On the uncertainty from the first-stage estimation of prognostic covariate adjustment in randomized controlled trials
Pith reviewed 2026-05-13 21:19 UTC · model grok-4.3
The pith
Estimating the prognostic score from historical data yields the same asymptotic variance for the treatment effect estimator as treating the score as known.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The asymptotic variance of the average treatment effect estimator obtained via analysis of covariance after prognostic score estimation equals the asymptotic variance obtained when the prognostic score is treated as known.
What carries the argument
Equality of the two asymptotic variances derived for the PROCOVA estimator, one treating the prognostic score as known and the other accounting for its first-stage estimation from historical data.
If this is right
- The variance estimator that treats the prognostic score as known is asymptotically valid.
- This estimator is simpler to derive and implement than the one that accounts for first-stage estimation.
- Use the known-score variance estimator unless historical data are small, in which case the estimator that accounts for estimation is preferred for conservative results.
Where Pith is reading between the lines
- First-stage estimation uncertainty from historical data does not inflate the asymptotic variance of the treatment-effect estimator.
- The result may apply to other two-stage procedures that adjust trial analyses with externally estimated nuisance parameters.
- Finite-sample studies could quantify how large the historical data must be before the simpler variance estimator performs adequately.
Load-bearing premise
The derivations assume standard regularity conditions for two-stage estimators, including consistency of the prognostic score estimator and sufficiently large samples.
What would settle it
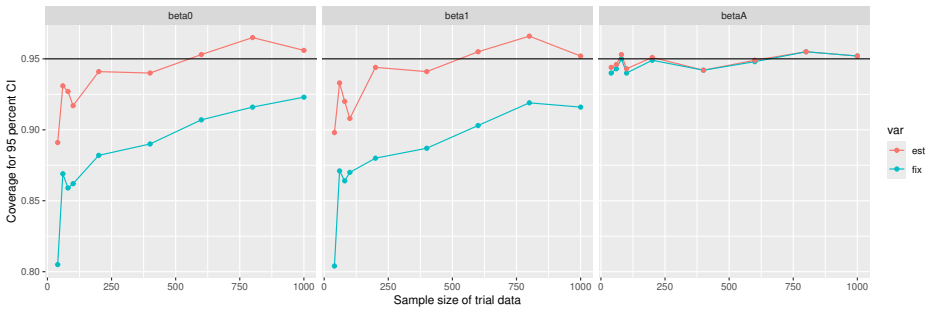
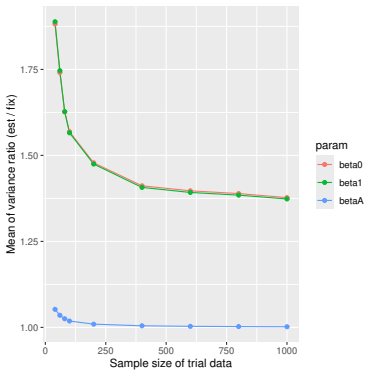
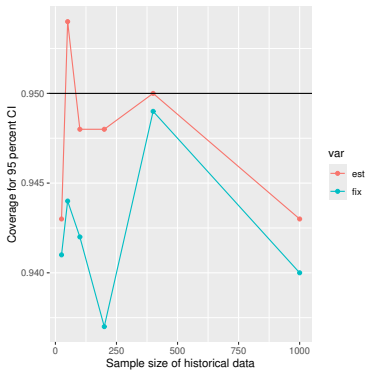
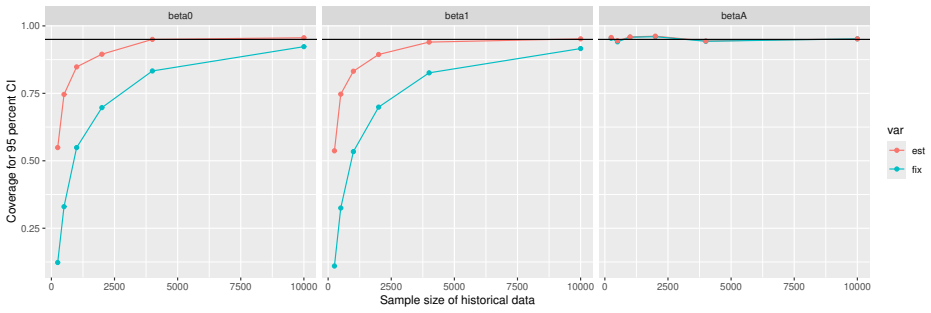
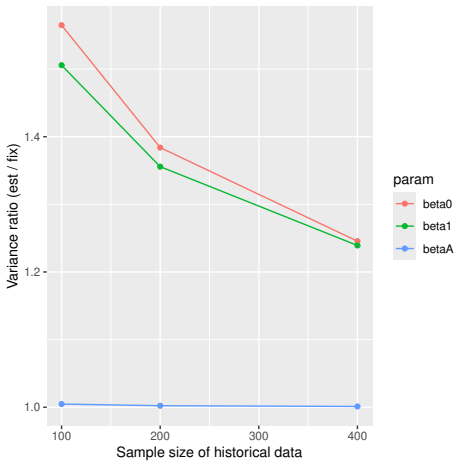
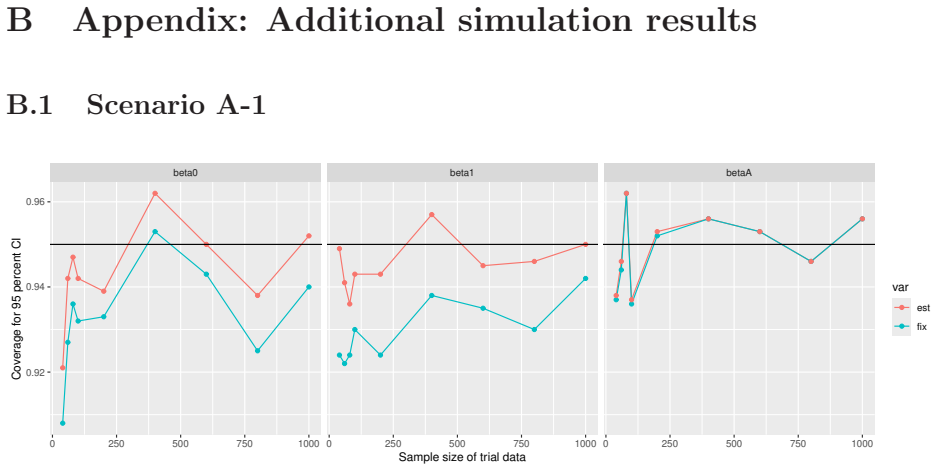
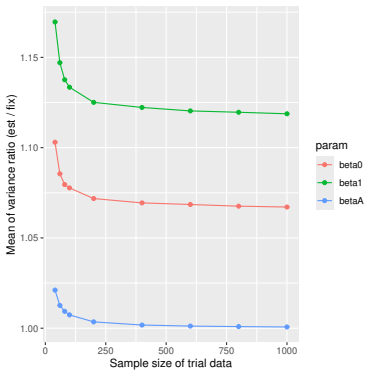
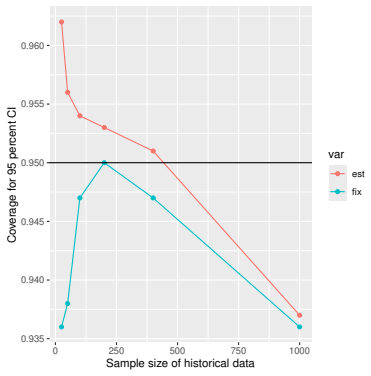
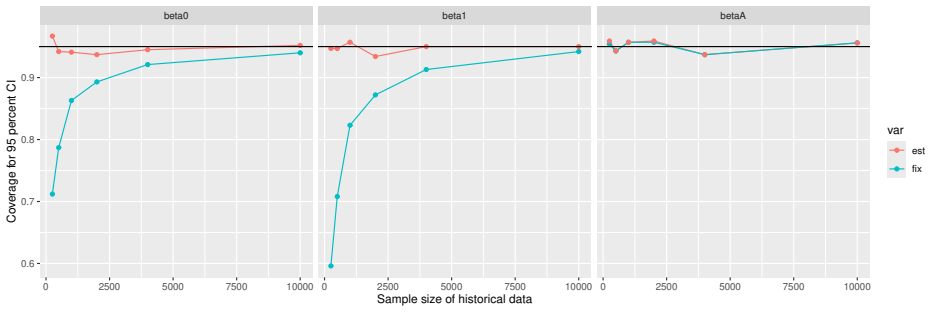
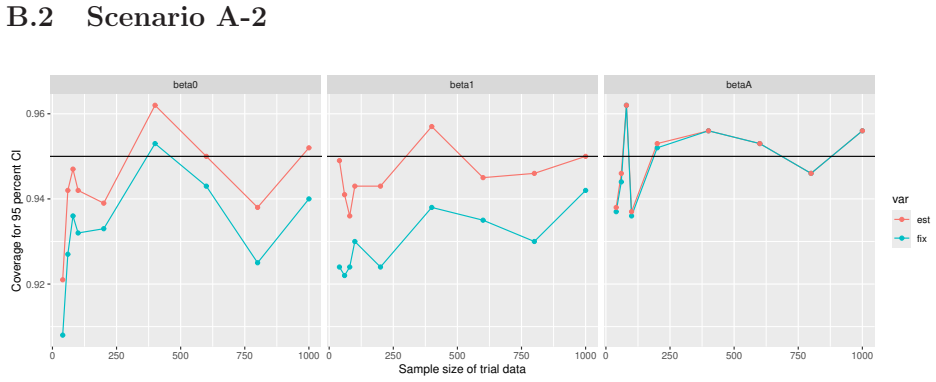
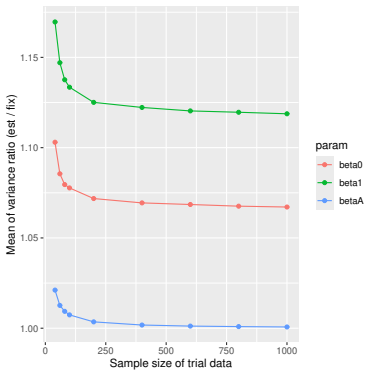
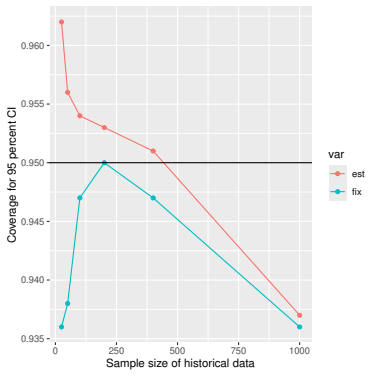
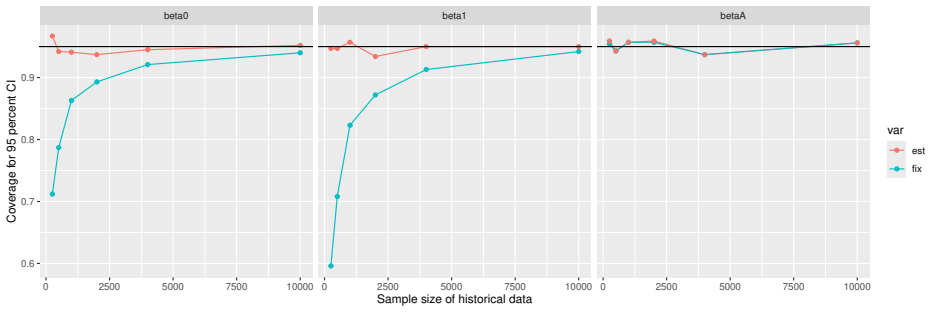
