Linear convergence of Gearhart-Koshy accelerated Kaczmarz methods for tensor linear systems
Pith reviewed 2026-05-10 18:38 UTC · model grok-4.3
The pith
The generalized Gearhart-Koshy accelerated Kaczmarz method for tensor linear systems converges linearly to the unique least-norm solution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
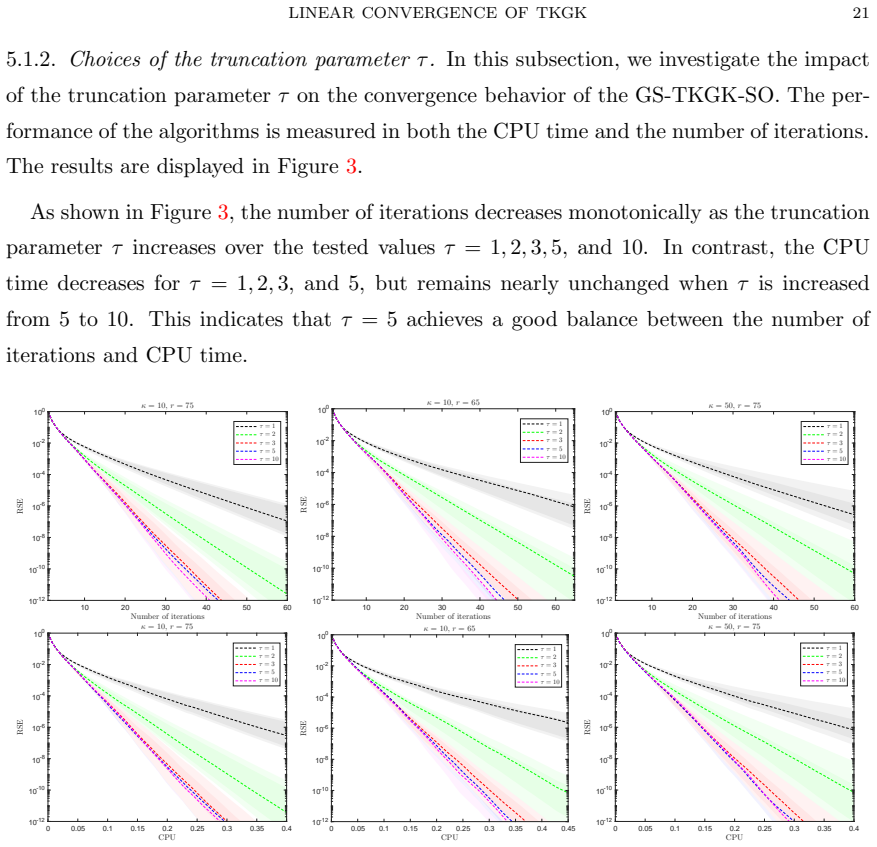
The generalized Gearhart-Koshy acceleration applied to the Kaczmarz method for tensor linear systems yields linear convergence to the unique least-norm solution. This holds for cyclic, incremental, shuffle-once, and random-reshuffling schemes, with an improved convergence upper bound compared to the plain Kaczmarz method.
What carries the argument
The generalized Gearhart-Koshy acceleration, an exact affine search technique for successive orthogonal projections onto hyperplanes in the tensor setting.
If this is right
- The accelerated scheme applies directly to incremental, shuffle-once, and random-reshuffling Kaczmarz variants on tensors.
- It supplies a strictly better convergence upper bound than the unaccelerated Kaczmarz method for the same ordering.
- A Gram-Schmidt implementation computes each new iterate in linear time relative to the problem size.
- The acceleration framework is equivalent to a short Arnoldi-type Krylov step, opening the door to hybrid solvers.
- Numerical tests on random and structured tensor systems confirm the predicted linear rates.
Where Pith is reading between the lines
- Because the acceleration is an exact line search, the same device could be inserted into other projection or splitting methods that operate on high-order arrays.
- The linear-time Gram-Schmidt step suggests these methods remain feasible even when the tensor dimensions are thousands in each mode.
- The Krylov connection implies that further acceleration may be obtained by enlarging the search subspace beyond one dimension while preserving the projection property.
- Relaxing the unique-solution assumption would allow the same machinery to be analyzed for inconsistent systems or minimum-norm least-squares problems.
