A deep backward regression-based scheme for high-dimensional nonlinear partial differential equations
Pith reviewed 2026-05-22 11:34 UTC · model grok-4.3
The pith
Reformulating backward losses with conditional expectations gives an intrinsic variance-reduction mechanism for deep solvers of high-dimensional nonlinear parabolic PDEs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that replacing the pathwise Brownian fluctuations inside the Euler residual by their conditional expectations converts the local regression problems into a form whose population loss already incorporates an averaged effect; this supplies an intrinsic variance-reduction mechanism before any Monte Carlo sampling occurs, produces smoother training targets, improves numerical stability during sequential backward training, and permits a half-order convergence proof under standard approximation and integrability assumptions.
What carries the argument
The reformulation of each local backward loss through conditional expectations, later approximated by local multi-path Monte Carlo averages.
If this is right
- Training proceeds by solving a sequence of regression problems backward in time, each using the conditional-expectation target.
- The scheme remains competitive in accuracy with earlier deep dynamic programming methods on standard high-dimensional test problems.
- Stability gains appear on unbounded-domain benchmarks where the baseline method becomes unreliable.
- The same conditional-expectation idea extends directly to variational inequalities.
- Under idealized population minimization the method converges at half order once the approximation and integrability conditions hold.
Where Pith is reading between the lines
- The built-in averaging may permit reliable training with smaller outer sample sizes than pathwise methods require.
- The sequential regression structure could be paired with adaptive time-stepping or learned basis functions without changing the variance-reduction property.
- The half-order analysis suggests that further gains would require either better conditional-expectation estimators or stronger regularity assumptions on the solution.
- The same averaging device might transfer to other backward stochastic differential equation schemes that currently rely on pathwise residuals.
Load-bearing premise
The conditional expectations can be approximated by finite-sample Monte Carlo averages without introducing bias large enough to erase the variance-reduction benefit or to invalidate the subsequent error bounds.
What would settle it
A controlled experiment in which increasing the number of inner Monte Carlo paths fails to reduce the variance of the computed loss gradients or fails to improve stability relative to the original pathwise scheme.
Figures

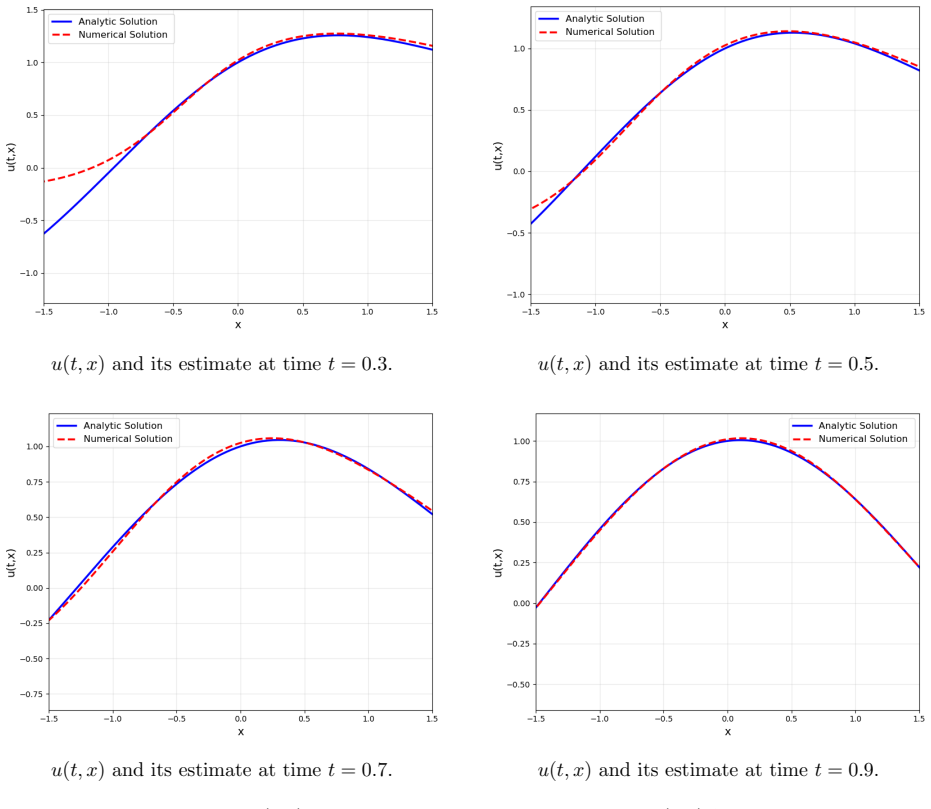
read the original abstract
We propose a deep backward regression-based (DBR) scheme for solving high-dimensional nonlinear parabolic partial differential equations. Building on the DBDP method of Hur\'e, Pham, and Warin~\cite{HCPHWX20}, the proposed method reformulates the local backward losses through conditional expectations and trains the resulting regression problems sequentially in time. This conditional-expectation formulation replaces pathwise Brownian fluctuations in the Euler residual by their averaged effect and therefore provides an intrinsic variance-reduction mechanism before loss evaluation. In practice, the conditional expectations are approximated by local multi-path Monte Carlo averages, which leads to smoother training targets and improved numerical stability. Numerical experiments