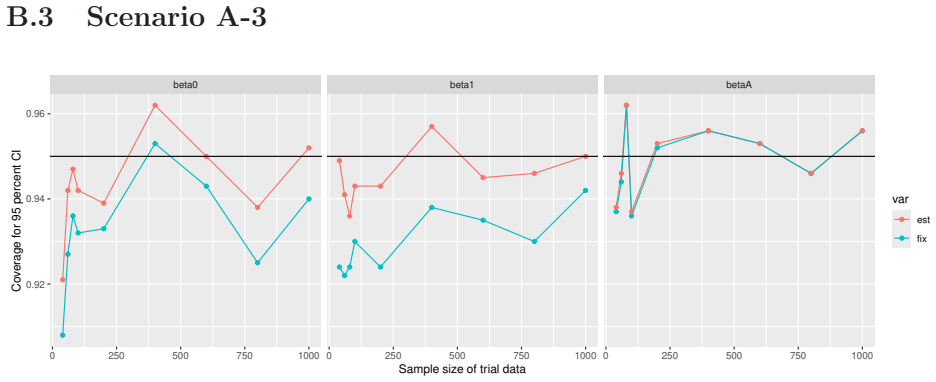
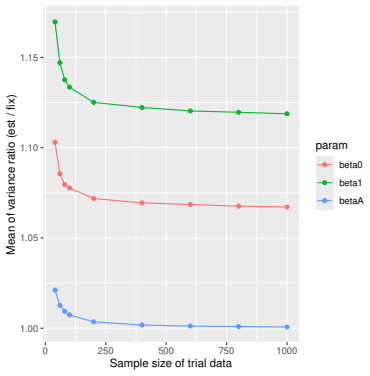
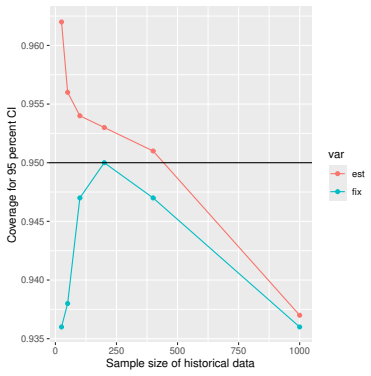
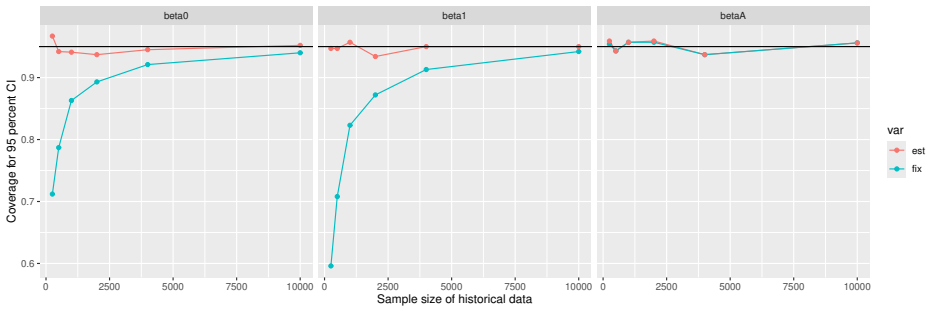
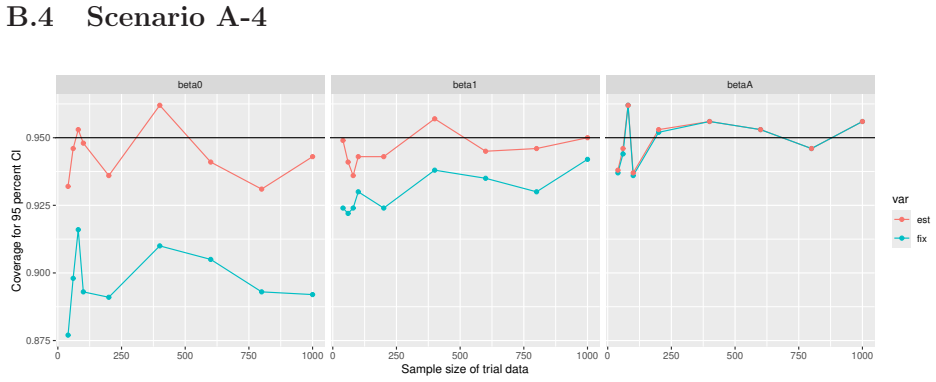
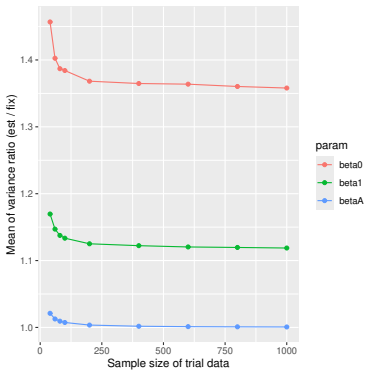
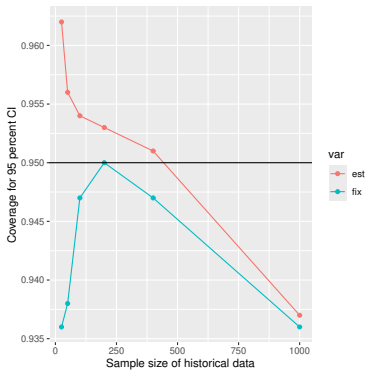
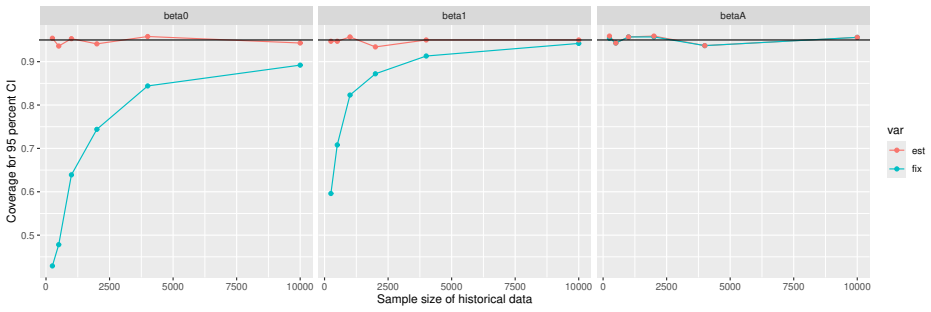
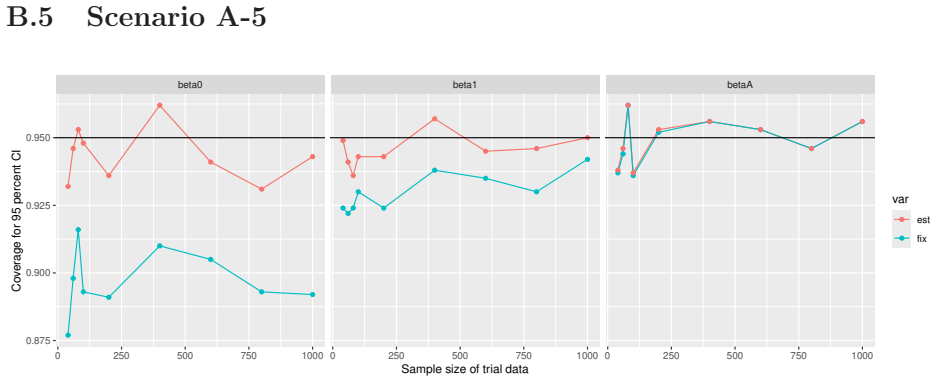
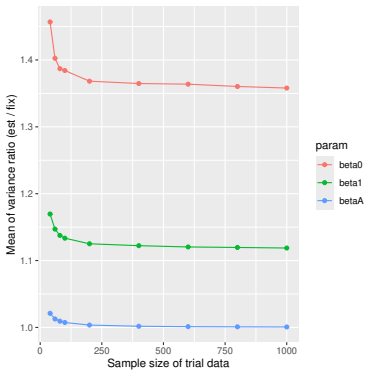
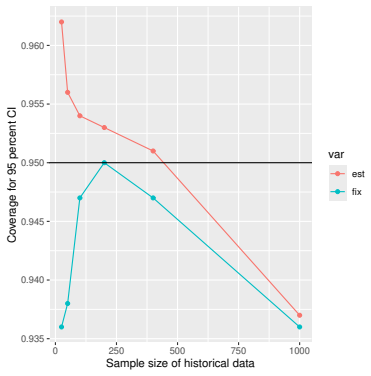
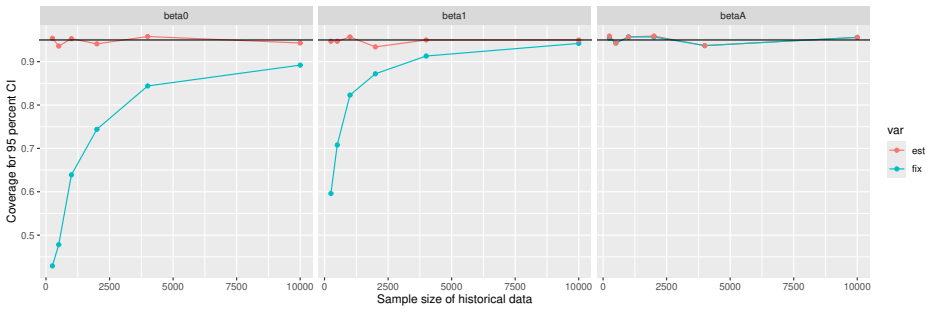
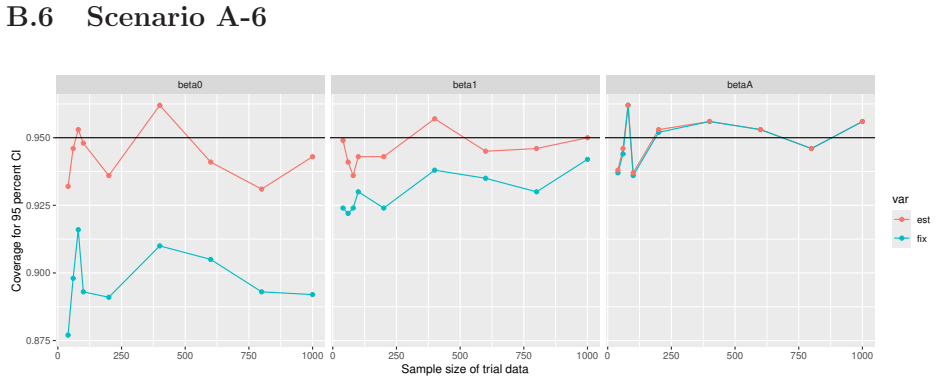
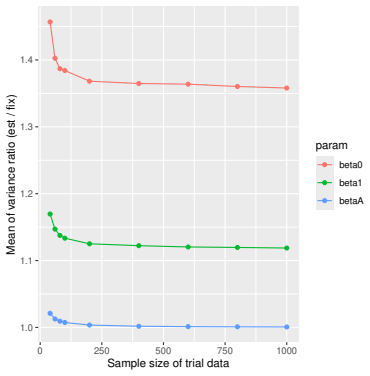
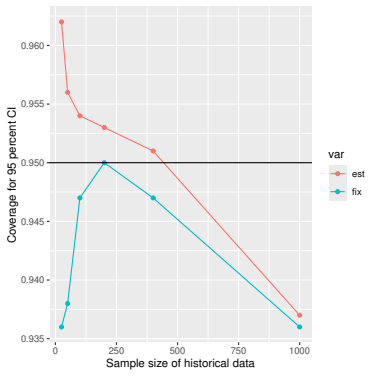
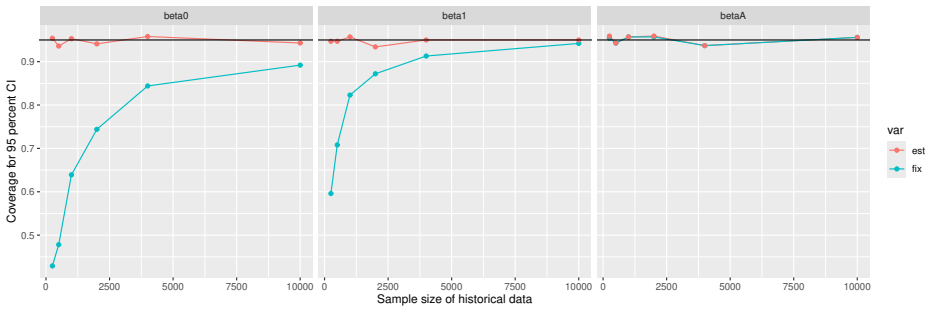
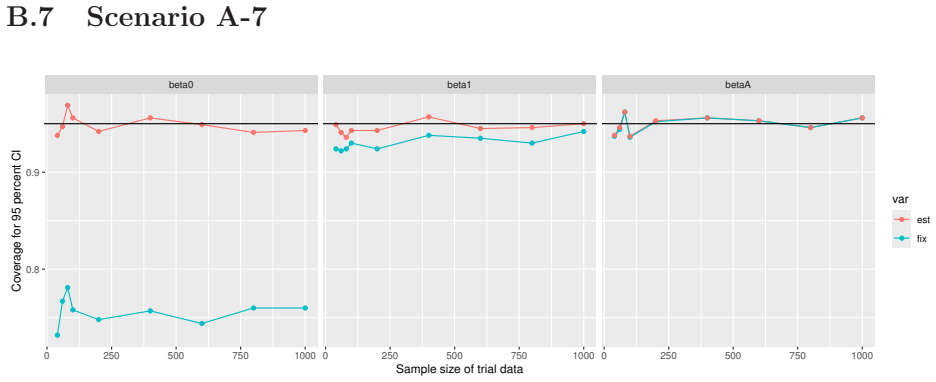
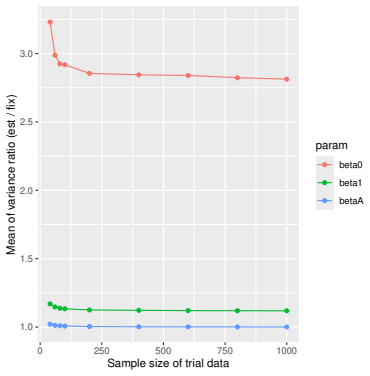
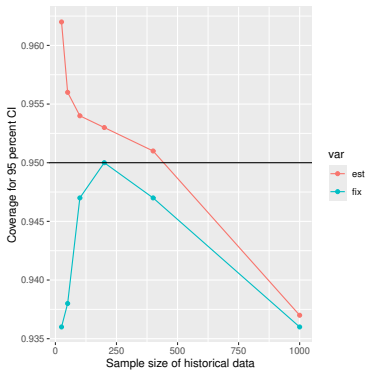
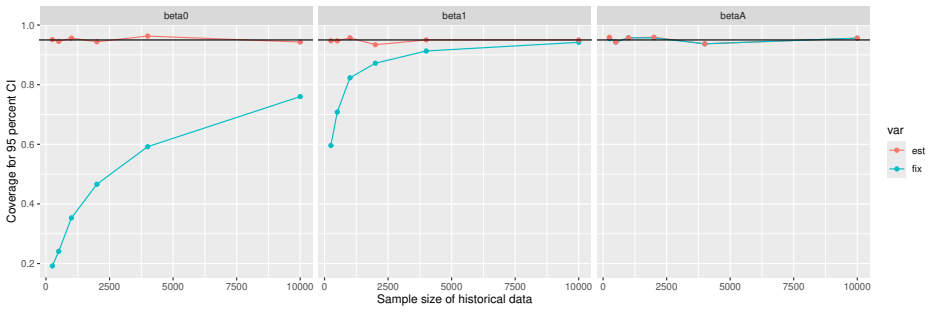
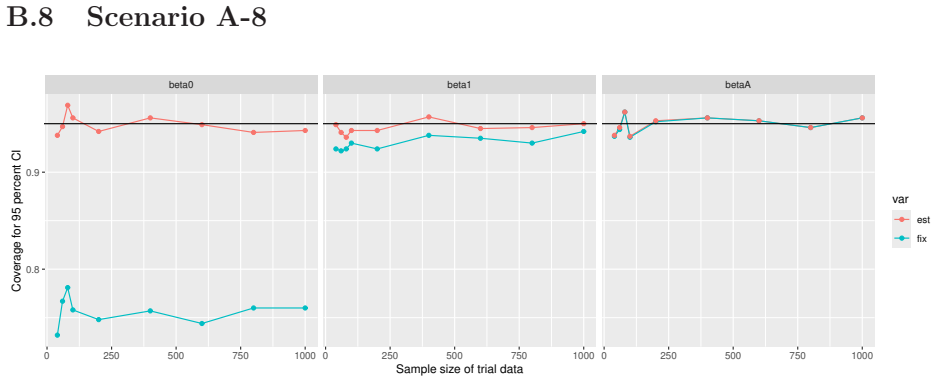
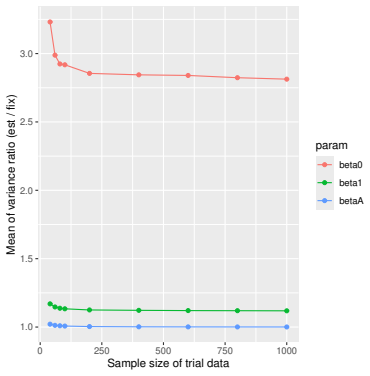
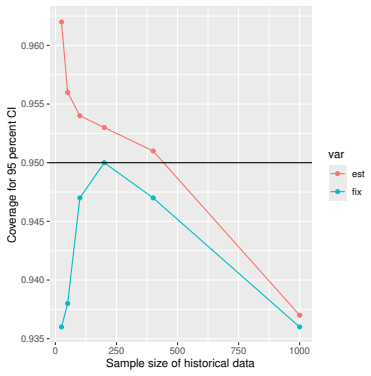
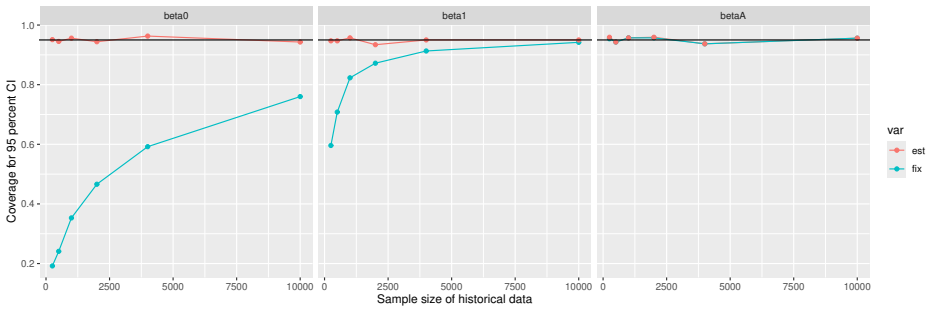
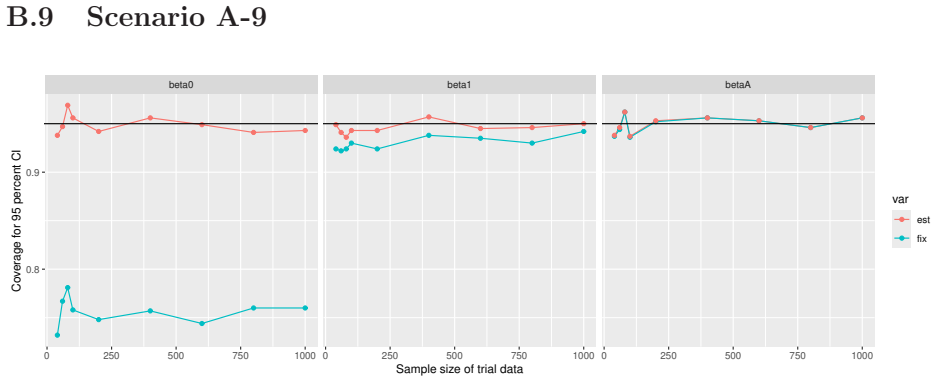
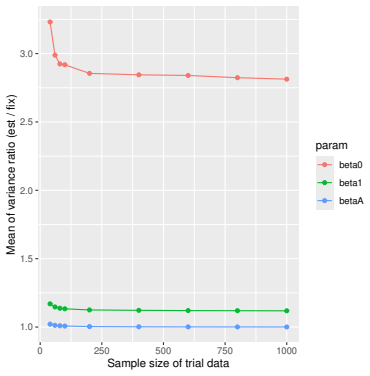
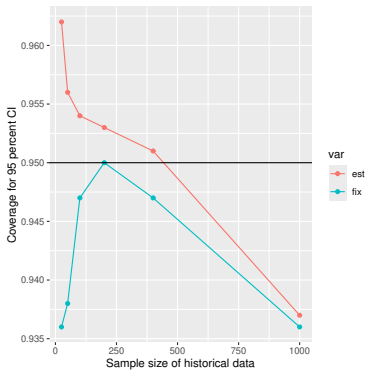
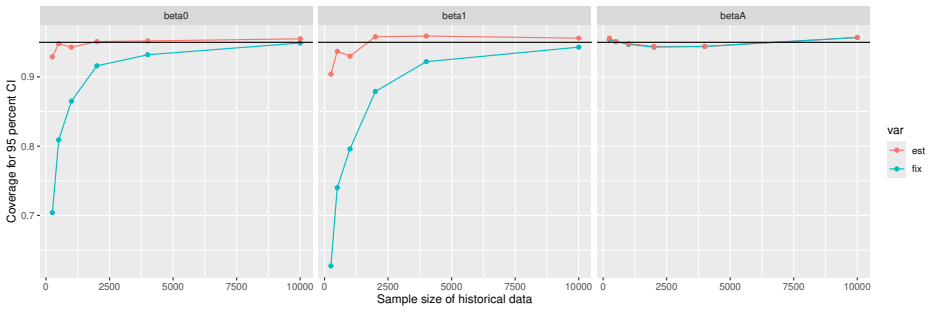
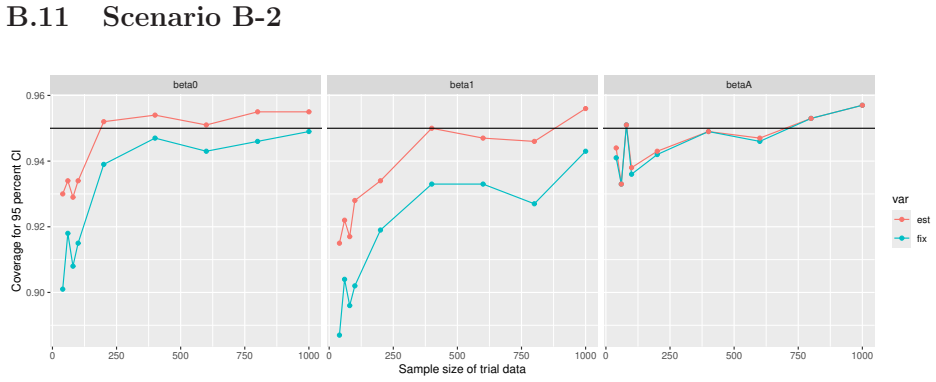
