Ira: Efficient Transaction Replay for Distributed Systems
Pith reviewed 2026-05-16 10:12 UTC · model grok-4.3
The pith
Sending compact hints of access patterns from primary to backups speeds up transaction replay 25 times in Ethereum systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ira demonstrates that the primary can generate and send compact hints encoding the working set of keys and their storage tables after executing a block, enabling backups to perform efficient prefetching during replay. This yields a median 25x per-block speedup and reduces total replay time from 6.5 hours to 16 minutes with 16 threads.
What carries the argument
The hint structure that captures the working set of keys accessed in a transaction batch along with one byte of table metadata per key to guide cache prefetching on backups.
Load-bearing premise
The access patterns observed by the primary after execution can be accurately predicted and encoded in compact hints that backups can use without causing extra I/O or prediction mistakes.
What would settle it
Observing whether backups with hints execute blocks correctly and faster than without them on the same Ethereum mainnet trace, or if hint-induced cache misses increase execution time.
Figures














read the original abstract
In primary-backup replication, consensus latency is bounded by the time for backup nodes to replay (re-execute) transactions proposed by the primary. In this work, we present Ira, a framework to accelerate backup replay by transmitting compact \emph{hints} alongside transaction batches. Our key insight is that the primary, having already executed transactions, possesses knowledge of future access patterns which is exactly the information needed for optimal replay. We use Ethereum for our case study and present a concrete protocol, Ira-L, within our framework to improve cache management of Ethereum block execution. The primaries implementing Ira-L provide hints that consist of the working set of keys used in an Ethereum block and one byte of metadata per key indicating the table to read from, and backups use these hints for efficient block replay. We evaluated Ira-L against the state-of-the-art Ethereum client reth over two weeks of Ethereum mainnet activity ($100,800$ blocks containing over $24$ million transactions). Our hints are compact, adding a median of $47$ KB compressed per block ($\sim5\%$ of block payload). We observe that the sequential hint generation and block execution imposes a $28.6\%$ wall-time overhead on the primary, though the direct cost from hints is $10.9\%$ of execution time; all of which can be pipelined and parallelized in production deployments. On the backup side, we observe that Ira-L achieves a median per-block speedup of $25\times$ over baseline reth. With $16$ prefetch threads, aggregate replay time drops from $6.5$ hours to $16$ minutes ($23.6\times$ wall-time speedup).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ira, a framework for accelerating transaction replay in primary-backup replication by transmitting compact post-execution hints from the primary to backups. In the Ethereum case study (Ira-L), hints encode the working-set keys plus one byte of table metadata per key. Evaluation on 100,800 real mainnet blocks (24M+ transactions) reports median 47 KB compressed hints per block, 28.6% primary overhead (10.9% direct), and 25× median per-block speedup over reth; with 16 prefetch threads aggregate replay time falls from 6.5 h to 16 min (23.6× wall-time reduction).
Significance. If the measured speedups prove robust, the work offers a practical, low-overhead technique to reduce replay latency in replicated ledgers without altering consensus. The exact (post-execution) nature of the hints avoids prediction error, the large real-world trace strengthens external validity, and the quantified primary cost shows the approach is deployable. The result is relevant to high-throughput blockchain clients and other primary-backup systems where replay is the bottleneck.
major comments (1)
- [§5] §5 (Evaluation): The reported 25× median per-block and 23.6× aggregate speedups are presented without statistical significance tests, per-block variance, or explicit controls for measurement artifacts (cache state, I/O scheduling, prefetch-thread scaling). These omissions make it difficult to assess whether the central empirical claim is load-bearing or sensitive to experimental conditions.
minor comments (2)
- [Abstract] Abstract: The phrase 'optimal replay' should be qualified; the speedup is relative to the reth baseline under the specific hint-driven prefetching scheme rather than a theoretical optimum.