show that DBR performs competitively on standard high-dimensional benchmarks and is more stable than DBDP1 on the challenging unbounded benchmark considered in Example~2. Under an idealized population-loss minimization setting, we provide an error analysis and establish a half-order convergence result under suitable approximation and integrability assumptions. We also discuss an extension to variational inequalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a deep backward regression-based (DBR) scheme for high-dimensional nonlinear parabolic partial differential equations. Building upon the DBDP method, it reformulates local backward losses using conditional expectations to achieve intrinsic variance reduction by replacing pathwise Brownian fluctuations with their averaged effects. In implementation, these expectations are approximated by local multi-path Monte Carlo averages, resulting in smoother training targets and enhanced stability. The method is tested on standard high-dimensional benchmarks where it performs competitively and shows improved stability on an unbounded example. An error analysis establishes a half-order convergence result under an idealized population-loss minimization setting with suitable approximation and integrability assumptions. An extension to variational inequalities is also presented.
Significance. Should the convergence analysis and numerical results hold, this work contributes a variance-reduced deep learning approach for solving high-dimensional PDEs, potentially offering better stability than prior methods like DBDP. The explicit error analysis, even in the idealized case, strengthens the theoretical foundation, and the competitive performance on benchmarks indicates practical relevance for applications in stochastic control and finance.
major comments (1)
- [Error analysis] Error analysis (as referenced in the abstract): The half-order convergence result is derived under an idealized population-loss minimization setting with explicit approximation and integrability assumptions. The practical scheme, however, approximates the conditional expectations via local multi-path Monte Carlo averages. The manuscript does not fold the Monte Carlo approximation error into the bounds or verify that finite-sample bias and variance preserve the integrability conditions needed for the rate. This leaves open whether the claimed convergence transfers from the population analysis to the implemented algorithm.
minor comments (2)
- [Abstract] Abstract: The description of the numerical experiments could briefly note the dimensions tested to help readers assess the high-dimensional regime.
- The reference to Huré, Pham, and Warin should be expanded in the bibliography with full details for consistency with journal style.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We appreciate the recognition of the method's contributions and address the major comment regarding the error analysis below.
read point-by-point responses
-
Referee: Error analysis (as referenced in the abstract): The half-order convergence result is derived under an idealized population-loss minimization setting with explicit approximation and integrability assumptions. The practical scheme, however, approximates the conditional expectations via local multi-path Monte Carlo averages. The manuscript does not fold the Monte Carlo approximation error into the bounds or verify that finite-sample bias and variance preserve the integrability conditions needed for the rate. This leaves open whether the claimed convergence transfers from the population analysis to the implemented algorithm.
