Explainable Detection of Machine Generated Music and Early Systematic Evaluation
Pith reviewed 2026-05-23 07:35 UTC · model grok-4.3
The pith
ResNet18 achieves the best results in detecting machine-generated music across in-domain and out-of-domain tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
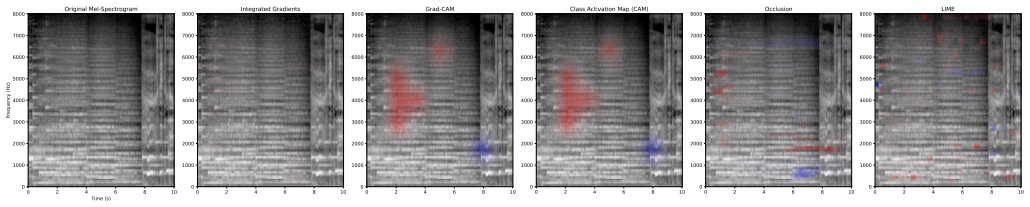
Experiments on existing large-scale datasets establish that ResNet18, among traditional machine learning models, deep neural networks, Transformer-based architectures, state space models, and multimodal models, delivers the highest accuracy for binary classification of machine-generated versus human music in both in-domain and out-of-domain settings. Multiple explainable AI tools are used to examine the internal decision processes of the evaluated models.
What carries the argument
ResNet18 applied to audio features for binary classification of music origin, supported by explainable AI analysis of its decisions.
If this is right
- ResNet18 can serve as a strong baseline model for future machine-generated music detection systems.
- Audio-only models are sufficient to reach top performance even though music combines melody and lyrics.
- Systematic benchmarks now exist for comparing new detection methods against established results.
- Explainable AI techniques can be applied to reveal decision patterns in audio classification models.
Where Pith is reading between the lines
- Platforms could integrate a ResNet18-based detector to flag machine-generated tracks before public release.
- The current best model may require retraining or replacement when new music generation techniques appear.
- Detection performance could be further improved by combining ResNet18 features with other architectures rather than replacing it outright.
Load-bearing premise
The large-scale datasets used for training and testing accurately represent real-world human and machine-generated music without major distribution shifts, label noise, or leakage.
What would settle it
A new held-out collection of music generated by recent AI systems on which ResNet18 no longer records the highest accuracy in both in-domain and out-of-domain splits would falsify the performance claim.
Figures

read the original abstract
Machine-generated music (MGM) has become a groundbreaking innovation with wide-ranging applications, such as music therapy, personalised editing, and creative inspiration within the music industry. However, the unregulated proliferation of MGM presents considerable challenges to the entertainment, education, and arts sectors by potentially undermining the value of high-quality human compositions. Consequently, MGM detection (MGMD) is crucial for preserving the integrity of these fields. Despite its significance, MGMD domain lacks comprehensive systematic evaluation results necessary to drive meaningful progress. To address this gap, we conduct experiments on existing large-scale datasets using a range of foundational models for audio processing, establishing systematic evaluation results tailored to the MGMD task. Our selection includes traditional machine learning models, deep neural networks, Transformer-based architectures, and State space models (SSM). Recognising the inherently multimodal nature of music, which integrates both melody and lyrics, we also explore fundamental multimodal models in our experiments. Beyond providing basic binary classification outcomes, we delve deeper into model behaviour using multiple explainable Artificial Intelligence (XAI) tools, offering insights into their decision-making processes. Our analysis reveals that ResNet18 performs the best according to in-domain and out-of-domain tests. By providing a comprehensive comparison of systematic evaluation results and their interpretability, we propose several directions to inspire future research to develop more robust and effective detection methods for MGM. We provide our codes and some samples on Github repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses the lack of systematic evaluation in machine-generated music detection (MGMD) by benchmarking traditional ML models, DNNs (including ResNet18), Transformer architectures, state-space models, and multimodal models on existing large-scale datasets. It reports binary classification results, applies multiple XAI tools to analyze decision processes, concludes that ResNet18 achieves the highest performance on both in-domain and out-of-domain tests, and releases code plus samples on GitHub.
