Learning-Based Strategy for Composite Robot Assembly Skill Adaptation
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
Composite skills with fixed conditions plus residual learning restricted to contact phases enable robust peg-in-hole assembly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
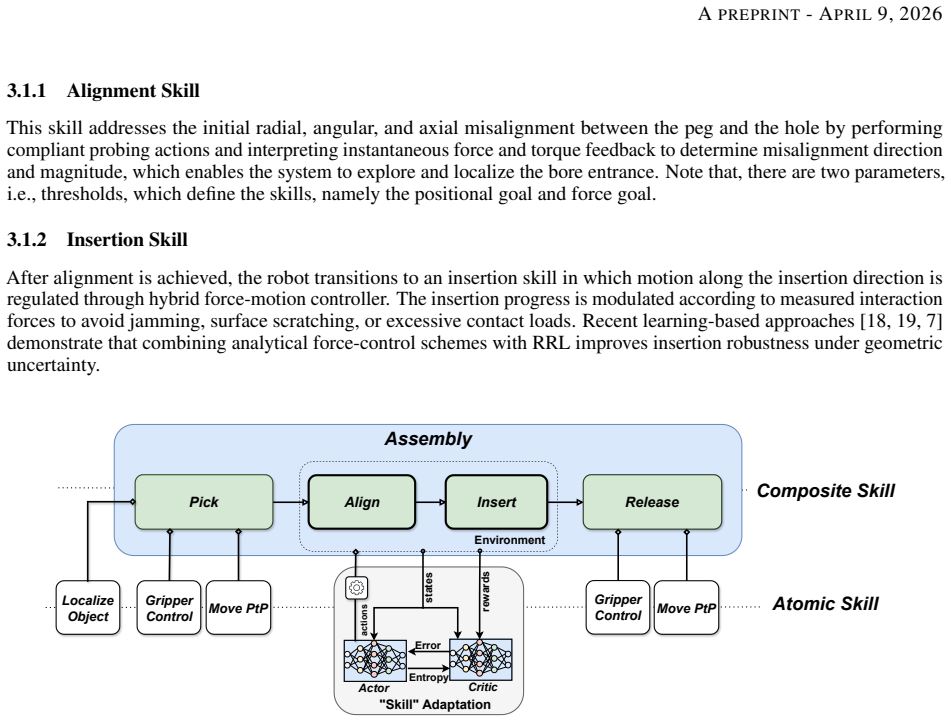
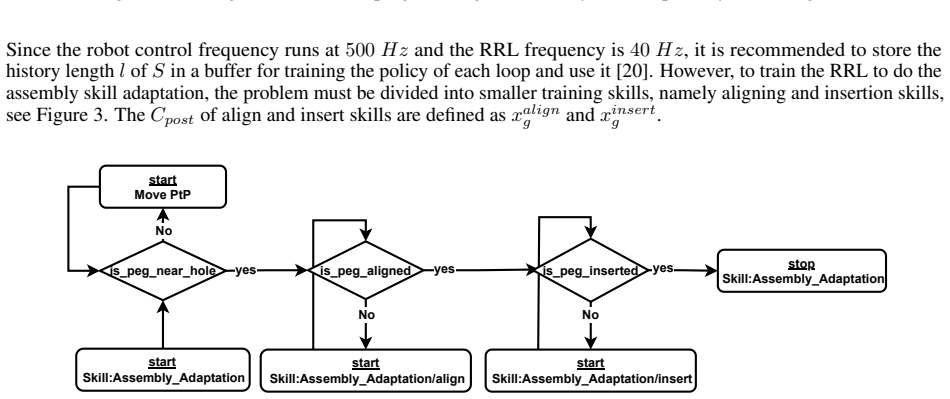
Assembly is represented as a sequence of composite skills whose pre-, post-, and invariant conditions enforce modularity and execution semantics. Residual reinforcement learning is applied only to refine actions within the contact-rich portions of those skills, leaving the skill structure and flow invariant. Training uses SAC in a MuJoCo environment on a UR5e with Robotiq gripper, and the resulting policies produce robust assembly execution under geometric and frictional variability.
What carries the argument
Composite skills defined by explicit pre-, post-, and invariant conditions, with residual policy refinements applied exclusively during contact-rich phases.
If this is right
- Skills can be reused across different peg-in-hole geometries without rewriting the high-level sequence.
- Learning is localized, which limits the search space and preserves the original safety constraints outside contact phases.
- The same skill library can be deployed on position-controlled industrial arms without requiring force/torque sensing at every step.
- Sample efficiency rises because each residual learner trains on a narrow segment rather than the full task.
