Randomness as Reference: Benchmark Metric for Optimization in Engineering
Pith reviewed 2026-05-17 20:24 UTC · model grok-4.3
The pith
A random sampling reference metric normalizes results across 235 engineering optimization problems for fair algorithm comparison.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
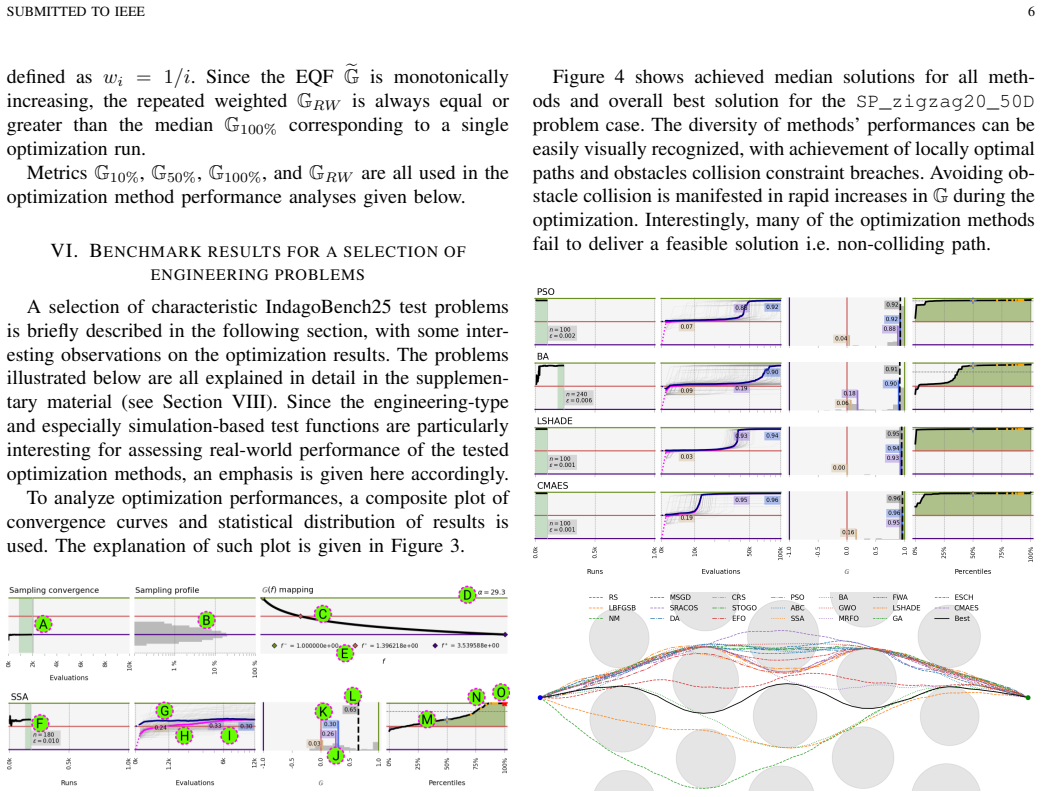
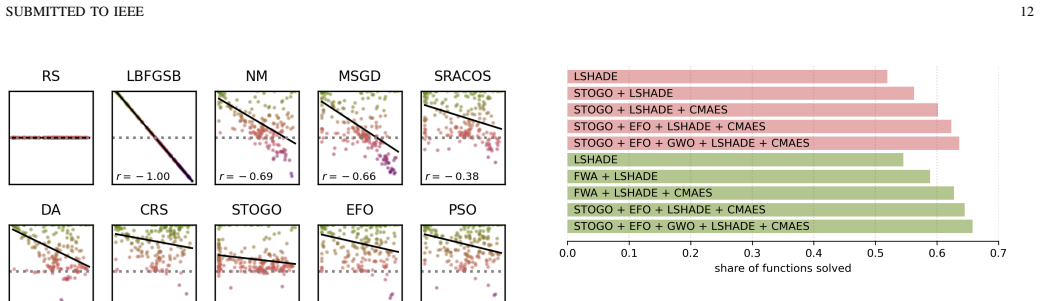
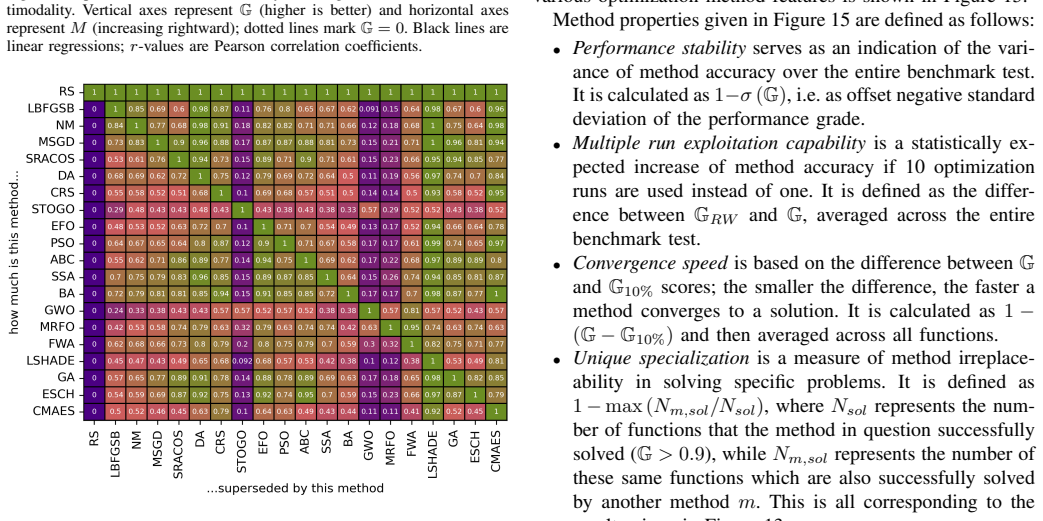
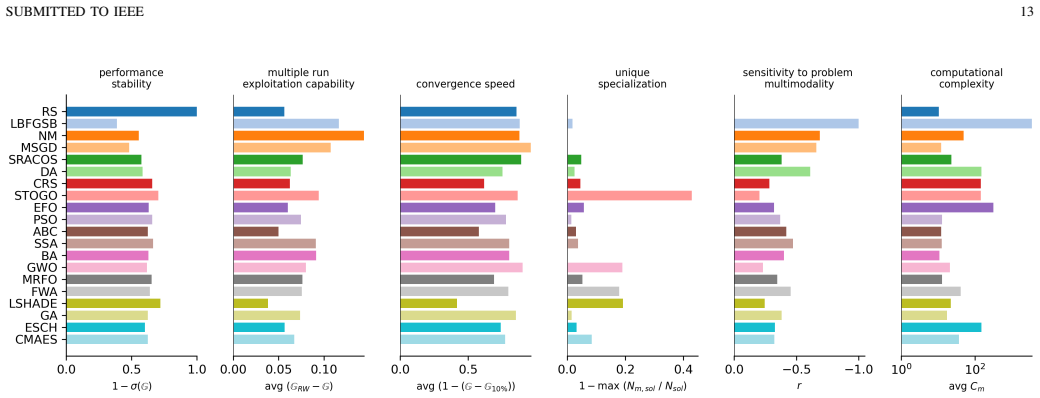
The authors establish a benchmark suite of 235 engineering-derived optimization problems and a metric that uses random sampling on each problem to create a reference distribution for nonlinear normalization of objective values. Extensive testing of 20 methods shows that only a small number achieve consistently excellent performance, whereas many commonly used metaheuristics exhibit severe efficiency loss, demonstrating the limitations of conventional benchmarks for engineering-type problems.
What carries the argument
The randomness-as-reference metric, which draws a distribution of objective values from random samples to enable nonlinear normalization and cross-problem comparison of algorithmic results on heterogeneous engineering objectives.
If this is right
- Only a few of the tested optimization methods consistently achieve excellent performance on the engineering problems.
- Several commonly used metaheuristics exhibit severe efficiency loss on these tasks.
- The evaluation yields practical guidelines for applying the methods to engineering design and simulation problems.