- [§4.2] §4.2: The description of hint compression and encoding would benefit from an explicit size breakdown (keys vs. metadata) to allow readers to reproduce the 47 KB median figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We appreciate the recognition of the work's practical relevance. We address the single major comment on the evaluation below, and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The reported 25× median per-block and 23.6× aggregate speedups are presented without statistical significance tests, per-block variance, or explicit controls for measurement artifacts (cache state, I/O scheduling, prefetch-thread scaling). These omissions make it difficult to assess whether the central empirical claim is load-bearing or sensitive to experimental conditions.
Authors: We agree that additional statistical analysis and experimental controls would strengthen the presentation. In the revised manuscript we will augment §5 with: (1) per-block speedup distributions showing median, interquartile range, and 5th/95th percentiles across all 100,800 blocks to quantify variance; (2) results from repeated runs under flushed-cache and varied I/O-scheduler conditions to address measurement artifacts; (3) full prefetch-thread scaling curves (1–32 threads) with both per-block and aggregate wall-time numbers; and (4) Wilcoxon signed-rank tests on paired per-block execution times confirming statistical significance of the speedups (p ≪ 0.001). These additions will be included in the next version. revision: yes
Circularity Check
No significant circularity; empirical measurements of implemented system
full rationale
The paper reports direct wall-time benchmarks of an implemented primary-backup protocol (Ira-L) on 100800 real Ethereum mainnet blocks. Hints are generated from actual post-execution key sets rather than any fitted model or prediction; primary overhead and backup speedups are measured quantities with no equations, uniqueness theorems, or self-citations invoked to derive the reported 25× median per-block or 23.6× aggregate speedups. All load-bearing claims rest on external execution traces and timing instrumentation, making the evaluation self-contained against real workloads.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Primary nodes possess accurate knowledge of future access patterns after executing transactions.
Reference graph
Works this paper leans on
- [1]
-
[2]
The Aptos Blockchain: Safe, Scalable, and Upgradeable Web3 Infrastructure
-
[3]
Certification-Based Replication | Galera Cluster | Mari- aDB Documentation
-
[4]
Cosmos Stack Developer Documentation. 14
-
[5]
Erigon/eth/stagedsync/README.md at release/2.60 · erigontech/erigon
-
[6]
Eth/63 fast synchronization algorithm by karalabe · Pull Request #1889·ethereum/go-ethereum
-
[7]
Introduction | Monad Developer Documentation
-
[8]
Libmdbx: One of the fastest embeddable key-value en- gine
-
[9]
Madvise(2) - Linux manual page
-
[10]
MySQL :: MySQL 8.0 Reference Manual :: 20 Group Replication
-
[11]
Posix_fadvise(2) - Linux manual page
-
[12]
The Sui Smart Contracts Platform
- [13]
- [14]
-
[15]
Sei Parallelization Engine: Multi-core Blockchain Exe- cution | Sei Docs, January 2026
work page 2026
-
[16]
Hy- perledger Fabric: A Distributed Operating System for Permissioned Blockchains
Elli Androulaki, Artem Barger, Vita Bortnikov, Chris- tian Cachin, Konstantinos Christidis, Angelo De Caro, David Enyeart, Christopher Ferris, Gennady Laventman, Yacov Manevich, Srinivasan Muralidharan, Chet Murthy, Binh Nguyen, Manish Sethi, Gari Singh, Keith Smith, Alessandro Sorniotti, Chrysoula Stathakopoulou, Marko Vukoli´c, Sharon Weed Cocco, and Ja...
-
[17]
Socrates: The New SQL Server in the Cloud
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. Socrates: The New SQL Server in the Cloud. InProceed...
