A Distributed Primal-Dual Method for Constrained Multi-agent Reinforcement Learning with General Parameterization
Pith reviewed 2026-05-23 19:04 UTC · model grok-4.3
The pith
Agents solve constrained multi-agent reinforcement learning problems using only local estimates of Lagrangian multipliers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose a distributed primal-dual actor-critic algorithm for constrained multi-agent RL with general parameterization. Each agent updates its local primal and dual variables from local information only. The algorithm establishes consensus among the agents' Lagrangian multiplier estimates and proves convergence to an equilibrium point whose sub-optimality relative to the exact solution of the unparameterized problem is characterized.
What carries the argument
Distributed primal-dual actor-critic updates that maintain and reach consensus on local Lagrangian multiplier estimates from neighbor information.
If this is right
- Agents can perform online constrained learning with only local communication and no central coordinator.
- The method applies to general function approximation rather than requiring linear or tabular representations.
- Convergence holds to an equilibrium whose performance is characterized relative to the unparameterized optimum.
- The algorithm can be evaluated on stochastic constrained Cournot games with dynamics.
Where Pith is reading between the lines
- The same local dual estimation pattern might extend to other networked constrained optimization problems outside reinforcement learning.
- Tighter sub-optimality bounds could be obtained by choosing richer parameterizations.
- Performance under time-varying networks or non-stationary dynamics is left open by the current analysis.
Load-bearing premise
Local multiplier estimates reach consensus under the chosen step-size schedules and network connectivity conditions.
What would settle it
A run of the algorithm on the constrained Cournot game in which the agents' multiplier estimates fail to converge to a common value or the achieved cost violates the shared constraint beyond the stated sub-optimality bound.
Figures

read the original abstract
This paper proposes a novel distributed approach for solving a cooperative Constrained Multi-agent Reinforcement Learning (CMARL) problem, where agents seek to minimize a global objective function subject to shared constraints. Unlike existing methods that rely on centralized training or coordination, our approach enables fully decentralized online learning, with each agent maintaining local estimates of both primal and dual variables. Specifically, we develop a distributed primal-dual algorithm based on actor-critic methods, leveraging local information to estimate Lagrangian multipliers. We establish consensus among the Lagrangian multipliers across agents and prove the convergence of our algorithm to an equilibrium point, analyzing the sub-optimality of this equilibrium compared to the exact solution of the unparameterized problem. Furthermore, we introduce a constrained cooperative Cournot game with stochastic dynamics as a test environment to evaluate the algorithm's performance in complex, real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a distributed primal-dual actor-critic algorithm for cooperative constrained multi-agent reinforcement learning under general parameterization. Each agent maintains local estimates of primal (policy) and dual (Lagrangian multiplier) variables using only local information and neighbor communication. The central claims are that the local multiplier estimates reach consensus, the algorithm converges to an equilibrium point, and the equilibrium's sub-optimality relative to the unparameterized constrained optimum is bounded; a constrained cooperative Cournot game is introduced as a numerical testbed.
Significance. If the convergence and sub-optimality results hold under the stated conditions, the work provides a fully decentralized method for constrained MARL that avoids centralized training or coordination, which is relevant for large-scale networked systems. The explicit treatment of general parameterization and the introduction of a stochastic Cournot test environment are positive contributions; the analysis appears to rely on standard technical conditions (connected graph, step-size schedules, bounded gradients) rather than novel axioms.
major comments (2)
- [§4.3, Theorem 4.2] §4.3, Theorem 4.2: the sub-optimality bound is stated to hold with respect to the unparameterized optimum, yet the proof sketch separates the parameterization bias from the distributed estimation error only at a high level; the dependence of the constant on the actor-critic approximation error (via the general parameterization) is not made explicit enough to verify the claimed rate.
- [Assumption 3.2 and §5.1] Assumption 3.2 and §5.1: the bounded-gradient and Lipschitz conditions required for consensus of the dual variables are listed, but it is unclear whether they remain uniform when the policy parameterization is nonlinear and the constraint functions depend on the joint state-action distribution; a counter-example or explicit verification for the Cournot game would strengthen the claim.
minor comments (3)
- [§3] Notation for the local multiplier estimates λ_i and the consensus variable is introduced in §3 but used interchangeably in the convergence statements of §4; a single consistent symbol or explicit equivalence would improve readability.