Where Pith is reading between the lines
- The same separation of fixed structure and local adaptation could be tested on other insertion or fastening tasks that share contact-rich phases.
- If the conditions are made explicit enough, the approach might serve as a template for combining symbolic task planners with learned refinements in broader automation pipelines.
- Physical robot experiments would be needed to check whether simulation-trained residuals transfer when unmodeled effects such as cable stretch or gripper compliance appear.
Load-bearing premise
The pre-, post-, and invariant conditions of the composite skills remain sufficient to guarantee safety and modularity when residual learning is added only inside contact-rich segments.
What would settle it
A single trial in which a trained residual policy causes violation of an invariant condition or repeated failure to seat the peg within tolerance under a new friction value would show the claim does not hold.
Figures

read the original abstract
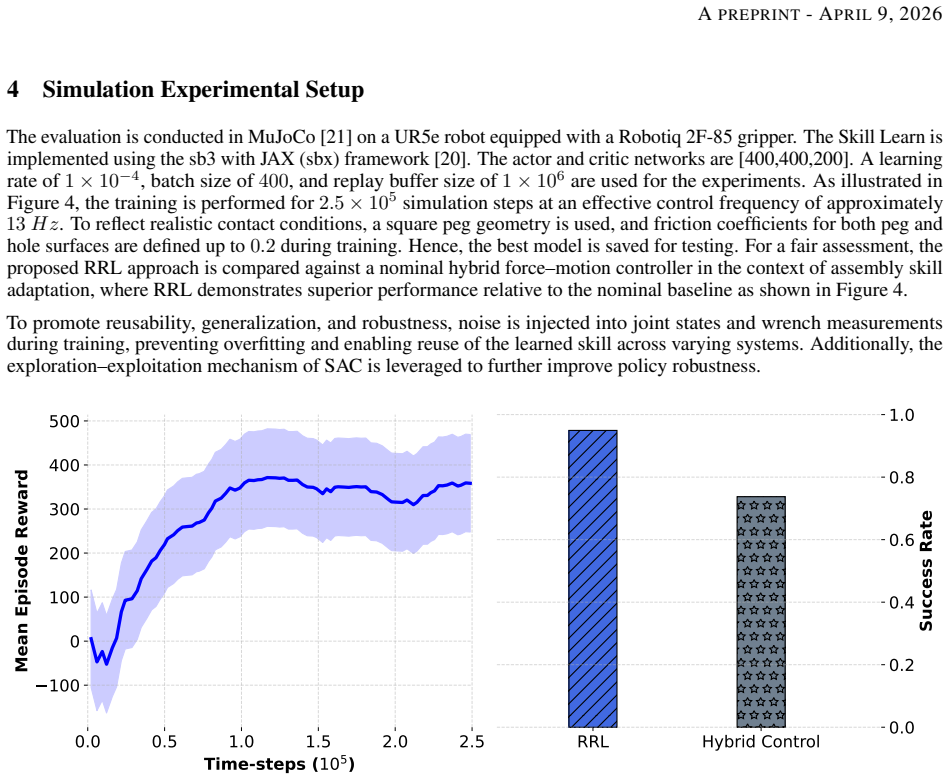
Contact-rich robotic skills remain challenging for industrial robots due to tight geometric tolerances, frictional variability, and uncertain contact dynamics, particularly when using position-controlled manipulators. This paper presents a reusable and encapsulated skill-based strategy for peg-in-hole assembly, in which adaptation is achieved through Residual Reinforcement Learning (RRL). The assembly process is represented using composite skills with explicit pre-, post-, and invariant conditions, enabling modularity, reusability, and well-defined execution semantics across task variations. Safety and sample efficiency are promoted through RRL by restricting adaptation to residual refinements within each skill during contact-rich interactions, while the overall skill structure and execution flow remain invariant. The proposed approach is evaluated in MuJoCo simulation on a UR5e robot equipped with a Robotiq gripper and trained using SAC and JAX. Results demonstrate that the proposed formulation enables robust execution of assembly skills, highlighting its suitability for industrial automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a composite skill-based framework for peg-in-hole assembly in which explicit pre-, post-, and invariant conditions define modular, reusable skills with well-defined execution semantics. Adaptation to contact-rich variations is performed exclusively via Residual Reinforcement Learning (RRL) that refines actions only inside designated sub-skills, while the overall skill structure and flow remain fixed. The approach is implemented and tested in MuJoCo on a UR5e manipulator with Robotiq gripper, using SAC trained in JAX, and is claimed to deliver robust execution suitable for industrial automation.
