UniRec: Unified Multimodal Encoding for LLM-Based Recommendations
Pith reviewed 2026-05-16 10:48 UTC · model grok-4.3
The pith
UniRec unifies four modalities with triplets and hierarchical modeling so LLMs can process heterogeneous recommendation signals including nested user histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
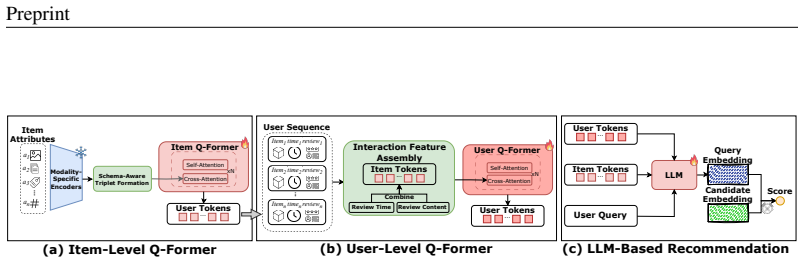
UniRec formalizes recommendation features into text, images, categorical features, and numerical attributes, then employs modality-specific encoders to produce consistent embeddings, adopts a triplet representation of attribute name, type, and value to separate schema from raw inputs and preserve semantic distinctions, and applies a hierarchical Q-Former to model the nested structure of user interactions while maintaining their layered organization.
What carries the argument
Triplet representation of each attribute together with the hierarchical Q-Former that models nested user-interaction sequences.
Load-bearing premise
That modality-specific encoders plus the triplet format and hierarchical Q-Former can resolve both inter-modality and intra-modality ambiguities and preserve nested history structure without introducing new information loss or overfitting.
What would settle it
A controlled test in which removing the triplet representation or the hierarchical Q-Former causes accuracy to fall below existing state-of-the-art multimodal recommenders on the same benchmarks, or in which models still confuse the semantics of different numerical attributes such as price versus rating.
Figures


read the original abstract
Large language models have recently shown promise for multimodal recommendation, particularly with text and image inputs. Yet real-world recommendation signals extend far beyond these modalities. To reflect this, we formalize recommendation features into four modalities: text, images, categorical features, and numerical attributes, and highlight the unique challenges this heterogeneity poses for LLMs in understanding multimodal information. In particular, these challenges arise not only across modalities but also within them, as attributes such as price, rating, and time may all be numeric yet carry distinct semantic meanings. Beyond this intra-modality ambiguity, another major challenge is the nested structure of recommendation signals, where user histories are sequences of items, each associated with multiple attributes. To address these challenges, we propose UniRec, a unified multimodal encoder for LLM-based recommendation. UniRec first employs modality-specific encoders to produce consistent embeddings across heterogeneous signals. It then adopts a triplet representation, comprising attribute name, type, and value, to separate schema from raw inputs and preserve semantic distinctions. Finally, a hierarchical Q-Former models the nested structure of user interactions while maintaining their layered organization. Across multiple real-world benchmarks, UniRec outperforms state-of-the-art multimodal and LLM-based recommenders by up to 15%, and extensive ablation studies further validate the contributions of each component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniRec, a unified multimodal encoder for LLM-based recommendations. It formalizes recommendation features into four modalities (text, images, categorical features, numerical attributes) and addresses inter- and intra-modality ambiguities plus the nested structure of user histories via modality-specific encoders, a triplet representation (attribute name, type, value), and a hierarchical Q-Former. The central claim is that this architecture outperforms state-of-the-art multimodal and LLM-based recommenders by up to 15% across multiple real-world benchmarks, with ablation studies validating each component.
Significance. If the reported gains prove robust, the work would advance multimodal LLM-based recommendation by offering a practical encoding scheme for heterogeneous signals that preserves semantic distinctions and nested history structure. The extensive ablation studies are a positive feature, as they provide direct empirical support for the contribution of the triplet representation and hierarchical Q-Former.
major comments (2)
- [§4] §4 (Experiments): The abstract and high-level description report up to 15% gains and ablation results, but the manuscript provides no error bars, number of runs, data-split details, or statistical significance tests; this is load-bearing for the central performance claim and leaves the improvements only partially verifiable.
- [§3.3] §3.3 (Hierarchical Q-Former): The description of how the module models nested user-item-attribute structure while avoiding new information loss or overfitting is high-level; without a formal equation, pseudocode, or complexity analysis, it is difficult to assess whether the design resolves the stated intra-modality ambiguities without introducing new hyperparameters that could affect generalization.
minor comments (2)
- The abstract mentions 'real-world benchmarks' but does not name them; adding the specific dataset names (e.g., Amazon, MovieLens variants) would improve clarity.
- [§3.2] Notation for the triplet embedding and Q-Former inputs could be standardized with a single equation or table to avoid ambiguity between 'type' and 'value' fields.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and have updated the manuscript to improve clarity and verifiability of the results.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The abstract and high-level description report up to 15% gains and ablation results, but the manuscript provides no error bars, number of runs, data-split details, or statistical significance tests; this is load-bearing for the central performance claim and leaves the improvements only partially verifiable.
Authors: We agree that the absence of these details limits full verification of the performance claims. In the revised manuscript, we have added error bars from 5 independent runs with different random seeds, explicit data-split protocols (temporal splits for sequential tasks and random splits for others), and paired t-test results confirming statistical significance (p < 0.05) of the reported gains. These updates appear in Section 4.2 and the supplementary material. revision: yes
-
Referee: [§3.3] §3.3 (Hierarchical Q-Former): The description of how the module models nested user-item-attribute structure while avoiding new information loss or overfitting is high-level; without a formal equation, pseudocode, or complexity analysis, it is difficult to assess whether the design resolves the stated intra-modality ambiguities without introducing new hyperparameters that could affect generalization.