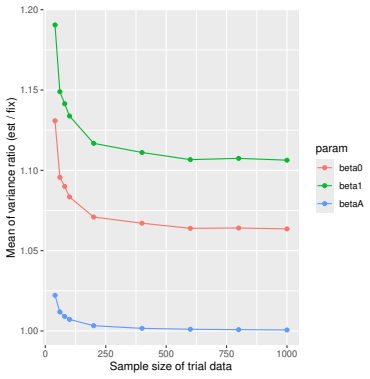
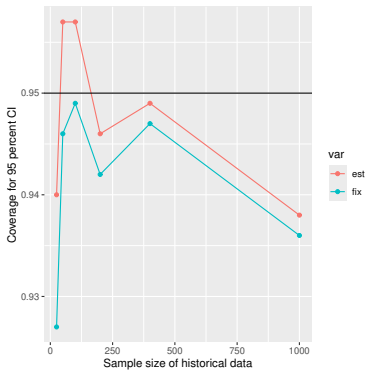
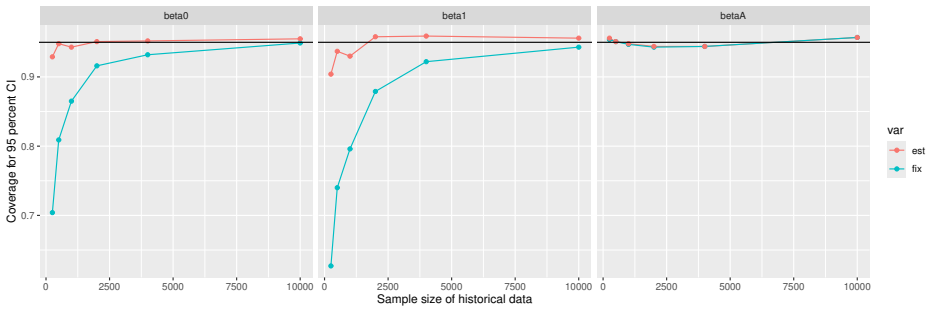
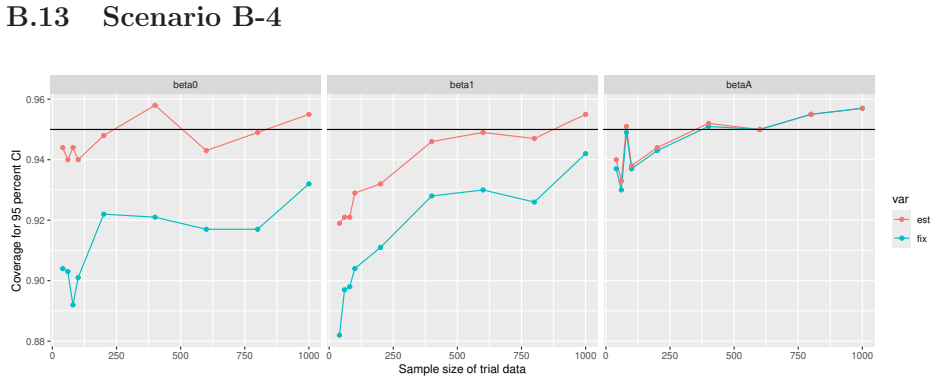
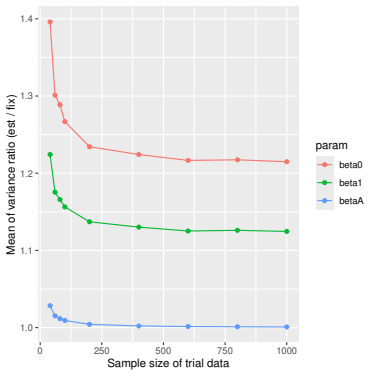
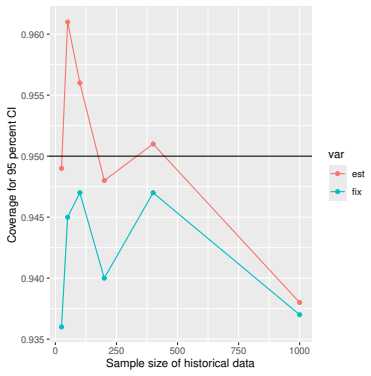
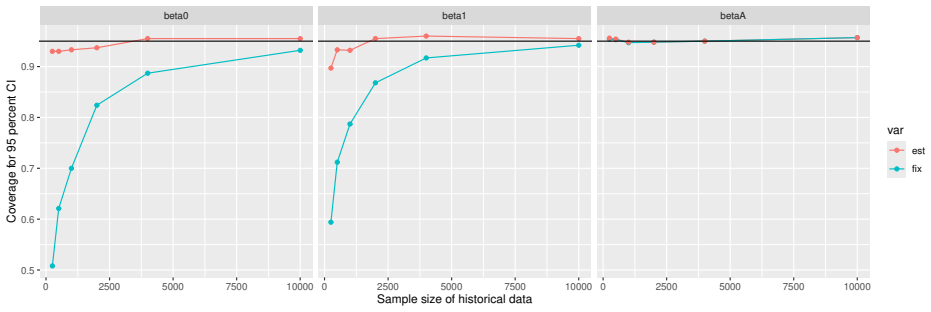
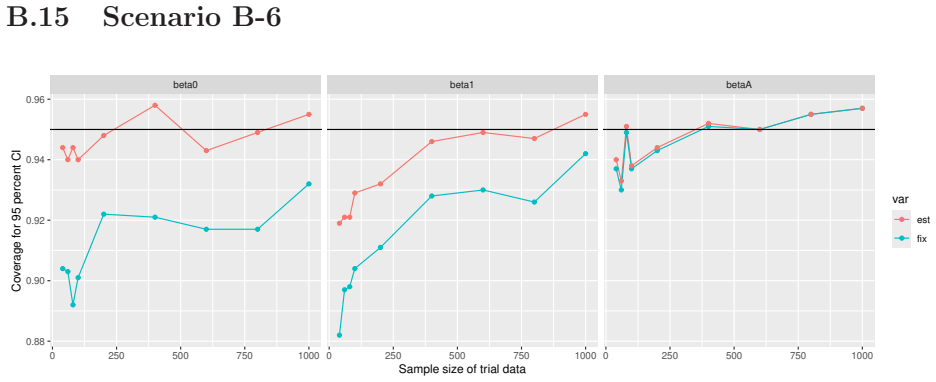
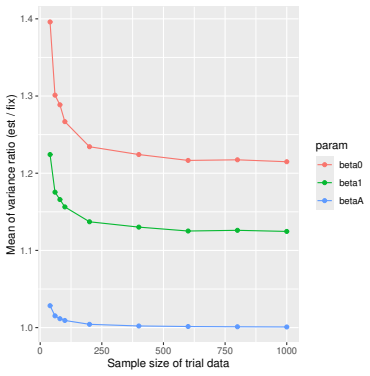
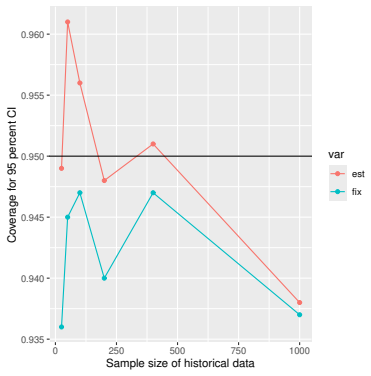
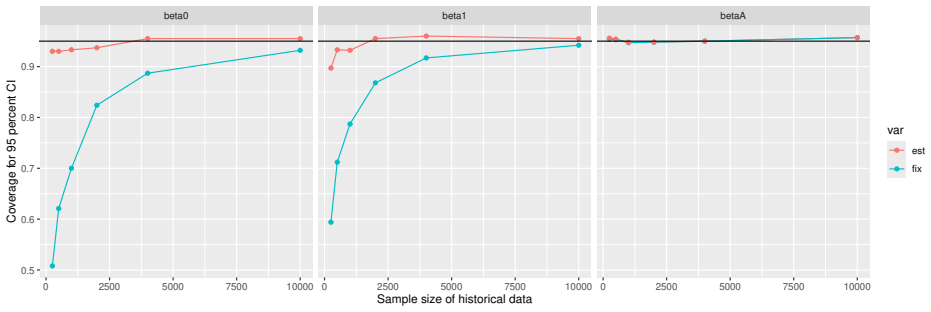
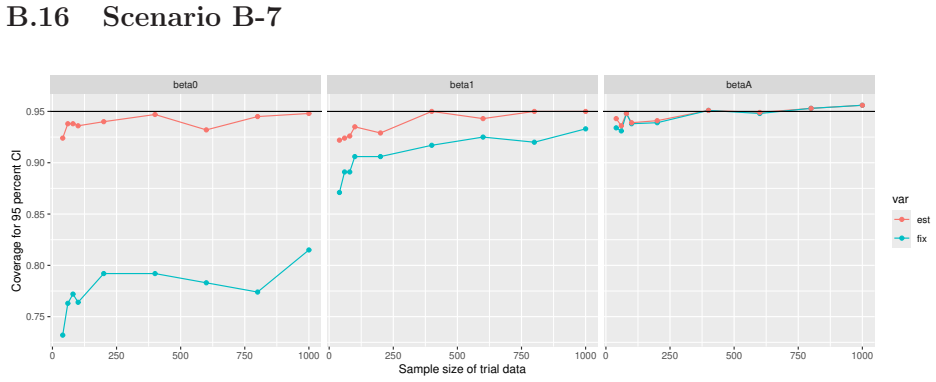
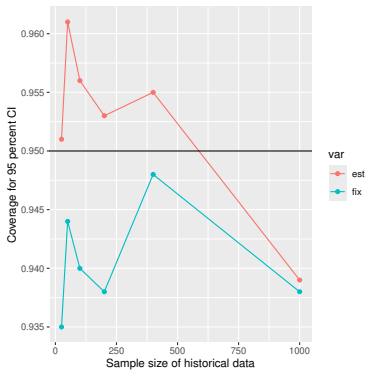
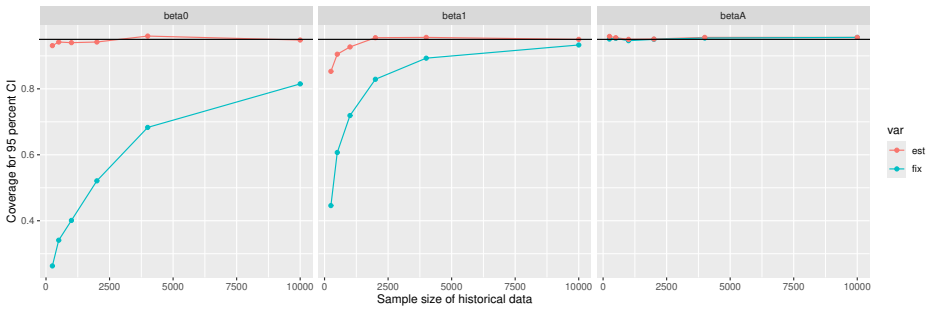
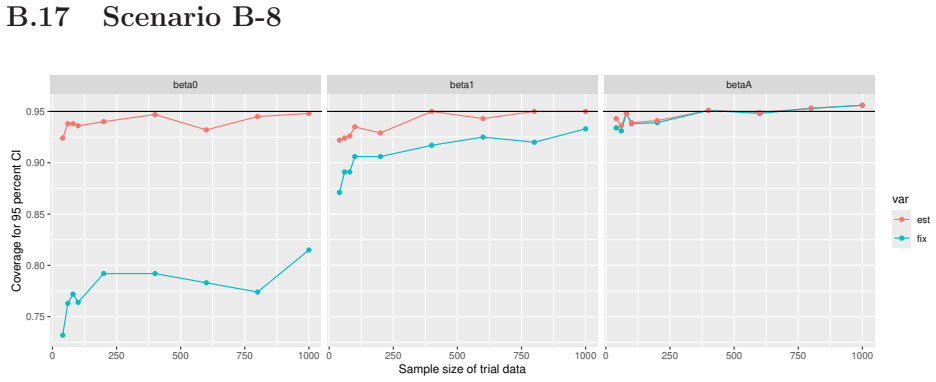
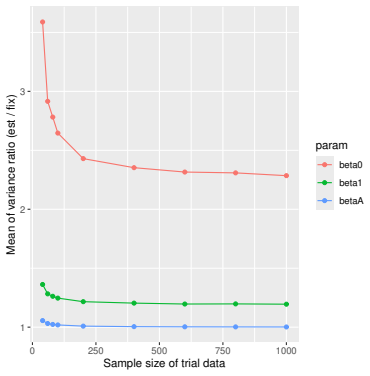
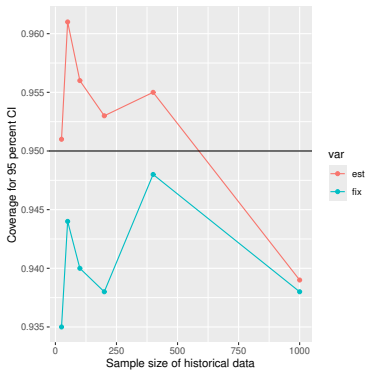
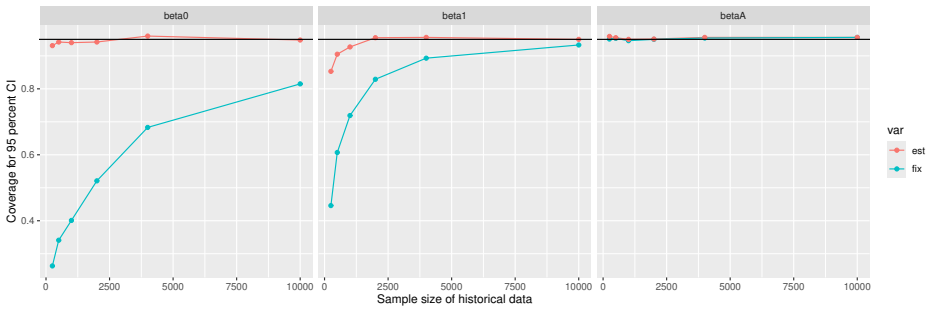
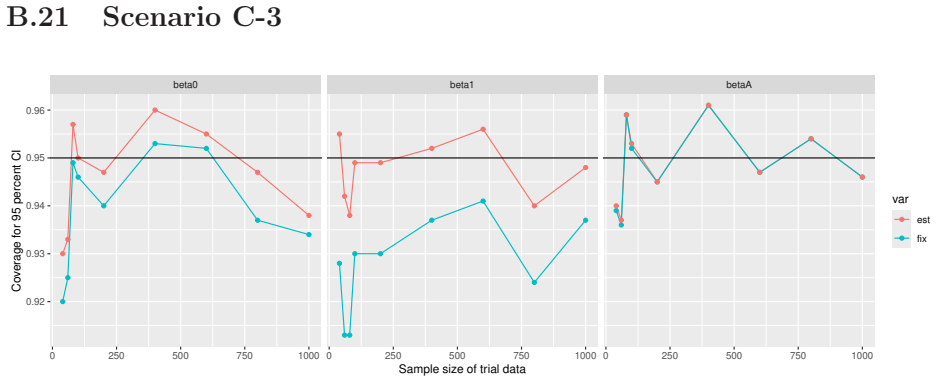
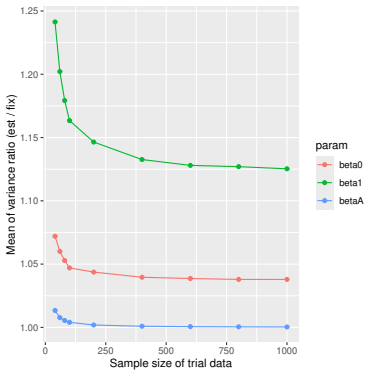
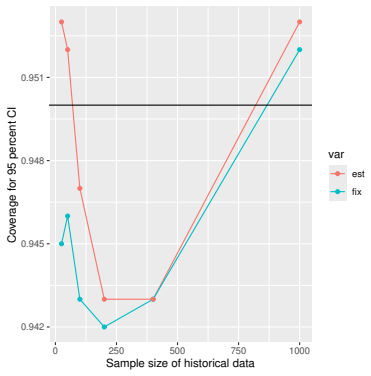
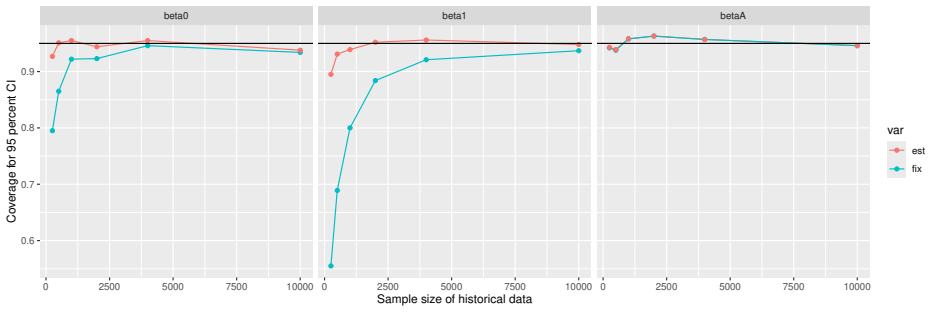
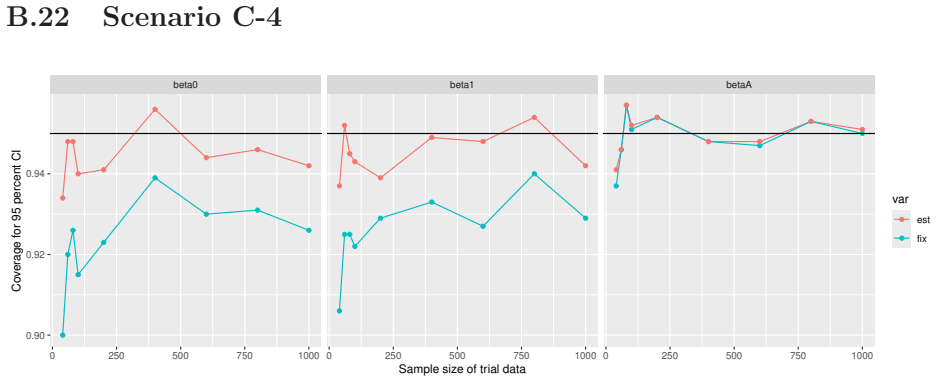
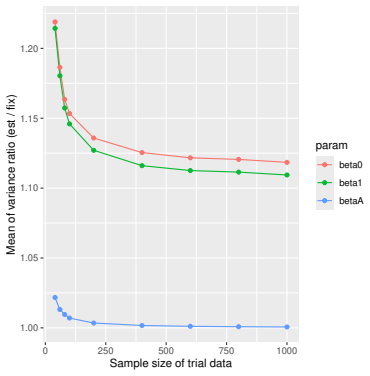
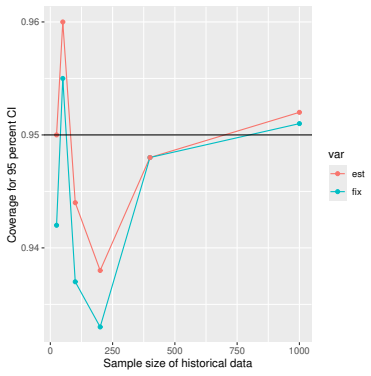
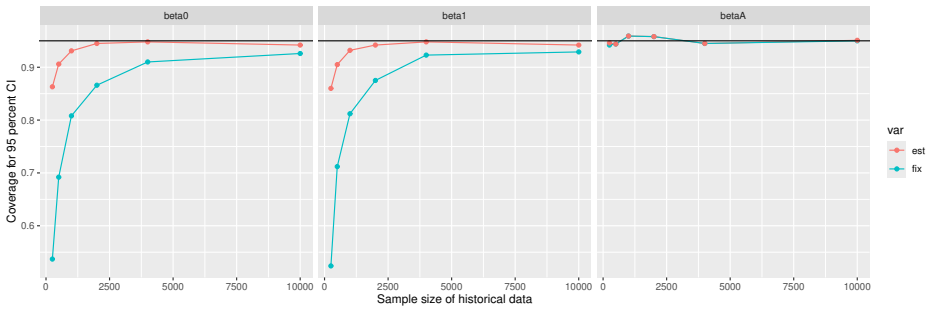
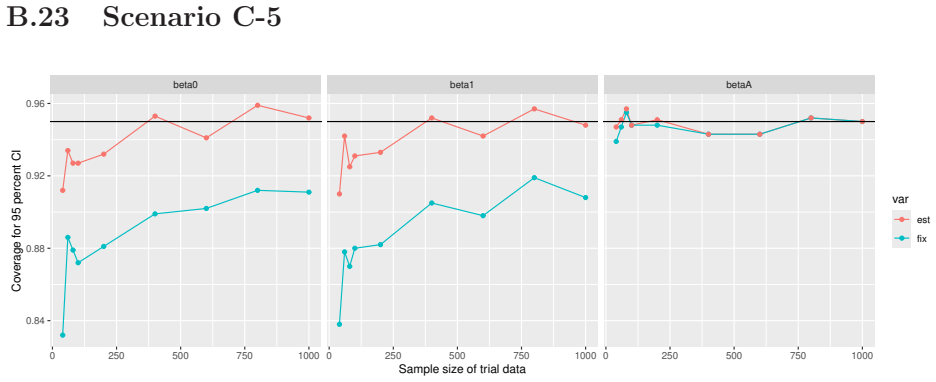
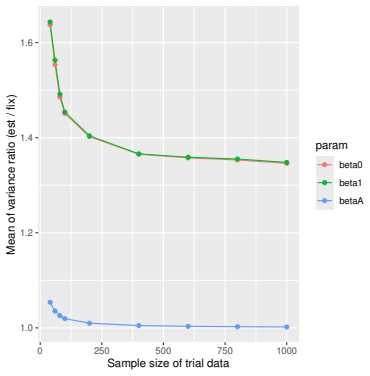
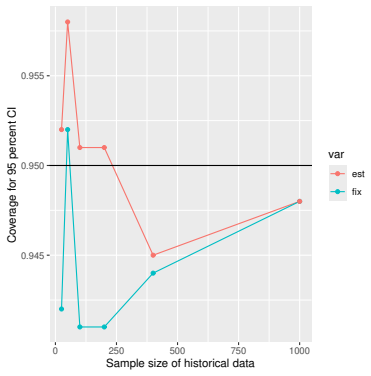
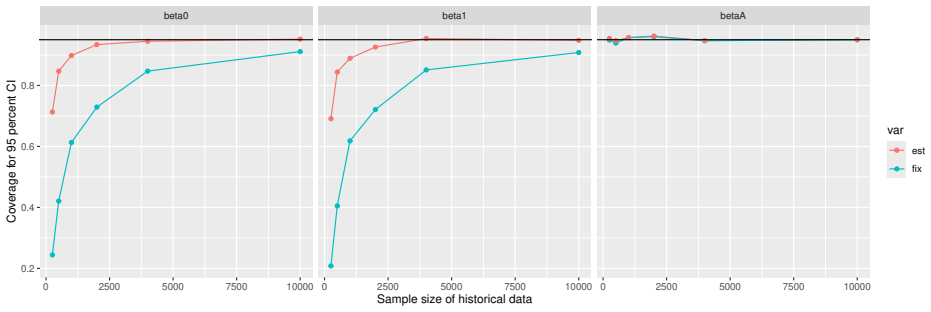
