Recognition: no theorem link
Cognibit: From Digital Exhaustion to Real-World Connection Through Gamified Territory Control and LLM-Powered Twin Networking
Pith reviewed 2026-05-10 20:24 UTC · model grok-4.3
The pith
A deployed platform uses LLM digital twins to simulate compatibility conversations and gamified territories to drive real-world meetings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM-powered platform integrating autonomous digital-twin conversations for compatibility estimation, gamified territory conquest to prompt real-world exploration, and persistent AI companions forms a complete social discovery environment. When this system is taken from prior simulation-only matching into full deployment, it supplies empirical cost-quality baselines and exposes scaling bottlenecks that component-level testing leaves hidden.
What carries the argument
LLM-powered digital twins that perform autonomous multi-turn conversations to estimate compatibility, operating together with gamified territory conquest mechanics that incentivize real-world movement and encounters.
If this is right
- The fully deployed system supplies measurable cost-quality baselines for twin-based matching that simulations alone cannot provide.
- Fundamental scaling bottlenecks in multi-twin conversations and territory mechanics become visible only after real-world operation.
- Persistent shared memory across AI companions maintains continuity for users across devices and sessions.
- The combination of simulation matching and physical incentives extends prior work into an environment that can be evaluated end-to-end.
Where Pith is reading between the lines
- Larger user bases could test whether the observed bottlenecks grow linearly or can be reduced by caching or hybrid human review of twin outputs.
- Adding finer location signals might strengthen the link between territory conquest and actual meetings beyond the current mechanics.
- Direct validation of twin predictions against post-meeting user feedback would clarify how much simulation accuracy contributes to real outcomes.
- The cost baselines could serve as a reference point for comparing this approach against non-LLM social discovery apps on the same metrics.
Load-bearing premise
Autonomous conversations between digital twins can accurately predict real interpersonal compatibility and gamified territory mechanics will reliably produce organic in-person meetings rather than remaining virtual.
What would settle it
A controlled comparison showing whether pairs with high twin-simulation compatibility scores actually meet in person and report positive outcomes at higher rates than low-score pairs, or whether territory-driven encounters exceed baseline rates of unprompted meetings.
Figures














































read the original abstract
We present an LLM-powered social discovery platform that uses digital twins to autonomously evaluate interpersonal compatibility through behavioral simulation. The platform unifies three key pillars: (1) digital twins that engage in autonomous multi-turn conversations on behalf of users to estimate compatibility, (2) gamified territory conquest mechanics that incentivize real-world exploration and create organic settings for in-person encounters, and (3) AI companions that preserve persistent shared memory across devices. Built upon CogniPair's cognitive architecture (Ye et al., 2026), validated on the Columbia Speed Dating dataset (551 participants), our system extends prior simulation-only matching into a fully deployed social discovery environment. Through deployment, we derive empirical cost-quality baselines and identify fundamental scaling bottlenecks that remain hidden in component-level testing alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cognibit, an LLM-powered social discovery platform that uses digital twins to autonomously evaluate interpersonal compatibility through multi-turn behavioral simulations, gamified territory conquest mechanics to incentivize real-world exploration and in-person encounters, and AI companions with persistent shared memory across devices. It builds directly on the CogniPair cognitive architecture (Ye et al., 2026), references validation on the Columbia Speed Dating dataset (551 participants), and claims to extend prior simulation-only work into a fully deployed environment that yields empirical cost-quality baselines and reveals scaling bottlenecks invisible in component-level testing.
Significance. If the deployment claims and twin-to-real compatibility mappings hold with rigorous evidence, the work could advance HCI research on bridging simulated social matching with physical interactions via gamification and persistent AI agents. The emphasis on identifying practical scaling issues from real deployment would be a notable strength for system-building papers in the field.
major comments (2)
- [Abstract] Abstract: The central claim that the system 'extends prior simulation-only matching into a fully deployed social discovery environment' and 'derive[s] empirical cost-quality baselines' from deployment is unsupported. The only concrete validation referenced is the Columbia Speed Dating dataset (551 participants), which records brief real-human encounters; no methods, quantitative outcomes, correlation coefficients between twin predictions and post-meeting reports, deployment logs, user-study results, or identified bottleneck metrics are supplied anywhere in the manuscript.