- The suite and metric together provide a transparent and reproducible platform for comparing optimizers on realistic applications.
Where Pith is reading between the lines
- The metric could be applied to newly proposed algorithms to identify those better matched to simulation-heavy engineering workflows.
- Extending the suite to include constrained or multi-objective variants would test whether the top performers remain robust under added realism.
- Cross-checking rankings against problems where the global optimum is known could further validate the random reference approach.
Load-bearing premise
Random sampling on each problem supplies a statistically stable and unbiased reference distribution sufficient for nonlinear normalization across heterogeneous engineering objectives.
What would settle it
Repeating the evaluation with an order-of-magnitude increase in random samples per problem and observing whether the relative performance rankings of the 20 methods stay the same would test the stability of the reference.
Figures





read the original abstract
Benchmarking optimization algorithms is fundamental for the advancement of computational intelligence. However, widely adopted artificial test suites exhibit limited correspondence with the diversity and complexity of real-world engineering optimization tasks. This paper presents a new benchmark suite comprising 235 bounded, continuous, unconstrained optimization problems, the majority derived from engineering design and simulation scenarios, including computational fluid dynamics and finite element analysis models. In conjunction with this suite, a novel performance metric is introduced, which employs random sampling as a statistical reference, providing nonlinear normalization of objective values and enabling unbiased comparison of algorithmic efficiency across heterogeneous problems. Using this framework, 20 deterministic and stochastic optimization methods were systematically evaluated through hundreds of independent runs per problem, ensuring statistical robustness. The results indicate that only a few of the tested optimization methods consistently achieve excellent performance, while several commonly used metaheuristics exhibit severe efficiency loss on engineering-type problems, emphasizing the limitations of conventional benchmarks. Furthermore, the conducted tests are used for analyzing various features of the optimization methods, providing practical guidelines for their application. The proposed test suite and metric together offer a transparent, reproducible, and practically relevant platform for evaluating and comparing optimization methods, thereby narrowing the gap between the available benchmark tests and realistic engineering applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark suite of 235 bounded continuous unconstrained optimization problems, mostly derived from engineering design, CFD, and FEA models. It proposes a novel performance metric that uses random sampling on each problem as a statistical reference to enable nonlinear normalization of objective values for cross-problem comparison. The authors evaluate 20 deterministic and stochastic optimization methods via hundreds of independent runs per problem and report that only a few methods consistently achieve excellent performance while several common metaheuristics exhibit severe efficiency loss on these engineering-type problems.
Significance. If the random-sampling reference distribution is shown to be statistically stable and representative across heterogeneous objectives, the work would offer a practically relevant alternative to artificial test suites and support reproducible guidelines for method selection in computational engineering. The emphasis on hundreds of runs per problem strengthens the statistical robustness of the reported rankings.
major comments (1)
- [Performance metric] Performance metric definition: the central claim of unbiased cross-problem comparison rests on nonlinear normalization via random sampling as reference, yet no convergence analysis, sensitivity study with respect to sample count, or demonstration of tail-behavior coverage for high-dimensional or multimodal engineering objectives is provided. This gap directly affects whether the reported distinctions between 'excellent performance' and 'severe efficiency loss' are robust.
minor comments (1)
- [Abstract] Abstract: the description of the nonlinear normalization does not specify the exact functional form or validation procedure, which would allow immediate assessment of the metric's properties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comment on the performance metric below, outlining revisions that will strengthen the statistical justification for the normalization approach.
read point-by-point responses
-
Referee: Performance metric definition: the central claim of unbiased cross-problem comparison rests on nonlinear normalization via random sampling as reference, yet no convergence analysis, sensitivity study with respect to sample count, or demonstration of tail-behavior coverage for high-dimensional or multimodal engineering objectives is provided. This gap directly affects whether the reported distinctions between 'excellent performance' and 'severe efficiency loss' are robust.
