Fast State Stabilization using Deep Reinforcement Learning for Measurement-based Quantum Feedback Control
Pith reviewed 2026-05-23 21:48 UTC · model grok-4.3
The pith
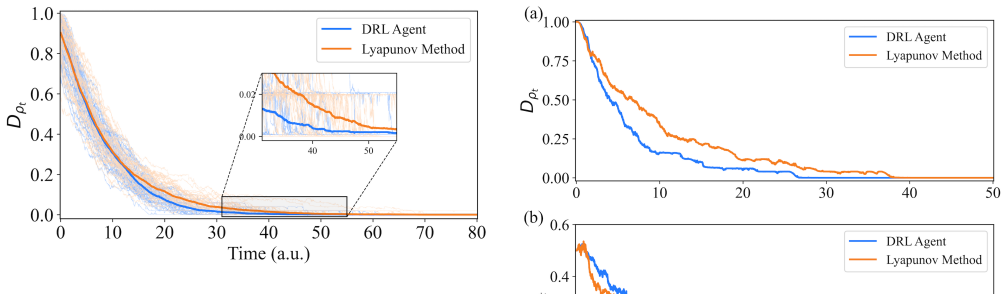
Deep reinforcement learning stabilizes random quantum states to target entangled states faster than Lyapunov control using measurement feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Applying a deep reinforcement learning algorithm to measurement information drives random initial quantum states to a target entangled state in two- and three-qubit systems with shorter convergence times than Lyapunov feedback control or several alternative DRL formulations, while retaining performance under imperfect measurements and delays in system evolution.
What carries the argument
Deep reinforcement learning policy trained on measurement outcomes to generate control signals for quantum feedback without explicit mapping construction.
Load-bearing premise
The simulated quantum dynamics, measurement model, and environmental interactions match physical hardware closely enough that a policy trained in simulation will work similarly on real devices.
What would settle it
An experiment on a physical two-qubit device that measures whether the learned DRL policy reaches the target state faster than Lyapunov control under actual noise, measurement error, and delay.
Figures









read the original abstract
The stabilization of quantum states is a fundamental problem for realizing various quantum technologies. Measurement-based-feedback strategies have demonstrated powerful performance, and the construction of quantum control signals using measurement information has attracted great interest. However, the interaction between quantum systems and the environment is inevitable, especially when measurements are introduced, which leads to decoherence. To mitigate decoherence, it is desirable to stabilize quantum systems faster, thereby reducing the time of interaction with the environment. In this paper, we utilize information obtained from measurement and apply deep reinforcement learning (DRL) algorithms, without explicitly constructing specific complex measurement-control mappings, to rapidly drive random initial quantum state to the target state. The proposed DRL algorithm has the ability to speed up the convergence to a target state, which shortens the interaction between quantum systems and their environments to protect coherence. Simulations are performed on two-qubit and three-qubit systems, and the results show that our algorithm can successfully stabilize random initial quantum system to the target entangled state, with a convergence time faster than traditional methods such as Lyapunov feedback control and several DRL algorithms with different reward functions. Moreover, it exhibits robustness against imperfect measurements and delays in system evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes applying deep reinforcement learning (DRL) to measurement-based quantum feedback control to stabilize random initial states to target entangled states in two- and three-qubit systems. Simulations are used to claim faster convergence times than Lyapunov feedback control and alternative DRL reward designs, along with robustness to modeled measurement imperfections and evolution delays.
Significance. If the simulation results hold under the reported conditions, the work supplies an empirical demonstration that DRL can outperform both classical Lyapunov control and other DRL variants on small-scale quantum stabilization tasks, potentially shortening interaction times with the environment. The explicit comparisons across reward functions and the inclusion of robustness tests constitute a strength of the empirical evaluation.
major comments (3)
- [§4 and §5] §4 (Simulation Setup) and §5 (Results): The central claim of faster convergence rests on simulation outcomes, yet the manuscript supplies no quantitative specification of the DRL network architecture (layers, units), training procedure (optimizer, episode count, batch size), or statistical measures (mean and standard deviation of convergence time over repeated trials) needed to substantiate the reported performance ordering versus Lyapunov control and other DRL variants.
- [§3.2] §3.2 (Reward Function Design): The paper states that several DRL algorithms with different reward functions were compared, but the explicit mathematical forms of those reward functions and the rationale for their selection are not provided; without these definitions it is impossible to assess whether the reported speed-up is attributable to the proposed reward or to other implementation choices.
- [§5.3] §5.3 (Robustness Tests): Robustness against imperfect measurements and delays is asserted, but the specific ranges of measurement error probabilities and delay durations, together with the quantitative metrics used to quantify degradation, are not reported, leaving the scope of the robustness claim unclear.
minor comments (2)
- [Figures in §5] Figure captions and axis labels in the simulation results should explicitly state the number of Monte Carlo runs and the precise definition of convergence time.