Significance. If the reported ranking proves robust, the work supplies an early reproducible benchmark for MGMD and illustrates how XAI can surface model behaviors in audio tasks. The explicit code release is a clear strength that supports verification and extension by others.
major comments (3)
- [Abstract] Abstract and experimental description: the claim that ResNet18 performs best on in-domain and out-of-domain tests is presented without dataset sizes, class balances, train/test split ratios, or any statistical significance tests on the performance differences. These omissions make it impossible to determine whether the ranking is reliable or sensitive to sampling variation.
- [Experimental description] Experimental description: the superiority of ResNet18 rests on the assumption that the large-scale datasets contain accurate labels and no train/test leakage (e.g., shared tracks or artists). The manuscript provides no description of leakage checks, artist/track deduplication, or label verification steps, which are load-bearing for the central empirical claim given known risks in music corpora.
- [Results] Results section: no hyper-parameter search protocol, error bars, or cross-validation details are reported for any model. Without these, the stability of the model ranking and the out-of-domain generalization claim cannot be assessed.
minor comments (2)
- [Abstract] The abstract is lengthy and repeats the list of model families; condensing it would improve readability.
- [Abstract] First use of model acronyms (SSM, XAI) should be expanded for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: the claim that ResNet18 performs best on in-domain and out-of-domain tests is presented without dataset sizes, class balances, train/test split ratios, or any statistical significance tests on the performance differences. These omissions make it impossible to determine whether the ranking is reliable or sensitive to sampling variation.
Authors: We agree these details strengthen interpretability of the claims. The experimental section already specifies the datasets and splits; we will expand the abstract with summary statistics on sizes, balances, and ratios. We will also add statistical significance tests (e.g., bootstrap confidence intervals or paired tests) on the reported performance differences in the revised results. revision: yes
-
Referee: [Experimental description] Experimental description: the superiority of ResNet18 rests on the assumption that the large-scale datasets contain accurate labels and no train/test leakage (e.g., shared tracks or artists). The manuscript provides no description of leakage checks, artist/track deduplication, or label verification steps, which are load-bearing for the central empirical claim given known risks in music corpora.
Authors: We acknowledge the concern. Experiments used the datasets in their released form, relying on original labels without additional artist/track deduplication or independent verification. We will revise the experimental description to explicitly state these choices, note reliance on source labels, and discuss potential leakage risks as a study limitation. revision: yes
-
Referee: [Results] Results section: no hyper-parameter search protocol, error bars, or cross-validation details are reported for any model. Without these, the stability of the model ranking and the out-of-domain generalization claim cannot be assessed.
Authors: Hyperparameters followed standard recommendations from the literature for each architecture to ensure feasible and comparable evaluation. No exhaustive search or k-fold cross-validation was performed given dataset scale. We will expand the results section with the exact hyperparameter protocol used and report variability from repeated runs with different seeds to provide error estimates where data permit. revision: partial
Circularity Check
No circularity: direct empirical comparison on fixed datasets
full rationale
The paper performs a standard empirical evaluation of off-the-shelf audio models (including ResNet18) on existing large-scale datasets for binary MGM detection, reporting in-domain and out-of-domain accuracies plus XAI analyses. No mathematical derivation, fitted parameter, or self-citation chain is used to establish the central claim that ResNet18 performs best; the ranking follows directly from measured performance metrics on the chosen splits. The study contains no self-definitional loops, predictions that reduce to fitted inputs, or load-bearing self-citations. This is a normal non-circular empirical ML comparison.
Axiom & Free-Parameter Ledger
free parameters (2)
- Model hyperparameters (learning rate, layers, etc.)
