SLIDE: Simultaneous Model Downloading and Inference at the Wireless Network Edge
Pith reviewed 2026-05-16 20:04 UTC · model grok-4.3
The pith
The SLIDE framework allows mobile devices to begin inferring AI models with early layers while downloading the rest, cutting end-to-end latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
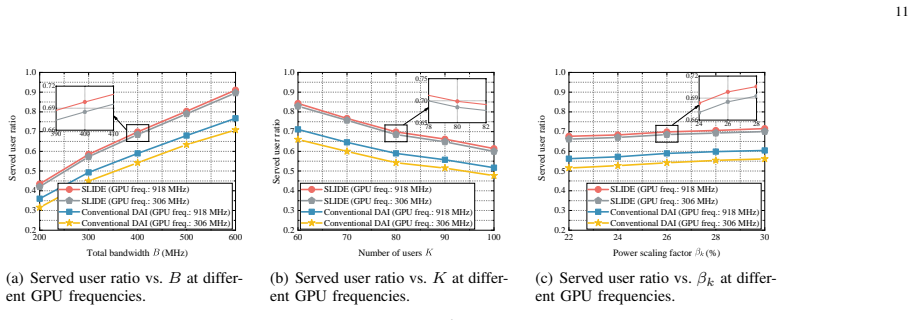
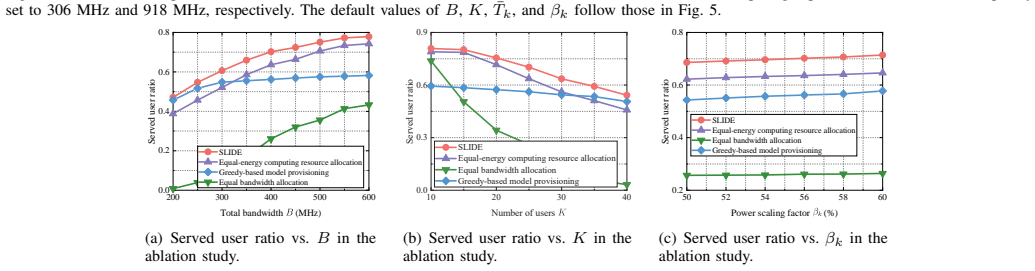
The SLIDE framework enables users to perform inference with downloaded layers while simultaneously receiving the remaining layers of the model. By jointly optimizing model provisioning, spectrum bandwidth allocation, and computing resource allocation for multi-user downlink systems, and accounting for recursive dependencies in inference latency across layers, an efficient polynomial-time algorithm yields solutions that significantly improve task throughput under latency and communication resource constraints compared to conventional model downloading schemes.
What carries the argument
The recursive latency dependencies across model layers in the SLIDE framework, where the inference time for each layer depends on the downloading bandwidth and computing resources allocated to all preceding layers.
If this is right
- Task throughput is maximized by solving a joint optimization over model splits, bandwidth, and compute resources.
- The approach achieves better performance than sequential download and inference under the same constraints.
- Real-time AI inference services become more viable in next-generation mobile networks despite large model sizes.
- An efficient algorithm computes the optimal allocation in polynomial time for practical deployment.
Where Pith is reading between the lines
- SLIDE could be combined with model compression techniques to further reduce download times for even larger models.
- Dynamic adjustments to layer splits based on real-time channel conditions might enhance robustness in varying wireless environments.
- Similar simultaneous processing ideas could apply to other data-intensive tasks like video analytics or sensor data processing at the edge.
Load-bearing premise
That AI models can be divided into independent layers for sequential inference without any drop in accuracy or extra overhead from the splitting process.
What would settle it
An experiment on real hardware showing whether splitting a neural network model for layer-by-layer inference maintains the same accuracy as full-model inference while measuring actual latency savings in a wireless setup.
