Sample size calculations for multilevel factorial longitudinal cluster randomised trials
Pith reviewed 2026-05-19 01:44 UTC · model grok-4.3
The pith
Power to detect individual, cluster, and interaction effects in split-plot factorial longitudinal cluster trials follows from standard formulas for simpler trial designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For continuous outcomes in split-plot factorial longitudinal cluster randomised trials, the power to detect a given effect of the individual-level intervention, the cluster-level intervention, and the interaction between them is determined directly from standard power formulas for individually randomised trials and for longitudinal cluster randomised trials.
What carries the argument
The split-plot factorial longitudinal cluster randomised trial, in which clusters are randomised to levels of one factor while individuals within clusters are randomised to levels of the second factor, with outcomes measured repeatedly over time.
If this is right
- Trial designers can plan joint assessment of patient-level and clinic-level interventions in stepped-wedge or crossover settings using readily available power calculators.
- The approach extends to any longitudinal cluster design whose power formula is already known, without requiring a completely new derivation.
- Interaction effects between the two intervention levels become testable within the same study that also estimates the separate main effects.
- Sample size can be expressed in terms of the variances and intra-class correlations already familiar from simpler trial types.
Where Pith is reading between the lines
- The method may reduce the barrier to running multilevel intervention studies in fields such as oncology or primary care where both clinician behaviour and patient education matter.
- Extension to binary or time-to-event outcomes would follow the same logic once the corresponding component formulas are substituted.
- The framework invites direct comparison of efficiency between split-plot factorial longitudinal designs and separate single-factor trials.
Load-bearing premise
That the power for the full multilevel factorial longitudinal design can be assembled by direct combination of existing formulas from separate individual-randomised and longitudinal cluster-randomised trials without extra terms for time-dependent interactions or the specific factorial randomisation structure.
What would settle it
A Monte Carlo simulation of a split-plot factorial longitudinal cluster trial in which the sample size chosen from the combined formulas fails to deliver the nominal power for the interaction effect when the true data-generating process includes realistic cluster-level and temporal correlation.
Figures

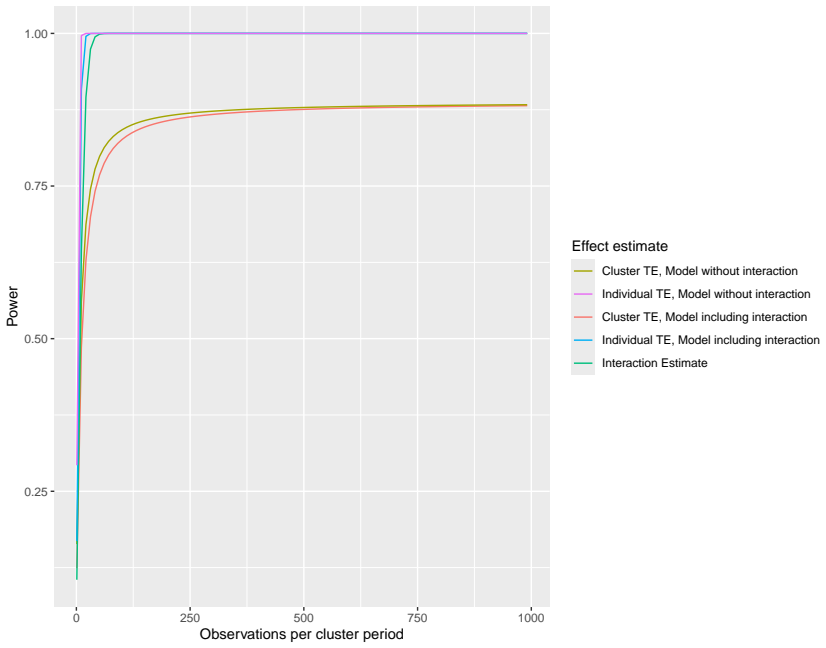

read the original abstract
Typically, trials investigate the impact of either an individual-level intervention on participant outcomes, or the impact of a cluster-level intervention on participant outcomes. Factorial designs consider two (or more) treatments for each of two (or more) different factors. In factorial trial designs, trial units (individuals or clusters) are each randomised to a level of each of the treatments; these designs allow assessment of the interactions between different interventions. Recently, there has been growing interest in the design of trials that jointly assess the impact of individual- and cluster-level interventions (i.e. multi-level interventions); requiring the development of methodology that accommodates randomisation at multiple levels. While recent work has developed sample size methodology for variants combining standard cluster randomisation and individual randomisation, that work does not apply to longitudinal cluster randomised trial designs such as the stepped wedge design or cluster randomised crossover design. Here we present dedicated sample size methodology for "split-plot factorial longitudinal cluster randomised trials" with continuous outcomes: allowing for joint assessment of individual-level and cluster-level interventions that allows for the impact of the cluster-level intervention to be assessed using any longitudinal cluster randomised trial design. We show how the power to detect given effects of the individual-level intervention, the cluster-level intervention, and the interaction between the two depends on standard results for individually-randomised trials and longitudinal cluster randomised trials. We apply these results to the SharES trial, which considered the effects of a patient- and clinician-level interventions for patients with breast cancer on patient knowledge about the risks and benefits of treatment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents dedicated sample size methodology for split-plot factorial longitudinal cluster randomised trials with continuous outcomes. It enables joint assessment of individual-level and cluster-level interventions (and their interaction) where the cluster-level intervention is evaluated via any longitudinal cluster randomised trial design such as stepped wedge or cluster crossover. The central claim is that power for the three effects follows directly from combining standard power results for individually randomised trials and longitudinal cluster randomised trials; the approach is illustrated via application to the SharES trial.