Authors: We agree that explicit analysis of the random-sampling reference would reinforce the robustness of the nonlinear normalization. The manuscript constructs the reference using a large fixed sample size (typically 10,000–100,000 points per problem, scaled with dimensionality) drawn uniformly from the bounded domain, with the resulting empirical distribution used for quantile-based normalization. To address the gap, the revised manuscript will add: (i) a convergence study plotting the normalized metric values against increasing sample counts (1,000 to 200,000) for representative problems, demonstrating stabilization; (ii) a sensitivity table showing how algorithm rankings change (or remain stable) across sample sizes; and (iii) quantile analysis of the reference tails for the subset of higher-dimensional (>10 variables) and known multimodal engineering problems in the suite. These additions will directly support the reported performance distinctions without changing the overall conclusions or methodology. revision: yes
Circularity Check
No significant circularity; random reference is independent external baseline
full rationale
The paper defines a performance metric that normalizes optimizer results against a random-sampling reference distribution generated separately on each of the 235 engineering problems. This reference is produced by direct sampling of the objective function and does not incorporate any fitted parameters, algorithm outputs, or self-citations from the authors' prior work. The subsequent evaluation of 20 methods and the claims about 'excellent performance' versus 'severe efficiency loss' are therefore downstream comparisons against this fixed external baseline rather than reductions of the metric to itself. No self-definitional equations, fitted-input predictions, load-bearing self-citations, or ansatz smuggling appear in the metric construction or result chain. The derivation remains self-contained against the independent random reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Random sampling on each problem provides a stable, unbiased reference distribution for nonlinear normalization of objective values across heterogeneous problems.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
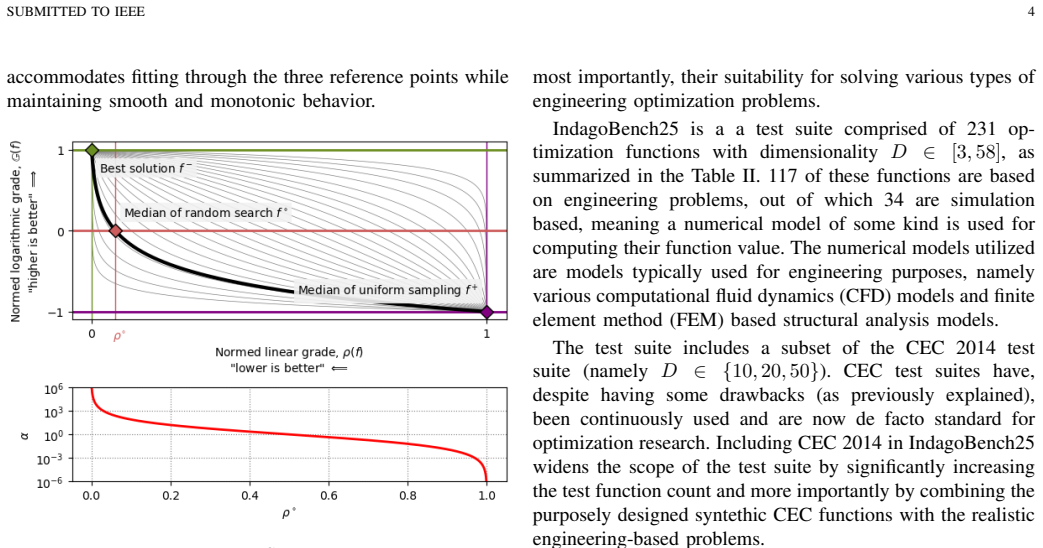
We define a metric denoted as G for nonlinear normalization based on three objectively defined reference points... G(f) = 1−2 log(ρ(f)·(α−1)+1)/log α
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The median value isoline splits the search space into two equally sized parts... Random Search (RS)... G=0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
GeoPAS: Geometric Probing for Algorithm Selection in Continuous Black-Box Optimisation
GeoPAS represents optimization problems via multi-scale 2D geometric slices fed to a validity-aware CNN that aggregates embeddings for risk-aware solver selection and log-scale performance prediction, outperforming th...