Figures








read the original abstract
To support on-device inference, the next-generation mobile networks are expected to support real-time model downloading services to mobile users. However, powerful AI models typically have large model sizes, resulting in excessive end-to-end (E2E) downloading-and-inference (DAI) latency. To address this issue, we propose a simultaneous model downloading and inference (SLIDE) framework, which allows users to perform inference with downloaded layers while simultaneously receiving the remaining layers of the model. To this end, we formulate a task throughput maximization problem by jointly optimizing model provisioning, spectrum bandwidth allocation, and computing resource allocation for multi-user downlink systems. Unlike traditional DAI frameworks, SLIDE introduces recursive dependencies across layers, where inference latency depends recursively on the downloading bandwidth and computing resource allocation for each of the preceding layers. To solve this challenging problem, we design an efficient algorithm that acquires the optimal solution with polynomial-time complexity. Simulation results demonstrate that the proposed SLIDE framework significantly improves task throughput under latency and communication resource constraints compared with the conventional model downloading schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the SLIDE framework to reduce end-to-end latency for on-device AI inference by enabling simultaneous model layer downloading and inference on already-received layers in multi-user wireless downlink systems. It formulates a task throughput maximization problem that jointly optimizes model provisioning (layer allocation), spectrum bandwidth, and computing resource allocation, explicitly incorporating recursive per-layer latency dependencies. The resulting non-convex optimization is solved by a polynomial-time algorithm whose optimality is asserted for the multi-user setting, with simulations claiming substantial throughput gains over conventional download-and-inference baselines under latency and resource constraints.
Significance. If the recursive latency model and optimality claims hold, the work offers a practical mechanism for overlapping communication and computation phases in edge AI, which could improve task throughput in bandwidth- and latency-constrained 5G/6G scenarios. The polynomial-time solvability is a concrete strength for real-time deployment, provided the formulation avoids hidden overheads from partial-layer execution.
major comments (2)
- [§3] §3 (System Model): The recursive latency dependency (inference time for layer k depending on prior-layer bandwidth and compute allocations) is load-bearing for the claimed novelty over DAI; the manuscript must supply the exact recursive equations and verify that they introduce no circularity or unmodeled accuracy loss when layers are executed sequentially.
- [§4] §4 (Algorithm): The polynomial-time complexity and optimality guarantee for the joint allocation problem must be supported by a formal proof or reduction (e.g., to a known solvable structure such as water-filling or dynamic programming); without it, the simulation gains cannot be attributed to the algorithm rather than heuristic tuning.
minor comments (2)
- [Abstract] Abstract and §5 (Simulations): Quantitative throughput gains (e.g., percentage improvement or absolute values) should be stated explicitly rather than described only qualitatively as 'significant'.
- [§3] Notation consistency: Ensure that variables for per-layer bandwidth B_k and compute C_k are defined before first use in the optimization formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of the recursive latency model and the algorithm's theoretical guarantees. We address each major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (System Model): The recursive latency dependency (inference time for layer k depending on prior-layer bandwidth and compute allocations) is load-bearing for the claimed novelty over DAI; the manuscript must supply the exact recursive equations and verify that they introduce no circularity or unmodeled accuracy loss when layers are executed sequentially.
Authors: We agree that the recursive formulation is central to SLIDE's novelty. In the revised Section 3, we will explicitly state the recursive latency equations: let T_k denote the completion time of layer k; then T_k = max(T_{k-1} + d_k / b_k, C_{k-1}) + c_k / f_k, where d_k is layer size, b_k bandwidth, c_k compute demand, and f_k allocated compute rate, with T_0 = 0. This structure is strictly forward-recursive with no circularity, as each layer's inference begins only after its download completes and prior layers finish. We add a paragraph confirming that sequential on-device execution introduces no accuracy loss beyond standard model partitioning, as partial-layer inference is not performed. revision: yes
-
Referee: [§4] §4 (Algorithm): The polynomial-time complexity and optimality guarantee for the joint allocation problem must be supported by a formal proof or reduction (e.g., to a known solvable structure such as water-filling or dynamic programming); without it, the simulation gains cannot be attributed to the algorithm rather than heuristic tuning.
