Efficient Simulation and Calibration of the Rough Bergomi Model via Wasserstein Distance
Pith reviewed 2026-05-17 03:32 UTC · model grok-4.3
The pith
The rough Bergomi model can be simulated at linear cost in time steps and calibrated by matching entire terminal distributions with Wasserstein distance instead of discrete option prices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The modified-sum-of-exponentials Monte Carlo scheme combines exact treatment of the singular kernel over the first time step with a sum-of-exponentials approximation thereafter and exact Gaussian simulation of the resulting multifactor components; for a fixed number of terms it maintains linear online complexity with respect to time steps and delivers high pricing accuracy, particularly for out-of-the-money options. Building on this engine, calibration is performed by matching the model-generated terminal distribution of the underlying asset to the market-implied distribution via the Wasserstein-1 distance and its Kantorovich-Rubinstein dual representation, which improves parameter recovery,
What carries the argument
The modified-sum-of-exponentials (mSOE) Monte Carlo scheme inside a hybrid multifactor approximation that handles the rough kernel exactly at the first step and with a fixed exponential sum afterward while preserving linear complexity.
If this is right
- Simulation cost scales linearly with the number of time steps once the number of exponential terms is fixed.
- Pricing errors remain small for out-of-the-money options even with the hybrid approximation.
- Calibration optimization becomes more stable because the objective compares full terminal distributions rather than isolated strikes.
- Out-of-sample pricing performance improves when parameters are obtained from Wasserstein matching.
- The same pricing engine can be reused for both calibration and subsequent valuation without changing complexity.
Where Pith is reading between the lines
- The linear-complexity engine could support real-time risk calculations that were previously too slow under rough-volatility dynamics.
- Distributional matching may automatically capture higher-order moments and tail behavior that strike-by-strike fitting often misses.
- The approach might extend to other rough-volatility models whose kernels admit similar exponential approximations.
- Testing the method on intraday or high-frequency data could reveal whether the fixed-exponential assumption holds under shorter time horizons.
Load-bearing premise
A fixed number of exponential terms in the mSOE approximation remains accurate enough for the singular kernel across the parameter regimes and time horizons used in the pricing and calibration experiments.
What would settle it
Generate paths with the true rough Bergomi parameters, apply the Wasserstein calibration on simulated option data, and check whether the recovered parameters converge to the known true values as the number of Monte Carlo paths increases.
Figures







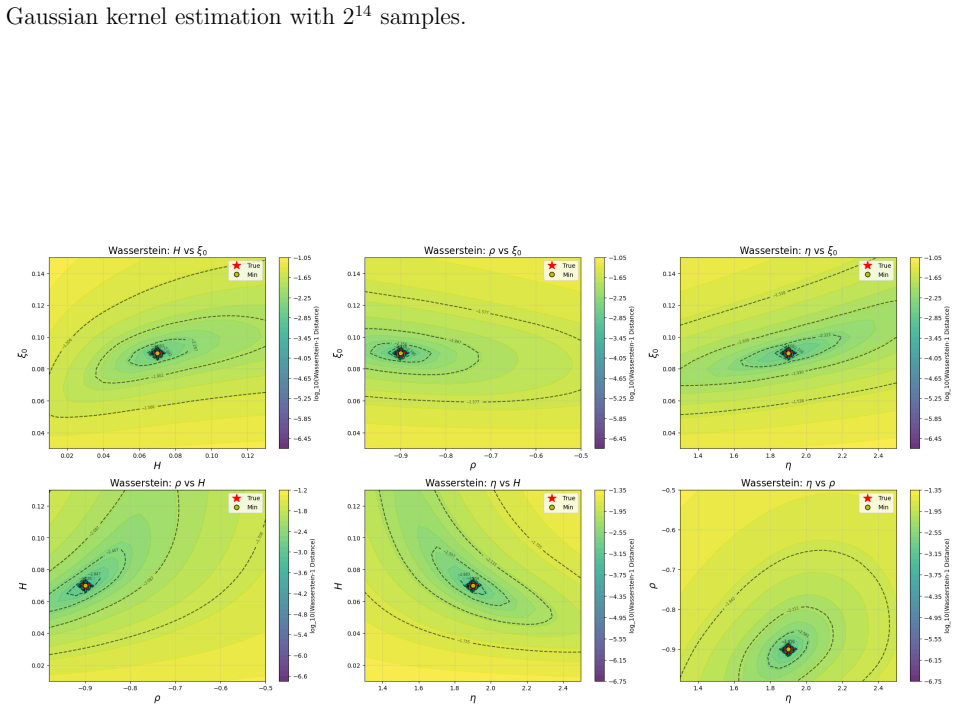


read the original abstract
Despite the empirical success of the rough Bergomi (rBergomi) model in modeling volatility dynamics, its practical use remains challenging due to high computational complexity in both pricing and calibration arising from its non-Markovian structure. To address these difficulties, we develop an efficient computational framework. First, we propose a modified-sum-of-exponentials (mSOE) Monte Carlo scheme within the class of hybrid multifactor approximations. The method combines an exact treatment of the singular kernel over the first time step with a sum-of-exponentials approximation over the remaining time interval, and exact Gaussian simulation of the resulting multifactor components. For a fixed number of exponential terms, the method maintains linear online complexity with respect to the number of time steps. It achieves high pricing accuracy in numerical experiments, particularly for out-of-the-money options. Second, building on this pricing engine, we formulate a calibration approach based on distributional matching of the terminal underlying asset via the Wasserstein-1 distance. Instead of fitting option prices only at selected strikes, this method compares model-generated and market-implied terminal distributions through the Kantorovich-Rubinstein dual representation. Numerical experiments indicate that the