work page 2019
-
[18]
L. A. Belady. A study of replacement algorithms for a virtual-storage computer. 5(2):78–101
- [19]
-
[20]
Sui Lutris: A Blockchain Combining Broadcast and Consensus, Oc- tober 2024
Sam Blackshear, Andrey Chursin, George Danezis, Anastasios Kichidis, Lefteris Kokoris-Kogias, Xun Li, Mark Logan, Ashok Menon, Todd Nowacki, Alberto Sonnino, Brandon Williams, and Lu Zhang. Sui Lutris: A Blockchain Combining Broadcast and Consensus, Oc- tober 2024
work page 2024
-
[21]
The latest gossip on BFT consensus
Ethan Buchman, Jae Kwon, and Zarko Milosevic. The latest gossip on BFT consensus
-
[22]
Forerunner: Constraint-based Speculative Transaction Execution for Ethereum
Yang Chen, Zhongxin Guo, Runhuai Li, Shuo Chen, Lidong Zhou, Yajin Zhou, and Xian Zhang. Forerunner: Constraint-based Speculative Transaction Execution for Ethereum. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, SOSP ’21, pages 570–587, New York, NY , USA, October 2021. Association for Computing Machinery
work page 2021
-
[23]
KuaFu: Closing the paral- lelism gap in database replication
Chuntao Hong, Dong Zhou, Mao Yang, Carbo Kuo, Lin- tao Zhang, and Lidong Zhou. KuaFu: Closing the paral- lelism gap in database replication. In2013 IEEE 29th International Conference on Data Engineering (ICDE), pages 1186–1195. IEEE
-
[24]
Zstandard - Real-time data compression algorithm
Facebook. Zstandard - Real-time data compression algorithm
-
[25]
Jose M. Faleiro and Daniel J. Abadi. Rethinking se- rializable multiversion concurrency control, December 2015
work page 2015
-
[26]
Jose M. Faleiro, Daniel J. Abadi, and Joseph M. Heller- stein. High performance transactions via early write visi- bility.Proceedings of the VLDB Endowment, 10(5):613– 624, January 2017
work page 2017
- [27]
-
[28]
DeepPrefetcher: A Deep Learning Framework for Data Prefetching in Flash Stor- age Devices
Gaddisa Olani Ganfure, Chun-Feng Wu, Yuan-Hao Chang, and Wei-Kuan Shih. DeepPrefetcher: A Deep Learning Framework for Data Prefetching in Flash Stor- age Devices. 39(11):3311–3322
-
[29]
Xiongzi Ge, Zhichao Cao, David H. C. Du, Pradeep Ganesan, and Dennis Hahn. HintStor: A Framework to Study I/O Hints in Heterogeneous Storage. 18(2):18:1– 18:24
-
[30]
Block-STM: Scaling Blockchain Ex- ecution by Turning Ordering Curse to a Performance Blessing
Rati Gelashvili, Alexander Spiegelman, Zhuolun Xiang, George Danezis, Zekun Li, Yu Xia, Runtian Zhou, and Dahlia Malkhi. Block-STM: Scaling Blockchain Ex- ecution by Turning Ordering Curse to a Performance Blessing
-
[31]
Dissecting the EIP-2930 Optional Access Lists, December 2023
Lioba Heimbach, Quentin Kniep, Yann V onlanthen, Roger Wattenhofer, and Patrick Züst. Dissecting the EIP-2930 Optional Access Lists, December 2023. 15
work page 2023
-
[32]
TiDB: A Raft-based HTAP database.Proceedings of the VLDB Endowment, 13(12):3072–3084, August 2020
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. TiDB: A Raft-based HTAP database.Proceedings of the VLDB Endowment, 13(12):3072–3084, August 2020
work page 2020
-
[33]
Patrick Hunt, Mahadev Konar, Flavio P. Junqueira, and Benjamin Reed. ZooKeeper: Wait-free coordination for internet-scale systems. InProceedings of the 2010 USENIX Conference on USENIX Annual Technical Con- ference, USENIXATC’10, page 11. USENIX Associa- tion
work page 2010
-
[34]
Back to the future: Lever- aging Belady’s algorithm for improved cache replace- ment
Akanksha Jain and Calvin Lin. Back to the future: Lever- aging Belady’s algorithm for improved cache replace- ment. 44(3):78–89
-
[35]
Rethinking Belady’s Algorithm to Accommodate Prefetching
Akanksha Jain and Calvin Lin. Rethinking Belady’s Algorithm to Accommodate Prefetching. In2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 110–123
-
[36]
Song Jiang and Xiaodong Zhang. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance. 30(1):31–42
-
[37]