- Train/validation/test splits
axioms (2)
- domain assumption Labeled audio datasets exist that contain both human-composed and machine-generated music and are sufficiently representative for benchmarking.
- standard math Standard cross-entropy classification loss and accuracy metrics are appropriate for the MGMD task.
Forward citations
Cited by 1 Pith paper
-
AT-ADD: All-Type Audio Deepfake Detection Challenge Evaluation Plan
AT-ADD introduces standardized tracks and datasets for evaluating audio deepfake detectors on speech under real-world conditions and on diverse unknown audio types to promote generalization beyond speech-centric methods.
Reference graph
Works this paper leans on
- [1]
-
[2]
Aiva - the ai music generation assistant,
AIV A Technologies, “Aiva - the ai music generation assistant,” 2023, Accessed: 2024-12-08
work page 2023
-
[3]
Artificial creativity. perceptions and prejudices on ai music production,
Alessandra Micalizzi, “Artificial creativity. perceptions and prejudices on ai music production,” in International Congress on Information and Communication Technology. Springer, 2024, pp. 481–491
work page 2024
-
[4]
Jean-Pierre Briot, Ga ¨etan Hadjeres, and Franc ¸ois-David Pachet, Deep Learning Techniques for Music Generation , Computational Synthesis and Creative Systems. Springer, 2020
work page 2020
-
[5]
From audio deepfake detection to ai-generated music detection–a pathway and overview,
Yupei Li, Manuel Milling, Lucia Specia, and Bj ¨orn W Schuller, “From audio deepfake detection to ai-generated music detection–a pathway and overview,” arXiv preprint arXiv:2412.00571 , 2024
-
[6]
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly, “As good as a coin toss human detection of ai-generated images, videos, audio, and audiovisual stimuli,” arXiv preprint arXiv:2403.16760, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Sonics: Synthetic or not– identifying counterfeit songs,
Md Awsafur Rahman, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, and Shaikh Anowarul Fattah, “Sonics: Synthetic or not– identifying counterfeit songs,” arXiv preprint arXiv:2408.14080 , 2024
-
[8]
Detecting music deepfakes is easy but actually hard,
Darius Afchar, Gabriel Meseguer Brocal, and Romain Hennequin, “Detecting music deepfakes is easy but actually hard,” arXiv preprint arXiv:2405.04181, 2024
-
[9]
Relyme: Improving lyric-to-melody generation by incorporating lyric-melody relationships,
Chen Zhang, Luchin Chang, Songruoyao Wu, Xu Tan, Tao Qin, Tie-Yan Liu, and Kejun Zhang, “Relyme: Improving lyric-to-melody generation by incorporating lyric-melody relationships,” in Proceedings of the 30th ACM International Conference on Multimedia . Oct. 2022, MM ’22, p. 1047–1056, ACM
work page 2022
-
[10]
Telemelody: Lyric-to-melody generation with a template-based two-stage method,
Zeqian Ju, Peiling Lu, Xu Tan, Rui Wang, Chen Zhang, Songruoyao Wu, Kejun Zhang, Xiangyang Li, Tao Qin, and Tie-Yan Liu, “Telemelody: Lyric-to-melody generation with a template-based two-stage method,” 2022
work page 2022
-
[11]
Luca Comanducci, Paolo Bestagini, and Stefano Tubaro, “Fakemusic- caps: a dataset for detection and attribution of synthetic music generated via text-to-music models,” arXiv preprint arXiv:2409.10684 , 2024
-
[12]
Yupei Li, Hanqian Li, Lucia Specia, and Bj ¨orn W. Schuller, “M6: Multi- generator, multi-domain, multi-lingual and cultural, multi-genres, multi- instrument machine-generated music detection databases,” 2024
work page 2024
-
[13]
Audio deepfake detection: A survey,
Jiangyan Yi, Chenglong Wang, Jianhua Tao, Xiaohui Zhang, Chu Yuan Zhang, and Yan Zhao, “Audio deepfake detection: A survey,” 2023
work page 2023
-
[14]
A review of modern audio deepfake detection methods: challenges and future directions,
