DeepASA: An Object-Oriented Multi-Purpose Network for Auditory Scene Analysis
Pith reviewed 2026-05-18 14:23 UTC · model grok-4.3
The pith
A single network can handle source separation, detection, classification and localization of sounds in complex overlapping scenes by using object-centric representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
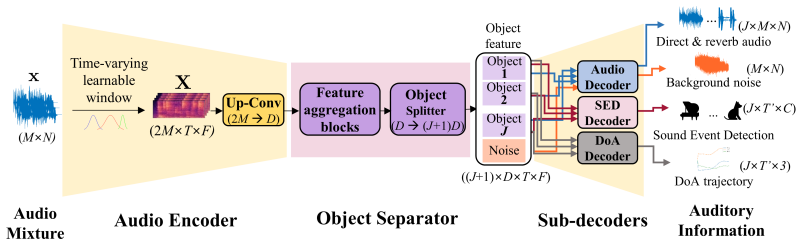
The central discovery is that an object-oriented processing pipeline, consisting of a dynamic temporal kernel feature extractor, transformer aggregator, and object separator, produces per-object features that multiple task decoders can use effectively when combined with temporal coherence matching in the chain-of-inference for iterative refinement and multi-task fusion.
What carries the argument
Object-oriented processing strategy that creates per-object features refined through chain-of-inference with temporal coherence matching to support consistent multi-task outputs.
If this is right
- Naturally resolves parameter association ambiguity in track-wise processing.
- Supports MIMO source separation and dereverberation along with parameter estimation tasks.
- Delivers state-of-the-art performance on ASA2, MC-FUSS, and STARSS23 datasets.
- Handles diverse spatial scenes with dynamically moving similar sources.
Where Pith is reading between the lines
- This suggests object-centric methods could be extended to reduce errors in highly reverberant environments.
- The unified framework might lower the barrier for deploying auditory scene analysis in resource-constrained devices by sharing computations.
- Similar approaches could be explored for video or multimodal scene analysis where objects need consistent tracking across tasks.
Load-bearing premise
The temporal coherence matching mechanism can reliably correct failures from the early object separation stage to ensure accurate outputs from the downstream task decoders.
What would settle it
Observing whether the model's performance on sound event detection or direction estimation remains high even when the initial separation step produces errors on a test set with closely similar sources would confirm or refute the effectiveness of the refinement process.
Figures











read the original abstract
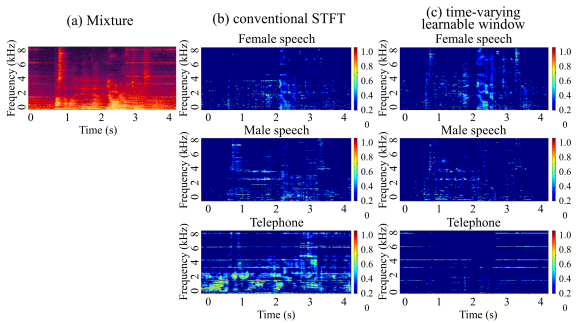
We propose DeepASA, a multi-purpose model for auditory scene analysis that performs multi-input multi-output (MIMO) source separation, dereverberation, sound event detection (SED), audio classification, and direction-of-arrival estimation (DoAE) within a unified framework. DeepASA is designed for complex auditory scenes where multiple, often similar, sound sources overlap in time and move dynamically in space. To achieve robust and consistent inference across tasks, we introduce an object-oriented processing (OOP) strategy. This approach encapsulates diverse auditory features into object-centric representations and refines them through a chain-of-inference (CoI) mechanism. The pipeline comprises a dynamic temporal kernel-based feature extractor, a transformer-based aggregator, and an object separator that yields per-object features. These features feed into multiple task-specific decoders. Our object-centric representations naturally resolve the parameter association ambiguity inherent in traditional track-wise processing. However, early-stage object separation can lead to failure in downstream ASA tasks. To address this, we implement temporal coherence matching (TCM) within the chain-of-inference, enabling multi-task fusion and iterative refinement of object features using estimated auditory parameters. We evaluate DeepASA on representative spatial audio benchmark datasets, including ASA2, MC-FUSS, and STARSS23. Experimental results show that our model achieves state-of-the-art performance across all evaluated tasks, demonstrating its effectiveness in both source separation and auditory parameter estimation under diverse spatial auditory scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeepASA, a unified multi-input multi-output neural network for auditory scene analysis that jointly performs source separation, dereverberation, sound event detection, audio classification, and direction-of-arrival estimation. It introduces an object-oriented processing strategy that produces per-object features via a dynamic temporal kernel extractor, transformer aggregator, and object separator; these features are refined by a chain-of-inference mechanism that includes temporal coherence matching (TCM) to mitigate error propagation from early separation stages and to resolve parameter association ambiguities. The model is evaluated on the ASA2, MC-FUSS, and STARSS23 benchmarks and claims state-of-the-art performance across all tasks.