Flavio P. Junqueira, Benjamin C. Reed, and Marco Ser- afini. Zab: High-performance broadcast for primary- backup systems. InProceedings of the 2011 IEEE/IFIP 41st International Conference on Dependable Sys- tems&Networks, DSN ’11, pages 245–256. IEEE Com- puter Society
work page 2011
-
[38]
H. T. Kung and John T. Robinson. On optimistic meth- ods for concurrency control.ACM Transactions on Database Systems, 6(2):213–226, June 1981
work page 1981
- [39]
- [40]
-
[41]
Yi Lu, Xiangyao Yu, Lei Cao, and Samuel Madden. Aria: A fast and practical deterministic OLTP database.Pro- ceedings of the VLDB Endowment, 13(12):2047–2060, August 2020
work page 2047
-
[42]
Using Hints to Improve Inline Block-layer Deduplication
Sonam Mandal, Geoff Kuenning, Dongju Ok, Varun Shastry, Philip Shilane, Sun Zhen, Vasily Tarasov, and Erez Zadok. Using Hints to Improve Inline Block-layer Deduplication. pages 315–322
-
[43]
R.L. Mattson, J. Gecsei, D. R. Slutz, and I. L. Traiger. Evaluation techniques for storage hierarchies. 9(2):78– 117
-
[44]
Nimrod Megiddo and Dharmendra S. Modha. {ARC}: A {Self-Tuning}, Low Overhead Replacement Cache
-
[45]
Repeating History Beyond ARIES.VLDB, 99:7–10, September 1999
C Mohan. Repeating History Beyond ARIES.VLDB, 99:7–10, September 1999
work page 1999
-
[46]
Mohan, Don Haderle, Bruce Lindsay, Hamid Pira- hesh, and Peter Schwarz
C. Mohan, Don Haderle, Bruce Lindsay, Hamid Pira- hesh, and Peter Schwarz. ARIES: A transaction re- covery method supporting fine-granularity locking and partial rollbacks using write-ahead logging.ACM Trans. Database Syst., 17(1):94–162, March 1992
work page 1992
-
[47]
Todd C. Mowry, Monica S. Lam, and Anoop Gupta. De- sign and evaluation of a compiler algorithm for prefetch- ing. 27(9):62–73
-
[48]
Phase Reconciliation for Contended In-Memory Transactions
Neha Narula, Cody Cutler, Eddie Kohler, and Robert Morris. Phase Reconciliation for Contended In-Memory Transactions. In11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), pages 511–524, 2014
work page 2014
-
[49]
Diego Ongaro and John Ousterhout. In Search of an Understandable Consensus Algorithm.Proceedings of USENIX ATC ’14: 2014 USENIX Annual Technical Conference., June 2014
work page 2014
-
[50]
R. H. Patterson, G. A. Gibson, E. Ginting, D. Stodol- sky, and J. Zelenka. Informed prefetching and caching. InProceedings of the Fifteenth ACM Symposium on Operating Systems Principles, SOSP ’95, pages 79–95. Association for Computing Machinery
-
[51]
EIP-2930: Optional access lists
Ethereum Improvement Proposals. EIP-2930: Optional access lists
-
[52]
Fred B Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial.ACM Computing Surveys, 22(4):299–319, December 1990
work page 1990
-
[53]
Effective Mimicry of Belady’s MIN Policy
Ishan Shah, Akanksha Jain, and Calvin Lin. Effective Mimicry of Belady’s MIN Policy. In2022 IEEE Inter- national Symposium on High-Performance Computer Architecture (HPCA), pages 558–572
-
[54]
Applying Deep Learning to the Cache Replace- ment Problem
Zhan Shi, Xiangru Huang, Akanksha Jain, and Calvin Lin. Applying Deep Learning to the Cache Replace- ment Problem. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchi- tecture, MICRO-52, pages 413–425. Association for Computing Machinery
-
[55]
A hierarchical neural model of data prefetching
Zhan Shi, Akanksha Jain, Kevin Swersky, Milad Hashemi, Parthasarathy Ranganathan, and Calvin Lin. A hierarchical neural model of data prefetching. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’21, pages 861–873. Association for Computing Machinery. 16
-
[56]
CockroachDB: The Resilient Geo-Distributed SQL Database
Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan Van- Benschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaf- fray, Lucy Zhang, and Peter Mattis. CockroachDB: The Resilient Geo-Distributed SQL Database. InPro- ceedings of the 2020 ACM SIGMOD Internationa...