Reference graph
Works this paper leans on
-
[1]
No free lunch theorems for optimization,
D. H. Wolpert and W. G. Macready, “No free lunch theorems for optimization,”IEEE transactions on evolutionary computation, vol. 1, no. 1, pp. 67–82, 2002
work page 2002
-
[2]
A literature survey of benchmark functions for global optimisation problems,
M. Jamil and X.-S. Yang, “A literature survey of benchmark functions for global optimisation problems,”International Journal of Mathematical Modelling and Numerical Optimisation, vol. 4, no. 2, pp. 150–194, 2013
work page 2013
-
[3]
A review of benchmark and test functions for global optimization algorithms and metaheuristics,
M. Naser, M. K. Al-Bashiti, A. T. G. Tapeh, A. Naser, V . Kodur, R. Hawileh, J. Abdalla, N. Khodadadi, A. H. Gandomi, and A. D. Eslam- lou, “A review of benchmark and test functions for global optimization algorithms and metaheuristics,”Wiley Interdisciplinary Reviews: Com- putational Statistics, vol. 17, no. 2, p. e70028, 2025
work page 2025
-
[4]
A critical problem in benchmarking and analysis of evo- lutionary computation methods,
J. Kudela, “A critical problem in benchmarking and analysis of evo- lutionary computation methods,”Nature Machine Intelligence, vol. 4, no. 12, pp. 1238–1245, 2022
work page 2022
-
[5]
The evolutionary computation methods no one should use,
J. Kudela, “The evolutionary computation methods no one should use,” arXiv preprint arXiv:2301.01984, 2023
-
[6]
J. Kudela, “Commentary on:“stoa: A bio-inspired based optimization al- gorithm for industrial engineering problems”[eaai, 82 (2019), 148–174] and “tunicate swarm algorithm: A new bio-inspired based metaheuristic paradigm for global optimization”[eaai, 90 (2020), no. 103541],”En- gineering Applications of Artificial Intelligence, vol. 113, p. 104930, 2022
work page 2019
-
[7]
Salp swarm optimization: a critical review,
M. Castelli, L. Manzoni, L. Mariot, M. S. Nobile, and A. Tangherloni, “Salp swarm optimization: a critical review,”Expert Systems with Applications, vol. 189, p. 116029, 2022
work page 2022
-
[8]
Deficiencies of the whale optimization algorithm and its validation method,
L. Deng and S. Liu, “Deficiencies of the whale optimization algorithm and its validation method,”Expert Systems with Applications, vol. 237, p. 121544, 2024
work page 2024
-
[9]
Structural bias in metaheuristic algorithms: Insights, open problems, and future prospects,
K. Rajwar and K. Deep, “Structural bias in metaheuristic algorithms: Insights, open problems, and future prospects,”Swarm and Evolutionary Computation, vol. 92, p. 101812, 2025
work page 2025
-
[10]
Comparing results of 31 algorithms from the black-box optimization benchmarking bbob- 2009,
N. Hansen, A. Auger, R. Ros, S. Finck, and P. Po ˇs´ık, “Comparing results of 31 algorithms from the black-box optimization benchmarking bbob- 2009,” inProceedings of the 12th annual conference companion on Genetic and evolutionary computation, 2010, pp. 1689–1696
work page 2009
-
[11]
Real-parameter black-box optimization benchmarking 2010: Experimental setup,
N. Hansen, A. Auger, S. Finck, and R. Ros, “Real-parameter black-box optimization benchmarking 2010: Experimental setup,” Ph.D. disserta- tion, INRIA, 2010
work page 2010
-
[12]
COCO: The Large Scale Black-Box Optimization Benchmarking (bbob-largescale) Test Suite
O. Elhara, K. Varelas, D. Nguyen, T. Tusar, D. Brockhoff, N. Hansen, and A. Auger, “Coco: the large scale black-box optimization bench- marking (bbob-largescale) test suite,”arXiv preprint arXiv:1903.06396, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[13]
Coco: A platform for comparing continuous optimizers in a black-box setting,
N. Hansen, A. Auger, R. Ros, O. Mersmann, T. Tu ˇsar, and D. Brockhoff, “Coco: A platform for comparing continuous optimizers in a black-box setting,”Optimization Methods and Software, vol. 36, no. 1, pp. 114– 144, 2021
