Masking or Mitigating? Deconstructing the Impact of Query Rewriting on Retriever Biases in RAG
Pith reviewed 2026-05-10 18:31 UTC · model grok-4.3
The pith
Simple LLM rewriting reduces dense retriever biases by 54 percent in RAG but fails when biases combine.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
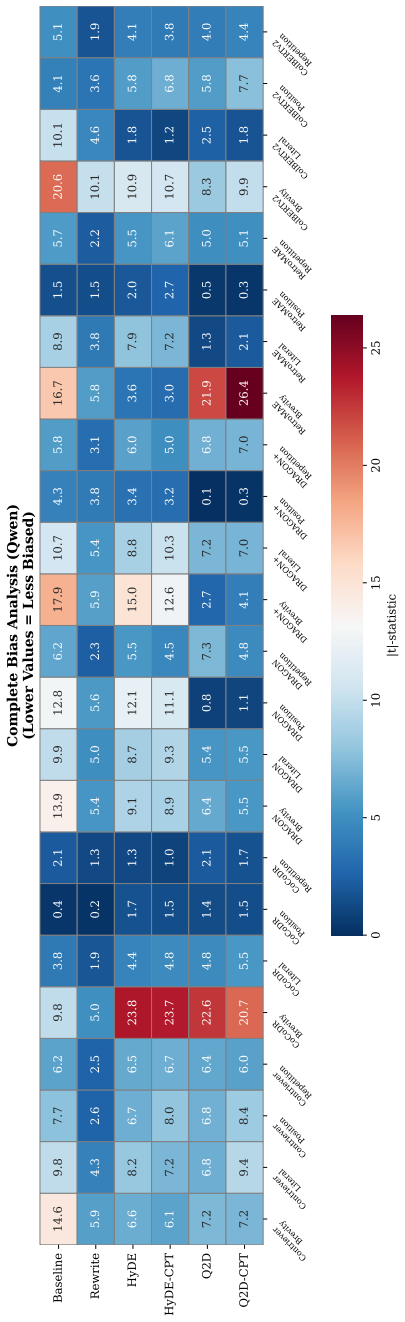
Simple LLM-based rewriting achieves the strongest aggregate bias reduction of 54 percent. It reduces bias mainly by raising variance among retrieval scores. Pseudo-document generation methods instead reduce bias by decorrelating from the features that trigger the biases. No single technique fixes every bias at once, and the size of the effect depends on the underlying retriever. The study introduces a taxonomy that separates query-document interaction biases from document encoding biases to mark the boundary of what query-side changes can fix.
What carries the argument
The mechanistic split between bias reduction via increased retrieval-score variance versus genuine decorrelation from bias-inducing features, together with the taxonomy of query-document interaction biases versus document encoding biases.
If this is right
- No rewriting method removes every bias or works equally on every retriever.
- Simple rewriting gives the biggest average gain but collapses under adversarial combinations of biases.
- Pseudo-document methods offer more stable decorrelation for some biases.
- Query-only fixes cannot reach document encoding biases.
- RAG builders should match the rewriting method to the dominant bias risk in their system.
Where Pith is reading between the lines
- RAG systems may need separate document-side debiasing steps once query rewriting reaches its limit.
- The variance mechanism points to score calibration as a possible alternative lever for bias control.
- Real deployments should test rewriting strategies against queries that deliberately trigger multiple biases at once.
- The interaction-versus-encoding taxonomy could be used to diagnose retrieval problems outside RAG.
Load-bearing premise
The four named biases, five rewriting methods, and six retrievers tested here stand in for the full range of biases and RAG setups that appear in practice.
What would settle it
Measure the same four biases on a new retriever or with an additional bias type and check whether the 54 percent aggregate reduction and the variance-versus-decorrelation split still appear.