Zaynab Almutairi and Hebah Elgibreen, “A review of modern audio deepfake detection methods: challenges and future directions,” Algo- rithms, vol. 15, no. 5, pp. 155, 2022
work page 2022
-
[15]
A Vaswani, “Attention is all you need,” Advances in Neural Information Processing Systems, 2017
work page 2017
-
[16]
Detection of ai-synthesized speech using cepstral & bispectral statistics,
Arun Kumar Singh and Priyanka Singh, “Detection of ai-synthesized speech using cepstral & bispectral statistics,” in 2021 IEEE 4th International Conference on Multimedia Information Processing and Retrieval (MIPR) . IEEE, 2021, pp. 412–417
work page 2021
-
[17]
Harsh Agarwal, Ankur Singh, and D Rajeswari, “Deepfake detection using svm,” in 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC) . IEEE, 2021, pp. 1245– 1249
work page 2021
-
[18]
Convolutional networks for images, speech, and time-series,
Yann LeCun, Benjamin Boser, John S. Denker, David Henderson, Robert E. Howard, W. Hubbard, and L. D. Jackel, “Convolutional networks for images, speech, and time-series,” Proceedings of the IEEE International Conference on Neural Networks , vol. 2, pp. 199– 206, 1995
work page 1995
-
[19]
Deep residual learning for image recognition,
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770– 778
work page 2016
-
[20]
Audio-deepfake detection: Adversarial attacks and countermeasures,
Mouna Rabhi, Spiridon Bakiras, and Roberto Di Pietro, “Audio-deepfake detection: Adversarial attacks and countermeasures,” Expert Systems with Applications , vol. 250, pp. 123941, 2024
work page 2024
-
[21]
Very deep convolutional networks for large-scale image recognition,
Karen Simonyan and Andrew Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proceedings of the International Conference on Learning Representations (ICLR) , 2015
work page 2015
-
[22]
The effect of deep learning methods on deepfake audio detection for digital investigation,
Mvelo Mcuba, Avinash Singh, Richard Adeyemi Ikuesan, and Hein Venter, “The effect of deep learning methods on deepfake audio detection for digital investigation,” Procedia Computer Science , vol. 219, pp. 211–219, 2023
work page 2023
-
[23]
Squeeze-and-excitation networks,
Jie Hu, Li Shen, and Gang Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1915–1923
work page 2018
-
[24]
Improving the robustness of deepfake audio detection through confidence calibration.,
Yuxiang Zhang, Jingze Lu, Zhuo Li, Zengqiang Shang, Wenchao Wang, and Pengyuan Zhang, “Improving the robustness of deepfake audio detection through confidence calibration.,” in DADA@ IJCAI, 2023, pp. 70–75
work page 2023
-
[25]
Mobilenets: Efficient convolutional neural networks for mobile vision applications,
Andrew G Howard, Menglong Zhu, Liang Chen, Dmitry Kalenichenko, Weijun Wang, Tal Weyand, Michele Andreetto, and Hartwig Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 6090–6098
work page 2017
-
[26]
Yan Wen, Zhenchun Lei, Yingen Yang, Changhong Liu, and Minglei Ma, “Multi-path gmm-mobilenet based on attack algorithms and codecs for synthetic speech and deepfake detection.,” in INTERSPEECH, 2022, pp. 4795–4799
work page 2022
-
[27]
Sepp Hochreiter and J ¨urgen Schmidhuber, “Long short-term memory,” in Neural computation . 1997, vol. 9, pp. 1735–1780, MIT Press
work page 1997
-
[28]
A hybrid cnn-lstm model for video deepfake detec- tion by leveraging optical flow features,
Pallabi Saikia, Dhwani Dholaria, Priyanka Yadav, Vaidehi Patel, and Mohendra Roy, “A hybrid cnn-lstm model for video deepfake detec- tion by leveraging optical flow features,” in 2022 international joint conference on neural networks (IJCNN) . IEEE, 2022, pp. 1–7
work page 2022
-
[29]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
Deepfake audio detection with vision transformer based method,