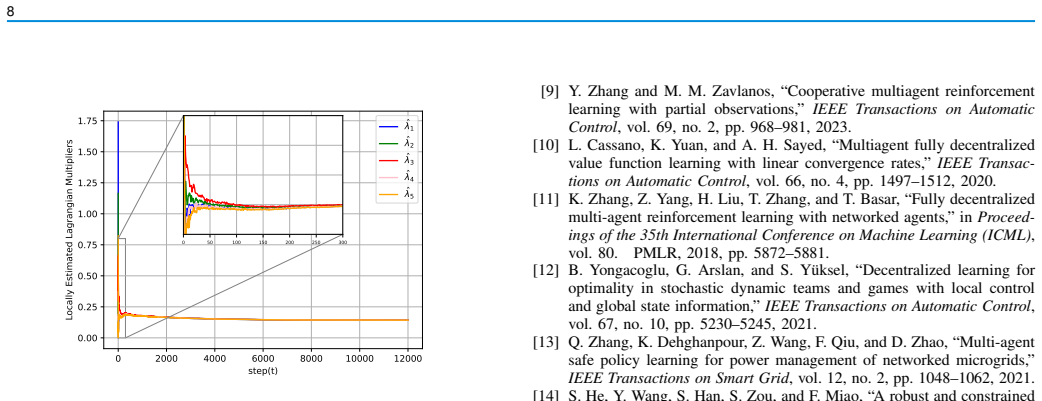
- [Figure 2] Figure 2 (Cournot game trajectories) lacks error bars or multiple random seeds; reporting mean and standard deviation over 10 independent runs would make the empirical comparison clearer.
- [Assumption 3.3] The step-size schedule η_t = 1/t^α is stated without specifying the admissible range of α that simultaneously guarantees consensus and convergence; adding this interval explicitly after Assumption 3.3 would help readers replicate the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the minor revision recommendation. We address each major comment below.
read point-by-point responses
-
Referee: [§4.3, Theorem 4.2] §4.3, Theorem 4.2: the sub-optimality bound is stated to hold with respect to the unparameterized optimum, yet the proof sketch separates the parameterization bias from the distributed estimation error only at a high level; the dependence of the constant on the actor-critic approximation error (via the general parameterization) is not made explicit enough to verify the claimed rate.
Authors: We agree the dependence on the approximation error should be stated more explicitly for verification. The proof sketch in Theorem 4.2 already separates the parameterization bias from the distributed error at a high level, but we will revise the discussion immediately following the theorem to explicitly derive and display how the sub-optimality constant depends on the actor-critic error bound. revision: yes
-
Referee: [Assumption 3.2 and §5.1] Assumption 3.2 and §5.1: the bounded-gradient and Lipschitz conditions required for consensus of the dual variables are listed, but it is unclear whether they remain uniform when the policy parameterization is nonlinear and the constraint functions depend on the joint state-action distribution; a counter-example or explicit verification for the Cournot game would strengthen the claim.
