Efficient Model Repository for Entity Resolution: Construction, Search, and Integration
Pith reviewed 2026-05-23 07:16 UTC · model grok-4.3
The pith
MoRER constructs a repository of entity resolution models by clustering tasks through feature distribution analysis, allowing reuse across heterogeneous sources with moderate new labeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By analyzing feature distributions to cluster entity resolution tasks, MoRER builds and searches a repository of classification models that can be initialized for new tasks with moderate labeling effort, delivering results on par with or better than label-limited baselines and outperforming self-supervised approaches on multi-source data.
What carries the argument
MoRER, a model repository construction method that clusters ER tasks via feature distribution analysis to support model search, initialization, and reuse.
If this is right
- New multi-source entity resolution problems can be solved with fewer fresh labels by starting from repository models of clustered similar tasks.
- Model repository search replaces repeated full training or large-scale self-supervision for each incoming data source combination.
- Performance remains competitive with active learning and transfer learning while exceeding self-supervised pre-trained language model approaches on the tested datasets.
- Results stay comparable to supervised transformer methods once training data volume increases beyond small sizes.
Where Pith is reading between the lines
- The same clustering step could be applied to other record-linkage or deduplication settings outside the three datasets examined.
- Repository growth over time might allow incremental addition of new models without rebuilding clusters from scratch.
- Integration into existing data integration pipelines could lower total labeling cost when sources arrive sequentially.
Load-bearing premise
Feature distribution analysis can reliably group similar entity resolution tasks so that models from one task initialize usefully for another across different data sources.
What would settle it
A controlled test on new multi-source datasets where models started from the clustered repository show no accuracy gain over models trained from random initialization with the same labeling budget would falsify the core reuse benefit.
Figures







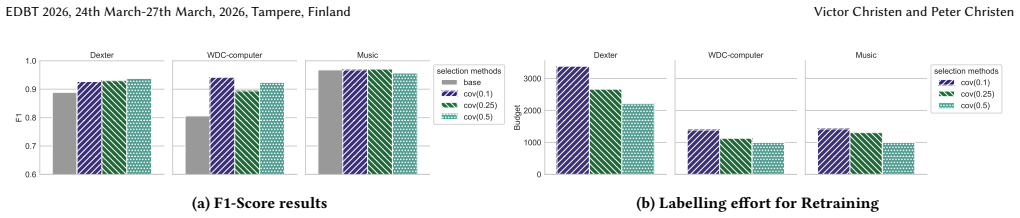
read the original abstract
Entity resolution (ER) is a fundamental task in data integration that enables insights from heterogeneous data sources. The primary challenge of ER lies in classifying record pairs as matches or nonmatches, which in multi-source ER (MS-ER) scenarios can become complicated due to data source heterogeneity and scalability issues. Existing methods for MS-ER generally require labeled record pairs, and such methods fail to effectively reuse models across multiple ER tasks. We propose MoRER (Model Repositories for Entity Resolution), a novel method for building a model repository consisting of classification models that solve ER problems. By leveraging feature distribution analysis, MoRER clusters similar ER tasks, thereby enabling the effective initialization of a model repository with a moderate labeling effort. Experimental results on three multi-source datasets demonstrate that MoRER achieves comparable or better results to methods that have label-limited budgets, such as active learning and transfer learning approaches, while outperforming self-supervised approaches that utilize large pre-trained language models. When compared to supervised transformer-based methods, MoRER achieves comparable or better results, depending on the size of the training data set used.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoRER, a method to construct a model repository for multi-source entity resolution (ER) by using feature distribution analysis to cluster similar ER tasks. This clustering is intended to support effective model initialization and reuse across tasks with only moderate labeling effort. The central experimental claim is that MoRER achieves results comparable or superior to active learning and transfer learning baselines (which also operate under label budgets), outperforms self-supervised methods that rely on large pre-trained language models, and matches supervised transformer-based methods depending on training set size, all demonstrated on three multi-source datasets.
Significance. If the clustering step reliably identifies transferable models, the approach could meaningfully lower labeling costs in heterogeneous multi-source ER settings, a practical bottleneck in data integration. The repository concept itself is a reasonable engineering response to repeated ER tasks, but the significance hinges entirely on whether feature-distribution clusters align with actual transfer performance rather than superficial similarity.
major comments (2)
- [Abstract] Abstract: the claim of 'comparable or better results' on three multi-source datasets is presented without any description of the datasets, evaluation metrics (e.g., F1), baselines, number of runs, error bars, or statistical tests. Because the entire contribution rests on these experimental comparisons rather than a derivation, the absence of these details prevents assessment of whether the results actually support the moderate-labeling claim.