Guzin Ulutas, Gul Tahaoglu, and Beste Ustubioglu, “Deepfake audio detection with vision transformer based method,” in 2023 46th Interna- tional Conference on Telecommunications and Signal Processing (TSP) . IEEE, 2023, pp. 244–247
work page 2023
-
[31]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
xlstm: Extended long short-term memory,
Maximilian Beck, Korbinian P ¨oppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, G ¨unter Klambauer, Johannes Brandstetter, and Sepp Hochreiter, “xlstm: Extended long short-term memory,” 2024
work page 2024
-
[33]
Mul- timodal music information processing and retrieval: Survey and future challenges,
Federico Simonetta, Stavros Ntalampiras, and Federico Avanzini, “Mul- timodal music information processing and retrieval: Survey and future challenges,” in 2019 international workshop on multilayer music representation and processing (MMRP) . IEEE, 2019, pp. 10–18
work page 2019
-
[34]
Llark: A multimodal instruction-following language model for music,
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M. Bittner, “Llark: A multimodal instruction-following language model for music,” 2024
work page 2024
-
[35]
Explainable artificial intelligence for medical applications: A review,
Qiyang Sun, Alican Akman, and Bj ¨orn W Schuller, “Explainable artificial intelligence for medical applications: A review,” arXiv preprint arXiv:2412.01829, 2024
-
[36]
Detecting deepfake voice using explainable deep learning techniques,
Suk-Young Lim, Dong-Kyu Chae, and Sang-Chul Lee, “Detecting deepfake voice using explainable deep learning techniques,” Applied Sciences, vol. 12, no. 8, pp. 3926, 2022
work page 2022
-
[37]
Acoustic features analysis for explainable machine learning-based audio spoofing detection,
Carmen Bisogni, Vincenzo Loia, Michele Nappi, and Chiara Pero, “Acoustic features analysis for explainable machine learning-based audio spoofing detection,” Computer Vision and Image Understanding , vol. 249, pp. 104145, 2024
work page 2024
-
[38]
Learning to mask: A method for occlusion- based visual explanation,
Y . Du, W. Lee, and D. Kim, “Learning to mask: A method for occlusion- based visual explanation,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pp. 14423–14431, 2020
work page 2020
-
[39]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” in Proceedings of the 34th International Conference on Machine Learning , 2017, pp. 3319–3328
work page 2017
-
[40]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2017, pp. 618–626
work page 2017
-
[41]
Learning deep features for discriminative localization,
B. Zhou, A. Liu, and H. Sun, “Learning deep features for discriminative localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016, pp. 2921–2929
work page 2016
-
[42]
Why should i trust you? explaining the predictions of any classifier,
M. T. Ribeiro, S. Singh, and C. Guestrin, “Why should i trust you? explaining the predictions of any classifier,” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pp. 1135–1144, 2016
work page 2016
-
[43]
librosa: Audio and music signal analysis in python.,
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto, “librosa: Audio and music signal analysis in python.,” in SciPy, 2015, pp. 18–24
work page 2015
-
[44]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in Neural Information Processing Systems , vol. 33, pp. 12449–12460, 2020
work page 2020
-
[45]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams, Learn- ing Representations by Back-Propagating Errors , vol. 323, Macmillan Publishers, 1986. TABLE VI HYPERPARAMETER SETTINGS Hyperparameter Value Batch Size 64 Epochs 10 GPU Tesla V100 input size 224 × 224 Learning Rate 0.001 optimiser Adam VI. A PPENDIX A. Baseline Model Hyperparameters We...
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.