- [§2] The system model section would benefit from a compact table listing the qubit Hamiltonians, measurement operators, and target states used for the two- and three-qubit cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which will help improve the reproducibility and clarity of the manuscript. We address each major comment below and will incorporate the requested details in the revised version.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Simulation Setup) and §5 (Results): The central claim of faster convergence rests on simulation outcomes, yet the manuscript supplies no quantitative specification of the DRL network architecture (layers, units), training procedure (optimizer, episode count, batch size), or statistical measures (mean and standard deviation of convergence time over repeated trials) needed to substantiate the reported performance ordering versus Lyapunov control and other DRL variants.
Authors: We agree that these implementation and statistical details are required for full reproducibility and to substantiate the performance claims. In the revised manuscript we will add a complete description of the DRL network architecture (number of layers and units), the training procedure (optimizer, episode count, batch size), and statistical measures (mean and standard deviation of convergence times over repeated independent trials) in §§4 and 5. revision: yes
-
Referee: [§3.2] §3.2 (Reward Function Design): The paper states that several DRL algorithms with different reward functions were compared, but the explicit mathematical forms of those reward functions and the rationale for their selection are not provided; without these definitions it is impossible to assess whether the reported speed-up is attributable to the proposed reward or to other implementation choices.
Authors: We acknowledge that the explicit mathematical expressions and design rationale are missing. In the revision we will insert the precise formulas for each reward function examined in §3.2 together with a paragraph explaining the motivation behind each choice, enabling readers to evaluate the contribution of the proposed reward. revision: yes
-
Referee: [§5.3] §5.3 (Robustness Tests): Robustness against imperfect measurements and delays is asserted, but the specific ranges of measurement error probabilities and delay durations, together with the quantitative metrics used to quantify degradation, are not reported, leaving the scope of the robustness claim unclear.
Authors: We agree that the tested ranges and evaluation metrics must be stated explicitly. The revised §5.3 will report the specific intervals of measurement-error probabilities and delay durations examined, as well as the quantitative metrics (e.g., mean convergence time and success rate) used to measure performance degradation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports empirical simulation outcomes on 2- and 3-qubit systems in which a trained DRL policy reaches target entangled states faster than Lyapunov feedback and alternative DRL reward designs, plus robustness to modeled imperfections. These results are generated by executing the learned policy inside the same simulator used for training; the reported convergence times and robustness metrics are not algebraically forced by the reward function or by any self-citation chain, nor do they rename a known pattern as a derivation. The abstract and reader summary contain no load-bearing self-citation, uniqueness theorem, or fitted-parameter prediction that reduces to the input by construction; the performance ordering is therefore an independent empirical observation within the simulation protocol.
Axiom & Free-Parameter Ledger
free parameters (2)
- DRL network architecture and learning hyperparameters
- Reward function design parameters
axioms (2)
- domain assumption The quantum system obeys the standard Lindblad master equation or equivalent Markovian evolution under the chosen Hamiltonian and measurement operators.
- domain assumption The control problem can be cast as a Markov decision process with the chosen observation and action spaces.
Forward citations
Cited by 1 Pith paper
-
Learning-Based Design of LQG Controllers in Quantum Coherent Feedback
A customized differential evolution algorithm designs LQG controllers for a quantum optical system, achieving lower performance indices while satisfying physical realizability constraints.