Authors: We acknowledge that the current manuscript asserts polynomial-time optimality without a self-contained proof. In the revised Section 4, we will add a formal proof by reduction to dynamic programming. The problem is solved by a DP table over layers and users that exploits the recursive latency structure, with state size O(K * U * R) where K is layers, U users, R discrete resource levels, yielding O(K U R^2) time. Optimality follows by induction: the subproblem optimum for the first k layers is preserved when extending to k+1 under the max-completion-time objective. This establishes that the reported simulation gains are due to the exact algorithm rather than tuning. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper formulates a joint optimization for throughput maximization under recursive per-layer latency dependencies, then presents a polynomial-time algorithm asserted to solve it optimally. No equation reduces to a prior fitted parameter or self-defined quantity by construction, no load-bearing self-citation chain is invoked, and the simulation results are presented as external validation rather than tautological confirmation. The recursive dependency structure is explicitly introduced as modeling novelty rather than smuggled in via prior work. The central claim therefore rests on independent formulation and algorithmic design rather than circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wireless downlink channel models and additive latency calculations for layer transmission and partial inference
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
recursive dependencies across layers, where inference latency depends recursively on the downloading bandwidth and computing resource allocation for each of the preceding layers
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
polynomial-time complexity O(K² + K I L_max)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Liu, L. Garcia, Z. Liu, B. Ou, and M. Srivastava, “SecDeep: Secure and performant on-device deep learning inference framework for mobile and IoT devices,” inProc. Int. Conf. Internet Things Des. Implement., Charlottesvle, V A, USA, May 2021, p. 67–79
work page 2021
-
[2]
S. Liu, D. Wen, D. Li, Q. Chen, G. Zhu, and Y . Shi, “Energy-efficient optimal mode selection for edge AI inference via integrated sensing- communication-computation,”IEEE Trans. Mobile Comput., vol. 23, no. 12, pp. 14 248–14 262, Dec. 2024
work page 2024
-
[3]
3GPP, “3rd generation partnership project; Technical specification group services and system aspects; Study on traffic characteristics and perfor- mance requirements for AI/ML model transfer in 5GS; (Release 18),” 3rd Generation Partnership Project (3GPP), Technical Specification (TS) 22.874, Dec. 2021, version 18.2.0
work page 2021
-
[4]
Green edge AI: A contemporary survey,
Y . Mao, X. Yu, K. Huang, Y .-J. A. Zhang, and J. Zhang, “Green edge AI: A contemporary survey,”Proc. IEEE, pp. 1–32, early access 2024
work page 2024
-
[5]
In-situ model downloading to realize versatile edge AI in 6G mobile networks,
K. Huang, H. Wu, Z. Liu, and X. Qi, “In-situ model downloading to realize versatile edge AI in 6G mobile networks,”IEEE Wireless Commun., vol. 30, no. 3, pp. 96–102, Jun. 2023
work page 2023
-
[6]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, Y . Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauthet al., “Gemini: A family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Notable site recognition using deep learning on mobile and crowd-sourced imagery,
