Learning Filters in Feedback Delay Networks from Noisy Room Impulse Responses
Pith reviewed 2026-05-16 21:40 UTC · model grok-4.3
The pith
Explicitly modeling noise during optimization yields accurate attenuation filter estimates for feedback delay networks even when room impulse responses are noisy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting the loss function with an explicit noise model, the optimization of frequency-dependent attenuation filters in a feedback delay network recovers the intended decay rates and spectral shape even when the target impulse response has low signal-to-noise ratio; the same procedure also quantifies the sensitivity of those filters to small changes in the network’s frequency-independent gains and delays.
What carries the argument
Explicit additive noise term inside the differentiable loss used to optimize recursive attenuation filters of a feedback delay network.
If this is right
- Attenuation filter estimates remain accurate down to lower signal-to-noise ratios than previously possible.
- Gradient optimization of feedback delay networks becomes more reproducible once frequency-independent parameters are held fixed or jointly optimized with care.
- The same noise-modeling step can be inserted into any differentiable loss that compares synthesized and measured impulse responses.
- Statistical tests on both synthetic and real data confirm the accuracy gain is consistent across multiple room geometries.
Where Pith is reading between the lines
- The stationary-noise assumption could be relaxed to a slowly varying noise floor without changing the overall optimization architecture.
- Similar explicit modeling of measurement artifacts may improve other differentiable audio tasks such as equalizer design or modal synthesis from noisy data.
- The observed sensitivity to frequency-independent parameters suggests that joint optimization schedules or regularization on those parameters would further stabilize filter learning.
Load-bearing premise
Background noise behaves as a simple stationary additive process whose interaction with the reverberant tail does not systematically bias the gradient updates for the attenuation filters.
What would settle it
On a set of measured room impulse responses whose true attenuation filters are known from a controlled anechoic reference, measure whether the noise-aware optimizer recovers filter coefficients within a stated error tolerance while the baseline optimizer without noise modeling does not.
Figures
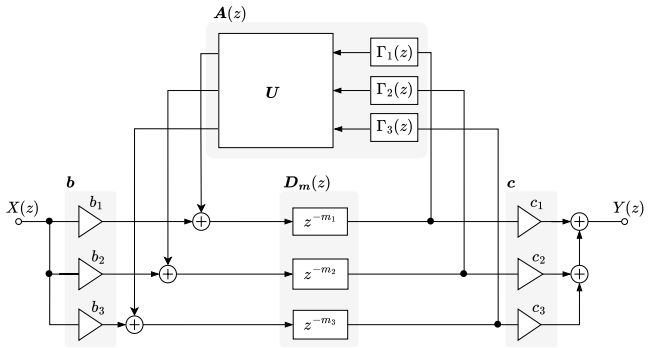











read the original abstract
Recursion is a fundamental concept in the design of filters and audio systems. In particular, artificial reverberation systems that use delay networks depend on recursive paths to control both echo density and the decay rate of modal components. The differentiable digital signal processing framework has shown promise in automatically tuning recursive and non-recursive elements using gradient-based optimization with perceptually or physically motivated loss functions, such as energy decay or spectrogram differences. These representations are highly sensitive to model mismatches, which can lead to spurious loss minima. In particular, discrepancies in background noise can result in inaccurate attenuation estimates. This paper addresses the problem of tuning recursive attenuation filters of a feedback delay network when targets are noisy. We analyze the loss profile associated with different optimization objectives and propose a method that explicitly models noise, improving the accuracy of the estimated attenuation filters under low signal-to-noise conditions. We demonstrate the effectiveness of the proposed approach through statistical analysis on both synthetic and real target data. Furthermore, we identify the sensitivity of attenuation filter parameters tuning to perturbations in frequency-independent parameters. These findings provide practical guidelines for more robust and reproducible gradient-based optimization of feedback delay networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes explicitly modeling stationary background noise within the loss function used to optimize per-frequency attenuation filters of a feedback delay network (FDN) when the target room impulse responses (RIRs) are noisy. It analyzes how noise creates spurious minima in standard energy-decay or spectrogram losses, introduces a joint optimization over filter coefficients and noise parameters, and reports statistical improvements in filter accuracy on both synthetic and measured RIRs at low SNR. The work additionally quantifies sensitivity of the tuned filters to small perturbations in frequency-independent FDN parameters.
Significance. If the stationary-noise modeling proves robust, the contribution would be a practical, low-overhead improvement to differentiable DSP pipelines for artificial reverberation. It directly mitigates a known source of optimization failure when fitting recursive structures to real acoustic measurements, thereby increasing reproducibility of automated FDN design.
major comments (2)
- [§3] §3 (noise-augmented loss): the claim that the added stationary noise term prevents biased gradients rests on the untested assumption that real background noise does not share modal structure or exhibit non-stationarity correlated with the reverberation tail. No simulation or measurement is shown in which the noise floor is allowed to decay or to excite the same modes as the FDN; without this, the reported accuracy gains may not generalize.
