Decoding species coexistence: A reinforcement learning perspective
Pith reviewed 2026-05-21 23:30 UTC · model grok-4.3
The pith
In a spatial rock-paper-scissors model, mobility adaptively regulated by reinforcement learning allows all three species to coexist stably across broad migration rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
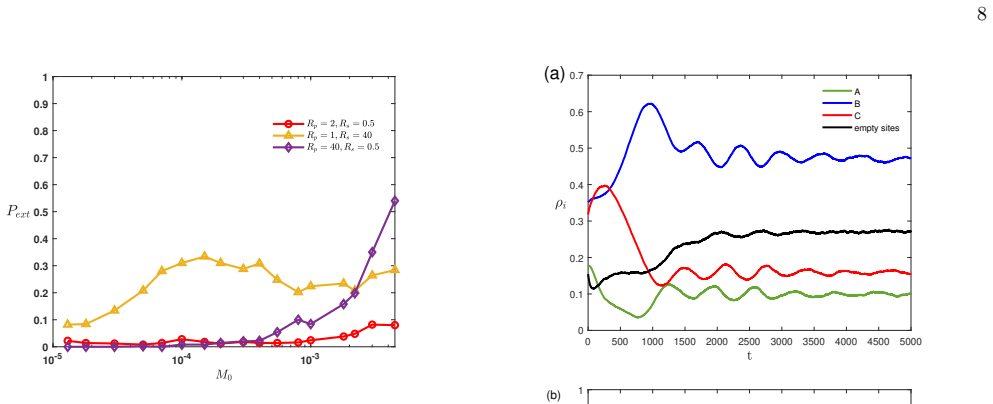
When mobility is adaptively regulated via a Q-learning algorithm in a spatial RPS model, all three species coexist stably with low extinction probabilities across a broad range of baseline migration rates. Individuals develop survival priority by escaping predators and predation priority by remaining near prey. Coexistence arises from the balance of these tendencies; imbalance jeopardizes biodiversity. A symmetry-breaking of action preference in a particular state accounts for divergent species densities. Q-learning species show a significant evolutionary advantage when interacting with fixed-mobility counterparts.
What carries the argument
Q-learning algorithm that adaptively regulates individual mobility based on local predator-prey encounters.
If this is right
- Coexistence remains stable over wide migration rates because learned behaviors balance escape and pursuit.
- Imbalance between survival priority and predation priority drives biodiversity loss.
- Symmetry-breaking in action preference in one state produces unequal species densities.
- Adaptive-mobility species outcompete fixed-mobility species in direct interactions.
Where Pith is reading between the lines
- Natural populations may evolve learning rules for movement that promote long-term diversity in competitive settings.
- The approach could be tested in other cyclic competition models to check whether adaptive regulation generally supports coexistence.
- Conservation planning might prioritize habitat features that enable behavioral adjustment over simply restricting overall movement.
Load-bearing premise
The Q-learning process accurately represents how real organisms adjust mobility in response to local predator-prey encounters.
What would settle it
Direct observation or measurement of movement rates in natural three-species cyclic systems showing whether individuals increase movement away from predators and toward prey in proportions matching the model's learned action preferences at high mobility.
Figures









read the original abstract
A central goal in ecology is to understand how biodiversity is maintained. Previous theoretical works have employed the rock-paper-scissors (RPS) game as a toy model, demonstrating that population mobility is crucial in determining the species' coexistence. One key prediction is that biodiversity is jeopardized and eventually lost when mobility exceeds a certain value--a conclusion at odds with empirical observations of highly mobile species coexisting in nature. To address this discrepancy, we introduce a reinforcement learning framework and study a spatial RPS model, where individual mobility is adaptively regulated via a Q-learning algorithm rather than held fixed. Our results show that all three species can coexist stably, with extinction probabilities remaining low across a broad range of baseline migration rates. Mechanistic analysis reveals that individuals develop two behavioral tendencies: survival priority (escaping from predators) and predation priority (remaining near prey). While species coexistence emerges from the balance of the two tendencies, their imbalance jeopardizes biodiversity. Notably, there is a symmetry-breaking of action preference in a particular state that is responsible for the divergent species densities. Furthermore, when Q-learning species interact with fixed-mobility counterparts, those with adaptive mobility exhibit a significant evolutionary advantage. Our study suggests that reinforcement learning may offer a promising new perspective for uncovering the mechanisms of biodiversity and informing conservation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a reinforcement learning (Q-learning) framework to model adaptive individual mobility in a spatial rock-paper-scissors (RPS) ecological model. Unlike fixed-mobility versions where high mobility leads to biodiversity loss, the adaptive model allows stable coexistence of all three species, with low extinction probabilities maintained across a broad range of baseline migration rates. Mechanistic analysis identifies survival-priority and predation-priority behaviors, symmetry-breaking in action preferences that drives density differences, and an evolutionary advantage for Q-learning agents when competing against fixed-mobility counterparts.