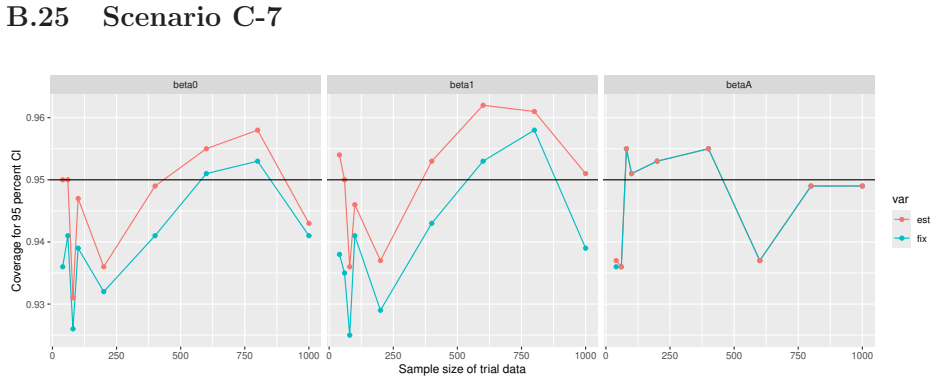
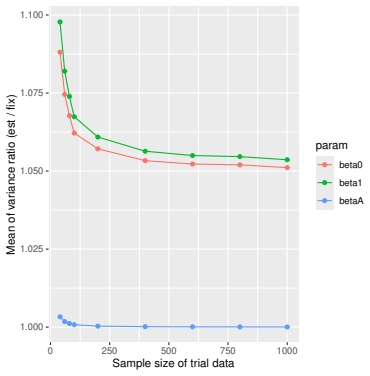
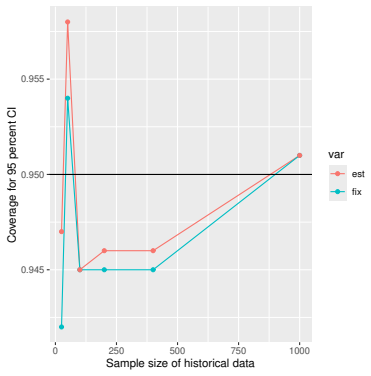
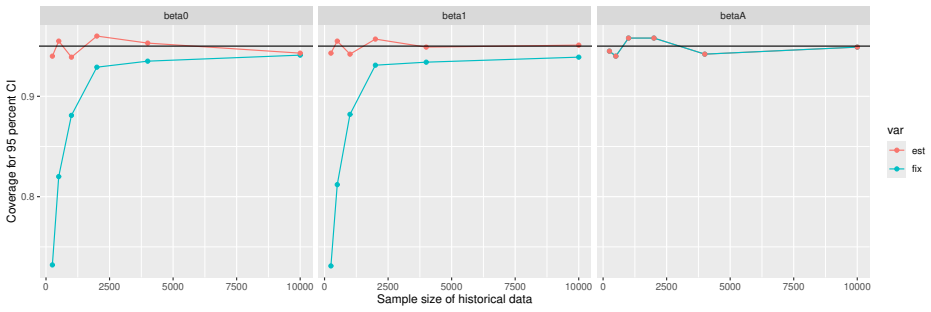
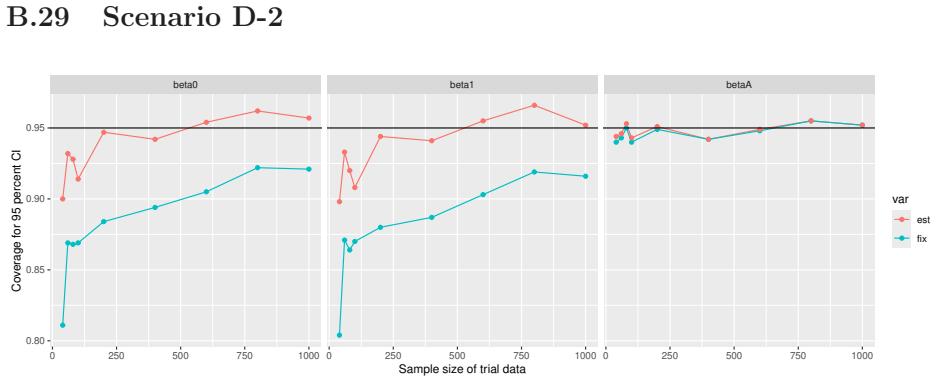
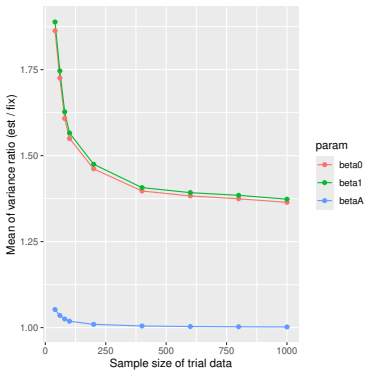
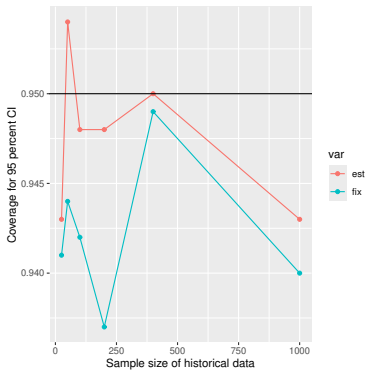
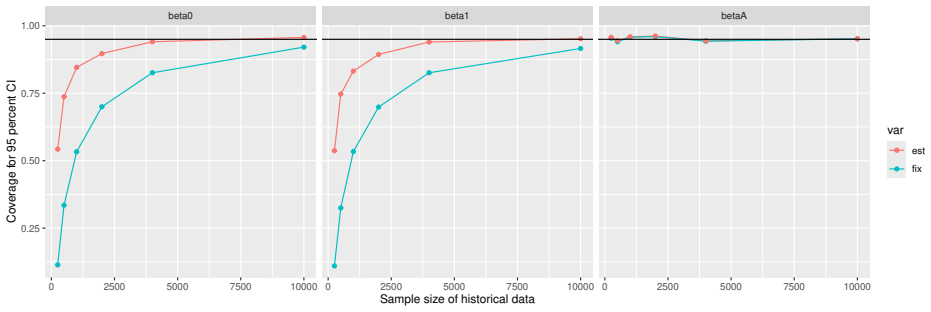
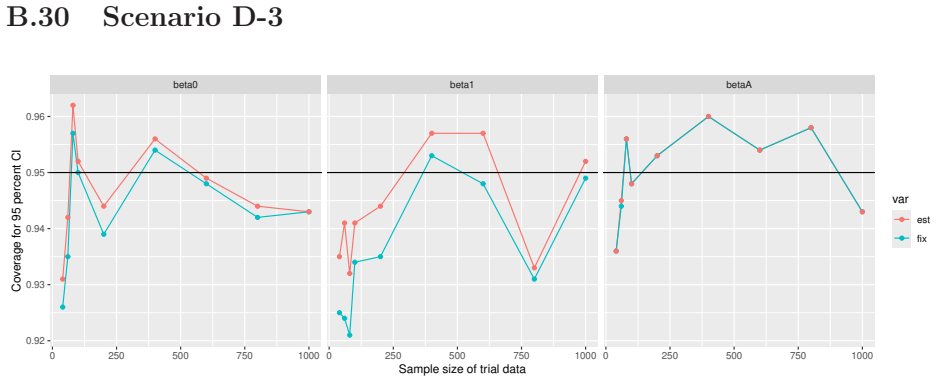
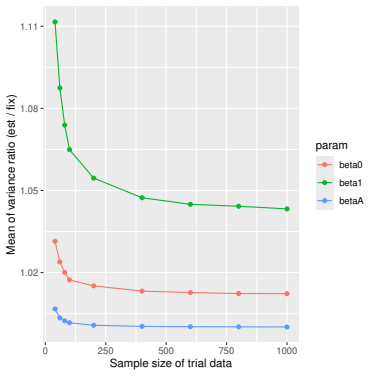
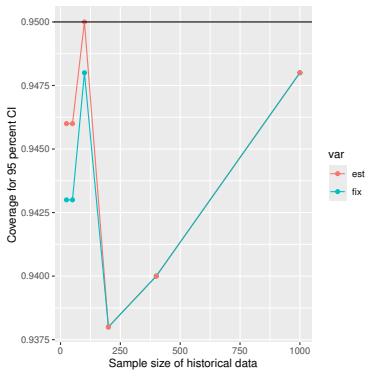
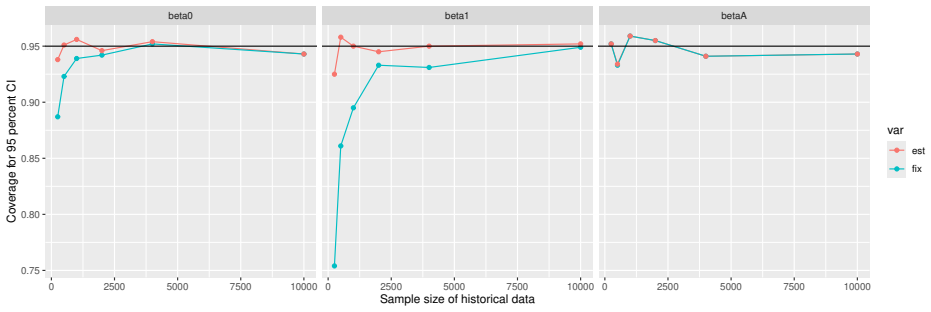
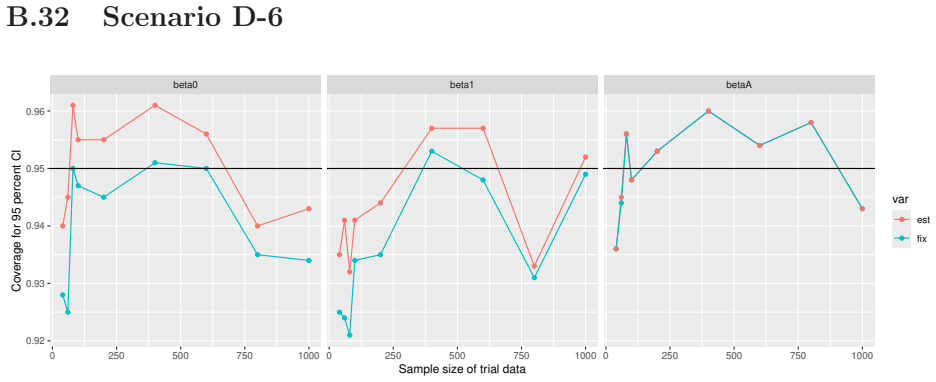
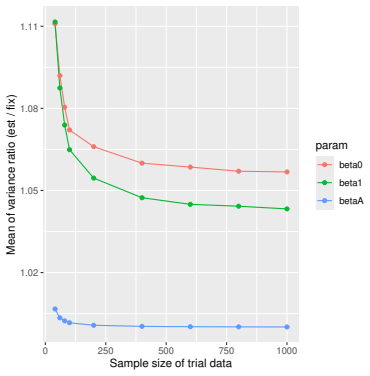
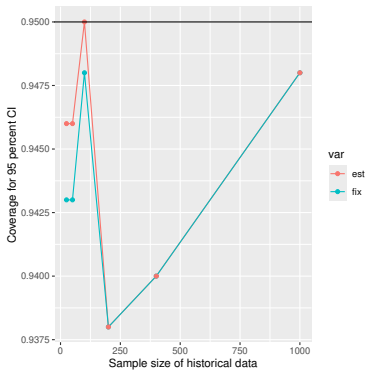
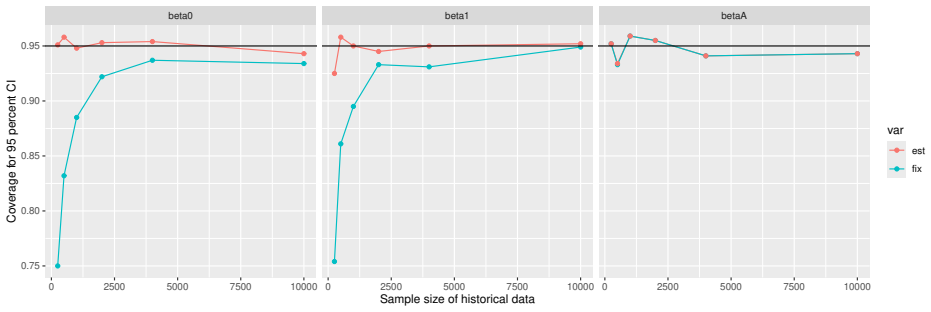
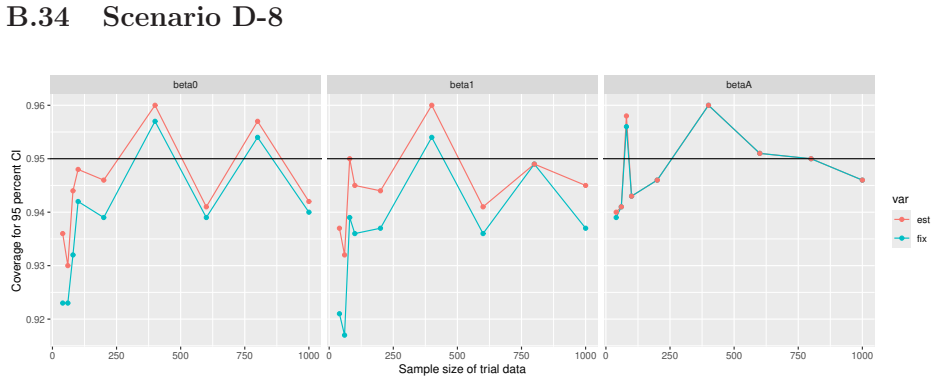
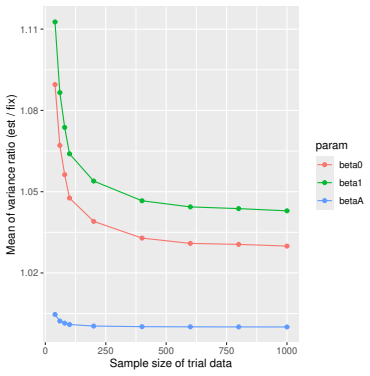
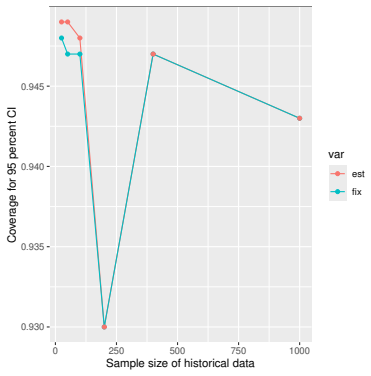
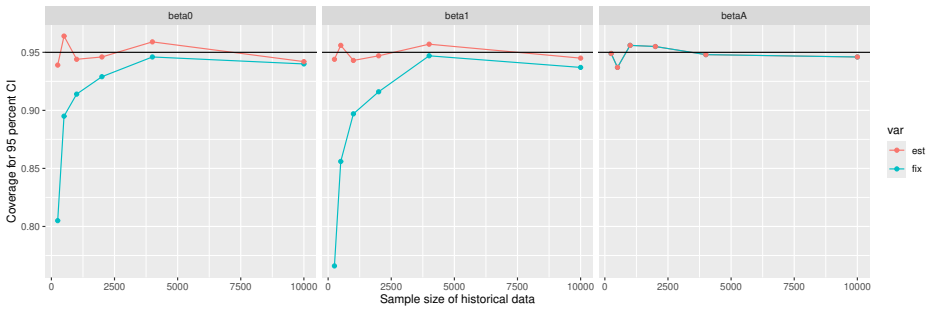
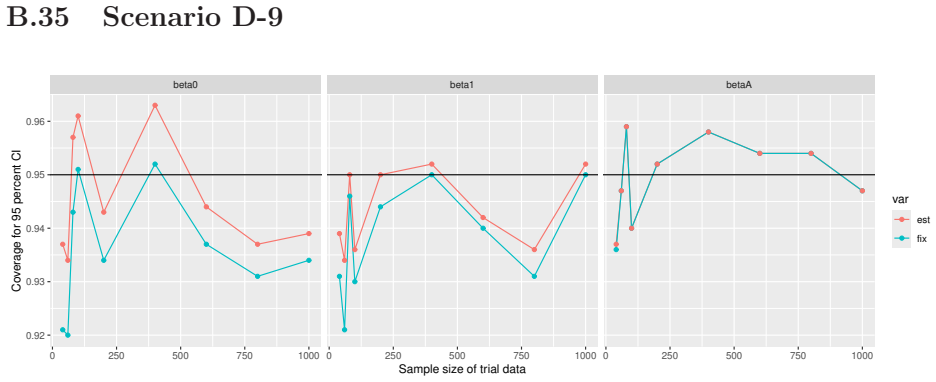
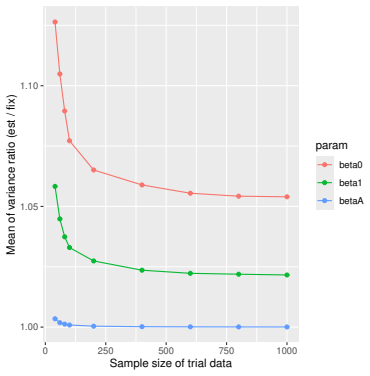
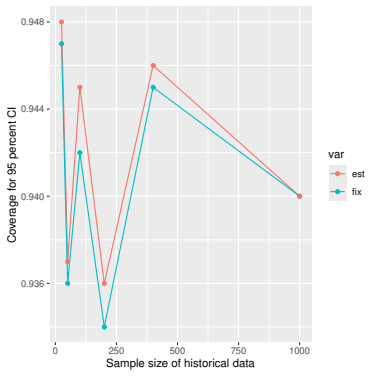
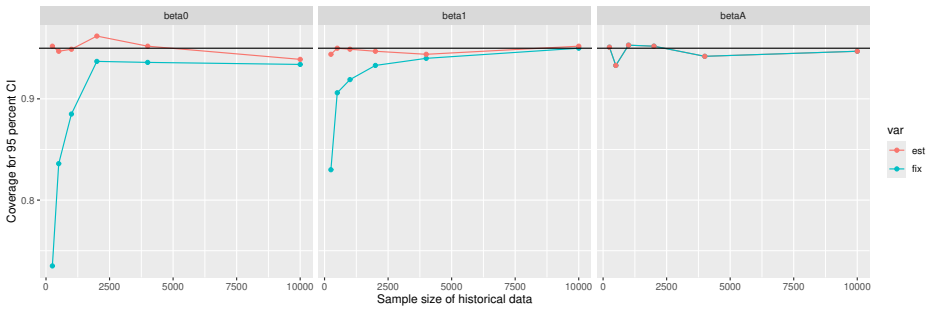
Monte Carlo simulations that compute both variance estimators for increasing sizes of historical and trial data and check whether their values and resulting confidence-interval coverage converge.