Significance. If the combination of existing formulas is shown to be statistically valid for the split-plot factorial structure, the work would supply a practical, accessible tool for sample-size planning in trials that evaluate multilevel interventions within longitudinal cluster designs. This addresses a methodological gap without requiring wholly new derivations, which is efficient. The real-trial application adds immediate relevance for trialists working on patient- and clinician-level interventions.
major comments (1)
- [Abstract and Methods] Abstract and Methods: the claim that power expressions for the individual-level, cluster-level, and interaction effects are obtained directly by combining standard results rests on the unstated assumption that the multilevel factorial structure introduces no additional variance components or time-dependent interaction terms beyond those already present in the separate individual-randomised and longitudinal-cluster formulae. Without an explicit combined variance expression or design-matrix adjustment (e.g., for the interaction contrast in a longitudinal mixed model), it is not possible to verify that the combination preserves correct type-I error and power for the interaction test.
minor comments (1)
- [Application] The SharES trial example would benefit from a short table listing the assumed effect sizes, intra-cluster correlations, and autocorrelation values used to obtain the reported sample sizes, allowing readers to reproduce the calculations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. The observation regarding the need for explicit verification of the combined variance structure is well taken and has prompted us to strengthen the presentation of the underlying model.
read point-by-point responses
-
Referee: Abstract and Methods: the claim that power expressions for the individual-level, cluster-level, and interaction effects are obtained directly by combining standard results rests on the unstated assumption that the multilevel factorial structure introduces no additional variance components or time-dependent interaction terms beyond those already present in the separate individual-randomised and longitudinal-cluster formulae. Without an explicit combined variance expression or design-matrix adjustment (e.g., for the interaction contrast in a longitudinal mixed model), it is not possible to verify that the combination preserves correct type-I error and power for the interaction test.
Authors: We agree that an explicit derivation of the variance expressions would improve verifiability. The split-plot factorial structure nests individual-level randomisation within the cluster-level longitudinal design, so that the fixed-effects contrasts for the individual-level main effect, cluster-level main effect, and their interaction remain orthogonal under the assumed linear mixed model. The random-effects structure (cluster, time, and cluster-by-time) is inherited directly from the longitudinal cluster trial component and does not acquire extra time-dependent interaction terms from the factorial aspect. In the revised manuscript we will add a subsection that states the full model, supplies the design-matrix contrast vectors for each effect, and derives the variance of the interaction estimator as a linear combination of the variances already present in the separate individual-randomised and longitudinal-cluster formulae. This will confirm that type-I error and power for the interaction test are preserved under the standard assumptions. revision: yes
Circularity Check
No significant circularity; derivation combines external standard results
full rationale
The paper's central claim is that power calculations for the split-plot factorial longitudinal cluster design follow from combining existing formulas for individually randomised trials and longitudinal cluster randomised trials. No load-bearing step reduces to a self-citation chain, fitted parameter renamed as prediction, or self-definitional loop within the manuscript. The derivation treats the multilevel factorial structure as separable into known components once the design is specified, with the abstract explicitly stating dependence on 'standard results' from prior literature rather than internal fits or author-specific uniqueness theorems. This is the most common honest non-finding for papers that extend methodology by composition of established results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Continuous outcomes follow linear mixed models with random effects capturing clustering and longitudinal correlation.