work page 2020
-
[57]
Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, Philip Shao, and Daniel J. Abadi. Calvin: Fast distributed transactions for partitioned database systems. InProceedings of the 2012 ACM SIGMOD International Conference on Management of Data, SIGMOD ’12, pages 1–12. Association for Com- puting Machinery
work page 2012
-
[58]
Speedy transactions in multicore in-memory databases
Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. Speedy transactions in multicore in-memory databases. InProceedings of the Twenty-F ourth ACM Symposium on Operating Sys- tems Principles, SOSP ’13, pages 18–32, New York, NY , USA, November 2013. Association for Computing Machinery
work page 2013
-
[59]
Amazon Aurora: Design Consid- erations for High Throughput Cloud-Native Relational Databases
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Mu- rali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. Amazon Aurora: Design Consid- erations for High Throughput Cloud-Native Relational Databases. InProceedings of the 2017 ACM Interna- tional Conference on Management of Data, SIGMO...
work page 2017
-
[60]
Giuseppe Vietri, Liana V . Rodriguez, Wendy A. Mar- tinez, Steven Lyons, Jason Liu, Raju Rangaswami, Ming Zhao, and Giri Narasimhan. Driving cache replacement with ML-based LeCaR. InProceedings of the 10th USENIX Conference on Hot Topics in Storage and File Systems, HotStorage’18, page 3. USENIX Association
-
[61]
Ethereum: A secure decentralised gener- alised transaction ledger
Gavin Wood. Ethereum: A secure decentralised gener- alised transaction ledger. pages 1–32
-
[62]
Carole-Jean Wu, Aamer Jaleel, Will Hasenplaugh, Mar- garet Martonosi, Simon C. Steely, and Joel Emer. SHiP: Signature-based hit predictor for high performance caching. InProceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, pages 430–441. ACM
-
[63]
Carole-Jean Wu, Aamer Jaleel, Margaret Martonosi, Si- mon C. Steely, and Joel Emer. PACMan: Prefetch-aware cache management for high performance caching. In Proceedings of the 44th Annual IEEE/ACM Interna- tional Symposium on Microarchitecture, pages 442–453. ACM
-
[64]
Solana: A new architecture for a high performance blockchain
Anatoly Yakovenko. Solana: A new architecture for a high performance blockchain. 2025
work page 2025
-
[65]
Xinjun Yang, Yingqiang Zhang, Hao Chen, Chuan Sun, Feifei Li, and Wenchao Zhou. PolarDB-SCC: A Cloud- Native Database Ensuring Low Latency for Strongly Consistent Reads.Proceedings of the VLDB Endow- ment, 16(12):3754–3767, August 2023
work page 2023
-
[66]
SGDP: A Stream-Graph Neural Network Based Data Prefetcher
Yiyuan Yang, Rongshang Li, Qiquan Shi, Xijun Li, Gang Hu, Xing Li, and Mingxuan Yuan. SGDP: A Stream-Graph Neural Network Based Data Prefetcher
-
[67]
Reiter, Guy Golan Gueta, and Ittai Abraham
Maofan Yin, Dahlia Malkhi, Michael K. Reiter, Guy Golan Gueta, and Ittai Abraham. HotStuff: BFT Consensus with Linearity and Responsiveness. InPro- ceedings of the 2019 ACM Symposium on Principles of Distributed Computing, PODC ’19, pages 347–356. Association for Computing Machinery
work page 2019
-
[68]
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Nama- sivayam, Alex Miller, Evan Tschannen, Steve Ather- ton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. Founda- tionDB: A Distributed Unbundled Transactional K...
