Do Generalized-Gamma Scale Mixtures of Normals Fit Large Image Datasets?
Pith reviewed 2026-05-16 20:50 UTC · model grok-4.3
The pith
Generalized gamma scale mixtures of normals fit image coefficients from remote sensing, medical, and classification datasets better than Gaussian, Laplace, or Student-t priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
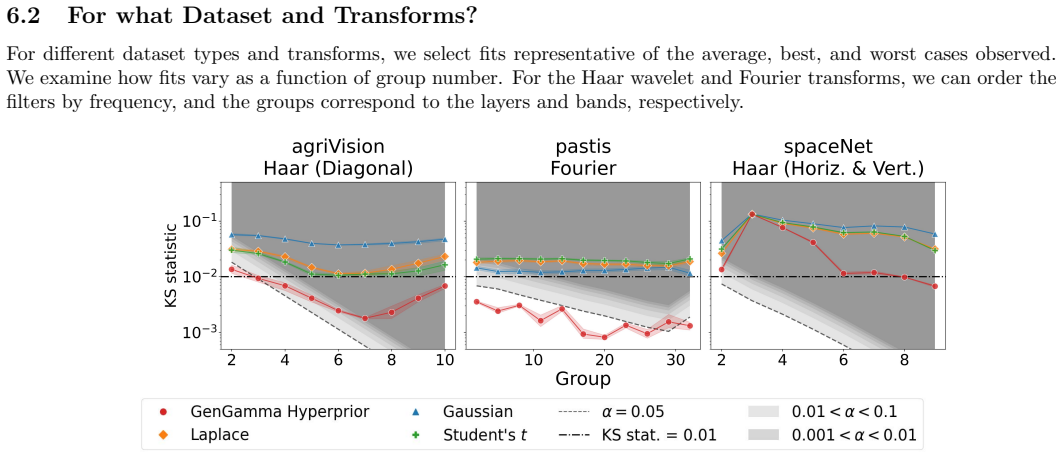
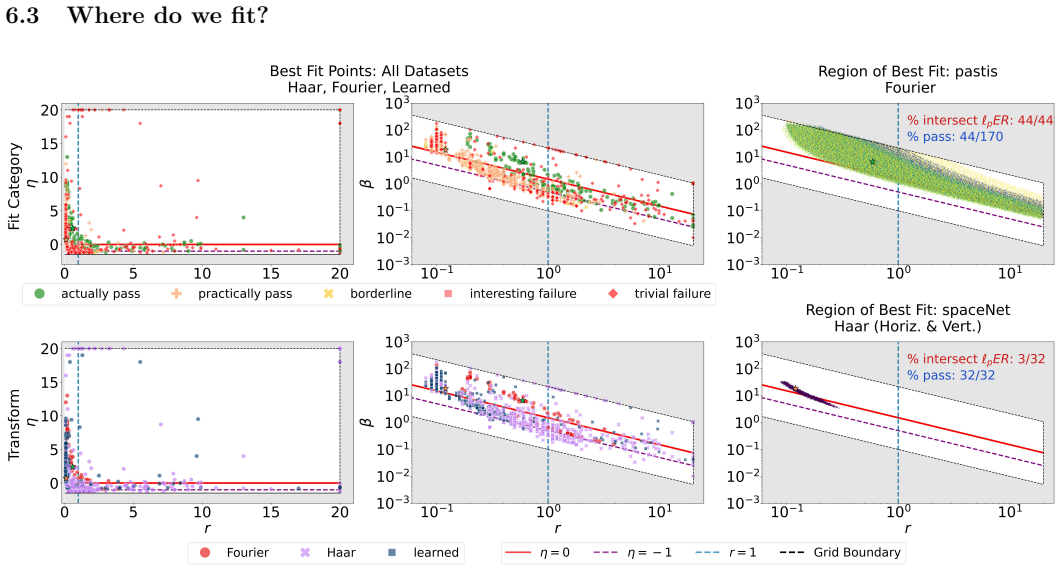
Generalized-gamma scale mixtures of normals are realistic for multiple large imaging data sets drawn from remote sensing, medical imaging, and image classification applications when applied to Fourier and wavelet transformations of the images as well as to coefficients produced by convolving against AlexNet first-layer filters, and this prior family provides a substantially better fit to each data set than Gaussian, Laplace, ell-p, or Student's t priors.