- ad hoc to paper The factorial multilevel structure does not introduce new variance components beyond those in the separate individual and cluster designs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show how the power to detect given effects ... depends on standard results for individually-randomised trials and longitudinal cluster randomised trials.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
var(ˆβI) = (1−ρCT) / (m T σZ² (1−πX)) · σ²/n
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Analysis of variance, design, and regression: Linear modeling for unbalanced data
Ronald Christensen. Analysis of variance, design, and regression: Linear modeling for unbalanced data. Chapman and Hall/CRC, 2018
work page 2018
-
[2]
John J Dziak, Inbal Nahum-Shani, and Linda M Collins. Multilevel factorial ex- periments for developing behavioral interventions: power, sample size, and resource considerations. Psychological methods, 17(2):153, 2012
work page 2012
-
[3]
Sarah T Hawley, Kelley Kidwell, David Zahrieh, Anne McCarthy, Rachel Wills, Aaron Rankin, Timothy Hofer, Selina Chow, Reshma Jagsi, and Heather Neuman. 25 Improving patient-centered communication in breast cancer: a study protocol for a multilevel intervention of a shared treatment deliberation system (shares) within the nci community oncology research pr...
work page 2023
- [4]
-
[5]
Jessica Kasza, Rhys Bowden, Yongdong Ouyang, Monica Taljaard, and Andrew B Forbes. Does it decay? obtaining decaying correlation parameter values from pre- viously analysed cluster randomised trials. Statistical Methods in Medical Research, 32(11):2123–2134, 2023
work page 2023
-
[6]
Cluster randomized controlled trial of a multilevel physical activity intervention for older adults
Jacqueline Kerr, Dori Rosenberg, Rachel A Millstein, Khalisa Bolling, Katie Crist, Michelle Takemoto, Suneeta Godbole, Kevin Moran, Loki Natarajan, Cynthia Castro-Sweet, et al. Cluster randomized controlled trial of a multilevel physical activity intervention for older adults. International Journal of Behavioral Nutrition and Physical Activity, 15:1–9, 2018
work page 2018
-
[7]
Walking the talk on multi-level interventions: the power of parsimony
Colleen M McBride, Hannah LF Cooper, David R Williams, and Karen M Emmons. Walking the talk on multi-level interventions: the power of parsimony. Social Sci- ence & Medicine, 283:114189, 2021
work page 2021
-
[8]
Noreen D Mdege, Sally Brabyn, Catherine Hewitt, Rachel Richardson, and David J Torgerson. The 2 × 2 cluster randomized controlled factorial trial design is mainly used for efficiency and to explore intervention interactions: a systematic review. Journal of Clinical Epidemiology , 67(10):1083–1092, 2014
work page 2014
-
[9]
A modern theory of factorial design
Rahul Mukerjee and CF Jeff Wu. A modern theory of factorial design . Springer Science & Business Media, 2007
work page 2007
-
[10]
Multilevel factorial designs in intervention development
Inbal Nahum-Shani and John J Dziak. Multilevel factorial designs in intervention development. Optimization of behavioral, biobehavioral, and biomedical interven- tions: Advanced topics , pages 47–87, 2018
work page 2018
-
[11]
Lila J Finney Rutten, Joan M Griffin, Jennifer L St Sauver, Kathy MacLaughlin, Jessica D Austin, Gregory Jenkins, Jeph Herrin, and Robert M Jacobson. Multilevel implementation strategies for adolescent human papillomavirus vaccine uptake: a cluster randomized clinical trial. JAMA pediatrics, 178(1):29–36, 2024
work page 2024
-
[12]
Multi- level intervention stepped wedge designs (mli-swds)
John Sperger, Michael R Kosorok, Laura Linnan, and Shawn M Kneipp. Multi- level intervention stepped wedge designs (mli-swds). Prevention Science, 25(Suppl 3):371–383, 2024
work page 2024
-
[13]
Sample size calculation in hierarchical 2 × 2 factorial trials with unequal cluster sizes
Zizhong Tian, Denise Esserman, Guangyu Tong, Ondrej Blaha, James Dziura, Peter Peduzzi, and Fan Li. Sample size calculation in hierarchical 2 × 2 factorial trials with unequal cluster sizes. Statistics in medicine , 41(4):645–664, 2022. 26
work page 2022
-
[14]
Learning from a factorial stepped-wedge cluster randomised controlled trial in primary care
BAM Van der Geest and JV Been. Learning from a factorial stepped-wedge cluster randomised controlled trial in primary care. Neonatal hyperbilirubinaemia, page 127, 2020. 27
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.