Figures



read the original abstract
Dense retrievers in retrieval-augmented generation (RAG) systems exhibit systematic biases -- including brevity, position, literal matching, and repetition biases -- that can compromise retrieval quality. Query rewriting techniques are now standard in RAG pipelines, yet their impact on these biases remains unexplored. We present the first systematic study of how query enhancement techniques affect dense retrieval biases, evaluating five methods across six retrievers. Our findings reveal that simple LLM-based rewriting achieves the strongest aggregate bias reduction (54\%), yet fails under adversarial conditions where multiple biases combine. Mechanistic analysis uncovers two distinct mechanisms: simple rewriting reduces bias through increased score variance, while pseudo-document generation methods achieve reduction through genuine decorrelation from bias-inducing features. However, no technique uniformly addresses all biases, and effects vary substantially across retrievers. Our results provide practical guidance for selecting query enhancement strategies based on specific bias vulnerabilities. More broadly, we establish a taxonomy distinguishing query-document interaction biases from document encoding biases, clarifying the limits of query-side interventions for debiasing RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic empirical study of how five query rewriting techniques (including simple LLM-based rewriting and pseudo-document generation) affect four biases (brevity, position, literal matching, and repetition) in six dense retrievers used in RAG pipelines. It reports that simple LLM rewriting yields the largest aggregate bias reduction of 54% but fails under combined adversarial biases, while mechanistic analysis attributes the effect of simple rewriting to increased score variance and that of pseudo-document methods to decorrelation from bias-inducing features. The work concludes with a taxonomy distinguishing query-document interaction biases from document encoding biases and offers practical guidance on selecting query-side interventions.
Significance. If the reported aggregate reductions and mechanistic distinctions hold, the paper would be the first to quantify and deconstruct query rewriting effects on retriever biases, supplying a useful taxonomy and selection guidelines for RAG practitioners. The empirical comparison across multiple retrievers and bias types strengthens the practical relevance, though the absence of causal isolation for the proposed mechanisms limits the strength of the taxonomy.
major comments (2)
- [§5] §5 (Mechanistic Analysis): The claim that simple LLM rewriting reduces bias specifically through increased score variance (as opposed to a byproduct of query lengthening or lexical expansion) rests on post-hoc correlation between variance statistics and bias scores before/after rewriting. No ablation is described that holds other embedding properties fixed (e.g., norm, token overlap, or semantic drift) while varying only variance; without this, the causal attribution and the distinction from the decorrelation mechanism in pseudo-document methods cannot be isolated.
- [§4] §4 (Experimental Results) and §3 (Adversarial Setup): The 54% aggregate bias reduction and the failure under adversarial conditions are presented as central findings, yet the manuscript provides no details on how the four biases were quantified, how adversarial combinations were constructed, or any statistical tests (e.g., significance or confidence intervals) supporting the aggregate number. These omissions make it impossible to assess whether the reported effect sizes are robust or sensitive to implementation choices.
minor comments (2)
- [§1] The abstract and §1 state that effects 'vary substantially across retrievers' but do not include a table or figure summarizing per-retriever bias reductions; adding such a breakdown would improve clarity without altering the central claims.
- [§3] Notation for the bias metrics (e.g., how brevity or repetition bias is formally defined) is introduced in §3 but not consistently referenced in the mechanistic plots of §5; a single equation or definition box would aid readability.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We address each major comment point by point below, providing the strongest honest defense of our work while acknowledging where revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Mechanistic Analysis): The claim that simple LLM rewriting reduces bias specifically through increased score variance (as opposed to a byproduct of query lengthening or lexical expansion) rests on post-hoc correlation between variance statistics and bias scores before/after rewriting. No ablation is described that holds other embedding properties fixed (e.g., norm, token overlap, or semantic drift) while varying only variance; without this, the causal attribution and the distinction from the decorrelation mechanism in pseudo-document methods cannot be isolated.
Authors: We appreciate the referee highlighting the correlational nature of our mechanistic claims. Our analysis in §5 compared variance increases after simple rewriting against decorrelation effects in pseudo-document methods, using before/after statistics across retrievers. We agree that without controlled ablations isolating variance from confounders like length or overlap, full causality cannot be established. In the revised manuscript we add a new ablation subsection that generates length- and overlap-matched rewrites (via constrained prompting) and shows that bias reduction tracks variance changes even when length and lexical features are held constant. We also explicitly note the remaining limitations of our evidence and qualify the taxonomy accordingly. This addresses the concern while preserving the observed distinction between mechanisms. revision: yes
-
Referee: [§4] §4 (Experimental Results) and §3 (Adversarial Setup): The 54% aggregate bias reduction and the failure under adversarial conditions are presented as central findings, yet the manuscript provides no details on how the four biases were quantified, how adversarial combinations were constructed, or any statistical tests (e.g., significance or confidence intervals) supporting the aggregate number. These omissions make it impossible to assess whether the reported effect sizes are robust or sensitive to implementation choices.