Significance. If the results hold, the work offers a potentially useful unified framework for spatial auditory scene analysis that addresses the association problem through object-centric representations rather than track-wise processing. The multi-task fusion via TCM is presented as a corrective mechanism for imperfect early separation, which could improve robustness in dynamic scenes. Evaluation on three public benchmarks provides a broad test of the multi-purpose claim; however, the absence of component-specific ablations and error-propagation metrics limits attribution of gains to the novel elements.
major comments (2)
- [Abstract] Abstract: The SOTA claim across ASA2, MC-FUSS, and STARSS23 rests on the assertion that TCM corrects failures from early-stage object separation, yet the manuscript provides no ablation studies, per-stage metrics (e.g., SI-SDR or DoAE error conditioned on separation quality before vs. after TCM), or error-propagation analysis to substantiate that the chain-of-inference actually restores decoder accuracy rather than merely correlating with it.
- [Experimental Results] Experimental section: No error bars, explicit baseline comparison tables, or details on data exclusions and hyperparameter sensitivity are reported, which is required to evaluate whether the reported gains are robust or sensitive to choices that could affect the central multi-task performance claim.
minor comments (1)
- [Abstract] The abstract would benefit from inclusion of at least one quantitative result (e.g., SI-SDR or F1 improvement) rather than a purely qualitative SOTA statement.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address each of the major comments below, providing clarifications and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA claim across ASA2, MC-FUSS, and STARSS23 rests on the assertion that TCM corrects failures from early-stage object separation, yet the manuscript provides no ablation studies, per-stage metrics (e.g., SI-SDR or DoAE error conditioned on separation quality before vs. after TCM), or error-propagation analysis to substantiate that the chain-of-inference actually restores decoder accuracy rather than merely correlating with it.
Authors: We agree that additional analyses would help substantiate the specific contribution of the temporal coherence matching (TCM) within the chain-of-inference. While the overall state-of-the-art results on the benchmarks demonstrate the effectiveness of the full DeepASA pipeline, we acknowledge the value of isolating the impact of TCM. In the revised manuscript, we will include ablation studies comparing the model with and without TCM, as well as per-stage performance metrics to illustrate error propagation and correction. revision: yes
-
Referee: [Experimental Results] Experimental section: No error bars, explicit baseline comparison tables, or details on data exclusions and hyperparameter sensitivity are reported, which is required to evaluate whether the reported gains are robust or sensitive to choices that could affect the central multi-task performance claim.
Authors: We appreciate this observation. To enhance the robustness and reproducibility of our experimental results, we will add error bars to the reported metrics in the revised version. We will also include more explicit baseline comparison tables and provide additional details on data exclusions, preprocessing steps, and hyperparameter selection and sensitivity analysis. revision: yes
Circularity Check
No circularity: empirical multi-task network evaluated on external benchmarks
full rationale
The paper presents an empirical neural architecture (DeepASA) with object-oriented processing, chain-of-inference, and temporal coherence matching, trained end-to-end and evaluated on public benchmarks ASA2, MC-FUSS, and STARSS23. No equations, parameters, or first-principles derivations are shown that reduce reported metrics or outputs to quantities defined by the authors' own fitted values or self-citations. Performance claims rest on direct comparison to prior art on independent test sets, rendering the evaluation self-contained with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and hyperparameters
axioms (1)
- domain assumption Object-centric representations naturally resolve parameter association ambiguity inherent in traditional track-wise processing.