Load-bearing premise
The tensor linear system admits a unique least-norm solution, which requires consistency together with range conditions on the tensor operator that make the feasible set a singleton orthogonal to the null space.
What would settle it
A concrete tensor linear system together with an explicit starting point for which the accelerated iterates fail to exhibit linear error reduction or do not approach the least-norm solution.
Figures




read the original abstract
The generalized Gearhart-Koshy acceleration is a recent exact affine search technique designed for the method of cyclic projections onto hyperplanes, i.e., the Kaczmarz method. However, its convergence properties, particularly the linear convergence rate, have not been thoroughly established. In this paper, we systematically establish the linear convergence of the generalized Gearhart-Koshy accelerated Kaczmarz method for tensor linear systems, proving that it converges linearly to the unique least-norm solution. Our analysis is general and applies to several popular Kaczmarz variants, including incremental, shuffle-once, and random-reshuffling schemes, and demonstrates that this acceleration approach yields a better convergence upper bound compared to the plain Kaczmarz method. We also propose an efficient Gram-Schmidt-based implementation that computes the next iterate in linear time. Building on this implementation, we establish a connection between this acceleration framework and Arnoldi-type Krylov subspace methods, further highlighting its efficiency and potential. Our theoretical results are supported by numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes linear convergence of the generalized Gearhart-Koshy accelerated Kaczmarz method for consistent tensor linear systems possessing a unique least-norm solution. It extends the standard cyclic-projection argument to the exact line-search acceleration step, derives a strictly smaller contraction factor than the unaccelerated Kaczmarz iteration, and shows that the same analysis covers incremental, shuffle-once, and random-reshuffling variants. An efficient Gram-Schmidt implementation is proposed that runs in linear time per iteration, and a connection to Arnoldi-type Krylov methods is derived as a corollary. Numerical experiments on small consistent instances confirm the predicted rates.
Significance. If the central derivation holds, the work supplies a parameter-free acceleration with a provably improved linear rate for projection methods on tensor equations, together with explicit coverage of several popular Kaczmarz variants and an efficient implementation. These elements constitute a clear strengthening of existing convergence theory for Kaczmarz-type solvers in the tensor setting and may be useful for large-scale applications where tensor linear systems appear.
minor comments (3)
- [§3.2] §3.2, after Eq. (3.7): the transition from the two-step error recursion to the single-step contraction factor is stated without an intermediate inequality; inserting the missing step would make the comparison with the plain Kaczmarz rate fully explicit.
- [Table 1] Table 1: the reported iteration counts for the accelerated method are given only for one random seed; adding a second column with standard deviation over 10 independent runs would strengthen the empirical support for the theoretical rate improvement.
- [§4.1] §4.1: the statement that the Gram-Schmidt implementation 'computes the next iterate in linear time' is correct only when the number of rows is fixed; a brief remark on the dependence on the tensor order would avoid potential misreading.
Simulated Author's Rebuttal
We thank the referee for the careful reading and positive assessment of our manuscript, including the accurate summary of our contributions and the recommendation for minor revision. No specific major comments were raised.
read point-by-point responses
-
Referee: No major comments were provided; the report consists of a summary, significance statement, and minor-revision recommendation.
Authors: We appreciate the referee's recognition that the central derivation supplies a parameter-free acceleration with a provably improved linear rate, explicit coverage of the listed Kaczmarz variants, and an efficient Gram-Schmidt implementation. We will incorporate minor revisions to improve exposition, add a short remark on the connection to Arnoldi methods in the introduction, and correct any typographical issues. revision: yes
Circularity Check
No significant circularity in the convergence proof
full rationale
The manuscript establishes linear convergence of the generalized Gearhart-Koshy accelerated Kaczmarz iteration for consistent tensor linear systems possessing a unique least-norm solution. The derivation proceeds from explicit range conditions on the tensor operator, applies the standard cyclic-projection error recursion, and obtains a strictly improved contraction factor for the exact line-search step; the same recursion covers the listed variants without introducing fitted parameters or self-referential definitions. Assumptions are stated up front, the Gram-Schmidt implementation and Arnoldi link are corollaries rather than load-bearing steps, and no equation reduces the claimed rate to a quantity defined by the result itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The tensor linear system has a unique least-norm solution.