Significance. If the reported simulation outcomes are robust, the work provides a novel mechanistic perspective on biodiversity maintenance that reconciles theoretical mobility thresholds with empirical observations of highly mobile coexisting species. The integration of reinforcement learning to derive adaptive behavioral rules from local interactions is a clear strength and could inform future agent-based ecological models and conservation applications.
major comments (2)
- [Results / Simulation protocol] The central claim that extinction probabilities remain low for all three species across a broad range of baseline migration rates rests on the simulation protocol correctly sampling the tail of the extinction-time distribution. The abstract and available description supply no information on the number of independent Monte Carlo replicates, total run length, burn-in period, or convergence diagnostics for the probability estimates; if these are modest or short relative to typical extinction timescales at high mobility, rare extinctions could be missed, undermining the stability conclusion (see skeptic note on underpowered estimates).
- [Methods / Q-learning details] The Q-learning implementation introduces free parameters (learning rate and exploration parameter) whose specific values and sensitivity are not reported. Because the coexistence result is obtained from agent-based simulations rather than an algebraic reduction, it is necessary to demonstrate that the low-extinction outcome is not an artifact of particular hyperparameter choices or post-hoc tuning.
minor comments (2)
- Clarify the precise mapping between the 'baseline migration rate' parameter and the adaptive mobility output of the Q-learning algorithm; this notation is used in the abstract but its operational definition is unclear from the summary.
- Add error bars, confidence intervals, or replicate variability to any figures reporting extinction probabilities or species densities to allow visual assessment of robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below and have revised the manuscript to incorporate additional details on simulation protocols and Q-learning hyperparameters, along with supporting analyses to strengthen the robustness claims.
read point-by-point responses
-
Referee: [Results / Simulation protocol] The central claim that extinction probabilities remain low for all three species across a broad range of baseline migration rates rests on the simulation protocol correctly sampling the tail of the extinction-time distribution. The abstract and available description supply no information on the number of independent Monte Carlo replicates, total run length, burn-in period, or convergence diagnostics for the probability estimates; if these are modest or short relative to typical extinction timescales at high mobility, rare extinctions could be missed, undermining the stability conclusion (see skeptic note on underpowered estimates).
Authors: We agree that explicit reporting of the simulation protocol is necessary for assessing the reliability of the extinction probability estimates. In the revised manuscript, we will add a new subsection in the Methods section specifying the number of independent Monte Carlo replicates (1000 per parameter combination), total simulation length (10^6 time steps after a 10^5-step burn-in), and convergence checks (monitoring stabilization of species densities and extinction event counts). These parameters were chosen to exceed typical extinction timescales observed in fixed-mobility controls, ensuring adequate sampling of rare events. We will also include supplementary figures showing cumulative extinction probability convergence over replicate count. revision: yes
-
Referee: [Methods / Q-learning details] The Q-learning implementation introduces free parameters (learning rate and exploration parameter) whose specific values and sensitivity are not reported. Because the coexistence result is obtained from agent-based simulations rather than an algebraic reduction, it is necessary to demonstrate that the low-extinction outcome is not an artifact of particular hyperparameter choices or post-hoc tuning.