Figures
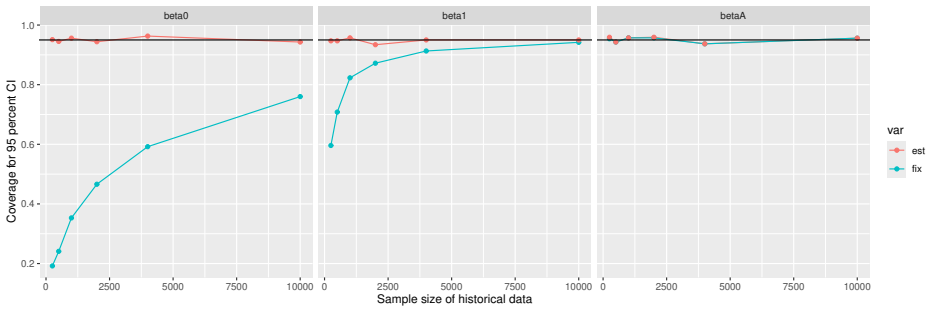
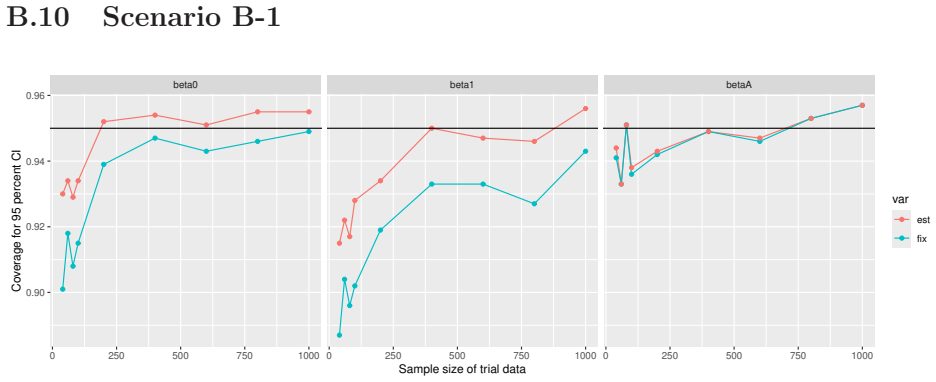
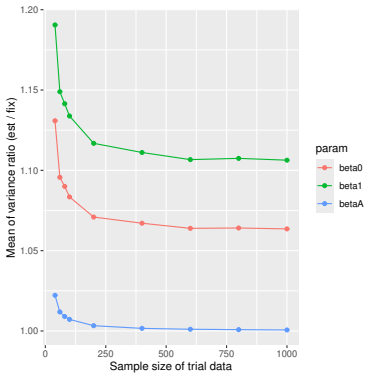
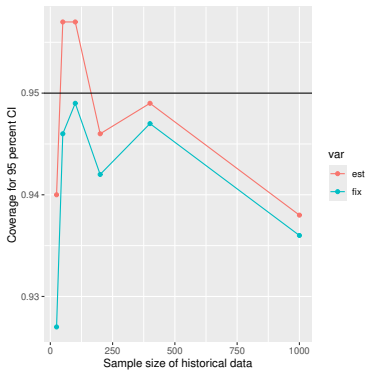
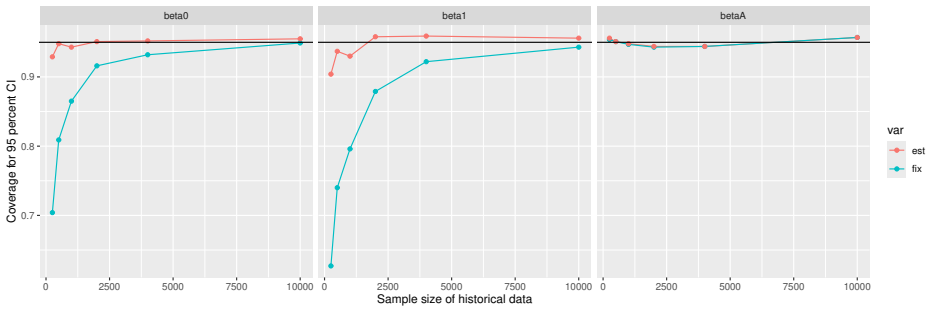
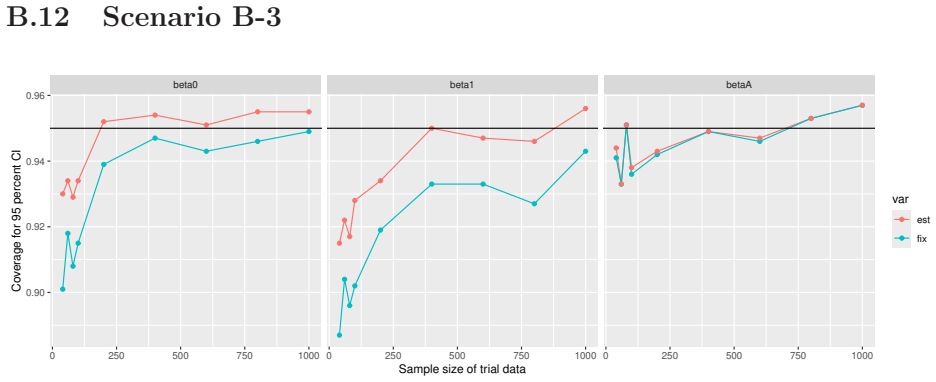
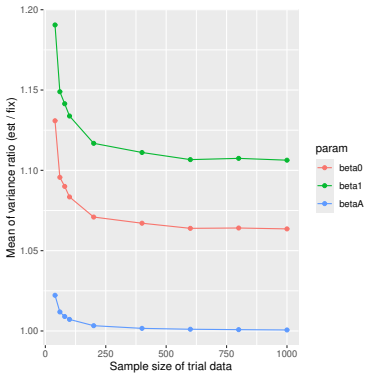
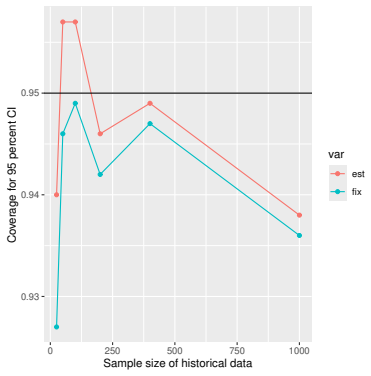
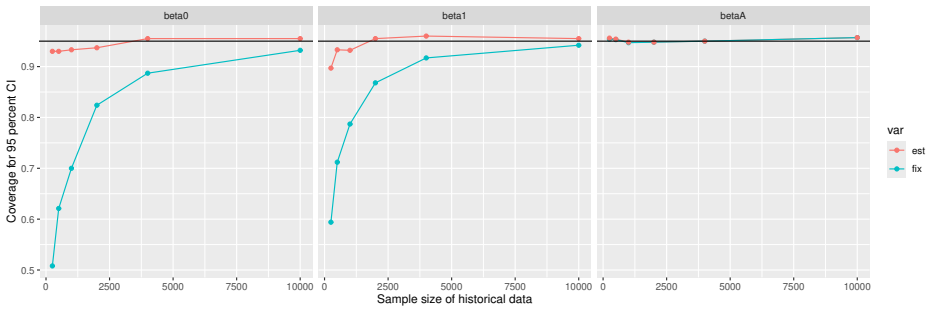
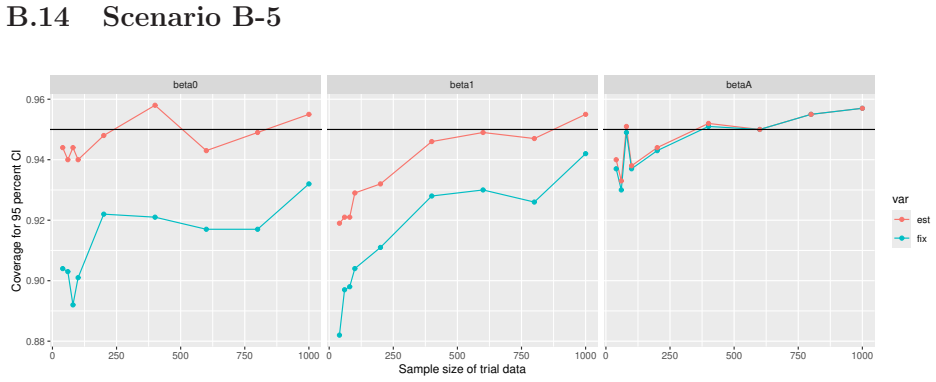
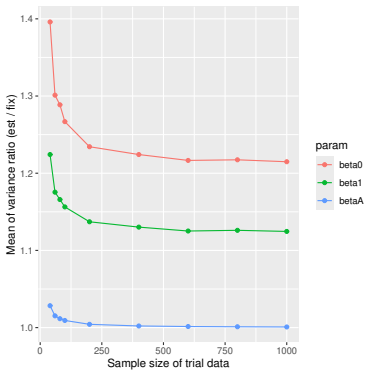
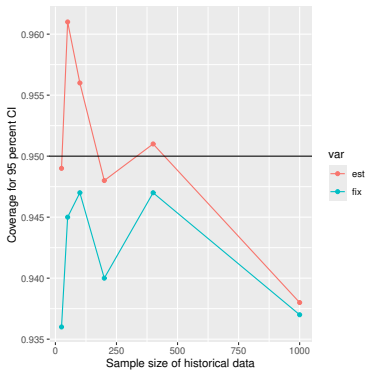

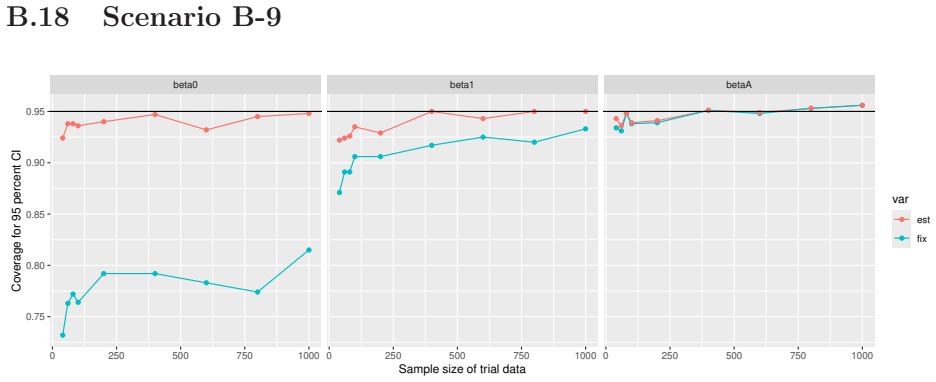
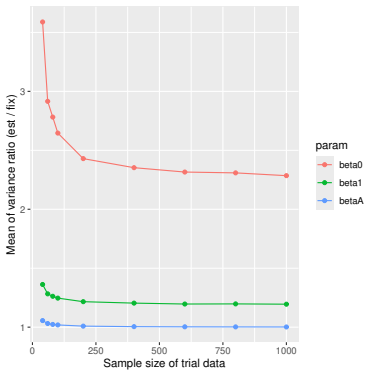
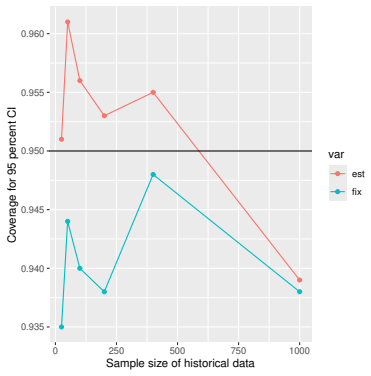
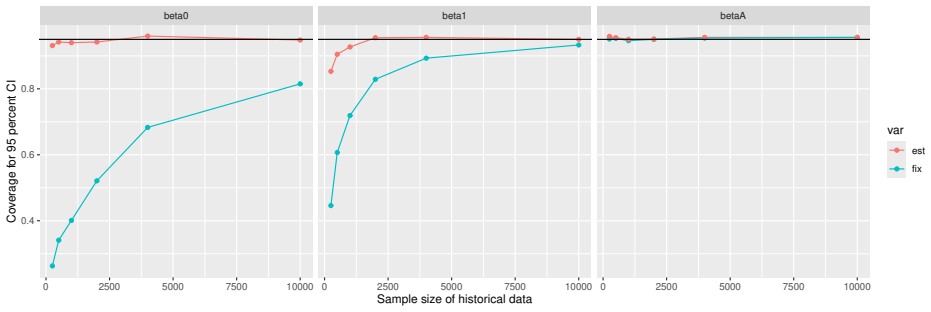
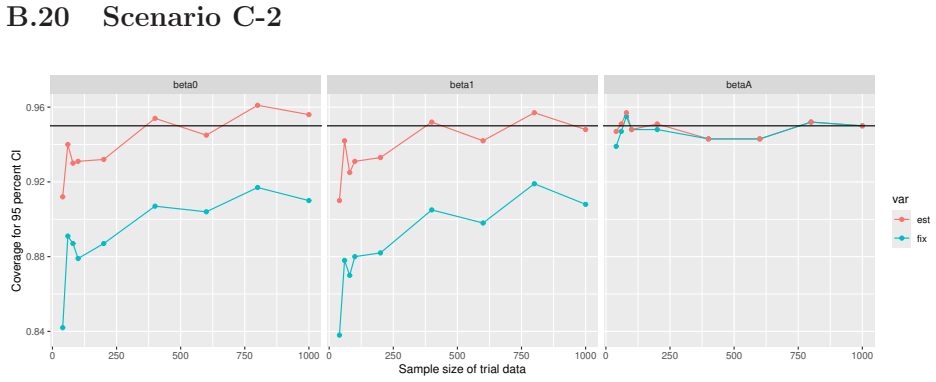
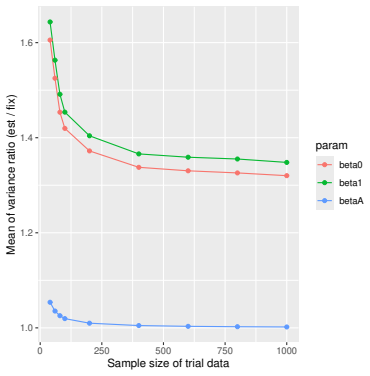
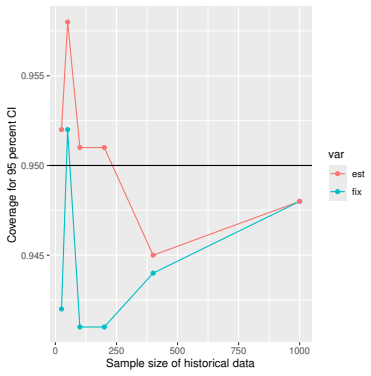
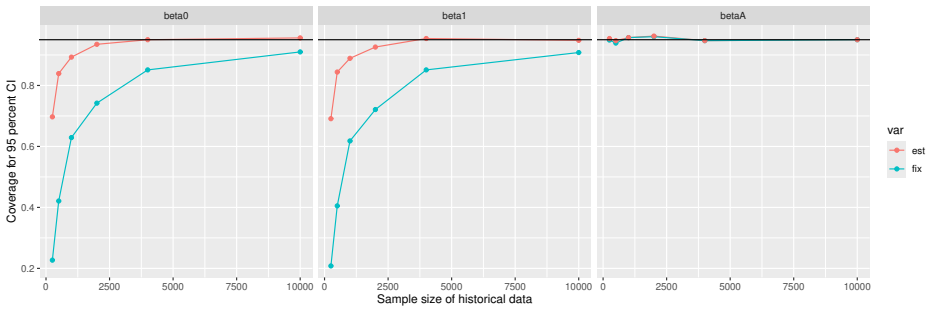
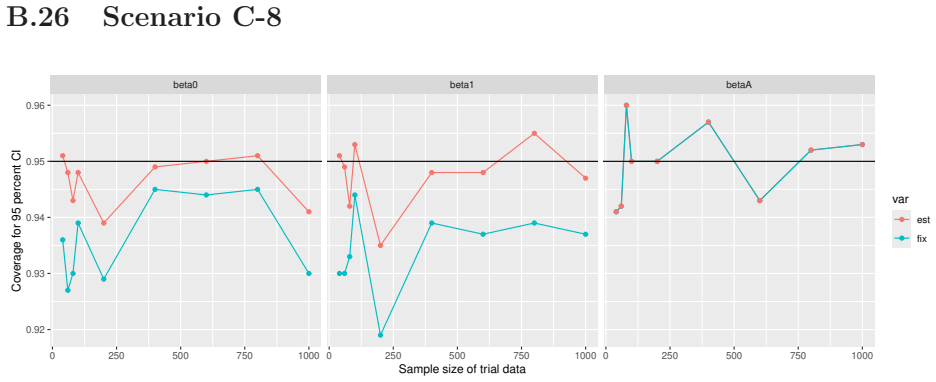
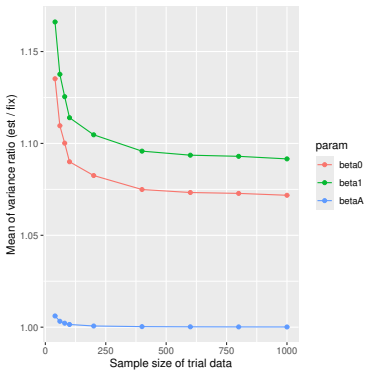
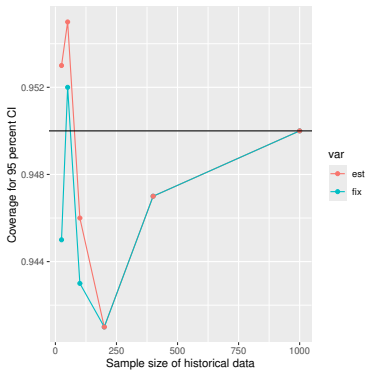
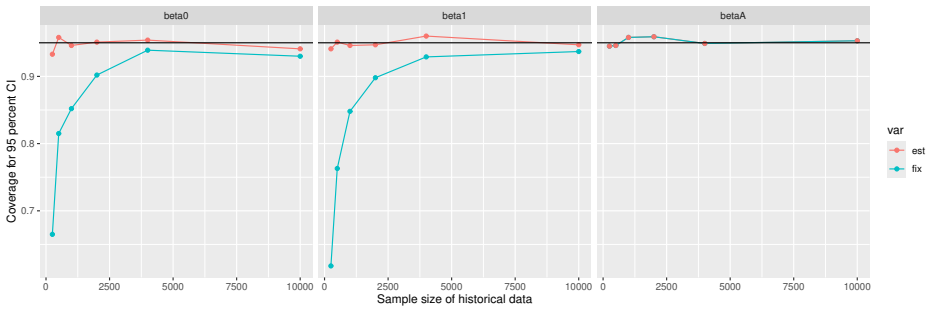
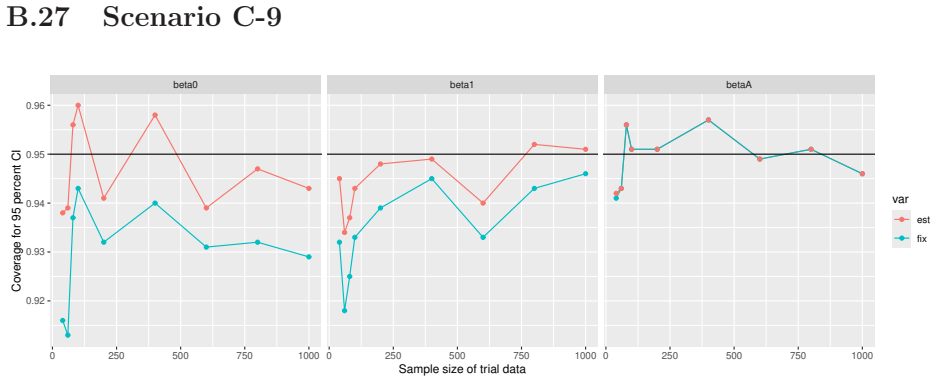
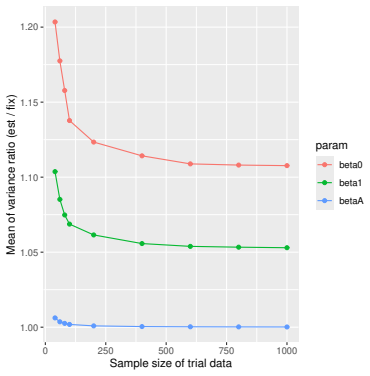
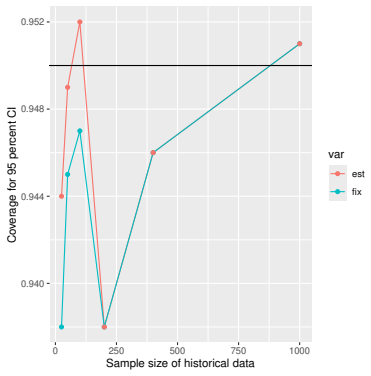
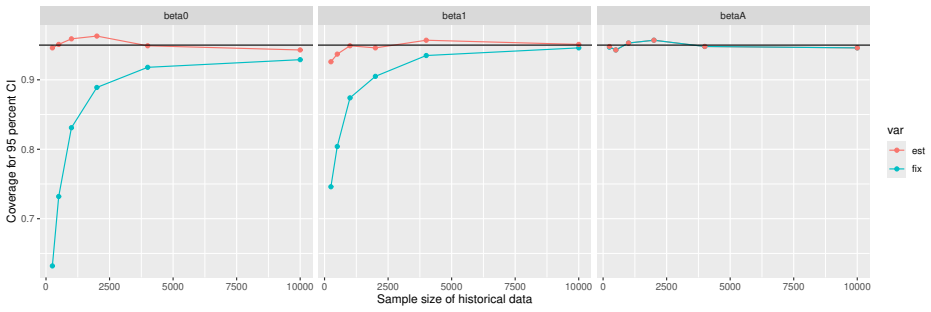
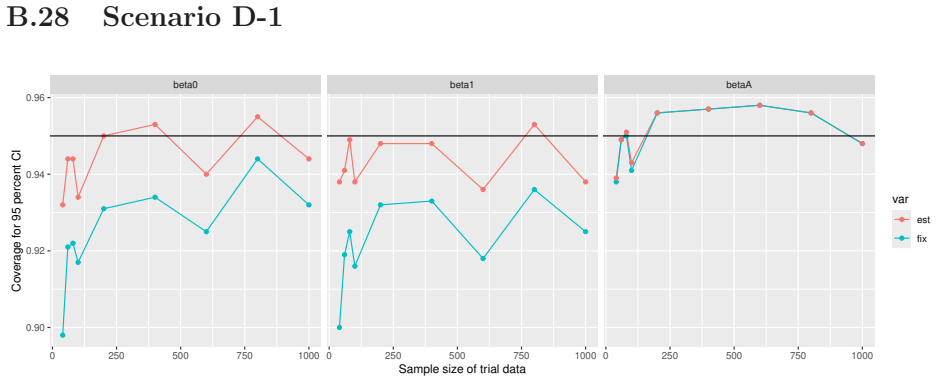
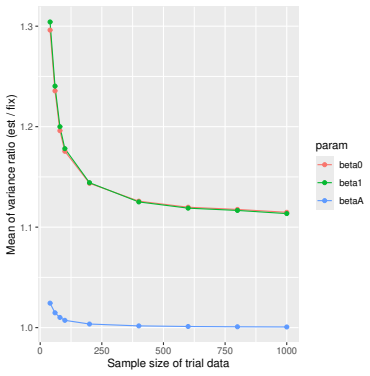
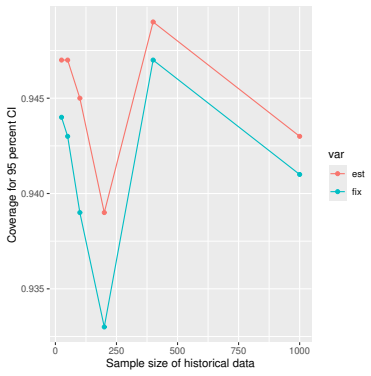
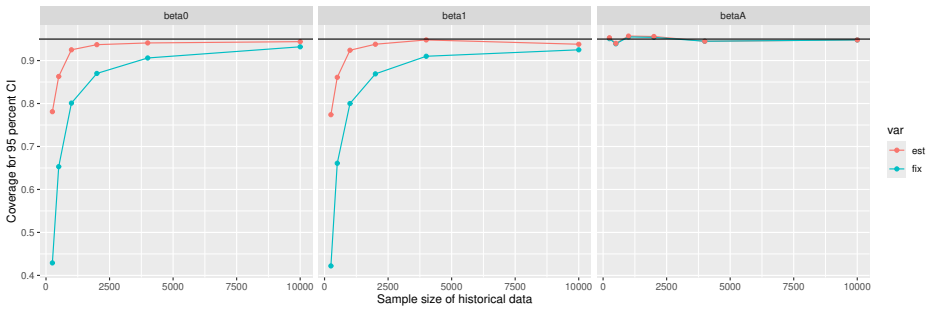
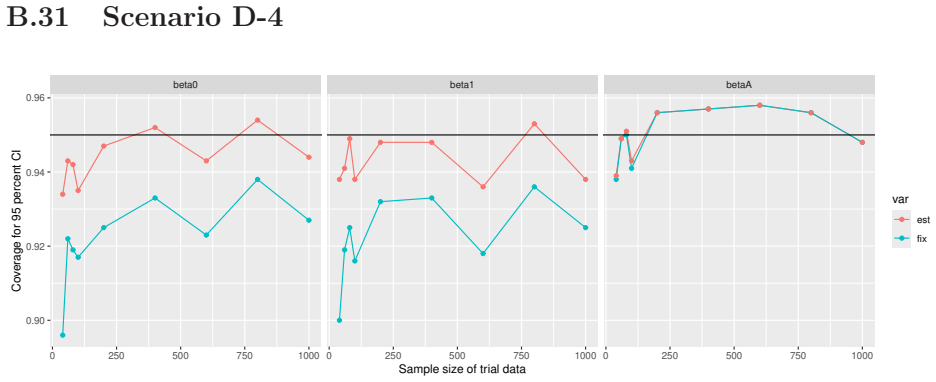
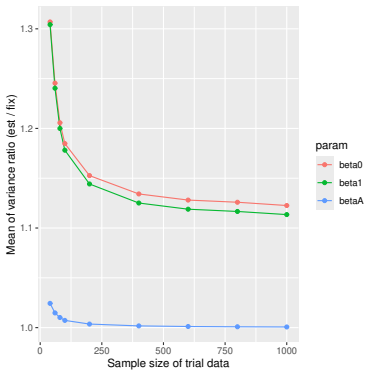
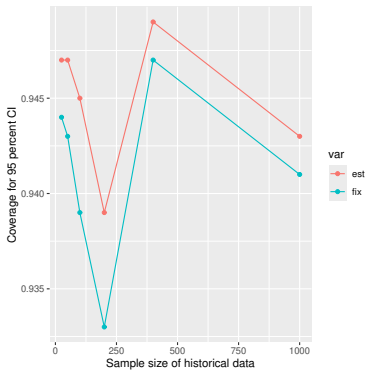
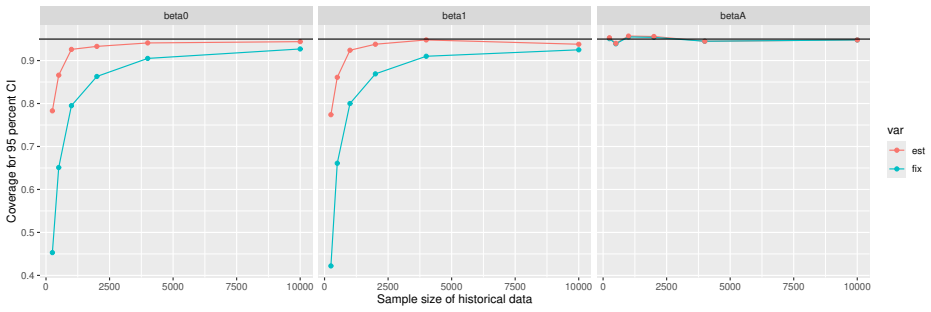
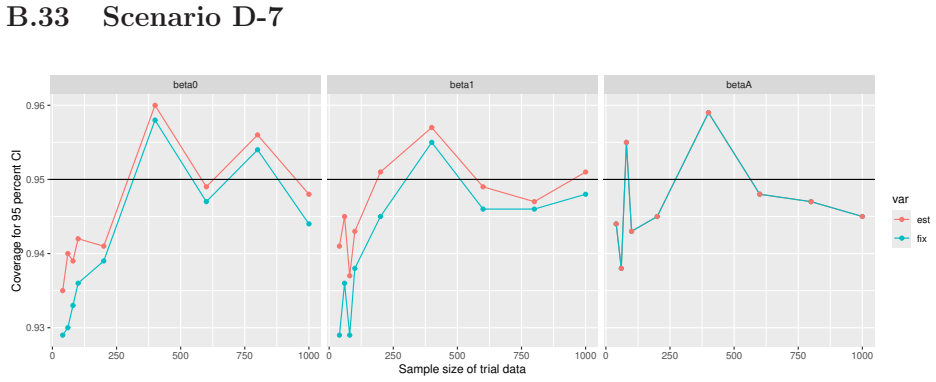
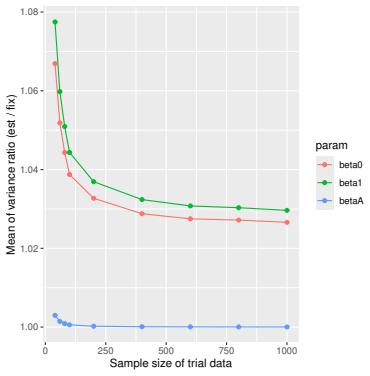
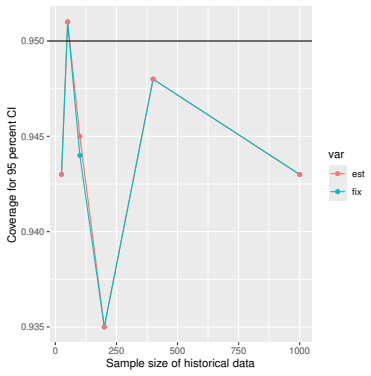
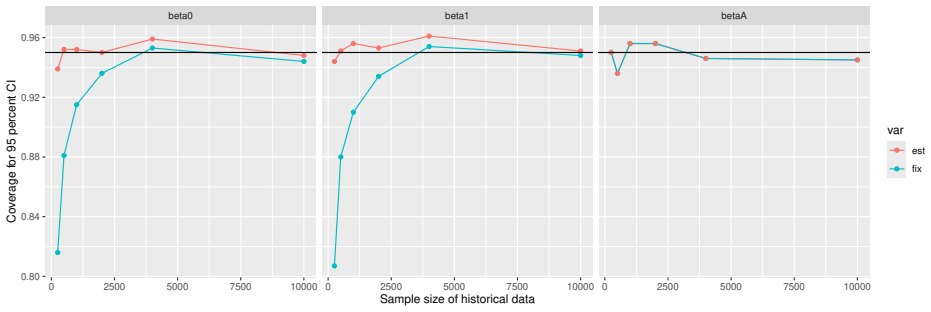
read the original abstract
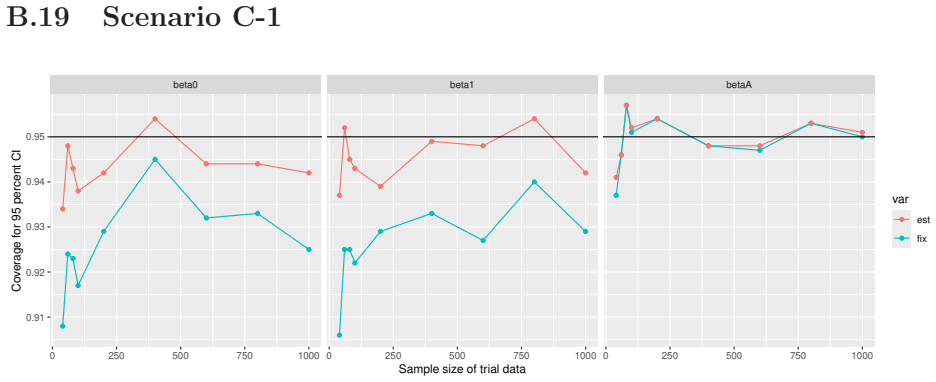
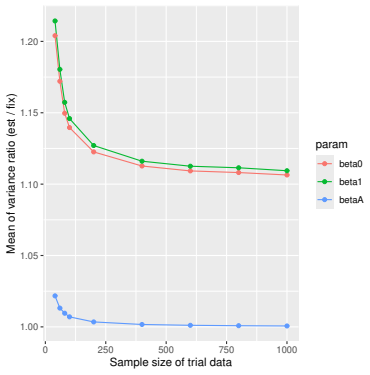
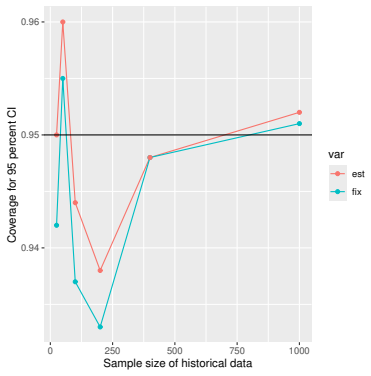
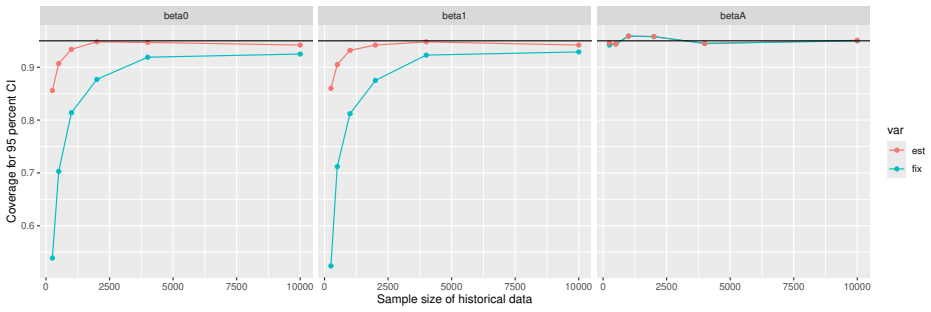
Prognostic covariate adjustment (PROCOVA) is a two-sample two-stage estimation method used in randomized controlled trials. In the first stage, a prognostic score, defined as the conditional expectation of an outcome given covariates under the control treatment, is estimated using historical data. In the second stage, analysis of covariance with the estimated prognostic score and treatment assignment as explanatory variables is performed, and the average treatment effect is estimated. Although the prognostic score is estimated in this procedure, the variance estimator, which treats the prognostic score as known, has been used. Furthermore, the difference in the asymptotic variance between cases where the prognostic score is known versus where it is estimated has not been previously clarified. In this study, we derived these two asymptotic variances and showed that they are equal. We also constructed two variance estimator: one that treats the prognostic score as known, and another that accounts for its estimation, and compared their performance through simulation studies and data applications. For PROCOVA, since both variance estimators are asymptotically valid, it is generally recommended to use a variance estimator that treats the prognostic score as known, as it is simpler to derive and implement. However, when historical data is small, a variance estimator that explicitly accounts for prognostic score estimation is recommended if conservative inference is preferred.