- standard math Orthogonal projections onto hyperplanes satisfy the usual geometric properties in the underlying Hilbert space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We systematically establish the linear convergence of the generalized Gearhart-Koshy accelerated Kaczmarz method for tensor linear systems, proving that it converges linearly to the unique least-norm solution.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the iteration sequence {X_k} generated by Algorithm 1 satisfies ||X_{k+1}-X_0^*||_F² ≤ ρ_πk ||X_k-X_0^*||_F² with ρ_πk<1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. Ahn, C. Yun, and S. Sra. SGD with shuffling: optimal rates without component convexity and large epoch requirements. Advances in Neural Information Processing Systems , 33:17526–17535, 2020
work page 2020
-
[2]
Z.-Z. Bai and W.-T. Wu. On greedy randomized Kaczmarz met hod for solving large sparse linear systems. SIAM Journal on Scientific Computing , 40(1):A592–A606, 2018
work page 2018
-
[3]
W. Bao, F. Zhang, W. Li, Q. Wang, and Y. Gao. Randomized ave rage Kaczmarz algorithm for tensor linear systems. Mathematics, 10(23):4594, 2022
work page 2022
-
[4]
A. Castillo, J. Haddock, I. Hartsock, P. Hoyos, L. Kassab , A. Kryshchenko, K. Larripa, D. Needell, S. Suryanarayanan, and K. Y. Djima. Block Gauss-Seidel meth ods for t-product tensor regression. arXiv preprint arXiv:2503.19155 , 2025
-
[5]
A. Castillo, J. Haddock, I. Hartsock, P. Hoyos, L. Kassab , A. Kryshchenko, K. Larripa, D. Needell, S. Suryanarayanan, and K. Yacoubou-Djima. Randomized Kacz marz methods for t-product tensor linear systems with factorized operators. arXiv preprint arXiv:2412.10583 , 2024
-
[6]
X. Chen and J. Qin. Regularized Kaczmarz algorithms for t ensor recovery. SIAM Journal on Imaging Sciences, 14(4):1439–1471, 2021
work page 2021
-
[7]
K. Du. Tight upper bounds for the convergence of the rando mized extended Kaczmarz and Gauss–Seidel algorithms. Numerical Linear Algebra with Applications , 26(3):e2233, 2019
work page 2019
-
[8]
W. B. Gearhart and M. Koshy. Acceleration schemes for the method of alternating projections. Journal of Computational and Applied Mathematics , 26(3):235–249, 1989
work page 1989
-
[9]
G. H. Golub and C. F. Van Loan. Matrix computations . JHU press, 2013
work page 2013
- [10]
-
[11]
R. M. Gower, D. Molitor, J. Moorman, and D. Needell. On ad aptive sketch-and-project for solving linear systems. SIAM Journal on Matrix Analysis and Applications , 42(2):954–989, 2021
work page 2021
-
[12]
R. M. Gower and P. Richt´ arik. Randomized iterative met hods for linear systems. SIAM Journal on Matrix Analysis and Applications , 36(4):1660–1690, 2015. 26 YIJIE W ANG, YONGHAN SUN, DEREN HAN, AND JIAXIN XIE
work page 2015
- [13]
-
[14]
D. Han, Y. Su, and J. Xie. Randomized Douglas-Rachford m ethods for linear systems: Improved accuracy and efficiency. SIAM J. Optim. , 34(1):1045–1070, 2024
work page 2024
- [15]
-
[16]
D.-R. Han and J.-X. Xie. A simple linear convergence ana lysis of the randomized reshuffling Kaczmarz method. Journal of the Operations Research Society of China , pages 1–13, 2025
work page 2025
-
[17]
M. Hegland and J. Rieger. Generalized Gearhart-Koshy a cceleration is a Krylov space method of a new type. arXiv preprint arXiv:2311.18305 , 2023
-
[18]
G. T. Herman and L. B. Meyer. Algebraic reconstruction t echniques can be made computationally efficient (positron emission tomography application). IEEE Trans. Medical Imaging , 12:600–609, 1993
work page 1993
-
[19]
H. Jeong and D. Needell. Linear convergence of reshufflin g Kaczmarz methods with sparse constraints. SIAM Journal on Scientific Computing , 47(4):A2323–A2352, 2025