work page 2021
-
[14]
S. Das and P. N. Suganthan, “Problem definitions and evaluation criteria for cec 2011 competition on testing evolutionary algorithms on real world optimization problems,” 2011. [Online]. Available: https://api.semanticscholar.org/CorpusID:14174334
work page 2011
-
[15]
J. J. Liang, B. Qu, P. N. Suganthan, and A. G. Hern ´andez-D´ıaz, “Problem definitions and evaluation criteria for the cec 2013 special session on real-parameter optimization,”Computational Intelligence Laboratory, Zhengzhou University, Zhengzhou, China and Nanyang Technological University, Singapore, Technical Report, vol. 201212, no. 34, pp. 281– 295, 2013
work page 2013
-
[16]
N. H. Awad, M. Z. Ali, P. N. Suganthan, J. J. Lian, and B. Y . Qu, “Problem definitions and evaluation criteria for the cec 2017 special session and competition on single objective real-parameter numerical optimization,” 10 2016
work page 2017
-
[17]
A comparative study of large-scale variants of cma-es,
K. Varelas, A. Auger, D. Brockhoff, N. Hansen, O. A. ElHara, Y . Semet, R. Kassab, and F. Barbaresco, “A comparative study of large-scale variants of cma-es,” inInternational conference on parallel problem solving from nature. Springer, 2018, pp. 3–15
work page 2018
-
[18]
D. Brockhoff, A. Auger, N. Hansen, and T. Tu ˇsar, “Using well- understood single-objective functions in multiobjective black-box op- timization test suites,”Evolutionary computation, vol. 30, no. 2, pp. 165–193, 2022
work page 2022
-
[19]
U. ˇSkvorc, T. Eftimov, and P. Koro ˇsec, “Understanding the problem space in single-objective numerical optimization using exploratory land- scape analysis,”Applied Soft Computing, vol. 90, p. 106138, 2020
work page 2020
-
[20]
Generating new space-filling test instances for continuous black-box optimization,
M. A. Mu ˜noz and K. Smith-Miles, “Generating new space-filling test instances for continuous black-box optimization,”Evolutionary compu- tation, vol. 28, no. 3, pp. 379–404, 2020
work page 2020
-
[21]
Investigating benchmark correlations when comparing algorithms with parameter tuning,
L. A. Christie, A. E. Brownlee, and J. R. Woodward, “Investigating benchmark correlations when comparing algorithms with parameter tuning,” inProceedings of the Genetic and Evolutionary Computation Conference Companion, 2018, pp. 209–210
work page 2018
-
[22]
B. Lacroix and J. McCall, “Limitations of benchmark sets and land- scape features for algorithm selection and performance prediction,” in SUBMITTED TO IEEE 15 Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2019, pp. 261–262
work page 2019
-
[23]
An exploratory landscape analysis- based benchmark suite,
R. D. Lang and A. P. Engelbrecht, “An exploratory landscape analysis- based benchmark suite,”Algorithms, vol. 14, no. 3, p. 78, 2021
work page 2021
-
[24]
New benchmark functions for single- objective optimization based on a zigzag pattern,
J. Kudela and R. Matousek, “New benchmark functions for single- objective optimization based on a zigzag pattern,”IEEE Access, vol. 10, pp. 8262–8278, 2022
work page 2022
-
[25]
An investigation of inherent structural bias in established benchmark sets,
D. Ibehej, A. Tzanetos, M. Juricek, and J. Kudela, “An investigation of inherent structural bias in established benchmark sets,” inProceedings of the Genetic and Evolutionary Computation Conference Companion, 2025, pp. 123–126
work page 2025
-
[26]
Catbench: A compiler autotuning benchmarking suite for black-box optimization,
J. O. Tørring, C. Hvarfner, L. Nardi, and M. Sj ¨alander, “Catbench: A compiler autotuning benchmarking suite for black-box optimization,” arXiv preprint arXiv:2406.17811, 2024
-
[27]
VRPBench: A Vehicle Routing Benchmark Tool