invented entities (2)
-
Object-oriented processing (OOP) strategy
no independent evidence
-
Temporal coherence matching (TCM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
temporal coherence matching (TCM) within the chain-of-inference, enabling multi-task fusion and iterative refinement of object features using estimated auditory parameters
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
object separator that yields per-object features
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. S. Bregman. Auditory scene analysis. InProceedings of the 7th International Conference on Pattern Recognition. Citeseer, 1984
work page 1984
-
[2]
G. J. Brown and M. Cooke. Computational auditory scene analysis.Computer Speech & Language, 1994
work page 1994
-
[3]
E. C. Cherry. Some experiments on the recognition of speech, with one and with two ears. Journal of the acoustical society of America, 1953
work page 1953
-
[4]
A. S. Bregman.Auditory scene analysis: The perceptual organization of sound. MIT press, 1994
work page 1994
-
[5]
S., Mounya E., and Christophe M
Shihab A. S., Mounya E., and Christophe M. Temporal coherence and attention in auditory scene analysis.Trends in Neurosciences, 2011
work page 2011
-
[6]
D-L. Wang and G. J. Brown.Computational auditory scene analysis: Principles, algorithms, and applications. Wiley-IEEE press, 2006
work page 2006
-
[7]
Q. Kong, Y . Xu, W. Wang, and M. D Plumbley. A joint detection-classification model for audio tagging of weakly labelled data. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2017
work page 2017
- [8]
- [9]
-
[10]
A. Mesaros, T. Heittola, T. Virtanen, and M. D. Plumbley. Sound event detection: A tutorial. IEEE Signal Processing Magazine, 2021
work page 2021
- [11]
-
[12]
N. Shao, X. Li, and X. Li. Fine-tune the pretrained ATST model for sound event detection. In IEEE International Conference on Acoustics, Speech and Signal Processing, 2024
work page 2024
-
[13]
P-A. Grumiaux, Sr ¯dan Kiti´c, L. Girin, and A. Guérin. A survey of sound source localization with deep learning methods.The Journal of the Acoustical Society of America, 2022
work page 2022
-
[14]
D. Diaz-Guerra, A. Miguel, and J. R. Beltran. Robust sound source tracking using SRP- PHAT and 3D convolutional neural networks.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020
work page 2020
-
[15]
Y . Wang, B. Yang, and X. Li. FN-SSL: Full-band and narrow-band fusion for sound source localization
-
[16]
D-L. Wang and J. Chen. Supervised speech separation based on deep learning: An overview. IEEE/ACM transactions on audio, speech, and language processing, 2018. 10
work page 2018
- [17]
-
[18]
I. Kavalerov, S. Wisdom, H. Erdogan, B. Patton, K. Wilson, J. Le Roux, and J. R. Hershey. Universal sound separation. InIEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019
work page 2019
-
[19]
He.Deep Learning Approaches for Auditory Perception in Robotics
W. He.Deep Learning Approaches for Auditory Perception in Robotics. PhD thesis, EPFL, 2021
work page 2021
- [20]
-
[21]
Marc Delcroix, Jorge Bennasar Vázquez, Tsubasa Ochiai, Keisuke Kinoshita, Yasunori Ohishi, and Shoko Araki. SoundBeam: Target sound extraction conditioned on sound-class labels and enrollment clues for increased performance and continuous learning.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022
work page 2022
-
[22]
H. Wang, D. Yang, C. Weng, J. Yu, and Y . Zou. Improving target sound extraction with timestamp information. 2022
work page 2022
-
[23]
M-S. Kim, D.and Baek, Y . Kim, and J-H. Chang. Improving target sound extraction with timestamp knowledge distillation. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2024
work page 2024
-
[24]
T. Jenrungrot, V . Jayaram, S. Seitz, and I. Kemelmacher-Shlizerman. The cone of silence: Speech separation by localization.Advances in Neural Information Processing Systems, 2020
work page 2020
- [25]
- [26]
-
[27]
K. Zmolikova, M. Delcroix, T. Ochiai, K. Kinoshita, J. ˇCernock`y, and D. Yu. Neural target speech extraction: An overview.IEEE Signal Processing Magazine, 2023
work page 2023
-
[28]
S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks.IEEE Journal of Selected Topics in Signal Processing, 2018
work page 2018
-
[29]
Y . He, N. Trigoni, and A. Markham. SoundDet: Polyphonic moving sound event detection and localization from raw waveform. InInternational Conference on Machine Learning, 2021
work page 2021
- [30]
- [31]
-
[32]
K. Shimada, A. Politis, P. Sudarsanam, D. A. Krause, K. Uchida, S. Adavanne, A. Hakala, Y . Koyama, N. Takahashi, S. Takahashi, et al. STARSS23: An audio-visual dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events.Advances in neural information processing systems, 2023