work page 2025
- [20]
- [21]
-
[22]
M. E. Kilmer, K. Braman, N. Hao, and R. C. Hoover. Third-o rder tensors as operators on matrices: A theoretical and computational framework with applicatio ns in imaging. SIAM Journal on Matrix Analysis and Applications , 34(1):148–172, 2013
work page 2013
-
[23]
M. E. Kilmer and C. D. Martin. Factorization strategies for third-order tensors. Linear Algebra and its Applications, 435(3):641–658, 2011
work page 2011
-
[24]
Y. Liao, W. Li, and D. Yang. The accelerated tensor Kaczm arz algorithm with adaptive parameters for solving tensor systems. Applied Numerical Mathematics , 202:100–119, 2024
work page 2024
- [25]
-
[26]
N. Loizou and P. Richt´ arik. Momentum and stochastic mo mentum for stochastic gradient, Newton, proximal point and subspace descent methods. Comput. Optim. Appl. , 77:653–710, 2020
work page 2020
-
[27]
K. Lund. The tensor t-function: A definition for functions of third-order tensor s. Numerical Linear Algebra with Applications , 27(3):e2288, 2020
work page 2020
- [28]
- [29]
- [30]
-
[31]
A. Ma, D. Needell, and A. Ramdas. Convergence propertie s of the randomized extended Gauss-Seidel and Kaczmarz methods. SIAM J. Matrix Anal. A. , 36(4):1590–1604, 2015
work page 2015
-
[32]
Y. Miao, L. Qi, and Y. Wei. Generalized tensor function v ia the tensor singular value decomposition based on the T-product. Linear Algebra and its Applications , 590:258–303, 2020
work page 2020
-
[33]
K. Mishchenko, A. Khaled, and P. Richt´ arik. Random res huffling: Simple analysis with vast improve- ments. Advances in Neural Information Processing Systems , 33:17309–17320, 2020
work page 2020
-
[34]
I. Necoara. Faster randomized block Kaczmarz algorith ms. SIAM Journal on Matrix Analysis and Applications, 40(4):1425–1452, 2019
work page 2019
-
[35]
D. Needell, N. Srebro, and R. Ward. Stochastic gradient descent, weighted sampling, and the randomized Kaczmarz algorithm. Math. Program., 155:549–573, 2016
work page 2016
-
[36]
D. Needell and J. A. Tropp. Paved with good intentions: a nalysis of a randomized block Kaczmarz method. Linear Algebra and its Applications , 441:199–221, 2014
work page 2014
-
[37]
E. Newman and M. E. Kilmer. Nonnegative tensor patch dic tionary approaches for image compression and deblurring applications. SIAM Journal on Imaging Sciences , 13(3):1084–1112, 2020. LINEAR CONVERGENCE OF TKGK 27
work page 2020
-
[38]
L. M. Nguyen, Q. Tran-Dinh, D. T. Phan, P. H. Nguyen, and M . Van Dijk. A unified convergence analysis for shuffling-type gradient methods. J. Mach. Learn. Res. , 22(207):1–44, 2021
work page 2021
-
[39]
L. Reichel and U. O. Ugwu. The tensor Golub-Kahan-Tikho nov method applied to the solution of ill- posed problems with at-product structure. Numerical Linear Algebra with Applications , 29(1):e2412, 2022
work page 2022
-
[40]
J. Rieger. Generalized Gearhart-Koshy acceleration f or the Kaczmarz method. Mathematics of Compu- tation, 92(341):1251–1272, 2023
work page 2023
-
[41]
H. Robbins and S. Monro. A stochastic approximation met hod. Ann. Math. Statistics , pages 400–407, 1951
work page 1951
-
[42]
I. Safran and O. Shamir. How good is SGD with random shuffli ng? In Conference on Learning Theory , pages 3250–3284. PMLR, 2020
work page 2020
-
[43]
F. Sch¨ opfer and D. Lorenz. Linear convergence of the ra ndomized sparse Kaczmarz method. Math. Program., 173:509–536, 2019
work page 2019
-
[44]
S. Soltani, M. E. Kilmer, and P. C. Hansen. A tensor-base d dictionary learning approach to tomographic image reconstruction. BIT Numerical Mathematics , 56:1425–1454, 2016
work page 2016
-
[45]
