 343–357. Springer, 2017
work page 2017
-
[35]
N. G. Marchant and B. I. Rubinstein. In search of an entity resolution oasis: optimal asymptotic sequential importance sampling. PVLDB, 10(11):1322–1333, 2017
work page 2017
-
[36]
T. Mitchell, W. Cohen, E. Hruschka, P. Talukdar, B. Yang, J. Betteridge, A. Carlson, B. Dalvi, M. Gardner, B. Kisiel, et al. Never-ending learning. Communications of the ACM, 61(5):103–115, 2018
work page 2018
-
[37]
P. Ojha and P. Talukdar. Kgeval: Accuracy estimation of automatically constructed knowledge graphs. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1741–1750, 2017
work page 2017
- [38]
-
[39]
J. S. Vitter. Random sampling with a reservoir. ACM Transactions on Mathematical Software (TOMS), 11(1):37–57, 1985
work page 1985
-
[40]
J. Wang, S. Krishnan, M. J. Franklin, K. Goldberg, T. Kraska, and T. Milo. A sample-and-clean framework for fast and accurate query processing on dirty data. In Proceedings of the 2014 ACM SIGMOD international conference on Management of data, pages 469–480. ACM, 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.