What carries the argument
The generalized gamma scale mixture of normals, formed by mixing normals of fixed mean with variances drawn from a generalized gamma distribution whose two shape parameters separately control behavior near the mode and tail decay.
If this is right
- The prior can be used with greater confidence in Bayesian formulations of inverse imaging problems.
- Parameter regions substantially broader than those emphasized in earlier computational work describe the observed data.
- Data-augmentation procedures and exchangeability screening are required to achieve the reported fit quality.
- The model remains unrealistic for images whose characteristic features produce heavy selection effects or non-exchangeable coefficients.
Where Pith is reading between the lines
- The same prior family could be tested on coefficients from deeper layers of convolutional networks or on other high-dimensional signals such as audio spectrograms.
- Identifying the specific image features that cause poor fit may guide the design of hybrid priors that switch between families depending on local image statistics.
- If the exchangeability assumption holds more generally, the two shape parameters could be estimated once from a representative image corpus and then reused across related inverse problems.
Load-bearing premise
Data-augmentation procedures produce approximately exchangeable coefficients whose marginal distribution can be treated as i.i.d. draws from the generalized-gamma scale mixture without selection bias that inflates apparent fit quality.
What would settle it
A large image dataset, after the same augmentation and exchangeability filtering, where the generalized gamma mixture yields a worse or equal fit to the data compared with Gaussian, Laplace, ell-p, or t priors.
Figures



















read the original abstract
A scale mixture of normals is a distribution formed by mixing a collection of normal distributions with fixed mean but different variances. A generalized gamma scale mixture draws the variances from a generalized gamma distribution. Generalized gamma scale mixtures of normals have been proposed as an attractive class of parametric priors for Bayesian inference in inverse imaging problems. Generalized gamma scale mixtures have two shape parameters, one that controls the behavior of the distribution about its mode, and the other that controls its tail decay. In this paper, we provide the first demonstration that the prior model is realistic for multiple large imaging data sets. We draw data from remote sensing, medical imaging, and image classification applications. We study the realism of the prior when applied to Fourier and wavelet (Haar and Gabor) transformations of the images, as well as to the coefficients produced by convolving the images against the filters used in the first layer of AlexNet, a popular convolutional neural network trained for image classification. We discuss data augmentation procedures that improve the fit of the model, procedures for identifying approximately exchangeable coefficients, and characterize the parameter regions that best describe the observed data sets. These regions are significantly broader than the region of primary focus in computational work. We show that this prior family provides a substantially better fit to each data set than any of the standard priors it contains. These include Gaussian, Laplace, $\ell_p$, and Student's $t$ priors. Finally, we identify cases where the prior is unrealistic and highlight characteristic features of images that suggest the model will fit poorly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically tests whether generalized-gamma scale mixtures of normals (with two shape parameters controlling mode behavior and tail decay) provide realistic priors for coefficients arising from Fourier, wavelet (Haar/Gabor), and AlexNet first-layer transformations of large image datasets drawn from remote sensing, medical imaging, and classification tasks. It introduces data-augmentation procedures and methods to select approximately exchangeable coefficients, characterizes the best-fitting parameter regions (broader than those emphasized in prior computational work), and claims that this two-parameter family yields substantially better fits than the Gaussian, Laplace, ℓ_p, and Student-t special cases it contains. The work also flags image features where the model fits poorly.