T. Strohmer and R. Vershynin. A randomized Kaczmarz alg orithm with exponential convergence. Jour- nal of Fourier Analysis and Applications , 15(2):262–278, 2009
work page 2009
-
[46]
Y. Su, D. Han, Y. Zeng, and J. Xie. On greedy multi-step in ertial randomized Kaczmarz method for solving linear systems. Calcolo, 61(4):68, 2024
work page 2024
-
[47]
Y. Su, D. Han, Y. Zeng, and J. Xie. On the convergence anal ysis of the greedy randomized Kaczmarz method. Numerical Algorithms, pages 1–22, 2026
work page 2026
- [48]
-
[49]
M. K. Tam. Gearhart-Koshy acceleration for affine subspa ces. Operations Research Letters, 49(2):157– 163, 2021
work page 2021
-
[50]
L. Tang, Y. Yu, Y. Zhang, and H. Li. Sketch-and-project m ethods for tensor linear systems. Numerical Linear Algebra with Applications , 30(2):e2470, 2023
work page 2023
- [51]
-
[52]
B. Ying, K. Yuan, S. Vlaski, and A. H. Sayed. Stochastic l earning under random reshuffling with constant step-sizes. IEEE Trans. Signal Process. , 67(2):474–489, 2018
work page 2018
-
[53]
Y. Zeng, D. Han, Y. Su, and J. Xie. Randomized Kaczmarz me thod with adaptive stepsizes for incon- sistent linear systems. Numer. Algorithms , 94:1403–1420, 2023
work page 2023
-
[54]
Y. Zeng, D. Han, Y. Su, and J. Xie. On adaptive stochastic heavy ball momentum for solving linear systems. SIAM Journal on Matrix Analysis and Applications , 45(3):1259–1286, 2024
work page 2024
-
[55]
Y. Zeng, D. Han, Y. Su, and J. Xie. On adaptive stochastic extended iterative methods for solving least squares. Mathematics of Computation , 2025
work page 2025
-
[56]
Y. Zeng, D. Han, Y. Su, and J. Xie. Stochastic dual coordi nate descent with adaptive heavy ball momentum for linearly constrained convex optimization. Numerische Mathematik, 158(2):749–794, 2026
work page 2026
-
[57]
P. Zhou, C. Lu, Z. Lin, and C. Zhang. Tensor factorizatio n for low-rank tensor completion. IEEE Transactions on Image Processing , 27(3):1152–1163, 2017
work page 2017
-
[58]
A. Zouzias and N. M. Freris. Randomized extended Kaczma rz for solving least squares. SIAM Journal on Matrix Analysis and Applications , 34(2):773–793, 2013
work page 2013
-
[59]
Appendix. Proof of the main results 7.1. Proof of Theorem 2.1. 28 YIJIE W ANG, YONGHAN SUN, DEREN HAN, AND JIAXIN XIE Proof of Theorem 2.1. To establish the results, we first note that all iterates of Al gorithm 1 belong to the affine subspace X 0 + rangeK (A†). Indeed, for any 1 ≤ i ≤ m, we have rangeK (A† i::) = range K(A⊤ i::) ⊆ rangeK(A⊤ ) = range K(A†),...
-
[60]
and the inclusion follows from the fact that A⊤ i:: = A⊤ ∗ Ii::. Consequently, Algorithm 1 ensures that X k ∈ X 0 + rangeK(A†). Besides, X 0 ∗ = A† ∗ B + ( I − A † ∗ A ) ∗ X 0 = X 0 + A† ∗ (B − A ∗ X 0) ∈ X 0 + range K(A†), therefore X k − X 0 ∗ ∈ rangeK(A†). Since A† ∗ A is the projector onto range K(A†), it follows (25) A† ∗ A ∗ (X k − X 0 ∗ ) = X k − X...
-
[61]
and ( 10), respectively. Given that ⟨X k − X 0 ∗ , X k − P π k (X k)⟩ = ∥X k − P π k(X k)∥2 F + ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩, it follows that (28) ⟨X k − X 0 ∗ , X k − P π k (X k)⟩2 = ∥X k − P π k (X k)∥4 F + ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩2 + 2∥X k − P π k (X k)∥2 F ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩. From the definition of γk in (
-
[62]
and its equivalent form in ( 11), we have ⟨X k − X 0 ∗ , X k − P π k (X k)⟩ = γk = 1 2 ∥rπ k (X k)∥2 F + 1 2 ∥X k − P π k (X k)∥2 F . Hence, we can rewrite ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩ as (29) ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩ = −∥X k − P π k (X k)∥2 F + ⟨X k − X 0 ∗ , X k − P π k (X k)⟩ = 1 2 ∥rπ k (X k)∥2 F − 1 2 ∥X k − P π k (X k)∥2 ...