work page 2023
-
[33]
T. N. T. Nguyen, K. N. Watcharasupat, N. K. Nguyen, D. L. Jones, and W-S. Gan. SALSA: Spatial cue-augmented log-spectrogram features for polyphonic sound event localization and detection.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022. 11
work page 2022
-
[34]
Y . Shul and J-W. Choi. CST-former: Transformer with channel-spectro-temporal attention for sound event localization and detection. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2024
work page 2024
-
[35]
L. Xue, H. Liu, and Y . Zhou. Attention mechanism network and data augmentation for sound event localization and detection. Technical report, DCASE2023 Challenge, June 2023
work page 2023
-
[36]
J. Hu, Y . Cao, M. Wu, F. Yang, W. Wang, M. D. Plumbley, and J. Yang. A data generation method for sound event localization and detection in real spatial sound scenes. Technical report, DCASE2023 Challenge, June 2023
work page 2023
-
[37]
Q. Wang, Y . Jiang, S. Cheng, M. Hu, Z. Nian, P. Hu, Z. Liu, Y . Dong, M. Cai, J. Du, and C-H. Lee. The NERC-SLIP system for sound event localization and detection of DCASE2023 challenge. Technical report, DCASE2023 Challenge, June 2023
work page 2023
-
[38]
D. Lee and J-W. Choi. DeFT-Mamba: Universal multichannel sound separation and polyphonic audio classification. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2025
work page 2025
-
[39]
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter. Audio set: An ontology and human-labeled dataset for audio events. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2017
work page 2017
-
[40]
Attentive Statistics Pooling for Deep Speaker Embedding
K. Okabe, T. Koshinaka, and K. Shinoda. Attentive statistics pooling for deep speaker embed- ding.arXiv preprint arXiv:1803.10963, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [41]
-
[42]
I. R Roman, C. Ick, S. Ding, A. S. Roman, B. McFee, and J. P. Bello. Spatial scaper: a library to simulate and augment soundscapes for sound event localization and detection in realistic rooms. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2024
work page 2024
-
[43]
T. von Neumann, K. Kinoshita, C. Boeddeker, M. Delcroix, and R. Haeb-Umbach. SA-SDR: A novel loss function for separation of meeting style data. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2022
work page 2022
-
[44]
J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey. SDR–half-baked or well done? In IEEE International Conference on Acoustics, Speech and Signal Processing, 2019
work page 2019
- [45]
-
[46]
Z-Q. Wang, S. Cornell, S. Choi, Y . Lee, B-Y . Kim, and S. Watanabe. TF-GridNet: Integrating full-and sub-band modeling for speech separation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023
work page 2023
-
[47]
D. Lee and J-W. Choi. DeFTAN-II: Efficient multichannel speech enhancement with subgroup processing.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
work page 2024
-
[48]
C. Quan and X. Li. SpatialNet: Extensively learning spatial information for multichannel joint speech separation, denoising and dereverberation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
work page 2024
- [49]
- [50]
-
[51]
K. Shimada, N. Takahashi, Y . Koyama, S. Takahashi, E. Tsunoo, M. Takahashi, and Y . Mitsu- fuji. Ensemble of ACCDOA-and EINV2-based systems with D3Nets and impulse response simulation for sound event localization and detection.arXiv preprint arXiv:2106.10806, 2021
-
[52]
Y . Cao, T. Iqbal, Q. Kong, F. An, W. Wang, and M. D. Plumbley. An improved event-independent network for polyphonic sound event localization and detection. InIEEE International Confer- ence on Acoustics, Speech and Signal Processing, 2021
work page 2021
-
[53]
Q. T. V o and D. K. Han. Resnet-conformer network with shared weights and attention mecha- nism for sound event localization, detection, and distance estimation. Technical report, Technical report, DCASE2024 Challenge, 2024
work page 2024
- [54]
- [55]
-
[56]
S-H. Kim, H. Nam, and Y-H. Park. Temporal dynamic convolutional neural network for text- independent speaker verification and phonemic analysis. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 6742–6746. IEEE, 2022
work page 2022
-
[57]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InIEEE International Conference on Computer Vision, pages 618–626, 2017
work page 2017
-
[58]
S. Niu, J. Du, Q. Wang, L. Chai, H. Wu, Z. Nian, L. Sun, Y . Fang, J. Pan, and C-H. Lee. An experimental study on sound event localization and detection under realistic testing conditions. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2023. 13 Appendix / Technical Appendices and Supplementary Material This appendix is organiz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.