work page 2021
-
[69]
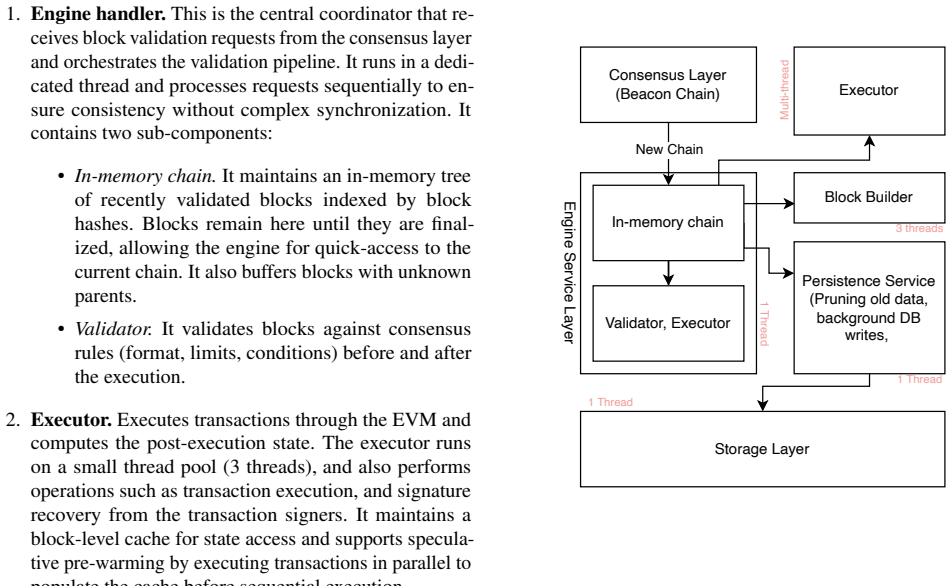
Engine handler.This is the central coordinator that re- ceives block validation requests from the consensus layer and orchestrates the validation pipeline. It runs in a dedi- cated thread and processes requests sequentially to en- sure consistency without complex synchronization. It contains two sub-components: • In-memory chain.It maintains an in-memory ...
-
[70]
Executor.Executes transactions through the EVM and computes the post-execution state. The executor runs on a small thread pool ( 3 threads), and also performs operations such as transaction execution, and signature recovery from the transaction signers. It maintains a block-level cache for state access and supports specula- tive pre-warming by executing t...
-
[71]
Block builder.Constructs new blocks when the node is selected as proposer. The builder selects transactions from the mempool, invokes the executor to verify validity and compute gas, assembles the final block
-
[72]
Runs on a dedicated thread and receives block batches from the engine handler
Storage layer.Handles durable storage of finalized blocks. Runs on a dedicated thread and receives block batches from the engine handler. State access and caching.The executor maintains a large in-memory cache (default 9 GB) partitioned by data type: • Storage cache (∼8 GB, 89%).: maps address-slot pairs to storage values. This is justified since it is th...
-
[73]
The block processor initializes a fresh per-block cache and invokes the executor
-
[74]
The executor reads and writes state through the per-block cache 19
-
[75]
On cache miss, the per-block cache queries the cross- block cache
-
[76]
On cache miss, the cross-block cache queries storage
-
[77]
After execution completes, the per-block cache contents are merged into the cross-block cache
-
[78]
B.1 Reth Primary reth-primaryis the hint generator that simulates a block pro- poser
The process repeats for the next block B Ira-L Architecture In this section, we provide details of Ira-L implementation in Rust. B.1 Reth Primary reth-primaryis the hint generator that simulates a block pro- poser. It replays blocks, collects all state keys accessed dur- ing execution, and writes hints that enable other backups to prefetch state for faste...
-
[79]
Block Processor .Iterates through blocks sequentially, coordinating execution, hint construction, and output writing
-
[80]
Key Collector .An EVM inspector that records accessed keys by intercepting opcodes: •SLOAD/SSTORE: storage slot accesses •BALANCE/SELFBALANCE: account accesses •CALL /STATICCALL/DELEGATECALL: bytecode ac- cesses •EXTCODECOPY /EXTCODESIZE: bytecode/account accesses Additionally, we also add transaction senders, recipients, and the block beneficiary (coinba...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.