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives the asymptotic variance of the average treatment effect estimator under prognostic covariate adjustment (PROCOVA) in randomized trials. It shows via two-stage asymptotic expansion that this variance is identical whether the prognostic score (conditional expectation under control) is treated as known or estimated from independent historical data. The authors construct two variance estimators—one treating the score as known and one accounting for its estimation—then compare them in simulations and real-data applications, recommending the simpler known-score estimator except when historical samples are small.
Significance. The equality result supplies a theoretical justification for routine use of the simpler variance estimator that ignores first-stage uncertainty, which is easier to derive and implement. By clarifying that first-stage estimation does not inflate the leading asymptotic variance term under standard regularity and independence conditions, the work removes a practical barrier to wider adoption of PROCOVA while still offering a conservative alternative for small historical data. The simulation and application comparisons provide useful finite-sample guidance.
major comments (1)
- [Theoretical derivation (around the asymptotic expansion)] The central equality rests on the cross-term between first-stage estimation error and the second-stage score vanishing at o_p(1/sqrt(n)). The manuscript should explicitly display this step (including the role of independence between historical and trial samples) rather than invoking it only by reference to standard two-stage theory.
minor comments (2)
- [Abstract and §5] In the abstract and recommendation paragraph, state the precise regularity conditions (correct model specification or consistency of the prognostic estimator, rate requirements on historical sample size) under which the equality and validity of both variance estimators hold.
- [Simulation studies] Clarify in the simulation design whether the historical sample size is varied independently of the trial sample size, and report coverage probabilities for both variance estimators across the full range of historical sizes examined.
Simulated Author's Rebuttal
We appreciate the referee's positive summary and recommendation for minor revision. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Theoretical derivation (around the asymptotic expansion)] The central equality rests on the cross-term between first-stage estimation error and the second-stage score vanishing at o_p(1/sqrt(n)). The manuscript should explicitly display this step (including the role of independence between historical and trial samples) rather than invoking it only by reference to standard two-stage theory.
Authors: We agree that making this step explicit will clarify the derivation. In the revised manuscript, we will expand the asymptotic expansion to explicitly demonstrate that the cross-term between the first-stage estimation error and the second-stage score vanishes at o_p(1/sqrt(n)). This follows directly from the independence of the historical data (used to estimate the prognostic score) and the randomized trial sample, under standard regularity conditions. We will include a detailed calculation or lemma showing this cancellation, rather than only referencing general two-stage theory. revision: yes