- [Method (feature distribution analysis)] Method section on feature distribution analysis and clustering: the central assumption that clusters derived from feature distributions group ER tasks by transferability (thereby enabling effective model reuse with moderate labels) receives no quantitative validation. No silhouette score, adjusted Rand index against a performance-based similarity matrix, or correlation between distribution distance and cross-task F1 is reported. On heterogeneous multi-source data this check is load-bearing; if the clusters are spurious, the initialization benefit reduces to standard supervised training plus overhead.
minor comments (1)
- [Abstract] Abstract: the qualifier 'depending on the size of the training data set used' for the supervised-transformer comparison is imprecise and should be replaced by concrete sizes or a figure reference.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and commit to revisions that directly incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'comparable or better results' on three multi-source datasets is presented without any description of the datasets, evaluation metrics (e.g., F1), baselines, number of runs, error bars, or statistical tests. Because the entire contribution rests on these experimental comparisons rather than a derivation, the absence of these details prevents assessment of whether the results actually support the moderate-labeling claim.
Authors: We agree that the abstract would benefit from additional context on the experimental setup to allow proper assessment of the claims. In the revised manuscript, we will expand the abstract to include brief descriptions of the three multi-source datasets, specify F1-score as the primary metric, enumerate the baseline categories (active learning, transfer learning, self-supervised methods with pre-trained language models, and supervised transformer-based methods), and note that results are reported as averages over multiple runs with error bars (as detailed in the experimental section). revision: yes
-
Referee: [Method (feature distribution analysis)] Method section on feature distribution analysis and clustering: the central assumption that clusters derived from feature distributions group ER tasks by transferability (thereby enabling effective model reuse with moderate labels) receives no quantitative validation. No silhouette score, adjusted Rand index against a performance-based similarity matrix, or correlation between distribution distance and cross-task F1 is reported. On heterogeneous multi-source data this check is load-bearing; if the clusters are spurious, the initialization benefit reduces to standard supervised training plus overhead.
Authors: We acknowledge that the manuscript does not provide direct quantitative validation (such as silhouette scores or correlation between distribution distances and cross-task F1) linking the feature-distribution clusters to transferability. While the end-to-end results support the overall approach, we agree that explicit checks are needed to substantiate the clustering assumption on heterogeneous data. In the revision, we will add an analysis subsection reporting the correlation between pairwise feature distribution distances and observed cross-task F1 differences, along with silhouette scores for the derived clusters. revision: yes
Circularity Check
No significant circularity; empirical method evaluated experimentally
full rationale
The paper proposes MoRER as an empirical approach to building model repositories for entity resolution via feature distribution analysis for task clustering, followed by experimental validation on three multi-source datasets. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or method description. Performance claims rest on direct comparisons to baselines (active learning, transfer learning, self-supervised PLM methods, supervised transformers) rather than any self-referential construction. The clustering step is presented as an input assumption whose effectiveness is tested externally via results, not defined in terms of the target transferability metric. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By leveraging feature distribution analysis, MoRER clusters similar ER tasks... We construct an ER problem similarity graph GP... cluster the graph GP using the Leiden algorithm
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize the determined aggregated similarity sim_p between ER problems of PI to build an entity resolution problem graph GP... partition the graph into multiple clusters of similar ER problems
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mikhail Bilenko and Raymond J. Mooney. 2003. Adaptive duplicate detection using learnable string similarity measures. InACM SIGKDD. Washington DC, 39–48
work page 2003
-
[2]
Ursin Brunner and Kurt Stockinger. 2020. Entity Matching with Transformer Architectures - A Step Forward in Data Integration. InProceedings of the 23rd International Conference on Extending Database Technology, EDBT 2020, Copenhagen, Denmark, March 30 - April 02, 2020, Angela Bonifati, Yongluan Zhou, Marcos Antonio Vaz Salles, Alexander Böhm, Dan Olteanu,...