Significance. If the central claims are substantiated, the work would demonstrate a practical route to combining structured, safety-preserving skill representations with targeted learning, thereby improving reusability and sample efficiency for contact-rich industrial tasks. The restriction of learning to residuals inside invariant-bounded phases is a conceptually attractive way to retain modularity while addressing frictional and geometric variability.
major comments (2)
- [Abstract / Approach] Abstract and approach description: the claim that 'the overall skill structure and execution flow remain invariant' and that safety is promoted rests on the assumption that SAC residuals cannot violate the pre-/post-/invariant conditions. No projection, clipping, barrier function, or other enforcement mechanism is indicated; without it, residuals can produce trajectories that falsify invariants (e.g., force/torque bounds or contact-mode constraints), directly undermining the reusability and safety guarantees.
- [Evaluation] Evaluation section: the abstract asserts 'robust execution' yet supplies no quantitative metrics, success rates, force/torque error statistics, baseline comparisons (e.g., pure SAC or non-residual RL), or description of how robustness was measured across task variations. This absence leaves the central empirical claim without load-bearing evidence.
minor comments (1)
- [Abstract] The abstract refers to 'composite skills' and 'RRL' without a brief parenthetical definition or pointer to the precise section where the formal conditions are stated; this reduces immediate readability for readers outside the immediate sub-field.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We provide point-by-point responses to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Approach] Abstract and approach description: the claim that 'the overall skill structure and execution flow remain invariant' and that safety is promoted rests on the assumption that SAC residuals cannot violate the pre-/post-/invariant conditions. No projection, clipping, barrier function, or other enforcement mechanism is indicated; without it, residuals can produce trajectories that falsify invariants (e.g., force/torque bounds or contact-mode constraints), directly undermining the reusability and safety guarantees.
Authors: We agree with this assessment. The current manuscript does not specify an explicit mechanism to enforce that residual actions respect the invariant conditions. While the skill structure is designed to maintain invariants through the composite representation, without additional safeguards like action clipping or barrier functions, violations are possible in principle. We will revise the approach section to incorporate a simple projection or clipping mechanism based on the invariant bounds and add a discussion on the resulting safety properties. revision: yes
-
Referee: [Evaluation] Evaluation section: the abstract asserts 'robust execution' yet supplies no quantitative metrics, success rates, force/torque error statistics, baseline comparisons (e.g., pure SAC or non-residual RL), or description of how robustness was measured across task variations. This absence leaves the central empirical claim without load-bearing evidence.
Authors: We acknowledge that the evaluation section in the manuscript lacks detailed quantitative metrics and comparisons. The simulation experiments were conducted with multiple task variations, but specific success rates, error statistics, and baseline results were not reported. We will revise the evaluation section to include these elements, such as success rates over repeated trials, force/torque profiles, and comparisons to a pure SAC baseline, to substantiate the claims of robust execution. revision: yes
Circularity Check
No circularity in composite skill RRL formulation
full rationale
The paper describes an empirical method for peg-in-hole assembly that combines pre-defined composite skills (with explicit pre/post/invariant conditions) and residual RL (SAC) applied only in contact-rich phases. No mathematical derivations, equations, or first-principles results are presented that reduce any claimed prediction or outcome to fitted parameters or self-referential definitions. The central claims rest on simulation results rather than any load-bearing step that collapses by construction to its inputs. Self-citations, if present, are not invoked to justify uniqueness or to smuggle ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Composite skills defined by pre-, post-, and invariant conditions enable modularity and reusability across task variations.