J. Tan, A. Noulas, D. S ´aez, and R. Schifanella, “Notable site recognition using deep learning on mobile and crowd-sourced imagery,” inProc. 2020 21st IEEE Int. Conf. Mobile Data Manage. (MDM), Versailles, France, Aug. 2020, pp. 137–147
work page 2020
-
[8]
Sense4FL: Vehicular crowdsensing enhanced federated learning for autonomous driving,
Y . Ma, S. Hu, Z. Fang, Y . Ji, Y . Deng, and Y . Fang, “Sense4FL: Vehicular crowdsensing enhanced federated learning for autonomous driving,”arXiv preprint arXiv:2503.17697, 2025
-
[9]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), Apr. 2022, pp. 1–13
work page 2022
-
[10]
Efficient multiuser AI downloading via reusable knowledge broadcasting,
H. Wu, Q. Zeng, and K. Huang, “Efficient multiuser AI downloading via reusable knowledge broadcasting,”IEEE Trans. Wireless Commun., vol. 23, no. 8, pp. 10 459–10 472, Aug. 2024
work page 2024
-
[11]
AgentsCoMerge: Large language model empowered collabo- rative decision making for ramp merging,
S. Hu, Z. Fang, Z. Fang, Y . Deng, X. Chen, Y . Fang, and S. T. W. Kwong, “AgentsCoMerge: Large language model empowered collabo- rative decision making for ramp merging,”IEEE Trans. Mobile Comput., vol. 24, no. 10, pp. 9791–9805, Oct. 2025
work page 2025
-
[12]
Hong Kong mobile network experience report,
OPENSIGNAL, “Hong Kong mobile network experience report,”
-
[13]
Available: https://www.opensignal.com/reports/2023/11/ hongkong/mobile-network-experience
[Online]. Available: https://www.opensignal.com/reports/2023/11/ hongkong/mobile-network-experience
work page 2023
-
[14]
Characterizing resource heterogeneity in edge devices for deep learning inferences,
J. Hao, P. Subedi, I. K. Kim, and L. Ramaswamy, “Characterizing resource heterogeneity in edge devices for deep learning inferences,” inProc. 2021 Syst. Netw. Telemetry Anal. (SNTA), Jun. 2021, pp. 21– 24
work page 2021
-
[15]
FastDimeNet++: Training DimeNet++ in 22 minutes,
F. Zhu, M. Futrega, H. Bao, S. B. Eryilmaz, F. Kong, K. Duan, X. Zheng, N. Angel, M. Jouanneaux, M. Stadleret al., “FastDimeNet++: Training DimeNet++ in 22 minutes,” inProc. 52nd Int. Conf. Parallel Process., Salt Lake City, UT, USA, Aug. 2023, pp. 274–284
work page 2023
-
[16]
Pre-warming is not enough: Accelerating serverless inference with opportunistic pre-loading,
Y . Sui, H. Yu, Y . Hu, J. Li, and H. Wang, “Pre-warming is not enough: Accelerating serverless inference with opportunistic pre-loading,” in Proc. 2024 ACM Symp. Cloud Comput., Redmond, W A, USA, Nov. 2024, p. 178–195
work page 2024
-
[17]
3GPP, “3rd generation partnership project; Technical specification group radio access network; NR; Base station (BS) radio transmission and reception; (Release 18),” 3rd Generation Partnership Project (3GPP), Technical Specification (TS) 38.104, Dec. 2024, version 18.8.0
work page 2024
-
[18]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” Apr. 2009
work page 2009
-
[19]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV , USA, Jun. 2016, pp. 770–778
work page 2016
-
[20]
TrimCaching: Parameter- sharing AI model caching in wireless edge networks,
G. Qu, Z. Lin, F. Liu, X. Chen, and K. Huang, “TrimCaching: Parameter- sharing AI model caching in wireless edge networks,” inProc. IEEE Int. Conf. Distrib. Comput. Syst. (ICDCS), Jersey City, NJ, USA, Jul. 2024, pp. 36–46
work page 2024
-
[21]
Multiuser co- inference with batch processing capable edge server,
W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Multiuser co- inference with batch processing capable edge server,”IEEE Trans. Wireless Commun., vol. 22, no. 1, pp. 286–300, Jan. 2023
work page 2023
-
[22]