Authors: Assumption 3.2 is stated to hold uniformly over the considered parameterization class. For the Cournot testbed the constraint functions are linear in actions and the compact action spaces together with the continuous parameterization ensure the gradient and Lipschitz bounds remain uniform. To strengthen the claim we will insert a short verification paragraph in §5.1 confirming that the conditions of Assumption 3.2 hold for this environment. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper proposes a distributed primal-dual actor-critic algorithm for constrained MARL, establishes consensus on multipliers, proves convergence to an equilibrium, and bounds sub-optimality relative to the unparameterized optimum. These are standard convergence results resting on technical conditions (connected graph, step-size schedules, bounded gradients, parameterization properties) that are external to the target claims and not defined in terms of the equilibrium or bounds themselves. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The central results are independent of the algorithm's own outputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a distributed primal-dual algorithm based on actor-critic methods, leveraging local information to estimate Lagrangian multipliers. We establish consensus among the Lagrangian multipliers across agents and prove the convergence of our algorithm to an equilibrium point
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 6: ... doubly stochastic ... spectral norm ... ρ ∈ [0,1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanctot et al., “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016
work page 2016
-
[2]
Reinforcement learning in robotics: A survey,
J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,” The International Journal of Robotics Research , vol. 32, no. 11, pp. 1238–1274, 2013
work page 2013
-
[3]
Multi-agent deep reinforcement learning for large-scale traffic signal control,
T. Chu, J. Wang, L. Codec `a, and Z. Li, “Multi-agent deep reinforcement learning for large-scale traffic signal control,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 3, pp. 1086–1095, 2020
work page 2020
-
[4]
Multi-agent reinforcement learning approach for hedging portfolio problem,
U. Pham, Q. Luu, and H. Tran, “Multi-agent reinforcement learning approach for hedging portfolio problem,” Soft Computing , vol. 25, no. 12, pp. 7877–7885, 2021
work page 2021
-
[5]
Smart grid for industry using multi-agent reinforcement learning,
M. Roesch, C. Linder, R. Zimmermann, A. Rudolf, A. Hohmann, and G. Reinhart, “Smart grid for industry using multi-agent reinforcement learning,” Applied Sciences, vol. 10, no. 19, p. 6900, 2020
work page 2020
-
[6]
Multi-agent reinforcement learning: A selective overview of theories and algorithms,
K. Zhang, Z. Yang, and T. Bas ¸ar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” Handbook of Rein- forcement Learning and Control , 2021
work page 2021
-
[7]
T. T. Nguyen, N. D. Nguyen, and S. Nahavandi, “Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications,”IEEE transactions on cybernetics, vol. 50, no. 9, pp. 3826– 3839, 2020
work page 2020
-
[8]
A review of cooperative multi-agent deep reinforcement learning,
A. Oroojlooy and D. Hajinezhad, “A review of cooperative multi-agent deep reinforcement learning,” Applied Intelligence, vol. 53, no. 11, pp. 13 677–13 722, 2023
work page 2023
-
[9]
Cooperative multiagent reinforcement learning with partial observations,
Y . Zhang and M. M. Zavlanos, “Cooperative multiagent reinforcement learning with partial observations,” IEEE Transactions on Automatic Control, vol. 69, no. 2, pp. 968–981, 2023
work page 2023
-
[10]
Multiagent fully decentralized value function learning with linear convergence rates,
L. Cassano, K. Yuan, and A. H. Sayed, “Multiagent fully decentralized value function learning with linear convergence rates,” IEEE Transac- tions on Automatic Control , vol. 66, no. 4, pp. 1497–1512, 2020
work page 2020
-
[11]
Fully decentralized multi-agent reinforcement learning with networked agents,
K. Zhang, Z. Yang, H. Liu, T. Zhang, and T. Basar, “Fully decentralized multi-agent reinforcement learning with networked agents,” in Proceed- ings of the 35th International Conference on Machine Learning (ICML) , vol. 80. PMLR, 2018, pp. 5872–5881
work page 2018
-
[12]
B. Yongacoglu, G. Arslan, and S. Y ¨uksel, “Decentralized learning for optimality in stochastic dynamic teams and games with local control and global state information,” IEEE Transactions on Automatic Control, vol. 67, no. 10, pp. 5230–5245, 2021
work page 2021
-
[13]
Multi-agent safe policy learning for power management of networked microgrids,