Authors: We acknowledge the referee's point that the error analysis is conducted in an idealized setting where the conditional expectations are exact, corresponding to population loss minimization. This is explicitly stated in the abstract ('Under an idealized population-loss minimization setting') and detailed in Section 4 of the manuscript. The practical implementation approximates these expectations using finite-sample Monte Carlo averages, which introduces additional approximation error not accounted for in the current theoretical bounds. We agree that incorporating the Monte Carlo error into the convergence analysis would provide a more complete theoretical justification. However, doing so rigorously would require deriving bounds on the bias and variance of the local Monte Carlo estimators and ensuring they preserve the necessary integrability conditions, which represents a substantial extension beyond the scope of the present work. In the revised version, we will expand the discussion in Section 4 to explicitly highlight this limitation and discuss how the Monte Carlo approximation error can be controlled in practice by increasing the number of paths. We believe this clarification addresses the concern while maintaining the focus on the core contribution of the conditional expectation reformulation for variance reduction. revision: partial
Circularity Check
No circularity: derivation is self-contained under explicit assumptions
full rationale
The paper builds a new DBR scheme on the cited DBDP method of Huré et al. (different authors) by reformulating local backward losses via conditional expectations, which mathematically replaces pathwise fluctuations with averaged effects. The half-order convergence is derived only in an idealized population-loss setting under stated approximation and integrability assumptions, with the practical multi-path Monte Carlo approximation presented separately as implementation. No equation reduces a claimed prediction or result to a fitted parameter by construction, no self-citation is load-bearing for the central claim, and no uniqueness theorem or ansatz is smuggled in. The derivation chain therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network architecture and training hyperparameters
axioms (1)
- domain assumption Suitable approximation and integrability assumptions hold for the neural network approximators and the underlying stochastic processes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reformulates the local backward losses through conditional expectations ... intrinsic variance-reduction mechanism
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
half-order convergence result under suitable approximation and integrability assumptions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anil, C., Lucas, J. and Grosse, R. (2019).Sorting out Lipschitz function approximation. In International conference on machine learning (pp. 291-301). PMLR
work page 2019
-
[2]
Bouchard, B. and Touzi, N. (2004).Discrete-time approximation and Monte-Carlo simulation of back- ward stochastic differential equations. Stoch. Process. Their Appl., 111(2), 175-206
work page 2004
-
[3]
Bouchard, B. and Chassagneux, J. F. (2008).Discrete-time approximation for continuously and dis- cretely reflected BSDEs.Stoch. Process. Their Appl, 118(12), 2269-2293
work page 2008
-
[4]
Bungartz, H. J. and Griebel, M. (2004).Sparse grids. Acta Numer., 13, 147-269. 29
work page 2004
-
[5]
Cai, W., Fang, S. and Zhou, T. (2025).SOC-MartNet: A martingale neural network for the Hamilton- Jacobi-Bellman equation without explicit in stochastic optimal controls. SIAM J. Sci. Comput., 47(4), C795-C819
work page 2025
-
[6]
Cai, W., Fang, S. and Zhou, T. (2025).Deep random difference method for high dimensional quasilinear parabolic partial differential equations. arXiv:2506.20308
-
[7]
Cai, W., Fang, S. and Zhou, T. (2024).Martingale deep learning for very high dimensional quasi-linear partial differential equations and stochastic optimal controls. arXiv:2408.14395
- [8]
-
[9]
and Menozzi, S.(2006).A forward-backward stochastic algorithm for quasi-linear PDEs
Delarue, F. and Menozzi, S.(2006).A forward-backward stochastic algorithm for quasi-linear PDEs. Ann. Appl. Probab., 16(1), 140-184
work page 2006
-
[10]
and Menozzi, S.(2008).An interpolated stochastic algorithm for quasi-linear PDEs
Delarue, F. and Menozzi, S.(2008).An interpolated stochastic algorithm for quasi-linear PDEs. Math. Comp., 77, 125-158
work page 2008
-
[11]
E, W., Han, J. and Jentzen, A. (2017).Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat., 5, 349-380
work page 2017
-
[12]