- [§4.3] §4.3 and associated tables: the statistical validation on real RIRs reports improved attenuation-filter error but does not provide the exact definition of the noise variance parameter, the optimizer hyperparameters, or the baseline loss without the noise term. These omissions make it impossible to verify that the improvement is attributable to the proposed modeling rather than to differences in regularization or initialization.
minor comments (2)
- [Figure 2] Figure 2 caption and axis labels: the loss-surface plots would benefit from explicit annotation of the location of the global minimum with and without the noise term.
- [Abstract] The abstract states that the method 'improves accuracy' but does not quantify the improvement (e.g., mean dB error reduction); adding a single sentence with the observed effect size would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3] §3 (noise-augmented loss): the claim that the added stationary noise term prevents biased gradients rests on the untested assumption that real background noise does not share modal structure or exhibit non-stationarity correlated with the reverberation tail. No simulation or measurement is shown in which the noise floor is allowed to decay or to excite the same modes as the FDN; without this, the reported accuracy gains may not generalize.
Authors: We agree that the analysis assumes stationary additive noise independent of the reverberation modes, which is a standard model for background measurement noise in RIRs. The noise-augmented loss is specifically derived to counteract the bias that arises when a stationary floor is present in the target. We will revise §3 to state these assumptions explicitly and add a short discussion of limitations for non-stationary or mode-correlated noise. We will also include a supplementary simulation with a decaying noise floor to illustrate the method's sensitivity at the boundary of the assumption. revision: partial
-
Referee: [§4.3] §4.3 and associated tables: the statistical validation on real RIRs reports improved attenuation-filter error but does not provide the exact definition of the noise variance parameter, the optimizer hyperparameters, or the baseline loss without the noise term. These omissions make it impossible to verify that the improvement is attributable to the proposed modeling rather than to differences in regularization or initialization.
Authors: We acknowledge the lack of implementation detail. In the revised manuscript we will expand §4.3 (and the associated tables) to specify: the exact parameterization and initialization of the noise variance, the full optimizer hyperparameters (learning rate, iteration count, convergence criteria), and the precise mathematical form of the baseline loss without the noise term. These additions will enable direct reproduction and confirm that the reported gains arise from the noise modeling. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes adding an explicit stationary noise model to the loss function when optimizing FDN attenuation filters from noisy RIRs. This is presented as an independent modeling choice that improves gradient behavior under low SNR, rather than a quantity fitted to or defined by the target attenuation filters themselves. No equations or steps in the abstract reduce the proposed noise term to a self-definition, a renamed fit, or a load-bearing self-citation whose validity depends on the current result. The method is evaluated on synthetic and real data, keeping the central claim externally falsifiable. The reader's assessment of score 2.0 aligns with a minor possible self-citation that is not load-bearing for the noise-modeling contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (washburn_uniqueness_aczel, Jcost)J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a method that explicitly models noise, improving the accuracy of the estimated attenuation filters under low signal-to-noise conditions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
loss profiles ... LEDC,lin ... LMSS ... noise-aware condition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Differentiable grouped feedback delay networks for learning coupled volume acoustics
[DDS+25] Orchisama Das, Gloria Dal Santo, Sebastian J Schlecht, Vesa Välimäki, and Zoran Cvetković. Differentiable grouped feedback delay networks for learning coupled volume acoustics. arXiv preprint arXiv:2508.06686,
-
[2]
[DPSV25] Gloria Dal Santo, Karolina Prawda, Sebastian J. Schlecht, and Vesa Välimäki. Optimizing tiny colorless feedback delay networks. EURASIP J. Audio Speech Music Process., 2025(13),
work page 2025
-
[3]
Ddsp: Differentiable digital signal processing.arXiv preprint arXiv:2001.04643, 2020
[EHGR20] J. Engel, L. Hantrakul, C. Gu, and A. Roberts. DDSP: Differentiable Digital Signal Processing. arXiv preprint 2001.04643,
-
[4]
[HSF25] Ben Hayes, Charalampos Saitis, and GyĂśrgy Fazekas. Audio synthesizer inversion in symmetric parameter spaces with approximately equivariant flow matching. arXiv preprint arXiv:2506.07199,
-
[5]
[MGDSB24a] Alessandro Ilic Mezza, Riccardo Giampiccolo, Enzo De Sena, and Alberto Bernardini. Data- driven room acoustic modeling via differentiable feedback delay networks with learnable delay lines. EURASIP J. Audio Speech Music Process. , 2024(1):1–20,
work page 2024
-
[6]
[MGDSB24b] Alessandro Ilic Mezza, Riccardo Giampiccolo, Enzo De Sena, and Alberto Bernardini. Data- driven room acoustic modeling via differentiable feedback delay networks with learnable delay lines. EURASIP J. Audio Speech Music Process. , 2024(51),
work page 2024
-
[7]
Scattering in feedback delay networks
[SH20] Sebastian J Schlecht and Emanuël AP Habets. Scattering in feedback delay networks. IEEE/ACM Trans. Audio Speech Lang. Process., 28:1915–1924, Oct
work page 1915
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.