-
[3]
Peter Christen. 2012.Data Matching – Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer. https://doi.org/10.1007/978- 3-642-31164-2
-
[4]
Victor Christen, Peter Christen, and Erhard Rahm. 2019. Informativeness- Based Active Learning for Entity Resolution. InMachine Learning and Knowl- edge Discovery in Databases - International Workshops of ECML PKDD (Com- munications in Computer and Information Science), Vol. 1168. Springer, 125–141. https://doi.org/10.1007/978-3-030-43887-6_11
-
[5]
Vassilis Christophides, Vasilis Efthymiou, Themis Palpanas, George Papadakis, and Kostas Stefanidis. 2021. An Overview of End-to-End Entity Resolution for Big Data.ACM Comput. Surv.53, 6 (2021), 127:1–127:42. https://doi.org/10.1145/ 3418896
work page 2021
-
[6]
Fernando de Meer Pardo, Claude Lehmann, Dennis Gehrig, Andrea Nagy, Ste- fano Nicoli, Branka Hadji Misheva, Martin Braschler, and Kurt Stockinger. 2025. GraLMatch: Matching Groups of Entities with Graphs and Language Models. InProceedings 28th International Conference on Extending Database Technology, EDBT 2025, Barcelona, Spain, March 25-28, 2025, Alkis ...
-
[7]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, ...
-
[8]
C., Yash Govind, Derek Paulsen, Kaushik Chandrasekhar, Philip Martinkus, and Matthew Christie
AnHai Doan, Pradap Konda, Paul Suganthan G. C., Yash Govind, Derek Paulsen, Kaushik Chandrasekhar, Philip Martinkus, and Matthew Christie. 2020. Magellan: toward building ecosystems of entity matching solutions.Commun. ACM63, 8 (2020), 83–91. https://doi.org/10.1145/3405476
-
[9]
Joty, Mourad Ouzzani, and Nan Tang
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq R. Joty, Mourad Ouzzani, and Nan Tang. 2017. DeepER - Deep Entity Resolution.CoRR abs/1710.00597 (2017). arXiv:1710.00597 http://arxiv.org/abs/1710.00597
-
[10]
M. Girvan and M. E. J. Newman. 2002. Community structure in social and biological networks.Proceedings of the National Academy of Sciences99, 12 (June 2002), 7821–7826. https://doi.org/10.1073/pnas.122653799
-
[11]
Rihan Hai, Christos Koutras, Christoph Quix, and Matthias Jarke. 2023. Data Lakes: A Survey of Functions and Systems.IEEE Trans. Knowl. Data Eng.35, 12 (2023), 12571–12590. https://doi.org/10.1109/TKDE.2023.3270101
-
[12]
Kai Hildebrandt, Fabian Panse, Niklas Wilcke, and Norbert Ritter. 2020. Large- Scale Data Pollution with Apache Spark.IEEE Trans. Big Data6, 2 (2020), 396–411. https://doi.org/10.1109/TBDATA.2016.2637378
-
[13]
Myles Hollander, Douglas A. Wolfe, and Eric Chicken. 2013.Nonparametric Statistical Methods(3rd ed.). John Wiley & Sons
work page 2013
-
[14]
Di Jin, Bunyamin Sisman, Hao Wei, Xin Luna Dong, and Danai Koutra. 2021. Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation.Proc. VLDB Endow.15, 3 (2021), 465–477. https://doi.org/10.14778/3494124.3494131
-
[15]
Nishadi Kirielle, Peter Christen, and Thilina Ranbaduge. 2022. TransER: Ho- mogeneous Transfer Learning for Entity Resolution. InProceedings of the 25th International Conference on Extending Database Technology, EDBT 2022, Edin- burgh, UK, March 29 - April 1, 2022. OpenProceedings.org, 2:118–2:130. https: //doi.org/10.48786/EDBT.2022.03
-
[16]
C., AnHai Doan, Adel Ardalan, Jeffrey R
Pradap Konda, Sanjib Das, Paul Suganthan G. C., AnHai Doan, Adel Ardalan, Jeffrey R. Ballard, Han Li, Fatemah Panahi, Haojun Zhang, Jeffrey F. Naughton, Shishir Prasad, Ganesh Krishnan, Rohit Deep, and Vijay Raghavendra. 2016. Magellan: Toward Building Entity Matching Management Systems.Proc. VLDB Endow.9, 12 (2016), 1197–1208. https://doi.org/10.14778/29...
-
[17]
Hannah Köpcke, Andreas Thor, and Erhard Rahm. 2010. Learning-Based Ap- proaches for Matching Web Data Entities.IEEE Internet Computing14, 4 (2010), 23–31. https://doi.org/10.1109/MIC.2010.58
-
[18]
Stefan Lerm, Alieh Saeedi, and Erhard Rahm. 2021. Extended Affinity Propa- gation Clustering for Multi-source Entity Resolution. InDatenbanksysteme für Business, Technologie und Web (BTW 2021), 19. Fachtagung des GI-Fachbereichs „Datenbanken und Informationssysteme" (DBIS), 13.-17. September 2021, Dres- den, Germany, Proceedings (LNI), Kai-Uwe Sattler, Me...
