A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
Pith reviewed 2026-05-10 15:35 UTC · model grok-4.3
The pith
A hardware accelerator renders full-HD 3D Gaussian Splatting at 129 frames per second on a 0.66 mm² chip.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
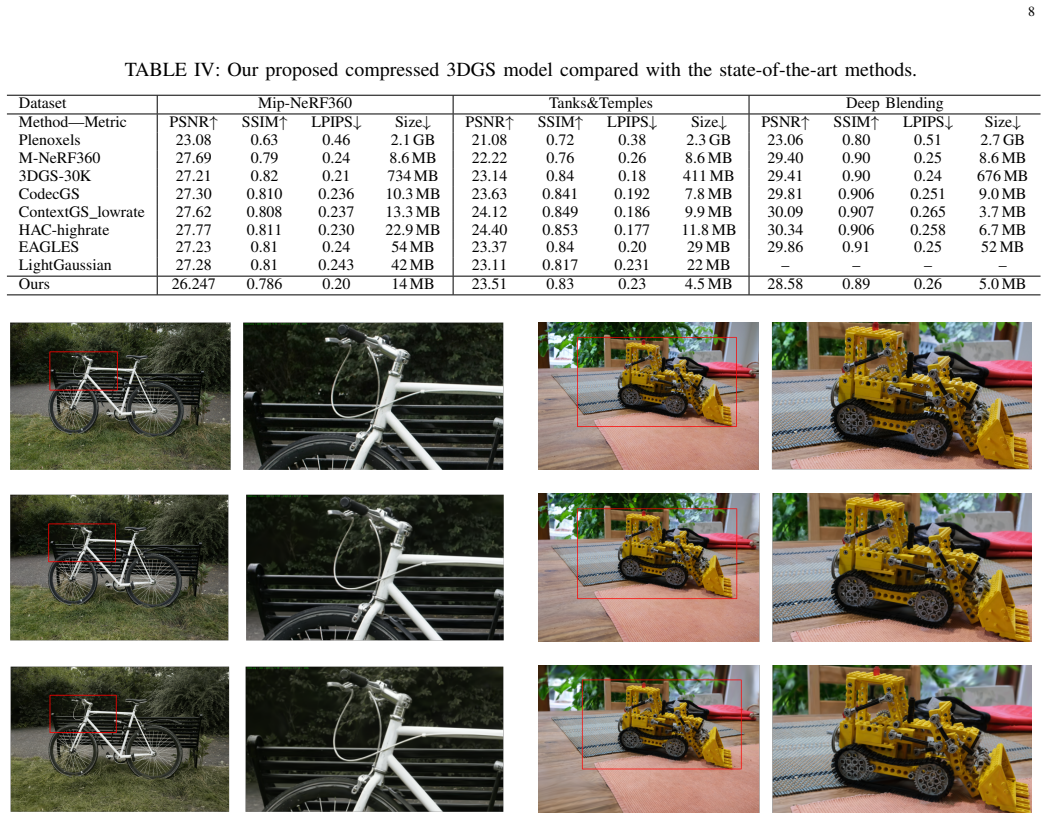
The paper presents an integrated compression and accelerator design for 3D Gaussian Splatting. Iterative pruning, progressive SH degree reduction, and vector quantization shrink model size by 51.6 times with 0.743 dB PSNR loss. The hardware uses a frame-level pipeline for point culling and projection, comparison-free tile sorting, and rasterization that skips zero-Jacobian matrix multiplications, cutting processing elements by 63 percent and computation by 53 percent. In TSMC 28-nm at 800 MHz the design occupies 0.66 mm², consumes 0.219 W, and reaches 267.5 Mpixels/s, delivering 5.98 times smaller area, 5.94 times higher throughput, and 7.5 times higher energy efficiency than prior 3DGS ASIC
What carries the argument
The frame-level pipeline that integrates point-based culling and projection with comparison-free tile-based sorting and rasterization while skipping zero-Jacobian operations.
If this is right
- Delivers 1080p 3DGS rendering at 129 FPS.
- Reduces model size by 51.6 times with only 0.743 dB PSNR loss.
- Achieves 5.98 times smaller silicon area than prior accelerators.
- Provides 7.5 times higher energy efficiency at 1219 Mpixels/J.
- Maintains deterministic latency through comparison-free sorting.
Where Pith is reading between the lines
- Embedding this accelerator in portable AR devices could eliminate the need to stream rendering data from the cloud.
- The small die area leaves room for multiple instances on one chip to support multi-view or higher-resolution output.
- Deterministic sorting latency may simplify scheduling in head-tracked display systems that require fixed frame timing.
- The same skipping of zero-Jacobian multiplications could be applied to other point-based rendering pipelines beyond 3DGS.