mSOE scheme exhibits stable convergence, and the Wasserstein-based calibration scheme improves parameter recovery, optimization stability, and out-of-sample performance relative to conventional MSE-based fitting in the rBergomi setting considered in this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modified sum-of-exponentials (mSOE) Monte Carlo scheme for the rough Bergomi model that treats the singular kernel exactly on the first time step and approximates the remainder with a fixed number of exponentials, yielding linear online complexity and high accuracy for out-of-the-money options in reported experiments; it further introduces a Wasserstein-1 distance calibration that matches terminal distributions via the Kantorovich-Rubinstein dual and reports improved parameter recovery, optimization stability, and out-of-sample performance relative to MSE-based fitting.
Significance. If the mSOE approximation error remains controlled, the framework would supply a practical, linearly scaling simulation engine and a more stable distributional calibration method for rough volatility models that are widely used in quantitative finance. The numerical experiments demonstrating stable convergence of the pricing scheme and better out-of-sample behavior of the Wasserstein objective constitute a concrete strength that supports the practical utility of the approach.
major comments (2)
- [§3] §3 (mSOE Monte Carlo scheme): the central accuracy claim for OTM options and the downstream Wasserstein calibration both rest on the fixed-term sum-of-exponentials approximation controlling truncation error for the kernel K(t)∼t^{H−1/2}. No a priori error bound is supplied, and the experiments do not systematically vary H down to 0.05 or extend T while holding the number of exponential terms constant; this is load-bearing for the reported pricing accuracy and calibration improvements.
- [§5] §5 (numerical experiments): the reported high accuracy and stable convergence are shown only for the chosen parameter regimes; without an ablation that increases the number of time steps or decreases H while keeping the exponential term count fixed, it is unclear whether the linear-complexity claim continues to deliver Monte-Carlo tolerance accuracy outside the tested window.
minor comments (2)
- [Abstract] Abstract: the phrase 'the rBergomi setting considered in this paper' is vague; a brief statement of the H and T ranges actually tested would improve clarity.
- Notation: the distinction between the exact first-step kernel treatment and the subsequent mSOE approximation could be highlighted with a dedicated equation or diagram to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important aspects of the theoretical and numerical support for the mSOE scheme. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (mSOE Monte Carlo scheme): the central accuracy claim for OTM options and the downstream Wasserstein calibration both rest on the fixed-term sum-of-exponentials approximation controlling truncation error for the kernel K(t)∼t^{H−1/2}. No a priori error bound is supplied, and the experiments do not systematically vary H down to 0.05 or extend T while holding the number of exponential terms constant; this is load-bearing for the reported pricing accuracy and calibration improvements.
Authors: We agree that a rigorous a priori error bound for the truncation error of the fixed-term sum-of-exponentials approximation would strengthen the theoretical foundation. The current manuscript relies on the hybrid construction (exact treatment of the singular kernel on the first step) together with numerical evidence to control the error for the reported regimes. To address the referee's concern, we will add a dedicated subsection in §3 discussing the sources of approximation error and their dependence on H and the number of terms, and we will include additional numerical tests that systematically lower H to 0.05 and increase T while keeping the exponential count fixed. revision: yes
-
Referee: [§5] §5 (numerical experiments): the reported high accuracy and stable convergence are shown only for the chosen parameter regimes; without an ablation that increases the number of time steps or decreases H while keeping the exponential term count fixed, it is unclear whether the linear-complexity claim continues to deliver Monte-Carlo tolerance accuracy outside the tested window.