Significance. If the reported superior fits survive scrutiny for preprocessing bias, the result would supply the first large-scale empirical validation that generalized-gamma scale mixtures are realistic for real imaging coefficients. This would strengthen the case for using this prior family in Bayesian inverse problems, where the extra flexibility over standard heavy-tailed choices could improve reconstruction quality. The identification of broader parameter regions and failure modes would also guide practical prior selection.
major comments (2)
- [Methods (data augmentation and exchangeability)] Methods section on data augmentation and exchangeability identification: the central claim that the prior family fits substantially better than its special cases rests on the assumption that augmentation and exchangeability selection produce approximately i.i.d. draws without preferentially retaining samples whose marginals match the two-parameter family. No comparison of fits before versus after selection, nor predictive checks on held-out images, is described that would rule out selection bias inflating the reported superiority.
- [Results] Results section (quantitative fit comparisons): the abstract asserts substantially better fits but supplies no numerical goodness-of-fit statistics (e.g., log-likelihood ratios, Kolmogorov-Smirnov distances, or cross-validated predictive scores) with error bars or details on post-hoc exclusions. Without these, it is impossible to assess whether the improvement is statistically meaningful or driven by fitting choices.
minor comments (2)
- [Methods] Clarify the precise definition of 'approximately exchangeable' and the quantitative criterion used to retain coefficients; this notation appears without an explicit threshold or algorithm in the abstract.
- [Figures] Figure captions should report the exact number of coefficients retained after exchangeability filtering for each dataset and transformation, to allow readers to gauge sample size.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have prompted us to strengthen the empirical support in the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [Methods (data augmentation and exchangeability)] Methods section on data augmentation and exchangeability identification: the central claim that the prior family fits substantially better than its special cases rests on the assumption that augmentation and exchangeability selection produce approximately i.i.d. draws without preferentially retaining samples whose marginals match the two-parameter family. No comparison of fits before versus after selection, nor predictive checks on held-out images, is described that would rule out selection bias inflating the reported superiority.
Authors: We agree that the absence of explicit before-versus-after comparisons leaves open the possibility of selection bias. In the revised manuscript we will add direct quantitative comparisons of goodness-of-fit (log-likelihood and Kolmogorov-Smirnov statistics) on the raw coefficient sets versus the post-augmentation, post-exchangeability-selected sets. We will also include posterior predictive checks on held-out images drawn from each application domain to confirm that the reported superiority is not an artifact of the selection procedure. revision: yes
-
Referee: [Results] Results section (quantitative fit comparisons): the abstract asserts substantially better fits but supplies no numerical goodness-of-fit statistics (e.g., log-likelihood ratios, Kolmogorov-Smirnov distances, or cross-validated predictive scores) with error bars or details on post-hoc exclusions. Without these, it is impossible to assess whether the improvement is statistically meaningful or driven by fitting choices.
Authors: We accept that the current version lacks the numerical summaries needed for rigorous evaluation. The revised manuscript will report log-likelihood ratios (with bootstrap standard errors), Kolmogorov-Smirnov distances, and cross-validated predictive scores for the generalized-gamma scale mixture versus each of its special cases, together with an explicit account of any post-hoc exclusions. These additions will allow readers to judge both the magnitude and statistical significance of the reported improvements. revision: yes
Circularity Check
No circularity: empirical marginal fits to image coefficients
full rationale
The paper performs direct empirical comparisons by fitting the two-parameter generalized-gamma scale mixture to observed histograms of Fourier, wavelet, and AlexNet coefficients drawn from multiple large imaging datasets. No derivation, prediction, or uniqueness claim is advanced that reduces by construction to a quantity defined from the fitted parameters themselves. The reported superiority over the one-parameter special cases (Gaussian, Laplace, Student-t) follows from standard likelihood or goodness-of-fit comparison on the same data; the extra flexibility is explicit and the paper also identifies regimes where the model fits poorly. Data-augmentation and exchangeability-selection steps are preprocessing choices whose effect on apparent fit quality can be checked against held-out coefficients or alternative transforms; they do not create a self-referential loop inside any equation. No self-citation supplies a load-bearing uniqueness theorem or ansatz. The analysis is therefore self-contained against external data benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- two shape parameters of generalized gamma
axioms (1)
- domain assumption Transformed coefficients are approximately exchangeable after data augmentation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that this prior family provides a substantially better fit to each data set than any of the standard priors it contains. These include Gaussian, Laplace, ℓp, and Student’s t priors.