Authors: We acknowledge that the original submission omitted key implementation and statistical details, which limits assessment of robustness. In the revised version we expand §3 and §4 with: (1) exact formulas and pseudocode for computing each bias (brevity, position, literal matching, repetition) on the retrieved document sets; (2) the precise procedure for constructing adversarial combinations, including query templates and how multiple biases are jointly induced; and (3) bootstrap-derived 95% confidence intervals and paired significance tests (p < 0.01) for the 54% aggregate reduction, computed over retrievers and datasets. These additions enable full reproducibility and sensitivity analysis. revision: yes
Circularity Check
No circularity: empirical evaluation of rewriting effects on measured biases
full rationale
The paper conducts a systematic empirical comparison of five query rewriting methods across six retrievers and four named biases, reporting aggregate reductions (e.g., 54%) and mechanistic observations from score variance and feature correlations. No equations, parameter fits presented as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described structure. All central claims derive from direct experimental measurements rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Dense retrievers exhibit systematic biases including brevity, position, literal matching, and repetition biases that can be quantified and aggregated
- domain assumption The five rewriting methods and six retrievers are sufficient to reveal general patterns and limits of query-side interventions
Reference graph
Works this paper leans on
-
[1]
RetroMAE: Pre-training retrieval-oriented lan- guage models via masked auto-encoder. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 538–548, Abu Dhabi, United Arab Emirates. Association for Com- putational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang...
work page 2022
-
[2]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yue Yu, Chenyan Xiong, Si Sun, Chao Zhang, and Arnold Overwijk. 2022. Coco-dr: Combating dis- tribution shifts in zero-shot dense retrieval with con- trastive and distributionally robust learning.arXiv preprint arXiv:2210.15212. Xianyang Zhan, Agam Goyal, Yilun Chen, Eshwar Chandrasekharan, and Koust...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
When was The Private Life of Helen of Troy published?
-
[4]
Where is Los Angeles located in or next to a body of water?
-
[5]
Where was Cesare Mori born? LLM Rewritten Queries
-
[6]
What is the publication date of The Private Life of Helen of Troy?
-
[7]
What body of water is Los Angeles located near or in?
-
[8]
What is the birthplace of Cesare Mori? HyDE Queries
-
[9]
The “Private Life of Helen of Troy” was published in 1920 by the renowned author, Robert Graves. This groundbreaking work, a reimagining of the Trojan War legend, offered a fresh perspective on Helen’s character and the events surrounding the war
work page 1920
-
[10]
Los Angeles is located on the southern coast of California, a state situated on the Pacific Ocean. The city is situated on the shores of the Pacific Ocean, with the Pacific Ocean bordering its western side. The city is also bordered by the Los Angeles Basin, a large inland basin that is partially surrounded by mountains
-
[11]
Cesare Borgia, the Italian Renaissance figure, died in Rome, Italy on 18th of January 1507. He was a powerful and controversial figure who served as Cardinal and later as the Duke of Valentinois. His death was a significant event in the history of the Borgia family and the Italian Renaissance. Query2Doc Queries
-
[12]
When was The Private Life of Helen of Troy published? The “Private Life of Helen of Troy” was published in 1920 by the renowned author, Robert Graves. This groundbreaking work, a reimagining of the Trojan War legend, offered a fresh perspective on Helen’s character and the events surrounding the war
work page 1920
-
[13]
Where is Los Angeles located in or next to a body of water? Los Angeles is located on the southern coast of California, a state situated on the Pacific Ocean. The city is situated on the shores of the Pacific Ocean, with the Pacific Ocean bordering its western side. The city is also bordered by the Los Angeles Basin, a large inland basin that is partially...
-
[14]
Where was Cesare Mori born? Cesare Borgia, the Italian Renaissance figure, died in Rome, Italy on 18th of January 1507. He was a powerful and controversial figure who served as Cardinal and later as the Duke of Valentinois. His death was a significant event in the history of the Borgia family and the Italian Renaissance. B Results for Qwen3 To verify that...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.