-
[19]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan
-
[20]
VLDB Endow.14, 1 (2020), 50–60
Deep Entity Matching with Pre-Trained Language Models.Proc. VLDB Endow.14, 1 (2020), 50–60. https://doi.org/10.14778/3421424.3421431
-
[21]
Robin Linacre, Sam Lindsay, Theodore Manassis, Zoe Slade, Tom Hepworth, Ross Kennedy, and Andrew Bond. 2022. Splink: Free software for probabilistic record linkage at scale.International Journal of Population Data Science7, 3 (Aug. 2022). https://doi.org/10.23889/ijpds.v7i3.1794
-
[22]
Michael Loster, Ioannis K. Koumarelas, and Felix Naumann. 2021. Knowledge Transfer for Entity Resolution with Siamese Neural Networks.ACM J. Data Inf. Qual.13, 1 (2021), 2:1–2:25. https://doi.org/10.1145/3410157
-
[23]
Jakub Maciejewski, Konstantinos Nikoletos, George Papadakis, and Yannis Vele- grakis. 2025. Progressive Entity Matching: A Design Space Exploration.Proc. ACM Manag. Data3, 1, Article 65 (Feb. 2025), 25 pages. https://doi.org/10.1145/3709715
-
[24]
Barzan Mozafari, Purna Sarkar, Michael Franklin, Michael Jordan, and Samuel Madden. 2014. Scaling Up Crowd-sourcing to Very Large Datasets: A Case for Active Learning.PVLDB Endowment8, 2 (Oct. 2014), 125–136
work page 2014
-
[25]
Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. 2018. Deep Learning for Entity Matching: A Design Space Exploration. InProceedings of the 2018 International Conference on Management of Data(Houston, TX, USA) (SIGMOD ’18). Association for Computing Machinery, N...
-
[26]
Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. 2018. Deep Learning for Entity Matching: A Design Space Exploration. InProceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, Gautam Da...
-
[27]
Axel-Cyrille Ngonga Ngomo and Klaus Lyko. 2012. EAGLE: Efficient Active Learning of Link Specifications Using Genetic Programming. InThe Semantic Web: Research and Applications. Berlin, Heidelberg, 149–163
work page 2012
-
[28]
S. Padmanabhan, L. Carty, E. Cameron, R. E. Ghosh, R. Williams, and H. Strong- man. 2019. Approach to record linkage of primary care data from Clini- cal Practice Research Datalink to other health-related patient data: overview and implications.European Journal of Epidemiology34, 1 (Jan 2019), 91–99. https://doi.org/10.1007/s10654-018-0442-4 Epub 2018 Sep 15
-
[29]
George Papadakis, Dimitrios Skoutas, Emmanouil Thanos, and Themis Palpanas
-
[30]
Blocking and Filtering Techniques for Entity Resolution: A Survey.ACM Comput. Surv.53, 2 (2021), 31:1–31:42. https://doi.org/10.1145/3377455
-
[31]
Ralph Peeters and Christian Bizer. 2023. Using ChatGPT for Entity Matching. In New Trends in Database and Information Systems - ADBIS 2023 (Communications in Computer and Information Science), Vol. 1850. Springer, 221–230. https://doi. org/10.1007/978-3-031-42941-5_20
-
[32]
Anna Primpeli and Christian Bizer. 2021. Graph-Boosted Active Learning for Multi-source Entity Resolution. InThe Semantic Web - ISWC 2021 - 20th Inter- national Semantic Web Conference, ISWC 2021, Virtual Event, October 24-28, 2021, Proceedings (Lecture Notes in Computer Science), Vol. 12922. Springer, 182–199. https://doi.org/10.1007/978-3-030-88361-4_11
-
[33]
Anna Primpeli, Ralph Peeters, and Christian Bizer. 2019. The WDC Training Dataset and Gold Standard for Large-Scale Product Matching. InCompanion of The 2019 World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019, Sihem Amer-Yahia, Mohammad Mahdian, Ashish Goel, Geert-Jan Houben, Kristina Lerman, Julian J. McAuley, Ricardo Baeza-Yate...