Authors: We acknowledge the importance of demonstrating robustness to hyperparameter choices. The revised manuscript will explicitly report the values used (learning rate α = 0.1, exploration rate ε = 0.05 with linear decay) in the Methods. We will add a new supplementary section with sensitivity analyses varying α from 0.01 to 0.5 and ε from 0.01 to 0.2, showing that stable coexistence with low extinction probabilities persists across this range. These results confirm that the reported outcomes are not sensitive to specific tuning. revision: yes
Circularity Check
No circularity: coexistence claims arise from independent agent-based RL simulations
full rationale
The paper's central results on stable coexistence and low extinction probabilities are generated by running Q-learning agents in a spatial RPS lattice model. No algebraic derivation chain is presented that reduces the reported outcomes to fitted parameters, self-definitions, or prior self-citations. The adaptive mobility behaviors and symmetry-breaking are observed outputs of the simulation protocol rather than inputs renamed as predictions. The work is self-contained against external benchmarks because the RL update rules and mobility adaptation are defined independently of the final extinction statistics.
Axiom & Free-Parameter Ledger
free parameters (2)
- Q-learning rate
- exploration parameter
axioms (1)
- domain assumption Species interactions follow cyclic dominance on a spatial lattice with local movement decisions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
individuals develop two behavioral tendencies: survival priority (escaping from predators) and predation priority (remaining near prey)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Q-learning algorithm on a spatial RPS model; individuals belonging to the same species are guided by a common Q-table
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A brief review of evolutionary game dynamics in the reinforcement learning paradigm
A review synthesizing how reinforcement learning in evolutionary games provides a unified framework for social and ecological phenomena beyond traditional imitation models.
Reference graph
Works this paper leans on
-
[1]
Each site of the lattice is randomly occupied by an individual of A, B, C, or left empty. Initialize all the items of the three Q-tables with random num- bers Qs,a ∈ (0, 1) independently to mimic the un- awareness of individuals to the surroundings. Each player i takes a random migration rate withai ∈ A
-
[2]
Their states also need to be updated
In the learning process, each agent’s action is made by pure exploration ai ∈ A ; afterwards, their re- wards are obtained by collecting payoffs, and then they update their Q-tables to accumulate their ex- perience. Their states also need to be updated
-
[3]
After the three Q-tables are converged, the game process starts. Their migration is then strictly guided by the corresponding Q-table belonging to their species, and the three Q-tables are no longer revised. Repeat step 2 till the convergence of three Q-tables, which completes the learning process. Repeat step 3 un- til the system reaches a statistically ...
-
[4]
M. E. Assessment, Ecosystems and human well-being: current state and trends: findings of the Condition and Trends Working Group (Island press, 2005)
work page 2005
-
[5]
Darwin, On the origin of species, 1859 (Routledge London, UK:, 2004)
C. Darwin, On the origin of species, 1859 (Routledge London, UK:, 2004)
work page 2004
- [6]
-
[7]
Government, The Economics of Biodiversity: The Dasgupta Review (UK Government, 2021)
U. Government, The Economics of Biodiversity: The Dasgupta Review (UK Government, 2021)
work page 2021
- [8]
-
[9]
J. D. Murray, Mathematical biology: I. An introduction 3rd ed. , Vol. 17 (Springer Science & Business Media, 2013)
work page 2013
-
[10]
C. L. Lehman and D. Tilman, Spatial ecology: the role of space in population dynamics and interspecific inter- actions 185, 191 (1997)
work page 1997
-
[11]