Circularity Check
No significant circularity; derivation relies on standard two-stage asymptotics
full rationale
The paper's central claim is that the asymptotic variance of the PROCOVA estimator is identical whether the prognostic score is treated as known or estimated from independent historical data. This equality follows from a standard two-stage asymptotic expansion: the estimator is expanded around the true conditional expectation, the first-stage estimation error contributes an o_p(1/sqrt(n)) term whose covariance with the second-stage score vanishes under the maintained independence between historical and trial data plus standard regularity conditions. No step reduces to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation whose content is itself unverified; the argument is self-contained against external asymptotic theory and does not import uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard regularity conditions for asymptotic expansions of two-stage estimators (consistency of first-stage estimator, bounded moments, correct model specification or at least consistency)
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we derived these two asymptotic variances and showed that they are equal... e⊤Veste = e⊤Vfixe holds if ... a = 0 (Theorem 3: ∂/∂θ⊤ e⊤β∗(θ)|θ=θ∗ = 0 for e=(0,1,0)⊤ under A ⊥ W)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... Vest = Vfix + κ Q−10 Q1 Vθ Q⊤1 (Q−10)⊤ ... Corollary 1: sufficient conditions Vθ=0, κ=0 or a=0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
into ( 15): ˆβn(ˆθ˜n) − ˆβn(θ∗) = − { ∂ ∂β ⊤ Ψ n(β, ¯θ˜n) ⏐ ⏐ ⏐ ⏐β = ˆβ (¯θ˜n) } − 1 { ∂ ∂θ⊤ Ψ n( ˆβn(θ),θ ) ⏐ ⏐ ⏐ ⏐θ=¯θ˜n } (ˆθ˜n − θ∗). By (A2) and (A3), { ∂ ∂β ⊤ Ψ n(β, ¯θ˜n) ⏐ ⏐ ⏐ ⏐β = ˆβ (¯θ˜n) } − 1 p → Q− 1 0 , and { ∂ ∂θ⊤ Ψ n( ˆβn(θ),θ ) ⏐ ⏐ ⏐ ⏐θ=¯θ˜n } p → Q1. Thus, the following holds: ˆβn(ˆθ˜n) − ˆβn(θ∗) = −Q− 1 0 Q1(ˆθ˜n − θ∗) +op(∥ˆθ˜n − θ∗∥)...
-
[2]
can be expressed as follows: ψ (O;β,θ ) = (Y − β ⊤Xθ)Xθ = Y − β ⊤Xθ (Y − β ⊤Xθ)A (Y − β ⊤Xθ)θ⊤W = Y − β0 − βAA − β1θ⊤W (Y − β0 − βAA − β1θ⊤W )A (Y − β0 − βAA − β1θ⊤W )θ⊤W . Thus,Q0 can be expressed as follows: Q0 = E [ ∂ ∂β ⊤ ψ (O;β,θ ∗) ⏐ ⏐ ⏐ β =β ∗ ] = E [ ∂ ∂β ⊤ (Y − β ⊤Xθ∗ )Xθ∗ ⏐ ⏐ ⏐ β =β ∗ ] = − E[Xθ∗X ...
-
[3]
Additionally, assume E[Y 2]< ∞ and E[||W ||2]< ∞ . Then, the following holds: √ n { ˆβ emp n (ˆθ˜n) − ˆβ emp n (θ∗) } = √ n { ˆβn(ˆθ˜n) − ˆβn(θ∗) } +op(1). Proof. By denoting ¯Dθ := 1 n n∑ j=1 θ⊤Wj − E[θ⊤W ], the following holds: θ⊤Wi − 1 n n∑ j=1 θ⊤Wj =θ⊤Wi − E[θ⊤W ] − ¯Dθ. Then, the following holds: X emp θ,i =Bn(θ)Xθ,i, where Bn(θ) = ...
-
[4]
can be expressed as follows: ψ (O;β,θ ) = (Y − β ⊤Xθ)Xθ = Y − β ⊤Xθ (Y − β ⊤Xθ)A (Y − β ⊤Xθ)(θ⊤W − E[θ⊤W ]) = Y − β0 − βAA − β1(θ⊤W − E[θ⊤W ]) {Y − β0 − βAA − β1(θ⊤W − E[θ⊤W ])}A {Y − β0 − βAA − β1(θ⊤W − E[θ⊤W ])}(θ⊤W − E[θ⊤W ]) . Thus,Q0 can be expressed as follows: Q0 = E [ ∂ ∂β ⊤ ψ (O;β,θ ∗) ⏐ ⏐ ⏐ β =β ∗ ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.