Load-bearing premise
The compression steps of pruning, SH reduction, and quantization preserve acceptable visual quality for arbitrary real-world unbounded scenes.
What would settle it
Fabricate the 28-nm design and measure actual frame rate, power, and PSNR on a physical chip while rendering diverse large-scale real-world scenes to check whether 129 FPS at 1080p and the reported efficiency hold.
Figures







read the original abstract
Rendering large-scale, unbounded scenes on AR/VR-class devices is constrained by the computation, bandwidth, and storage cost of 3D Gaussian Splatting (3DGS). We propose a low-power, low-cost 3DGS hardware accelerator that renders full-HD images in real time, together with a hardware-friendly compression pipeline that combines iterative Gaussian pruning and fine-tuning, progressive spherical harmonics (SH) degree reduction, and vector quantization of all SH coefficients and colors. The scheme achieves a $51.6\times$ model-size reduction with a 0.743 dB PSNR loss. The accelerator uses a frame-level pipeline that integrates point-based culling and projection with tile-based sorting and rasterization, skips zero-Jacobian matrix multiplications (reducing processing elements by 63\% and computation by 53\%), and adopts comparison-free tile-based sorting with deterministic latency. Implemented in a TSMC 28-nm process at 800 MHz, the design occupies $0.66~\text{mm}^2$ with 1.1438 M gates and 120 kB SRAM, consumes 0.219 W, and delivers 1219 Mpixels/J at 267.5 Mpixels/s, enabling 1080p at 129 FPS. Overall, it is $5.98\times$ smaller in area, $5.94\times$ higher throughput, and delivers $7.5\times$ higher energy efficiency than prior 3DGS accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hardware accelerator for 3D Gaussian Splatting (3DGS) targeting real-time full-HD rendering on low-power AR/VR devices. It introduces a compression pipeline of iterative Gaussian pruning with fine-tuning, progressive spherical harmonics degree reduction, and vector quantization of SH coefficients and colors, yielding 51.6× model-size reduction at 0.743 dB PSNR loss. The accelerator employs a frame-level pipeline integrating point-based culling/projection, tile-based sorting/rasterization, zero-Jacobian skipping (63% PE reduction, 53% computation reduction), and comparison-free deterministic sorting. Post-synthesis results in TSMC 28-nm at 800 MHz report 0.66 mm² area, 1.1438 M gates, 120 kB SRAM, 0.219 W power, 267.5 Mpixels/s throughput, and 1219 Mpixels/J efficiency, enabling 1080p at 129 FPS, with claimed gains of 5.98× smaller area, 5.94× higher throughput, and 7.5× higher energy efficiency versus prior 3DGS accelerators.
Significance. If the performance numbers hold under silicon validation, the work would be a meaningful contribution to hardware support for 3DGS, directly addressing computation, bandwidth, and storage barriers for large unbounded scenes on edge devices. The reported efficiency gains and compression ratio could enable practical deployment where prior accelerators fall short, with the architectural optimizations (Jacobian skipping, deterministic sorting) providing concrete, measurable benefits.
major comments (1)
- [Implementation/results] Implementation/results section (abstract and synthesis paragraph): The headline metrics (0.66 mm², 0.219 W, 800 MHz, 267.5 Mpixels/s, 1219 Mpixels/J) and the 5.98×/5.94×/7.5× comparison claims rest entirely on post-synthesis RTL estimates. In TSMC 28-nm, interconnect parasitics and process variation routinely increase dynamic power 15-30% and can reduce achievable frequency; without post-layout extraction, power-grid analysis, or measured silicon data, these numbers cannot be taken as final and directly undermine the energy-efficiency and real-time 129 FPS assertions.
minor comments (1)
- [Compression pipeline evaluation] The 0.743 dB PSNR loss is stated as acceptable, but the manuscript should explicitly tabulate or plot quality metrics across a broader set of unbounded real-world scenes (beyond the reported examples) to strengthen the generalization claim for the pruning + progressive SH + VQ pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on the post-synthesis results point-by-point below and are prepared to make revisions to improve the clarity and robustness of our claims.
read point-by-point responses
-
Referee: [Implementation/results] Implementation/results section (abstract and synthesis paragraph): The headline metrics (0.66 mm², 0.219 W, 800 MHz, 267.5 Mpixels/s, 1219 Mpixels/J) and the 5.98×/5.94×/7.5× comparison claims rest entirely on post-synthesis RTL estimates. In TSMC 28-nm, interconnect parasitics and process variation routinely increase dynamic power 15-30% and can reduce achievable frequency; without post-layout extraction, power-grid analysis, or measured silicon data, these numbers cannot be taken as final and directly undermine the energy-efficiency and real-time 129 FPS assertions.