Optimal model placement and online model splitting for device-edge co-inference,
J. Yan, S. Bi, and Y .-J. A. Zhang, “Optimal model placement and online model splitting for device-edge co-inference,”IEEE Trans. Wireless Commun., vol. 21, no. 10, pp. 8354–8367, Oct. 2022
work page 2022
-
[23]
Improving device-edge cooperative inference of deep learning via 2-step pruning,
W. Shi, Y . Hou, S. Zhou, Z. Niu, Y . Zhang, and L. Geng, “Improving device-edge cooperative inference of deep learning via 2-step pruning,” inProc. IEEE Conf. Comput. Commun. Workshops (INFOCOM WK- SHPS), Paris, France, Jul. 2019, pp. 1–6
work page 2019
-
[24]
A survey on quality of experience of HTTP adaptive streaming,
M. Seufert, S. Egger, M. Slanina, T. Zinner, T. Hoßfeld, and P. Tran-Gia, “A survey on quality of experience of HTTP adaptive streaming,”IEEE Commun. Surveys Tuts., vol. 17, no. 1, pp. 469–492, 1st Quart. 2014
work page 2014
-
[25]
Measuring the quality of experience of HTTP video streaming,
R. K. P. Mok, E. W. W. Chan, and R. K. C. Chang, “Measuring the quality of experience of HTTP video streaming,” inProc. IFIP/IEEE Int. Symp. Integrated Netw. Manag. (IM 2011) and Workshops, Dublin, Ireland, May 2011, pp. 485–492
work page 2011
-
[26]
Streaming video over HTTP with consistent quality,
Z. Li, A. C. Begen, J. Gahm, Y . Shan, B. Osler, and D. Oran, “Streaming video over HTTP with consistent quality,” inProc. 5th ACM Multimedia Syst. Conf., Singapore, Singapore, Mar. 2014, p. 248–258
work page 2014
-
[27]
A control-theoretic approach for dynamic adaptive video streaming over HTTP,
X. Yin, A. Jindal, V . Sekar, and B. Sinopoli, “A control-theoretic approach for dynamic adaptive video streaming over HTTP,” inProc. 2015 ACM Conf. Spec. Interest Group Data Commun. (SIGCOMM), London United Kingdom, Aug. 2015, pp. 325–338
work page 2015
-
[28]
J. Peng, Z. Cao, H. Qu, Z. Zhang, C. Guo, Y . Zhang, Z. Cao, and T. Chen, “Harnessing your DRAM and SSD for sustainable and ac- cessible LLM inference with mixed-precision and multi-level caching,” arXiv preprint arXiv:2410.14740, 2024
-
[29]
S. Bhattacharya and N. D. Lane, “Sparsification and separation of deep learning layers for constrained resource inference on wearables,” inProc. 14th ACM Conf. Embedded Netw. Sens. Syst. CD-ROM, Stanford, CA, USA, Nov. 2016, pp. 176–189
work page 2016
-
[30]
FlexNN: Efficient and adaptive DNN inference on memory-constrained edge devices,
X. Li, Y . Li, Y . Li, T. Cao, and Y . Liu, “FlexNN: Efficient and adaptive DNN inference on memory-constrained edge devices,” inProc. 30th Annu. Int. Conf. Mobile Comput. Netw., Washington D.C., DC, USA, May 2024, p. 709–723
work page 2024
-
[31]
The larger the merrier? Efficient large AI model inference in wireless edge networks,
Z. Lyu, M. Xiao, J. Xu, M. Skoglund, and M. D. Renzo, “The larger the merrier? Efficient large AI model inference in wireless edge networks,” IEEE J. Sel. Areas Commun., pp. 1–15, early access 2025
work page 2025
-
[32]
Techpowerup, “NVIDIA GeForce RTX 4090,” 2022. [Online]. Available: https://www.techpowerup.com/gpu-specs/geforce-rtx-4090.c3889
work page 2022
- [33]
-
[34]
iGniter: Interference-aware GPU resource provisioning for predictable DNN inference in the cloud,
F. Xu, J. Xu, J. Chen, L. Chen, R. Shang, Z. Zhou, and F. Liu, “iGniter: Interference-aware GPU resource provisioning for predictable DNN inference in the cloud,”IEEE Trans. Parallel Distrib. Syst., vol. 34, no. 3, pp. 812–827, Mar. 2023
work page 2023
-
[35]
Efficient parallel split learning over resource-constrained wireless edge networks,