Fahhim, A., Touzi, N. and Warin, X. (2011).A probabilistic numerical method for fully nonlinear parabolic PDEs.Ann. Appl. Probab., 21(4), 1322-1364
work page 2011
-
[13]
E, W., Hutzenthaler, M., Jentzen, A. and Kruse, T. (2019).On multilevel Picard numerical approx- imations for high-dimensional nonlinear parabolic partial differential equations and high-dimensional nonlinear backward stochastic differential equations. J. Sci. Comput., 79(3), 1534-1571
work page 2019
-
[14]
El Karoui, N., Kapoudjian, C., Pardoux, E., Peng, S. and Quenez, M. C. (1997).Reflected solutions of backward SDE’s, and related obstacle problems for PDE’s. Ann. Probab., 25(2), 702-737
work page 1997
-
[15]
Germain, M., Lauriere, M., Pham, H. and Warin, X. (2022).DeepSets and their derivative networks for solving symmetric PDEs. J. Sci. Comput., 91(2), 63
work page 2022
-
[16]
Germain, M., Mikael, J. and Warin, X. (2022).Numerical resolution of McKean-Vlasov FBSDEs using neural networks. Methodol. Comput. Appl. Probab., 24(4), 2557-2586
work page 2022
-
[17]
Germain, M., Pham, H. and Warin, X. (2022).Approximation error analysis of some deep backward schemes for nonlinear PDEs. SIAM J. Sci. Comput., 44(1), A28-A56
work page 2022
-
[18]
Glorot X. and Bengio Y. (2010).Understanding the difficulty of training deep feed- forward neural networks. Proc. Mach. Learn. Res., 9, 249-256. Available at PMLR: https://proceedings.mlr.press/v9/glorot10a.html
work page 2010
-
[19]
Gobet, E. and Labart, C. (2007).Error expansion for the discretization of backward stochastic differential equations. Stoch. Process. Their Appl., 117(7), 803-829. 30
work page 2007
-
[20]
Gobet, E., Lopez-Salas, J. G., Turkedjiev, P. and Vazquez, C. (2016).Stratified regression Monte-Carlo scheme for semilinear PDEs and BSDEs with large scale parallelization on GPUs. SIAM J. Sci. Comput., 38(6), C652-C677
work page 2016
-
[21]
Gobet, E. and Turkedjiev, P. (2016).Linear regression MDP scheme for discrete backward stochastic differential equations under general conditions. Math. Comput., 85(299), 1359-1391
work page 2016
- [22]
-
[23]
Han, J., Hu, R. and Long, J. (2024).Learning high-dimensional McKean-Vlasov forward-backward stochastic differential equations with general distribution dependence. SIAM J. Numer. Anal., 62(1), 1-24
work page 2024
- [24]
- [25]
-
[26]
Han, Q., Lan, S. and Zhu, Q. (2024).A novel second order scheme with one step for forward backward stochastic differential equations. arXiv preprint arXiv:2409.07118
-
[27]
Hornik, K., Stinchcombe, M. and White, H. (1989).Multilayer feedforward networks are universal approximators. Neural networks, 2(5), 359-366
work page 1989
-
[28]
Hur´ e C., Pham H. and Warin X. (2020).Deep backward schemes for high-dimensional nonlinear PDEs. Math. Comp., 89, 1547-1579
work page 2020
-
[29]
Ji, S., Peng, S., Peng, Y. and Zhang, X. (2025).A Novel Control Method for Solving High-Dimensional Hamiltonian Systems Through Deep Neural Networks. SIAM J. Sci. Comput., 47(4), C873-C898
work page 2025
-
[30]
Kloeden, P. E. and Platen, E. (1992).Numerical Solution of Stochastic Differential Equations. Appli- cations of Mathematics (New York) 23. Springer, Berlin. MR1214374
work page 1992
-
[31]
Pardoux, E. and Peng, S. (1990).Adapted solution of a backward stochastic differential equation. Syst. Control Lett., 14(1), 55-61
work page 1990
-
[32]
Pardoux, E. and Peng, S. (1992).Backward stochastic differential equations and quasilinear parabolic partial differential equations. In Stochastic partial differential equations and their applications (pp. 200-217). Springer, Berlin, Heidelberg
work page 1992
-
[33]
Peng, S. (1991).Probabilistic interpretation for systems of quasilinear parabolic partial differential equa- tions.Stoch. Stoch. Rep., 37(1-2), 61-74
work page 1991
-
[34]
Pham, H., Warin, X. and Germain, M. (2021).Neural networks-based backward scheme for fully non- linear PDEs. SN Partial Differ. Equ. Appl., 2(1), 16. 31
work page 2021
-
[35]
Zhang C., Wu J. and Zhao W. (2019).One-step multi-derivative methods for backward stochastic dif- ferential equations. Numer. Math. Theor. Meth. Appl., 12 , 1213-1230
work page 2019
-
[36]
(2004).A numerical scheme for BSDEs
Zhang, J. (2004).A numerical scheme for BSDEs. Ann. Appl. Probab., 14(1), 459-488
work page 2004
-
[37]
Zhao, W., Chen, L. and Peng, S. (2006).A new kind of accurate numerical method for backward stochas- tic differential equations. SIAM J. Sci. Comput., 28(4), 1563-1581
work page 2006
-
[38]
Zhao, W., Fu, Y. and Zhou T. (2014)New kinds of high-order multistep schemes for coupled forward backward stochastic differential equations. SIAM J. Sci. Comput., 36, A1731-A1751. 32
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.