A. J. McLane, C. Semeniuk, G. J. McDermid, and D. J. Marceau, Ecological modelling 222, 1544 (2011)
work page 2011
-
[12]
J. M. Smith, Evolution and the Theory of Games (Cam- bridge Univ. Press, 1982)
work page 1982
-
[13]
J. Hofbauer and K. Sigmund, Evolutionary Games and Population Dynamics (Cambridge University Press, Cambridge, 1998)
work page 1998
-
[14]
M. A. Nowak, Evolutionary Dynamics (Belknap Press, Cambridge, MA, 2006)
work page 2006
-
[15]
R. Durrett and S. Levin, Journal of Theoretical Biology 185, 165 (1997)
work page 1997
- [16]
-
[17]
B. Kerr, C. Neuhauser, B. J. M. Bohannan, and A. M. Dean, Nature 418, 171 (2002)
work page 2002
-
[19]
R. M. May and W. J. Leonard, SIAM Journal on Applied Mathematics 29, 243 (1975)
work page 1975
-
[20]
C. R. Johnson and I. Seinen, Proceedings of the Royal Society of London. Series B: Biological Sciences 269, 655 (2002)
work page 2002
-
[21]
T. Reichenbach, M. Mobilia, and E. Frey, Physical Re- view E 74, 051907 (2006)
work page 2006
- [22]
-
[23]
A. Szolnoki, M. Mobilia, L.-L. Jiang, B. Szczesny, A. M. Rucklidge, and M. Perc, Journal of the Royal Society Interface 11, 20140735 (2014)
work page 2014
-
[24]
Zhou, Contemporary Physics 57, 151 (2016)
H.-J. Zhou, Contemporary Physics 57, 151 (2016)
work page 2016
- [25]
-
[26]
C. E. Paquin and J. Adams, Nature 306, 368 (1983)
work page 1983
-
[27]
J. Jackson and L. Buss, Proceedings of the National Academy of Sciences 72, 5160 (1975)
work page 1975
-
[28]
T. L. Cz´ ar´ an, R. F. Hoekstra, and L. Pagie, Proceedings of the National Academy of Sciences 99, 786 (2002)
work page 2002
- [29]
- [30]
-
[31]
W.-X. Wang, Y.-C. Lai, and C. Grebogi, Physical Re- view E 81, 046113 (2010)
work page 2010
-
[32]
W.-X. Wang, X. Ni, Y.-C. Lai, and C. Grebogi, Physical Review E 83, 011917 (2011)
work page 2011
-
[33]
J. Park, Y. Do, Z. Huang, and Y. Lai, Chaos 23, 023128 (2013)
work page 2013
- [34]
-
[35]
H.-W. Lee, C. Cleveland, and A. Szolnoki, Chaos 32, 093103 (2022)
work page 2022
- [36]
-
[37]
J. Park and B. Jang, Journal of the Korean Society for Industrial and Applied Mathematics 24, 351 (2020)
work page 2020
-
[38]
J. Park, EPL 126, 38004 (2019). 11 Algorithm 1: RPS model with Q-learning Input: α, γ Initialization; Q1, Q2, Q3 ← random(15 × 7); Lattice point ← random[0, 3]L×L; σ, µ ← 1; Nstep ← 10; Learning Process; repeat for each round t do for Each agent do Agent picks a random action a ∈ A; for interaction count = 1 to Nstep × L2 do Randomly select an agent and i...
work page 2019
-
[39]
Z. Ding, G. Zheng, C. Cai, W. Cai, L. Chen, J. Zhang, and X. Wang, Chaos, Solitons & Fractals 175, 114032 (2023)
work page 2023
- [40]
- [41]
- [42]
- [43]
- [44]
- [45]
-
[46]
M. M. Olsen and R. Fraczkowski, Journal of Computa- tional Science 9, 118 (2015). (a) 0 500 1000 1500 2000 2500 3000 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 A B C empty sites (b) FIG. 10: Evolution in predation dominance scenarios. The typical pattern (a) and time series (b) in the predation dominance scenario with Rp = 40 and Rs = 0.5. Parameters: N...
work page 2015
-
[47]
X. Wang, J. Cheng, and L. Wang, Entropy 21, 773 (2019)
work page 2019
-
[48]
X. Wang, J. Cheng, and L. Wang, Ecological Complexity 42, 100815 (2020)
work page 2020
-
[49]
J. Park, J. Lee, T. Kim, I. Ahn, and J. Park, Entropy 23, 461 (2021)
work page 2021
-
[50]
J. Li, L. Li, and S. Zhao, New Journal of Physics 25, 092001 (2023)
work page 2023
- [51]
- [52]
-
[53]
T. Reichenbach, M. Mobilia, and E. Frey, Journal of Theoretical Biology 254, 368 (2008)
work page 2008
-
[54]
C. J. C. H. Watkins and P. Dayan, Machine Learning 8, 279 (1992)
work page 1992
-
[55]
R. Sutton and A. Barto, Reinforcement Learning:An In- troduction (MIT press, 2018)
work page 2018
-
[56]
J. E. R. Staddon, Adaptive behavior and learning (Cam- bridge University Press, 1983)
work page 1983
-
[57]
A. J. Underwood, Experiments in ecology: their logi- cal design and interpretation using analysis of variance (Cambridge university press, 1997)
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.