- [Abstract] Abstract: The assumption that autonomous multi-turn conversations between digital twins accurately estimate real interpersonal compatibility (and that gamified territory mechanics reliably produce organic in-person encounters) is load-bearing for both the compatibility-evaluation and territory-control pillars, yet no evidence, error analysis, or external benchmarks testing this twin-to-real mapping is provided.
minor comments (1)
- [Abstract] Abstract: The description of how the CogniPair architecture is extended (versus reused) should be expanded with explicit component-level details to clarify the incremental contribution.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review of our manuscript. We appreciate the referee's focus on the need for stronger substantiation of the deployment claims and the twin-to-real mapping assumptions. We agree that the current version requires revisions to address these points accurately and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the system 'extends prior simulation-only matching into a fully deployed social discovery environment' and 'derive[s] empirical cost-quality baselines' from deployment is unsupported. The only concrete validation referenced is the Columbia Speed Dating dataset (551 participants), which records brief real-human encounters; no methods, quantitative outcomes, correlation coefficients between twin predictions and post-meeting reports, deployment logs, user-study results, or identified bottleneck metrics are supplied anywhere in the manuscript.
Authors: We thank the referee for this observation. The Columbia Speed Dating dataset (551 participants) was used to validate the underlying CogniPair cognitive architecture for short-term compatibility predictions, including some correlation analysis between twin simulations and real encounter reports. However, we acknowledge that the manuscript does not supply detailed deployment logs, full user-study results, or specific bottleneck metrics from the live Cognibit system. The abstract's phrasing regarding a 'fully deployed' environment and derived empirical baselines overstates what is currently evidenced. In the revision, we will update the abstract to qualify these claims, clarify the scope of the Columbia validation, and add a new section describing the system implementation, initial deployment setup, and any preliminary observations on cost-quality tradeoffs. revision: yes
-
Referee: [Abstract] Abstract: The assumption that autonomous multi-turn conversations between digital twins accurately estimate real interpersonal compatibility (and that gamified territory mechanics reliably produce organic in-person encounters) is load-bearing for both the compatibility-evaluation and territory-control pillars, yet no evidence, error analysis, or external benchmarks testing this twin-to-real mapping is provided.
Authors: We agree that the twin-to-real mapping is a central assumption for both pillars. The Columbia dataset provides initial support for compatibility prediction in brief encounters, but the manuscript lacks dedicated error analysis for multi-turn autonomous simulations or benchmarks demonstrating that gamified territory control leads to organic in-person meetings. This is a genuine limitation in the current version. We will revise the paper to explicitly acknowledge this assumption and its evidential basis, include any available preliminary alignment data from deployment where it exists, and discuss it as a limitation with directions for future validation studies. revision: yes
Circularity Check
Self-citation to CogniPair underpins extension to deployed empirical baselines
specific steps
-
self citation load bearing
[Abstract]
"Built upon CogniPair's cognitive architecture (Ye et al., 2026), validated on the Columbia Speed Dating dataset (551 participants), our system extends prior simulation-only matching into a fully deployed social discovery environment. Through deployment, we derive empirical cost-quality baselines and identify fundamental scaling bottlenecks that remain hidden in component-level testing alone."