-
[63]
and ( 9), respectively. Using the equivalent form of sk k− jk,τ +1 in ( 16), we can further express it as sk k− jk,τ +1 = γk ∥(I − VkV † k )⃗dk∥2 2 = γk ∥⃗dk∥2 2 ( 1 − ∥VkV † k ⃗dk∥2 2 ∥⃗dk∥2 2 )− 1 , where the last equality follows from ∥(I − VkV † k )⃗dk∥2 2 = ∥⃗dk∥2 2 − ∥ VkV † k ∥2 2∥⃗dk∥2
-
[64]
Recall the definitions of γk in (
-
[65]
and ζk in ( 14), it holds that γ 2 k ∥ ⃗dk∥2 2 = ζ2 k ∥X k − X 0 ∗ ∥2 F . As βk = ( 1 − ∥VkV † k ⃗dk∥2 2 ∥ ⃗dk∥2 2 )− 1 in ( 14), we conclude that sk k− jk,τ +1 = β kζ2 k∥X k−X 0 ∗ ∥2 F γk and ∥X k+1 − X 0 ∗ ∥2 F ≤ (1 − βkζ2 k )∥X k − X 0 ∗ ∥2 F . Next, we prove that 1 − βkζ2 k ≤ ∥ bcirc ( Tπ k ∗ A† ∗ A ) ∥2
-
[66]
Since Mk has full column rank, it follows that ⃗dk /∈ Range(Vk). Consequently, because VkV † k is the orthogonal projector onto Range(Vk), it holds that 0 < 1 − ∥VkV † k ⃗dk∥2 2 ∥ ⃗dk∥2 2 ≤ 1, which implies that βk ≥ 1. Therefore, to establish 1 − βkζ2 k ≤ ∥ bcirc ( Tπ k ∗ A† ∗ A ) ∥2 2, it suffices to prove the inequality 1 − ζ2 k ≤ LINEAR CONVERGENCE OF T...
-
[67]
From the definition of ζk in (
-
[68]
and Lemma 7.1, 1− ζ2 k is expressed as 1 − ζ2 k = 1 − rπ k (X k) 2 F ∥X k − X 0∗ ∥2 F − ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩2 ∥X k − X 0∗ ∥2 F ∥X k − P π k (X k)∥2 F .(30) Using the equation in ( 27), We further obtain 1 − ζ2 k ≤ 1 − rπ k (X k) 2 F ∥X k − X 0∗ ∥2 F = Pπ k (X k) − X 0 ∗ 2 F ∥X k − X 0∗ ∥2 F . From the inequality (
-
[69]
If ∥rπ k (X k)∥2 F ̸= ∥X k − P π k (X k)∥2 F , then the last term of (
in the proof of Theorem 2.1, it holds that Pπ k (X k) − X 0 ∗ 2 F ≤ bcirc(Tπ k ∗ A† ∗ A) 2 2 X k − X 0 ∗ 2 F , which results in 1 − ζ2 k ≤ bcirc(Tπ k ∗ A† ∗ A) 2 2 . If ∥rπ k (X k)∥2 F ̸= ∥X k − P π k (X k)∥2 F , then the last term of (
-
[70]
gives ⟨Pπ k (X k) − X 0 ∗ , X k − P π k (X k)⟩2 ∥X k − X 0∗ ∥2 F ∥X k − P π k (X k)∥2 F = ( ∥rπ k (X k)∥2 F − ∥X k − P π k (X k)∥2 F )2 4 ∥X k − X 0∗ ∥2 F ∥X k − P π k (X k)∥2 F > 0, where the equality follows from ( 29). Hence we complete the proof. □ 7.4. Proof of Proposition 4.1 and Theorem 4.2. Proof of Proposition 4.1. We prove by induction on k ≥ 1 ...
-
[71]
By induction, the sequences {⃗ xk}k≥ 0 coincide
Therefore, both algorithms generate the same ⃗ xk+1. By induction, the sequences {⃗ xk}k≥ 0 coincide. □ LINEAR CONVERGENCE OF TKGK 35 School of Mathematical Sciences, Beihang University, Beij ing, 100191, China. Email address : yj wang@buaa.edu.cn School of Mathematical Sciences, Beihang University, Beij ing, 100191, China. Email address : sunyonghan@buaa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.