G. A. Zeni, M. Menzori, P. S. Martins, and L. A. Meira, “Vrpbench: A vehicle routing benchmark tool,”arXiv preprint arXiv:1610.05402, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Aerodynamic shape optimiza- tion investigations of the common research model wing benchmark,
Z. Lyu, G. K. Kenway, and J. R. Martins, “Aerodynamic shape optimiza- tion investigations of the common research model wing benchmark,” AIAA journal, vol. 53, no. 4, pp. 968–985, 2015
work page 2015
-
[29]
Adjoint-based aerodynamic optimization of benchmark problems,
S. Nadarajah, “Adjoint-based aerodynamic optimization of benchmark problems,” in53rd AIAA aerospace sciences meeting, 2015, p. 1948
work page 2015
-
[30]
Truss topology optimization with simultaneous analysis and design,
S. Sankaranarayanan, R. T. Haftka, and R. K. Kapania, “Truss topology optimization with simultaneous analysis and design,”AIAA journal, vol. 32, no. 2, pp. 420–424, 1994
work page 1994
-
[31]
Nonlinear integer and discrete programming in mechan- ical design optimization,
E. Sandgren, “Nonlinear integer and discrete programming in mechan- ical design optimization,” 1990
work page 1990
-
[32]
Benchmark problems in structural optimization,
A. H. Gandomi and X.-S. Yang, “Benchmark problems in structural optimization,” inComputational optimization, methods and algorithms. Springer, 2011, pp. 259–281
work page 2011
-
[33]
A collection of robotics problems for benchmarking evolutionary computation methods,
J. Kudela, M. Ju ˇr´ıˇcek, and R. Par ´ak, “A collection of robotics problems for benchmarking evolutionary computation methods,” inInternational conference on the applications of evolutionary computation (Part of EvoStar). Springer, 2023, pp. 364–379
work page 2023
-
[34]
Benchmarking and optimization of robot motion planning with motion planning pipeline,
S. Liu and P. Liu, “Benchmarking and optimization of robot motion planning with motion planning pipeline,”The International Journal of Advanced Manufacturing Technology, vol. 118, no. 3, pp. 949–961, 2022
work page 2022
-
[35]
Benchmarking global optimization techniques for unmanned aerial vehicle path planning,
M. A. Shehadeh and J. Kudela, “Benchmarking global optimization techniques for unmanned aerial vehicle path planning,”Expert Systems with Applications, p. 128645, 2025
work page 2025
-
[36]
solar: A solar thermal power plant simulator for blackbox optimization benchmarking,
N. Andr ´es-Thi´o, C. Audet, M. Diago, A. E. Gheribi, S. L. Digabel, X. Lebeuf, M. L. Garneau, and C. Tribes, “solar: A solar thermal power plant simulator for blackbox optimization benchmarking,”Optimization and Engineering, pp. 1–47, 2025
work page 2025
-
[37]
Simopt: A testbed for simulation-optimization experiments,
D. J. Eckman, S. G. Henderson, and S. Shashaani, “Simopt: A testbed for simulation-optimization experiments,”INFORMS Journal on Com- puting, vol. 35, no. 2, pp. 495–508, 2023
work page 2023
-
[38]
On the limited memory bfgs method for large scale optimization,
D. C. Liu and J. Nocedal, “On the limited memory bfgs method for large scale optimization,”Mathematical programming, vol. 45, no. 1, pp. 503–528, 1989
work page 1989
-
[39]
Implementing the nelder-mead simplex algorithm with adaptive parameters,
F. Gao and L. Han, “Implementing the nelder-mead simplex algorithm with adaptive parameters,”Computational Optimization and Applica- tions, vol. 51, no. 1, pp. 259–277, 2012
work page 2012
-
[40]
Zoopt: a toolbox for derivative-free optimization,
Y .-R. Liu, Y .-Q. Hu, H. Qian, C. Qian, and Y . Yu, “Zoopt: a toolbox for derivative-free optimization,”Science China Information Sciences, vol. 65, no. 10, Sep. 2022. [Online]. Available: http: //dx.doi.org/10.1007/s11432-021-3416-y
-
[41]
Efficiency of generalized simulated annealing,
Y . Xiang and X. G. Gong, “Efficiency of generalized simulated annealing,”Phys. Rev. E, vol. 62, pp. 4473–4476, Sep 2000. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevE.62.4473