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We discuss data augmentation procedures that improve the fit of the model, procedures for identifying approximately exchangeable coefficients
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[1]C. Abanto-Valle, D. Bandyopadhyay, V. Lachos, and I. Enriquez, Robust bayesian analysis of heavy-tailed stochastic volatility models using scale mixtures of normal distributions, Computational Statistics & Data Analysis, 54 (2010), pp. 2883–2898. [2]S. Agrawal, H. Kim, D. Sanz-Alonso, and A. Strang, A variational inference approach to inverse problems ...
work page 2010
-
[2]
[5]S. D. Babacan, R. Molina, and A. K. Katsaggelos, Bayesian compressive sensing using laplace priors, IEEE Transactions on Image Processing, 19 (2010), pp. 53–63. [6]S. Bhadra, W. Zhou, and M. A. Anastasio, Medical image reconstruction with image-adaptive priors learned by use of generative adversarial networks,
work page 2010
-
[3]
[7]A. Buades, B. Coll, and J. M. Morel, A review of image denoising algorithms, with a new one, Multiscale Modeling & Simulation, 4 (2005), pp. 490–530. [8]D. Calvetti, R. K. Dash, E. Somersalo, and M. E. Cabrera, Local regularization method applied to estimating oxygen consumption during muscle activities, Inverse Problems, 22 (2006), pp. 229– 243.https:...
-
[4]
, Brain activity mapping from MEG data via a hierarchical Bayesian algorithm with automatic depth weighting, Brain topography, 32 (2019), pp. 363–393. [12]D. Calvetti, F. Pitolli, E. Somersalo, and B. Vantaggi, Bayes meets Krylov: Statistically inspired preconditioners for CGLS, SIAM Review, 60 (2018), pp. 429–461. [13]D. Calvetti, M. Pragliola, and E. So...
work page 2019
-
[5]
26 [23]Y. Dong and M. Pragliola, Inducing sparsity via the horseshoe prior in imaging problems, Inverse Problems, 39 (2023), p. 074001. [24]D. L. Donoho, M. Elad, and V. N. Temlyakov, Stable recovery of sparse overcomplete representations in the presence of noise, IEEE Transactions on information theory, 52 (2005), pp. 6–18. [25]M. A. Figueiredo, R. D. No...
work page 2023
-
[6]
[28]J. Glaubitz and A. Gelb, Leveraging joint sparsity in hierarchical bayesian learning, SIAM/ASA Journal on Uncertainty Quantification, 12 (2024), pp. 442–472. [29]J. Glaubitz, A. Gelb, and G. Song, Generalized sparse bayesian learning and application to image reconstruction, SIAM/ASA Journal on Uncertainty Quantification, 11 (2023), p. 262–284. [30]J. ...
-
[7]
[38]J. Lindbloom, J. Glaubitz, and A. Gelb, Efficient sparsity-promoting map estimation for bayesian linear inverse problems, Inverse Problems, 41 (2025), p. 025001. [39]A. Manninen, M. Mozumder, T. Tarvainen, and A. Hauptmann, Sparsity promoting reconstructions via hierarchical prior models in diffuse optical tomography, Inverse Problems and Imaging, 18 ...
work page 2025
-
[8]
[46]M. Pragliola, D. Calvetti, and E. Somersalo, Overcomplete representation in a hierarchical Bayesian framework, arXiv preprint arXiv:2006.13524, (2020). [47]L. Roininen, M. Girolami, S. Lasanen, and M. Markkanen, Hyperpriors for mat´ ernfields with applications in bayesian inversion, Inverse Problems and Imaging, 13 (2019), pp. 1–29. [48]J. Shermeyer, ...