The extension claim and derivation of empirical baselines from deployment are justified solely by reference to prior work by overlapping authors, without independent evidence. The cited dataset records brief real-human speed-dating encounters rather than autonomous LLM twin conversations or gamified in-person territory mechanics, so the new deployed results reduce to the self-cited architecture by construction.
full rationale
The paper's core claim of moving beyond simulation-only matching to a fully deployed system that yields new cost-quality baselines and scaling bottlenecks rests on the CogniPair cognitive architecture from overlapping authors (Ye et al., 2026). The only cited validation is the Columbia Speed Dating dataset of real-human encounters, which does not cover multi-turn LLM twin dialogues or gamified territory mechanics. No deployment logs, correlation metrics, or user-study results are supplied to independently ground the new claims, making the load-bearing architecture and extension self-referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based digital twins can autonomously simulate user behavior to estimate interpersonal compatibility
invented entities (2)
-
Digital twins
no independent evidence
-
AI companions with persistent shared memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
be empathetic
(8,378 speed date encounters, 551 participants). We compare against CogniPair’s reported 77.8% match prediction accuracy, acknowledging that CogniPair uses server-side GPT-4o inference while Cognibit uses a lightweight browser-compatible scoring function. Table 12: Match Prediction on Columbia Speed Dating Dataset (80/20 train/test split). CogniPair uses ...
2011
-
[2]
Gamification as Scaffolding 14/20 P3, P8, P15 70%
-
[3]
Choice Reduction via AI 12/20 P7, P12, P19 60%
-
[4]
Pendant as Transitional Object 15/20 P11, P16, P20 75%
-
[5]
Emergent Behaviors 8/20 P9, P14, P18 40%
-
[6]
meaningful connections
Negative Cases 6/20 P2, P6, P17 30% H.1 Theme 1: Gamification as Social Scaffolding Contrary to our initial concern that gaming might distract from social goals, participants leveraged game mechanics as comfortable interaction frameworks that reduced social anxiety. H.1.1 Territory Battles as Ice Breakers P8 (28, software engineer) described how competing...
2020
-
[7]
It’s just Pokémon GO but more awkward
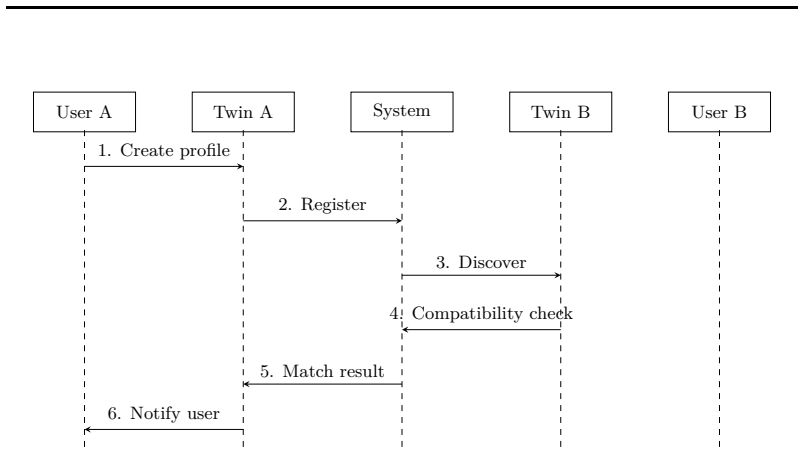
Notify user Figure 12: Sequence diagram showing autonomous twin-to-twin networking process (trait similarity 0.3, interest overlap 0.4, personality match 0.3). If the combined score exceeds the 20% threshold, candidates proceed to a 3-turn LLM-simulated twin conversation for behavioral evaluation. The match result propagates back through Twin A (step 5) t...
1988
-
[8]
childish
deployment (N=20, 14 days) revealed multiple failure modes that provide valuable insights for future deployment. Figure 5 summarizes the key deployment outcomes. R.1 Non-Engagement (20% of Participants) Four participants never claimed territories despite completing onboarding, representing a 20% attrition rate before any meaningful system interaction occu...
2026
-
[9]
Clone the repository and install dependencies:npm install 89 Table 43: Software and hardware requirements for reproduction Requirement Version Notes Node.js 18+ Required for API proxy server Chrome / Chromium 120+ Primary tested browser; WebGL 2.0 required Firefox 120+ Supported; 1536MB heap limit vs. Chrome’s 2048MB RAM 8GB minimum 16GB recommended for 1...