-
[34]
Usha Nandini Raghavan, Réka Albert, and Soundar Kumara. 2007. Near linear time algorithm to detect community structures in large-scale networks.Phys. Rev. E76 (Sep 2007), 036106. Issue 3. https://doi.org/10.1103/PhysRevE.76.036106
-
[35]
Alieh Saeedi, Lucie David, and Erhard Rahm. 2021. Matching Entities from Mul- tiple Sources with Hierarchical Agglomerative Clustering. InIC3K. SCITEPRESS, 40–50. https://doi.org/10.5220/0010649600003064
-
[36]
Alieh Saeedi, Eric Peukert, and Erhard Rahm. 2018. Using Link Features for Entity Clustering in Knowledge Graphs. InThe Semantic Web - 15th International Conference, ESWC 2018, Proceedings (Lecture Notes in Computer Science), Vol. 10843. Springer, 576–592. https://doi.org/10.1007/978-3-319-93417-4_37
-
[37]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Dis- tilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.CoRR abs/1910.01108 (2019). arXiv:1910.01108 http://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Mike Schuster and Kuldip K. Paliwal. 1997. Bidirectional recurrent neural net- works.IEEE Trans. Signal Process.45, 11 (1997), 2673–2681. https://doi.org/10. 1109/78.650093
work page 1997
-
[39]
2005.Credit Risk Scorecards: Developing and Implementing Intelli- gent Credit Scoring
Naeem Siddiqi. 2005.Credit Risk Scorecards: Developing and Implementing Intelli- gent Credit Scoring. John Wiley & Sons
work page 2005
-
[40]
Michael Stonebraker and Ihab F. Ilyas. 2018. Data Integration: The Current Status and the Way Forward.IEEE Data Eng. Bull.41, 2 (2018), 3–9
work page 2018
-
[41]
Saravanan Thirumuruganathan, Han Li, Nan Tang, Mourad Ouzzani, Yash Govind, Derek Paulsen, Glenn Fung, and AnHai Doan. 2021. Deep Learning for Blocking EDBT 2026, 24th March-27th March, 2026, Tampere, Finland Victor Christen and Peter Christen in Entity Matching: A Design Space Exploration.Proc. VLDB Endow.14, 11 (2021), 2459–2472. https://doi.org/10.1477...
-
[42]
V. A. Traag, L. Waltman, and N. J. van Eck. 2019. From Louvain to Leiden: guaranteeing well-connected communities.Scientific Reports9, 1 (March 2019). https://doi.org/10.1038/s41598-019-41695-z
-
[43]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
work page 2017
-
[44]
Cédric Villani. 2009.Optimal Transport: Old and New. Springer-Verlag Berlin Heidelberg. https://doi.org/10.1007/978-3-540-71050-9
-
[45]
Qing Wang, Dinusha Vatsalan, and Peter Christen. 2015. Efficient Interactive Training Selection for Large-Scale Entity Resolution. InPAKDD. Ho Chi Minh City, Vietnam
work page 2015
-
[46]
Runhui Wang, Yuliang Li, and Jin Wang. 2023. Sudowoodo: Contrastive Self- supervised Learning for Multi-purpose Data Integration and Preparation. In39th IEEE International Conference on Data Engineering, ICDE 2023, Anaheim, CA, USA, April 3-7, 2023. IEEE, 1502–1515. https://doi.org/10.1109/ICDE55515.2023.00391
- [47]
-
[48]
Renzhi Wu, Sanya Chaba, Saurabh Sawlani, Xu Chu, and Saravanan Thirumu- ruganathan. 2020. ZeroER: Entity Resolution using Zero Labeled Examples. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang-Chiew Ta...
-
[49]
Xiaocan Zeng, Pengfei Wang, Yuren Mao, Lu Chen, Xiaoze Liu, and Yunjun Gao. 2024. MultiEM: Efficient and Effective Unsupervised Multi-Table Entity Matching. In40th IEEE International Conference on Data Engineering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 3421–3434. https://doi.org/10. 1109/ICDE60146.2024.00264
-
[50]
Zeyu Zhang, Paul Groth, Iacer Calixto, and Sebastian Schelter. 2025. A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models. InProceedings 28th International Conference on Extending Database Technology, EDBT 2025, Barcelona, Spain, March 25-28, 2025, Alkis Simitsis, Bettina Kemme, Anna Queralt, Oscar Romero, and Petar Jovanovi...
-
[51]
Chen Zhao and Yeye He. 2019. Auto-EM: End-to-end Fuzzy Entity-Matching using Pre-trained Deep Models and Transfer Learning. InThe World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019, Ling Liu, Ryen W. White, Amin Mantrach, Fabrizio Silvestri, Julian J. McAuley, Ricardo Baeza-Yates, and Leila Zia (Eds.). ACM, 2413–2424. https://doi...
-
[52]
2002.Learning from labeled and unlabeled data with label propagation
Xiaojin Zhu and Zoubin Ghahramani. 2002.Learning from labeled and unlabeled data with label propagation. Technical Report CMU-CALD-02-107. Carnegie Mellon University
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.