Reference graph
Works this paper leans on
-
[1]
D. Dong and I. R. Petersen, Learning and Robust Control in Quantum Technology. Springer Nature, 2023
work page 2023
-
[2]
Quantum teleportation using three- particle entanglement,
A. Karlsson and M. Bourennane, “Quantum teleportation using three- particle entanglement,” Physical Review A , vol. 58, no. 6, p. 4394, 1998
work page 1998
-
[3]
Quantum algorithms: entanglement–enhanced information processing,
A. Ekert and R. Jozsa, “Quantum algorithms: entanglement–enhanced information processing,” Philosophical Transactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences, vol. 356, no. 1743, pp. 1769–1782, 1998
work page 1998
-
[4]
On the role of entanglement in quantum- computational speed-up,
R. Jozsa and N. Linden, “On the role of entanglement in quantum- computational speed-up,” Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences , vol. 459, no. 2036, pp. 2011–2032, 2003
work page 2036
-
[5]
Quantum experiments and graphs. III. high-dimensional and multiparticle entanglement,
X. Gu, L. Chen, A. Zeilinger, and M. Krenn, “Quantum experiments and graphs. III. high-dimensional and multiparticle entanglement,” Physical Review A , vol. 99, no. 3, p. 032338, 2019
work page 2019
-
[6]
Rapid Lyapunov control of finite-dimensional quantum systems,
S. Kuang, D. Dong, and I. R. Petersen, “Rapid Lyapunov control of finite-dimensional quantum systems,” Automatica, vol. 81, pp. 164– 175, 2017
work page 2017
-
[7]
Two- step feedback preparation of entanglement for qubit systems with time delay,
Y . Liu, D. Dong, S. Kuang, I. R. Petersen, and H. Yonezawa, “Two- step feedback preparation of entanglement for qubit systems with time delay,” Automatica, vol. 125, p. 109174, 2021
work page 2021
-
[8]
Lyapunov-based feedback preparation of GHZ entanglement of N-qubit systems,
Y . Liu, S. Kuang, and S. Cong, “Lyapunov-based feedback preparation of GHZ entanglement of N-qubit systems,” IEEE Transactions on Cybernetics, vol. 47, no. 11, pp. 3827–3839, 2016
work page 2016
-
[9]
Teaching lasers to control molecules,
R. S. Judson and H. Rabitz, “Teaching lasers to control molecules,” Physical Review Letters , vol. 68, no. 10, p. 1500, 1992
work page 1992
-
[10]
Quantum estimation, control and learn- ing: opportunities and challenges,
D. Dong and I. R. Petersen, “Quantum estimation, control and learn- ing: opportunities and challenges,” Annual Reviews in Control, vol. 54, pp. 243–251, 2022
work page 2022
-
[11]
Learning control of quantum systems,
D. Dong, “Learning control of quantum systems,” in Encyclopedia of Systems and Control , J. Baillieul and T. Samad, Eds. Springer London, 2020, https://doi.org/10.1007/978-1-4471-5102-9 100161-1
-
[12]
Genetic algorithm optimization of laser pulses for molecular quantum state excitation,
S. Sharma, H. Singh, and G. G. Balint-Kurti, “Genetic algorithm optimization of laser pulses for molecular quantum state excitation,” The Journal of Chemical Physics , vol. 132, no. 6, p. 064108, 2010
work page 2010
-
[13]
O. M. Shir, Niching in derandomized evolution strategies and its applications in quantum control . Leiden University, 2008
work page 2008
-
[14]
Sampling-based learning control for quantum systems with uncertainties,
D. Dong, M. A. Mabrok, I. R. Petersen, B. Qi, C. Chen, and H. Rabitz, “Sampling-based learning control for quantum systems with uncertainties,” IEEE Transactions on Control Systems Technology , vol. 23, no. 6, pp. 2155–2166, 2015
work page 2015
-
[15]
Quantum theory of continuous feedback,
H. M. Wiseman, “Quantum theory of continuous feedback,” Physical Review A, vol. 49, no. 3, p. 2133, 1994
work page 1994
-
[16]
Reinforcement learning in different phases of quantum control,
M. Bukov, A. G. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, “Reinforcement learning in different phases of quantum control,” Physical Review X , vol. 8, no. 3, p. 031086, 2018
work page 2018
-
[17]
Model-free quantum control with reinforcement learning,
V . Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsioutsios, and M. De- voret, “Model-free quantum control with reinforcement learning,” Physical Review X , vol. 12, no. 1, p. 011059, 2022
work page 2022
-
[18]
Reinforcement-learning-assisted quantum optimization,
M. M. Wauters, E. Panizon, G. B. Mbeng, and G. E. Santoro, “Reinforcement-learning-assisted quantum optimization,”Physical Re- view Research, vol. 2, no. 3, p. 033446, 2020
work page 2020
-
[19]
Reinforcement learning for many-body ground-state preparation inspired by counterdiabatic driving,
J. Yao, L. Lin, and M. Bukov, “Reinforcement learning for many-body ground-state preparation inspired by counterdiabatic driving,” Physical Review X, vol. 11, no. 3, p. 031070, 2021
work page 2021
-
[20]
S. Borah, B. Sarma, M. Kewming, G. J. Milburn, and J. Twamley, “Measurement-based feedback quantum control with deep reinforce- ment learning for a double-well nonlinear potential,” Physical Review Letters, vol. 127, no. 19, p. 190403, 2021
work page 2021
-
[21]
Deep reinforcement learning for quantum state preparation with weak nonlinear measure- ments,