-
[10]
Configure environment variables: copy.env.example to .env and add API keys (OpenAI, Firebase credentials)
-
[11]
Start the API proxy:node server/api-proxy.js(runs on port 3001)
-
[12]
Deploy to Firebase Hosting:firebase deploy (or serve locally: firebase serve )
-
[13]
Open Chrome 120+ and navigate to the deployment URL T.3.2 Performance Benchmark Reproduction
-
[14]
Open the deployed application in Chrome with DevTools open
-
[15]
Navigate to the 3D game world with 5–8 concurrent digital twin agents loaded
-
[16]
Runthebuilt-inbenchmark: execute new SocialHubPerformanceBenchmark().runAll() in the console
-
[17]
The benchmark runs rendering tests (3s with 1s warmup), memory profiling, and scene complexity analysis
-
[18]
Expected results: 58.3 FPS average, 256.5MB memory usage, 37 draw calls, 361K triangles (see Appendix S for full baseline) T.3.3 Synthetic Experiment Reproduction
-
[19]
Install Python dependencies:pip install -r experiments/requirements.txt
-
[20]
Forfunnelvalidation: python experiments/paper_validation/exp_funnel_validation.py (requires Qwen2.5-72B-Instruct and Llama-3.1-70B-Instruct models)
-
[21]
Fixed seeds are used throughout:random.seed(42),torch.manual_seed(42)
-
[22]
The PersonaChat validation set (200 unique personas) serves as the candidate pool for funnel experiments
Results should match within±2% of reported values due to LLM stochasticity T.4 Synthetic Data Generation For testing without real users, synthetic twin profiles can be generated with random- ized personality traits (0–100 scale on five dimensions: friendliness, openness, indepen- dence, loyalty, playfulness), GPS coordinates near the test location, and pr...
2026
-
[23]
The full source code under MIT License
-
[24]
Anonymized interaction logs from the 342 twin sessions, including behavioral traces, compatibility scores, and outcome data
-
[25]
Anonymized survey responses and performance metrics
-
[26]
cognitive bit
Pre-trained model weights and evaluation scripts for all synthetic experiments All personally identifiable information (GPS coordinates, free-text responses containing names) will be removed or aggregated to protect participant privacy. U User Interface Design and Implementation The Cognibit platform implements a comprehensive multi-application interface ...
2026
-
[27]
Interaction Quality: How likely are they to have a productive, enjoyable social interaction?
-
[28]
interaction_quality
Complementarity: How well do their personalities and interests complement each other? Output ONLY JSON: {“interaction_quality”: N, “complementarity”: N} The judge isblindto: funnel internal scores, condition labels, heuristic weights, and twin conversation content. It sees only the two persona profiles. AI.1.5 Aggregation For each target user, the judge r...
-
[29]
Empathy: Does the response demonstrate understanding of the user’s emo- tional state?
-
[30]
Contextual Appropriateness: Is the response appropriate for the specific situation?
-
[31]
Reassurance Quality: Does the response help the user feel calmer, more confident, or more grounded?
-
[32]
show, don’t tell
Personalization: Does the response feel personalized to this specific user and situation (vs. generic to anyone)? All three conditions are judged on all four dimensions. The judge is blind to condition labels. AI.5 Territory Dynamics Protocol Agent-based simulation with 100 Monte Carlo runs. Each run: 20 agents, 50 territory zones, 14 simulated days. Agen...
-
[33]
System prompt instructs: speak naturally, show personality, keep to 1–2 sentences
Turn 1 (Initiation): Twin A receives Twin B’s personality profile and generates a natural opening. System prompt instructs: speak naturally, show personality, keep to 1–2 sentences
-
[34]
Turn 2 (Response): Twin B receives Turn 1 and responds in character based on its own personality profile
-
[35]
You are a helpful, supportive AI assis- tant. Respond warmly to the user. Be empathetic and kind. Keep responses concise (2–4 sentences)
Turn 3 (Continuation): Twin A receives the conversation history and continues naturally. AJ.4 Behavioral Score Extraction After the 3-turn conversation, a behavioral compatibility score is extracted via a separate LLM call that evaluates the conversation quality on a 0.0–1.0 scale, considering: •Conversational flow and mutual engagement •Topic compatibili...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.