Authors: We acknowledge that the original description was insufficiently formal. The revised Section 3.3 now includes a mathematical formulation (Equation 3) defining the hierarchical query mechanism, pseudocode in Appendix Algorithm 1, and a complexity analysis of O(N) where N is the total number of attributes across the history. We also added a hyperparameter sensitivity study in the ablation section demonstrating stable performance across reasonable ranges of query tokens and layers, supporting generalization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical architecture (modality-specific encoders, triplet encoding, hierarchical Q-Former) and reports performance gains on external real-world benchmarks plus ablation studies. No equations, derivations, or first-principles predictions appear in the provided text; all central claims are positioned as measured outcomes on held-out data rather than algebraic reductions to fitted parameters or self-citations. The work is therefore self-contained against external benchmarks with no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modality-specific encoders can produce consistent embeddings across heterogeneous signals
invented entities (2)
-
Triplet representation (attribute name, type, value)
no independent evidence
-
Hierarchical Q-Former
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UniRec first employs modality-specific encoders... triplet representation... hierarchical Q-Former models the nested structure
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
schema-aware triplet... Jcost not mentioned anywhere
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tallrec: Teaching large language models to recom- mend.arXiv preprint arXiv:2305.12366,
Yu Bao, Yujie Li, Hu Xu, Xiangnan He, et al. Tallrec: Teaching large language models to recom- mend.arXiv preprint arXiv:2305.12366,
-
[2]
doi:10.48550/arXiv.2207.08815 , urldate =
Y . Cheng et al. Representation learning for tabular and multimodal data: A survey.arXiv preprint arXiv:2207.08815,
-
[3]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys 2022), pp. 299–315. ACM,
work page 2022
-
[4]
VIP5: Towards multi- modal foundation models for recommendation
Shijie Geng, Juntao Tan, Shuchang Liu, Zuohui Fu, and Yongfeng Zhang. VIP5: Towards multi- modal foundation models for recommendation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 9606–9620. Association for Computational Linguistics,
work page 2023
-
[5]
A survey on large language models for recommendation.arXiv preprint arXiv:2305.19860,
10 Preprint Yuwei Hou et al. A survey on large language models for recommendation.arXiv preprint arXiv:2305.19860,
-
[6]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. InProceedings of the 2018 IEEE International Conference on Data Mining (ICDM), pp. 197–206,
work page 2018
-
[7]
Jinming Li, Wentao Zhang, Tian Wang, Guanglei Xiong, Alan Lu, and Gerard Medioni. GPT4Rec: A generative framework for personalized recommendation and user interests interpretation. In SIGIR eCom, 2023a. Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large langu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Multimodal recommender systems: A survey.arXiv preprint arXiv:2302.03883, 2023a
Qidong Liu, Jiaxi Hu, Yutian Xiao, Jingtong Gao, and Xiangyu Zhao. Multimodal recommender systems: A survey.arXiv preprint arXiv:2302.03883, 2023a. Tie-Yan Liu. Learning to rank for information retrieval. InFoundations and Trends in Information Retrieval,
-
[9]
Xiao Liu et al. Mmrec: Bridging language and vision for recommendation with multimodal language models.arXiv preprint arXiv:2304.03667, 2023b. Alejo L´opez- ´Avila and Jinhua Du. A survey on large language models in multimodal recommender systems.arXiv preprint arXiv:2505.09777,
-
[10]
Yucong Luo, Qitao Qin, Hao Zhang, Mingyue Cheng, Ruiran Yan, Kefan Wang, and Jie Ouyang. Molar: Multimodal llms with collaborative filtering alignment for enhanced sequential recom- mendation.arXiv preprint arXiv:2412.18176,
-
[11]
Representation Learning with Contrastive Predictive Coding
Wei Tao et al. M3r: Memory-augmented multi-modal recommendation. InCIKM, 2022a. 11 Preprint Zhiwei Tao, Xiao Liu, Yingxue Xia, Xiang Wang, Ling-Yu Yang, Xiangnan Huang, and Tat-Seng Chua. Self-supervised learning for multimedia recommendation.IEEE Transactions on Multime- dia, 2022b. A¨aron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learnin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Chunfeng Wei, Liqiang Nie, Xiang Li, and et al
doi: 10.1038/s41598-025-14251-1. Chunfeng Wei, Liqiang Nie, Xiang Li, and et al. Mmgcn: Multi-modal graph convolution network for personalized recommendation. InSIGIR, 2019a. Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. Mmgcn: Multi-modal graph convolution network for personalized recommendation of micro-video. In Pro...
-
[13]
NoteLLM-2: Multimodal large representation models for recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Xiangyu Zhao, Yan Gao, Yao Hu, and Enhong Chen. NoteLLM-2: Multimodal large representation models for recommendation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’25), 2025a. Sheng Zhang et al. Prompt4rec: Pre-train and prompt for sequential recommendatio...
-
[14]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advanc- ing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025b. Hongyu Zhou, Xin Zhou, Zhiwei Zeng, Lingzi Zhang, and Zhiqi Shen. A comprehensi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Xin Zhou, Hongyu Zhou, Yong Liu, Zhiwei Zeng, Chunyan Miao, Pengwei Wang, Yuan You, and Feijun Jiang. Bootstrap latent representations for multi-modal recommendation. InProceedings of the ACM web conference 2023, pp. 845–854, 2023b. A ENCODERIMPLEMENTATIONDETAILS TEXTENCODER We employ the Qwen3-0.6B embedding model (Zhang et al., 2025b), an instruction-tu...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.