Authors: The experiments in §5 demonstrate stable convergence and high accuracy for the parameter values and time-step counts typical in practical rBergomi applications. We acknowledge that broader ablation studies would more convincingly establish robustness of the linear-complexity claim. In the revised manuscript we will augment §5 with additional tables and figures that increase the number of time steps and decrease H (down to 0.05) while holding the number of exponential terms constant, confirming that Monte-Carlo tolerance accuracy is maintained. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The mSOE Monte Carlo scheme is constructed by explicitly combining an exact singular-kernel treatment on the first time step with a fixed-term sum-of-exponentials approximation thereafter, followed by exact Gaussian simulation of the resulting factors; this definition is independent of any target pricing or calibration outcome. The Wasserstein-1 calibration is likewise formulated directly via the Kantorovich-Rubinstein dual representation comparing terminal distributions, without fitting a parameter that is then re-labeled as a prediction or invoking a self-citation chain whose validity depends on the present results. Numerical accuracy claims rest on reported experiments rather than on any algebraic identity that collapses the method to its inputs by construction. No load-bearing self-citation, uniqueness theorem imported from the authors, or ansatz smuggled via prior work appears in the central derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of exponential terms
axioms (1)
- domain assumption The rough Bergomi model dynamics with fractional kernel are correctly specified for the market data considered.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
inf θ∈Θ 1/M ∑ W1(STj(θ), SMKT_Tj) ... Kantorovich-Rubinstein duality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
E. Abi Jaber and O. El Euch. Multifactor approximation of rough volatility models. SIAM Journal on Financial Mathematics , 10(2):309–349, 2019
work page 2019
-
[3]
F. Baschetti, G. Bormetti, and P. Rossi. Deep calibration with random grids. Quanti- tative Finance, pages 1–23, 2024
work page 2024
-
[4]
C. Bayer and S. Breneis. Markovian approximations of stochastic Volterra equations with the fractional kernel. Quantitative Finance, 23(1):53–70, 2023
work page 2023
-
[5]
C. Bayer and S. Breneis. Weak Markovian approximations of rough Heston. arXiv preprint arXiv:2309.07023, 2023
- [6]
-
[7]
M. Bennedsen, A. Lunde, and M. S. Pakkanen. Hybrid scheme for Brownian semista- tionary processes. Finance and Stochastics, 21:931–965, 2017
work page 2017
-
[8]
D. Braess. Nonlinear approximation theory. Springer Science & Business Media, 2012
work page 2012
-
[9]
M. De Angelis and A. Gray. Why the 1-Wasserstein distance is the area between the two marginal cdfs. arXiv preprint arXiv:2111.03570 , 2021
- [10]
- [11]
-
[12]
P. Gassiat. On the martingale property in the rough Bergomi model. 2019
work page 2019
-
[13]
J. Gatheral, T. Jaisson, and M. Rosenbaum. Volatility is rough. In Commodities, pages 659–690. Chapman and Hall/CRC, 2022
work page 2022
-
[14]
A. Gulisashvili. Gaussian stochastic volatility models: Scaling regimes, large deviations, and moment explosions. Stochastic Processes and their Applications, 130(6):3648–3686, 2020. 27
work page 2020
-
[15]
P. Harms. Strong convergence rates for Markovian representations of fractional Brownian motion, 2019
work page 2019
-
[16]
B. Horvath, A. Muguruza, and M. Tomas. Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough) volatility models. Quantitative Finance, 21(1):11–27, 2021
work page 2021
- [17]
- [18]
-
[19]
S. Liu, A. Borovykh, L. A. Grzelak, and C. W. Oosterlee. A neural network-based framework for financial model calibration. Journal of Mathematics in Industry , 9(1):9, 2019
work page 2019
-
[20]
C. R. Nelson and A. F. Siegel. Parsimonious modeling of yield curves. Journal of business, pages 473–489, 1987
work page 1987
-
[21]
S. E. Rømer. Hybrid multifactor scheme for stochastic Volterra equations with com- pletely monotone kernels. Available at SSRN 3706253 , 2022
work page 2022
-
[22]
A. Tong, T. Nguyen-Tang, T. Tran, and J. Choi. Learning fractional white noises in neural stochastic differential equations. In Advances in Neural Information Processing Systems, volume 35, pages 37660–37675, 2022
work page 2022
-
[23]
C. Villani. Topics in optimal transportation. American Mathematical Soc., Providence, 2021
work page 2021
-
[24]
D. V. Widder. The Laplace Transform, volume vol. 6 of Princeton Mathematical Series. Princeton University Press, Princeton, NJ, 1941
work page 1941
-
[25]
Q. Zhu, G. Loeper, W. Chen, and N. Langren´ e. Markovian approximation of the rough Bergomi model for Monte Carlo option pricing. Mathematics, 9(5):528, 2021. 28
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.