Z. Lin, G. Zhu, Y . Deng, X. Chen, Y . Gao, K. Huang, and Y . Fang, “Efficient parallel split learning over resource-constrained wireless edge networks,”IEEE Trans. Mobile Comput., vol. 23, no. 10, pp. 9224–9239, Oct. 2024
work page 2024
-
[36]
Q. Zeng, Y . Du, K. Huang, and K. K. Leung, “Energy-efficient resource management for federated edge learning with CPU-GPU heterogeneous computing,”IEEE Trans. Wireless Commun., vol. 20, no. 12, pp. 7947– 7962, Dec. 2021
work page 2021
-
[37]
Evaluating and analyzing the energy efficiency of CNN inference on high-performance GPU,
C. Yao, W. Liu, W. Tang, J. Guo, S. Hu, Y . Lu, and W. Jiang, “Evaluating and analyzing the energy efficiency of CNN inference on high-performance GPU,”Concurr. Comput.: Pract. Exper., vol. 33, no. 6, p. e6064, Oct. 2021
work page 2021
-
[38]
Power- efficient time-sensitive mapping in heterogeneous systems,
C. Liu, J. Li, W. Huang, J. Rubio, E. Speight, and X. Lin, “Power- efficient time-sensitive mapping in heterogeneous systems,” inProc. Int. Conf. Parallel Archit. and Compilation Tech. (PACT), Minneapolis, MN, USA, Sep. 2012, pp. 23–32
work page 2012
-
[39]
Learning-based resource allocation for backscatter- aided vehicular networks,
W. U. Khan, T. N. Nguyen, F. Jameel, M. A. Jamshed, H. Pervaiz, M. A. Javed, and R. J¨antti, “Learning-based resource allocation for backscatter- aided vehicular networks,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 10, pp. 19 676–19 690, Oct. 2022
work page 2022
-
[40]
T. E. Bogale, X. Wang, and L. B. Le, “Adaptive channel prediction, beamforming and scheduling design for 5G V2I network: Analytical and machine learning approaches,”IEEE Trans. Veh. Technol., vol. 69, no. 5, pp. 5055–5067, May 2020
work page 2020
-
[41]
X. Duan, Y . Liu, and X. Wang, “SDN enabled 5G-V ANET: Adaptive vehicle clustering and beamformed transmission for aggregated traffic,” IEEE Commun. Mag., vol. 55, no. 7, pp. 120–127, Jul. 2017
work page 2017
-
[42]
Delay-based maximum power-weight scheduling with heavy-tailed traffic,
S.-C. Lin, P. Wang, I. F. Akyildiz, and M. Luo, “Delay-based maximum power-weight scheduling with heavy-tailed traffic,”IEEE/ACM Trans. Netw., vol. 25, no. 4, pp. 2540–2555, Aug. 2017
work page 2017
-
[43]
A tutorial on decomposition methods for network utility maximization,
D. Palomar and M. Chiang, “A tutorial on decomposition methods for network utility maximization,”IEEE J. Sel. Areas Commun., vol. 24, no. 8, pp. 1439–1451, Aug. 2006
work page 2006
-
[44]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jegou, “Training data-efficient image transformers & distillation through attention,” inProc. 38th Int. Conf. Mach. Learn. (ICML), vol. 139, Jul. 2021, pp. 10 347–10 357
work page 2021
-
[45]
Data sheet nvidia jetson orin NX series,
NVIDIA, “Data sheet nvidia jetson orin NX series,” 2022. [Online]. Available: https://connecttech.com/ftp/pdf/jetson orin nx datasheet.pdf
work page 2022
-
[46]
Data sheet nvidia jetson orin nano series,
NVIDIA, “Data sheet nvidia jetson orin nano series,” 2022. [Online]. Available: https://connecttech.com/ftp/pdf/nvidia jetson orin datasheet. pdf
work page 2022
-
[47]
Nesterov,Introductory lectures on convex optimization: A basic course, 1st ed., ser
Y . Nesterov,Introductory lectures on convex optimization: A basic course, 1st ed., ser. Applied Optimization. New York, NY , USA: Springer Science & Business Media, 2013, vol. 87. 1 APPENDIXA PROOF OFPROPOSITION1 Wheny k = 0, constraint (11d) inP2enforcesˆz k,li = 0, which aligns with the computing resource allocation inP1un- der the same condition. When...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.