-
[9]
[49]Z. Si, Y. Liu, and A. Strang, Path-following methods for maximum a posteriori estimators in bayesian hierarchical models: How estimates depend on hyperparameters, SIAM Journal on Optimization, 34 (2024), pp. 2201–2230. [50]J. Suuronen, N. K. Chada, and L. Roininen, Cauchy markov random field priors for bayesian inversion, Statistics and Computing, 32 ...
-
[10]
[54]Y. Xiao and J. Glaubitz, Sequential image recovery using joint hierarchical bayesian learning, Journal of Scientific Computing, 96 (2023). [55]H. Zou and T. Hastie, Regularization and variable selection via the elastic net, Journal of the Royal Statistical Society Series B: Statistical Methodology, 67 (2005), pp. 301–320. 28 A Survey of Computational ...
work page 2023
-
[11]
2008 Computed / Synthetic Computational Conditionally Gaussian hypermodels for cerebral source local- ization
work page 2008
-
[12]
2009 Computed / Synthetic Application Sparse Bayesian image Restoration
work page 2009
-
[13]
2010 Classic Application A hierarchical Krylov–Bayes iterative inverse solver for MEG with physiological preconditioning
work page 2010
-
[14]
2015 Computed / Synthetic Application Bayes meets Krylov: Statistically inspired preconditioners for CGLS
work page 2015
-
[15]
2018 Computed / Synthetic Computational Brain activity mapping from MEG data via a hierarchical Bayesian algorithm with automatic depth weighting
work page 2018
-
[16]
2019 Real and Synthetic Application Hierarchical Bayesian models and sparsity:ℓ 2-magic
work page 2019
-
[17]
2019 Computed / Synthetic Computational Sparse reconstructions from few noisy data: analysis of hier- archical Bayesian models with generalized gamma hyperpriors
work page 2019
-
[18]
2020 Computed / Synthetic Computational Sparsity promoting hybrid solvers for hierarchical Bayesian in- verse problems
work page 2020
-
[19]
2020 Computed / Synthetic Computational Overcomplete representation in a hierarchical Bayesian frame- work
work page 2020
-
[20]
2020 Computed / Synthetic Computational A variational inference approach to inverse problems with gamma hyperpriors
work page 2020
-
[21]
2022 Computed / Synthetic Computational Hierarchical ensemble Kalman methods with sparsity-promoting generalized Gamma hyperpriors
work page 2022
-
[22]
2022 Computed / Synthetic Computational Hierarchical Ensemble Kalman Methods with Sparsity- Promoting Generalized Gamma Hyperpriors
work page 2022
-
[23]
2022 Computed / Synthetic Computational Sparsity promoting reconstructions via hierarchical prior mod- els in diffuse optical tomography
work page 2022
-
[24]
2023 Computed / Synthetic Computational Sequential image recovery using joint hierarchical Bayesian learning
work page 2023
-
[25]
2023 Real and Synthetic Computational Leveraging joint sparsity in hierarchical Bayesian learning
work page 2023
-
[26]
2024 Computed / Synthetic Computational Efficient sampling for sparse Bayesian learning using hierarchi- cal prior normalization
work page 2024
-
[27]
2025 Computed / Synthetic Computational Efficient sparsity-promoting MAP estimation for Bayesian lin- ear inverse problems
work page 2025
-
[28]
2025 Classic Computational Table 7: Survey of papers using a conditionally Gaussian prior model with (generalized) gamma hyperpriors. 29 B Learned Filters Figure 18: Visualization of all 64 learned filters used, normalized 0-1, from the first layer of AlexNet with their filter category. Cn th Moment Calculation E[X n] = (n−1)!!ϑ n 2 Γ η+1.5+ n...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.