Reference graph
Works this paper leans on
-
[1]
Berlin, Heidelberg: Springer, 2008
Bruno Siciliano and Oussama Khatib.Springer Handbook of Robotics. Berlin, Heidelberg: Springer, 2008. 5 APREPRINT- APRIL9, 2026
work page 2008
-
[2]
Learning force control policies for compliant manipulation
Mrinal Kalakrishnan et al. “Learning force control policies for compliant manipulation”. In:IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). 2011, pp. 4639–4644
work page 2011
-
[3]
Deep Reinforcement Learning for Robotic Assembly of Mixed Deformable and Rigid Objects
Jianlan Luo et al. “Deep Reinforcement Learning for Robotic Assembly of Mixed Deformable and Rigid Objects”. In:IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2018, pp. 2062–2069
work page 2018
-
[4]
Residual Reinforcement Learning for Robot Control
Tobias Johannink et al. “Residual Reinforcement Learning for Robot Control”. In:International Conference on Robotics and Automation (ICRA). 2019, pp. 6023–6029
work page 2019
-
[5]
Federated Residual Reinforcement Learning for Collaborative Robot Skill Learning in Industry
Khalil Abuibaid et al. “Federated Residual Reinforcement Learning for Collaborative Robot Skill Learning in Industry”. In:3rd International Conference on Federated Learning Technologies and Applications (FLTA). 2025, pp. 530–536
work page 2025
-
[6]
Sustainable Transfer Learning for Adaptive Robot Skills
Khalil Abuibaid et al. “Sustainable Transfer Learning for Adaptive Robot Skills”. In:Advances in Service and Industrial Robotics (RAAD). Springer, 2025, pp. 389–397
work page 2025
-
[7]
Learning Force Control for Contact-Rich Manipulation Tasks With Rigid Position-Controlled Robots
Cristian Camilo Beltran-Hernandez et al. “Learning Force Control for Contact-Rich Manipulation Tasks With Rigid Position-Controlled Robots”. In:IEEE Robotics and Automation Letters5.4 (2020), pp. 5709–5716
work page 2020
-
[8]
Skill-based multi-agent control for safe and effective human-robot collaboration
Achim Wagner et al. “Skill-based multi-agent control for safe and effective human-robot collaboration”. In:at - Automatisierungstechnik73.9 (2025), pp. 679–697
work page 2025
-
[9]
Skills Composition Framework for Reconfig- urable Cyber-Physical Production Modules
Aleksandr Sidorenko, Achim Wagner, and Martin Ruskowski. “Skills Composition Framework for Reconfig- urable Cyber-Physical Production Modules”. In:IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETF A). 2024, pp. 1–8
work page 2024
-
[10]
Robot skill acquisition in assembly process using deep reinforcement learning
Fengming Li et al. “Robot skill acquisition in assembly process using deep reinforcement learning”. In:Neuro- computing. Deep Learning for Intelligent Sensing, Decision-Making and Control 345 (2019), pp. 92–102
work page 2019
-
[11]
A flexible manufacturing assembly system with deep reinforcement learning
Junzheng Li et al. “A flexible manufacturing assembly system with deep reinforcement learning”. In:Control Engineering Practice118 (2022), p. 104957
work page 2022
-
[12]
Skill learning for robotic assembly based on visual perspectives and force sensing
Rui Song et al. “Skill learning for robotic assembly based on visual perspectives and force sensing”. In:Robotics and Autonomous Systems135 (2021), p. 103651
work page 2021
-
[13]
Robotic assembly strategy via reinforcement learning based on force and visual information
Kuk-Hyun Ahn, Minwoo Na, and Jae-Bok Song. “Robotic assembly strategy via reinforcement learning based on force and visual information”. In:Robotics and Autonomous Systems164 (2023), p. 104399
work page 2023
-
[14]
A framework for fine robotic assembly
Francisco Suárez-Ruiz and Quang-Cuong Pham. “A framework for fine robotic assembly”. In:IEEE International Conference on Robotics and Automation (ICRA). 2016, pp. 421–426
work page 2016
-
[15]
Manipulation Skill Acquisition for Robotic Assembly using Deep Reinforcement Learning
Fengming Li et al. “Manipulation Skill Acquisition for Robotic Assembly using Deep Reinforcement Learning”. In:IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM). 2019, pp. 13–18
work page 2019
-
[16]
Skill-based Programming of Force-controlled Assembly Tasks using Deep Reinforcement Learning
Arik Lämmle et al. “Skill-based Programming of Force-controlled Assembly Tasks using Deep Reinforcement Learning”. In:Procedia CIRP. 53rd CIRP Conference on Manufacturing Systems 93 (2020), pp. 1061–1066
work page 2020
- [17]
-
[18]
Learning-based Optimization Algorithms Combining Force Control Strategies for Peg-in-Hole Assembly
Peng Zou et al. “Learning-based Optimization Algorithms Combining Force Control Strategies for Peg-in-Hole Assembly”. In:IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2020, pp. 7403– 7410
work page 2020
-
[19]
Robotic Skill Acquisition in Peg-in-hole Assembly Tasks Based on Deep Reinforcement Learning
Peng Tu et al. “Robotic Skill Acquisition in Peg-in-hole Assembly Tasks Based on Deep Reinforcement Learning”. In:Procedia Computer Science250 (2024), pp. 129–135
work page 2024
-
[20]
Stable-Baselines3: Reliable Reinforcement Learning Implementations
Antonin Raffin et al. “Stable-Baselines3: Reliable Reinforcement Learning Implementations”. In:Journal of Machine Learning Research22.268 (2021), pp. 1–8
work page 2021
-
[21]
MuJoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. “MuJoCo: A physics engine for model-based control”. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2012, pp. 5026–5033. 6
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.