-
[42]
Some variants of the controlled random search algorithm for global optimization,
P. Kaelo and M. M. Ali, “Some variants of the controlled random search algorithm for global optimization,”Journal of Optimization Theory and Applications, vol. 130, no. 2, pp. 253–264, Aug 2006. [Online]. Available: https://doi.org/10.1007/s10957-006-9101-0
-
[43]
Global optimization using branch-and-bound,
K. Madsen, S. Zertchaninov, and A. Zilinskas, “Global optimization using branch-and-bound,” 1998
work page 1998
-
[44]
Electromagnetic field optimization: A physics-inspired metaheuristic optimization algorithm,
H. Abedinpourshotorban, S. M. H. Shamsuddin, Z. Beheshti, and D. N. A. Jawawi, “Electromagnetic field optimization: A physics-inspired metaheuristic optimization algorithm,”Swarm Evol. Comput., vol. 26, pp. 8–22, 2016. [Online]. Available: https: //api.semanticscholar.org/CorpusID:184052
work page 2016
-
[45]
A new optimizer using particle swarm theory,
R. Eberhart and J. Kennedy, “A new optimizer using particle swarm theory,” inMHS’95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science, 1995, pp. 39–43
work page 1995
-
[46]
A comparative study of artificial bee colony algorithm,
D. Karaboga and B. Akay, “A comparative study of artificial bee colony algorithm,”Applied Mathematics and Computation, vol. 214, no. 1, pp. 108–132, 2009. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0096300309002860
work page 2009
-
[47]
A novel nature-inspired algorithm for optimization: Squirrel search algorithm,
M. Jain, V . Singh, and A. Rani, “A novel nature-inspired algorithm for optimization: Squirrel search algorithm,”Swarm and Evolutionary Computation, vol. 44, pp. 148–175, 2019
work page 2019
-
[48]
Bat algorithm: a novel approach for global engineering optimization,
X.-S. Yang and A. Hossein Gandomi, “Bat algorithm: a novel approach for global engineering optimization,”Engineering computations, vol. 29, no. 5, pp. 464–483, 2012
work page 2012
-
[49]
S. Mirjalili, S. M. Mirjalili, and A. Lewis, “Grey wolf optimizer,” Advances in Engineering Software, vol. 69, pp. 46–61, 2014. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0965997813001853
work page 2014
-
[50]
Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications,
W. Zhao, Z. Zhang, and L. Wang, “Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications,” Engineering Applications of Artificial Intelligence, vol. 87, p. 103300, 2020. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0952197619302593
work page 2020
-
[51]
Fireworks algorithm for optimization,
Y . Tan and Y . Zhu, “Fireworks algorithm for optimization,” inAdvances in Swarm Intelligence, Y . Tan, Y . Shi, and K. C. Tan, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 355–364
work page 2010
-
[52]
Improving the search performance of shade using linear population size reduction,
R. Tanabe and A. S. Fukunaga, “Improving the search performance of shade using linear population size reduction,” in2014 IEEE Congress on Evolutionary Computation (CEC), 2014, pp. 1658–1665
work page 2014
-
[53]
pymoo: Multi-objective optimization in python,
J. Blank and K. Deb, “pymoo: Multi-objective optimization in python,” IEEE Access, vol. 8, pp. 89 497–89 509, 2020
work page 2020
-
[54]
Designing novel photonic devices by bio-inspired computing,
C. Santos, M. Gonc ¸alves, and H. E. Hern ´andez Figueroa, “Designing novel photonic devices by bio-inspired computing,”Photonics Technol- ogy Letters, IEEE, vol. 22, pp. 1177 – 1179, 09 2010
work page 2010
-
[55]
Completely derandomized self- adaptation in evolution strategies,
N. Hansen and A. Ostermeier, “Completely derandomized self- adaptation in evolution strategies,”Evolutionary Computation, vol. 9, no. 2, pp. 159–195, 2001
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.