R. Porotti, A. Essig, B. Huard, and F. Marquardt, “Deep reinforcement learning for quantum state preparation with weak nonlinear measure- ments,” Quantum, vol. 6, p. 747, 2022
work page 2022
-
[22]
A. Perret and Y . B ´erub´e-Lauzi`ere, “Preparation of cavity-Fock-state superpositions by reinforcement learning exploiting measurement backaction,” Physical Review A , vol. 109, no. 2, p. 022609, 2024
work page 2024
-
[23]
Quantum feedback control and classical control theory,
A. C. Doherty, S. Habib, K. Jacobs, H. Mabuchi, and S. M. Tan, “Quantum feedback control and classical control theory,” Physical Review A, vol. 62, no. 1, p. 012105, 2000
work page 2000
-
[24]
A straightforward introduction to contin- uous quantum measurement,
K. Jacobs and D. A. Steck, “A straightforward introduction to contin- uous quantum measurement,” Contemporary Physics , vol. 47, no. 5, pp. 279–303, 2006
work page 2006
-
[25]
H. M. Wiseman and G. J. Milburn, Quantum Measurement and Control. Cambridge University Press, 2009
work page 2009
-
[26]
Reinforcement learning and Markov decision processes,
M. Van Otterlo and M. Wiering, “Reinforcement learning and Markov decision processes,” Reinforcement Learning: State-of-the-Art , pp. 3– 42, 2012
work page 2012
-
[27]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602 , 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Policy gradi- ent methods for reinforcement learning with function approximation,
R. S. Sutton, D. McAllester, S. Singh, and Y . Mansour, “Policy gradi- ent methods for reinforcement learning with function approximation,” Advances in Neural Information Processing Systems , vol. 12, 1999
work page 1999
-
[29]
V . Konda and J. Tsitsiklis, “Actor-critic algorithms,” Advances in Neural Information Processing Systems , vol. 12, 1999
work page 1999
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Quantum state tomography via linear regression estimation,
B. Qi, Z. Hou, L. Li, D. Dong, G. Xiang, and G. Guo, “Quantum state tomography via linear regression estimation,” Scientific Reports, vol. 3, no. 1, p. 3496, 2013
work page 2013
-
[32]
J. A. Smolin, J. M. Gambetta, and G. Smith, “Efficient method for computing the maximum-likelihood quantum state from measurements with additive gaussian noise,” Physical Review Letters, vol. 108, no. 7, p. 070502, 2012
work page 2012
-
[33]
D. Hadfield-Menell, S. Milli, P. Abbeel, S. J. Russell, and A. Dragan, “Inverse reward design,” Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[34]
Stable-baselines3: Reliable reinforcement learning im- plementations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning im- plementations,” Journal of Machine Learning Research , vol. 22, no. 268, pp. 1–8, 2021
work page 2021
-
[35]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KG et al., “Gymnasium: A standard interface for reinforcement learning environments,” arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Stabilizing feedback controls for quantum systems,
M. Mirrahimi and R. van Handel, “Stabilizing feedback controls for quantum systems,” SIAM Journal on Control and Optimization , vol. 46, no. 2, pp. 445–467, 2007
work page 2007
-
[37]
D. M. Greenberger, M. A. Horne, and A. Zeilinger, “Going beyond bell’s theorem,” inBell’s theorem, quantum theory and conceptions of the universe. Springer, 1989, pp. 69–72
work page 1989
-
[38]
Three qubits can be entangled in two inequivalent ways,
W. D ¨ur, G. Vidal, and J. I. Cirac, “Three qubits can be entangled in two inequivalent ways,” Physical Review A, vol. 62, no. 6, p. 062314, 2000
work page 2000
-
[39]
14-qubit entanglement: Creation and coherence,
T. Monz, P. Schindler, J. T. Barreiro, M. Chwalla, D. Nigg, W. A. Coish, M. Harlander, W. H¨ansel, M. Hennrich, and R. Blatt, “14-qubit entanglement: Creation and coherence,” Physical Review Letters , vol. 106, no. 13, p. 130506, 2011
work page 2011
-
[40]
S. Kuang, G. Li, Y . Liu, X. Sun, and S. Cong, “Rapid feedback stabilization of quantum systems with application to preparation of multiqubit entangled states,” IEEE Transactions on Cybernetics , vol. 52, no. 10, pp. 11 213–11 225, 2021
work page 2021
-
[41]
Quantum feedback: theory, experiments, and applications,
J. Zhang, Y .-x. Liu, R.-B. Wu, K. Jacobs, and F. Nori, “Quantum feedback: theory, experiments, and applications,” Physics Reports, vol. 679, pp. 1–60, 2017
work page 2017
-
[42]
T. Xie, Y . Ma, and Y .-X. Wang, “Towards optimal off-policy evaluation for reinforcement learning with marginalized importance sampling,” Advances in Neural Information Processing Systems , vol. 32, 2019
work page 2019
-
[43]
R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[44]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estima- tion,” arXiv preprint arXiv:1506.02438 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Deepmimic: Example-guided deep reinforcement learning of physics-based charac- ter skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based charac- ter skills,” ACM Transactions on Graphics (TOG) , vol. 37, no. 4, pp. 1–14, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.