Q. Zhang, K. Dehghanpour, Z. Wang, F. Qiu, and D. Zhao, “Multi-agent safe policy learning for power management of networked microgrids,” IEEE Transactions on Smart Grid , vol. 12, no. 2, pp. 1048–1062, 2021
work page 2021
-
[14]
S. He, Y . Wang, S. Han, S. Zou, and F. Miao, “A robust and constrained multi-agent reinforcement learning electric vehicle rebalancing method in amod systems,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2023, pp. 5637–5644
work page 2023
-
[15]
Constrained markov games: Nash equilib- ria,
E. Altman and A. Shwartz, “Constrained markov games: Nash equilib- ria,” in Advances in Dynamic Games and Applications . Springer, 2000, pp. 213–221
work page 2000
-
[16]
Con- strained reinforcement learning has zero duality gap,
S. Paternain, L. Chamon, M. Calvo-Fullana, and A. Ribeiro, “Con- strained reinforcement learning has zero duality gap,” in Advances in Neural Information Processing Systems (NeurIPS) , vol. 32, 2019
work page 2019
-
[17]
Safe policies for reinforcement learning via primal-dual methods,
S. Paternain, M. Calvo-Fullana, L. F. Chamon, and A. Ribeiro, “Safe policies for reinforcement learning via primal-dual methods,” IEEE Transactions on Automatic Control, vol. 68, no. 3, pp. 1321–1336, 2022
work page 2022
-
[18]
On the hardness of constrained cooperative multi-agent reinforcement learning,
Z. Chen, Y . Zhou, and H. Huang, “On the hardness of constrained cooperative multi-agent reinforcement learning,” in Proceedings of the 12th International Conference on Learning Representations (ICLR) , 2024
work page 2024
-
[19]
S. Bhatnagar and K. Lakshmanan, “An online actor-critic algorithm with function approximation for constrained markov decision processes,” Journal of Optimization Theory and Applications, vol. 153, pp. 688–708, 2012
work page 2012
-
[20]
Actor- critic algorithms for constrained multi-agent reinforcement learning,
R. B. Diddigi, D. S. K. Reddy, P. KJ, and S. Bhatnagar, “Actor- critic algorithms for constrained multi-agent reinforcement learning,” in Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , 2019, pp. 1931–1933
work page 2019
-
[21]
Decentralized policy gradient descent ascent for safe multi-agent reinforcement learning,
S. Lu, K. Zhang, T. Chen, T. Bas ¸ar, and L. Horesh, “Decentralized policy gradient descent ascent for safe multi-agent reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 35, no. 10, 2021, pp. 8767–8775
work page 2021
-
[22]
Multi-agent first order constrained optimization in policy space,
Y . Zhao, Y . Yang, Z. Lu, W. Zhou, and H. Li, “Multi-agent first order constrained optimization in policy space,” in Advances in Neural Information Processing Systems (NeurIPS) , vol. 36, 2023, pp. 39 189– 39 211
work page 2023
-
[23]
R. Hassan, K. S. Wadith, M. M. Rashid, and M. M. Khan, “Depaint: A decentralized safe multi-agent reinforcement learning algorithm con- sidering peak and average constraints,” Applied Intelligence , pp. 1–17, 2024
work page 2024
-
[24]
Decom: Decomposed policy for constrained cooperative multi-agent reinforcement learning,
Z. Yang, H. Jin, R. Ding, H. You, G. Fan, X. Wang, and C. Zhou, “Decom: Decomposed policy for constrained cooperative multi-agent reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 10 861–10 870
work page 2023
-
[25]
D. Ying, Y . Zhang, Y . Ding, A. Koppel, and J. Lavaei, “Scalable primal- dual actor-critic method for safe multi-agent reinforcement learning with general utilities,” Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024
work page 2024
-
[26]
Distributed constrained op- timization by consensus-based primal-dual perturbation method,
T.-H. Chang, A. Nedi ´c, and A. Scaglione, “Distributed constrained op- timization by consensus-based primal-dual perturbation method,” IEEE Transactions on Automatic Control, vol. 59, no. 6, pp. 1524–1538, 2014
work page 2014
-
[27]
Distributed subgradient methods for multi- agent optimization,
A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi- agent optimization,” IEEE Transactions on Automatic Control , vol. 54, no. 1, pp. 48–61, 2009
work page 2009
-
[28]
Reinforcement learning: An introduction,
R. S. Sutton, “Reinforcement learning: An introduction,” 2018
work page 2018
-
[29]
H. J. Kushner and D. S. Clark, Stochastic Approximation Methods for Constrained and Unconstrained Systems . Springer, 1978
work page 1978
-
[30]
On-policy deep reinforcement learning for the average-reward criterion,
Y . Zhang and K. W. Ross, “On-policy deep reinforcement learning for the average-reward criterion,” in Proceedings of the 38th International Conference on Machine Learning (ICML) , vol. 139. PMLR, 2021, pp. 12 535–12 545
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.