Authors: We acknowledge that the reported metrics are based on post-synthesis RTL estimates and that interconnect parasitics and process variation in TSMC 28-nm can increase dynamic power by 15-30% and affect achievable frequency. Our synthesis flow followed standard practices using commercial EDA tools and the TSMC 28-nm cell library, which is typical for reporting accelerator designs in the literature. The comparison factors (5.98× area, 5.94× throughput, 7.5× energy efficiency) are computed against prior 3DGS accelerators that likewise rely on post-synthesis results. To address this concern, we will revise the manuscript by expanding the implementation section with a detailed description of the synthesis setup, explicitly noting the limitations of post-synthesis estimates, and qualifying the headline claims (including the 129 FPS figure) with appropriate caveats on potential deviations. The relative benefits of our architectural optimizations, such as zero-Jacobian skipping and comparison-free sorting, remain independent of these absolute numbers. We cannot provide post-layout extraction or silicon measurements without additional fabrication resources. revision: partial
Circularity Check
No circularity: direct hardware design report with independent synthesis metrics
full rationale
The paper is an engineering implementation report describing an RTL design for a 3DGS accelerator, a compression pipeline (pruning + SH reduction + VQ), and post-synthesis results in TSMC 28 nm. No equations, predictions, or uniqueness claims are present that reduce to self-definitions, fitted inputs renamed as outputs, or self-citation chains. All performance numbers (area, power, throughput) are stated as direct outputs of the synthesis flow at 800 MHz; comparisons to prior accelerators cite external works. The 0.743 dB PSNR loss is an empirical measurement of the chosen compression scheme, not a derived quantity that loops back to its own inputs. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in hardware synthesis, power estimation, and timing analysis for TSMC 28 nm CMOS process hold for the reported area, power, and frequency figures.
Reference graph
Works this paper leans on
-
[1]
3D Gaussian Splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian Splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, pp. 139– 1, 2023
work page 2023
-
[2]
Compact 3d scene representation via self-organizing gaussian grids,
W. Morgenstern, F. Barthel, A. Hilsmann, and P. Eisert, “Compact 3d scene representation via self-organizing gaussian grids,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 18–34
work page 2024
-
[3]
Compact 3D Gaussian representation for radiance field,
J. C. Lee, D. Rho, X. Sun, J. H. Ko, and E. Park, “Compact 3D Gaussian representation for radiance field,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 719–21 728
work page 2024
-
[4]
Lightgaussian: Unbounded 3D Gaussian compression with 15x reduction and 200+ fps,
Z. Fan, K. Wang, K. Wen, Z. Zhu, D. Xu, and Z. Wang, “Lightgaussian: Unbounded 3D Gaussian compression with 15x reduction and 200+ fps,”Advances in neural information processing systems, vol. 37, pp. 140 138– 140 158, 2024
work page 2024
-
[5]
Reducing the memory footprint of 3d gaussian splatting,
P. Papantonakis, G. Kopanas, B. Kerbl, A. Lanvin, and G. Drettakis, “Reducing the memory footprint of 3d gaussian splatting,”Proceedings of the ACM on Computer Graphics and Interactive Techniques, vol. 7, no. 1, pp. 1–17, 2024
work page 2024
-
[6]
Mini-splatting: Representing scenes with a constrained number of gaussians,
G. Fang and B. Wang, “Mini-splatting: Representing scenes with a constrained number of gaussians,” in European Conference on Computer Vision. Springer, 2024, pp. 165–181
work page 2024
-
[7]
Taming 3dgs: High-quality radiance fields with limited resources,
S. S. Mallick, R. Goel, B. Kerbl, M. Steinberger, F. V . Carrasco, and F. De La Torre, “Taming 3dgs: High-quality radiance fields with limited resources,” in SIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1– 11
work page 2024
-
[8]
Progs: Progressive rendering of gaussian splats,
B. Zoomers, M. Wijnants, I. Molenaers, J. Vanherck, J. Put, and N. Michiels, “Progs: Progressive rendering of gaussian splats,” in2025 IEEE/CVF Winter Conference 11 on Applications of Computer Vision (WACV). IEEE, 2025, pp. 3118–3127
work page 2025
-
[9]
Stopthepop: Sorted gaussian splatting for view-consistent real-time rendering,
L. Radl, M. Steiner, M. Parger, A. Weinrauch, B. Kerbl, and M. Steinberger, “Stopthepop: Sorted gaussian splatting for view-consistent real-time rendering,”ACM Transactions on Graphics (TOG), vol. 43, no. 4, pp. 1– 17, 2024
work page 2024
-
[10]
Gscore: Efficient radiance field rendering via architectural support for 3D Gaussian Splatting,
J. Lee, S. Lee, J. Lee, J. Park, and J. Sim, “Gscore: Efficient radiance field rendering via architectural support for 3D Gaussian Splatting,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 497–511
work page 2024
-
[11]
H. Lee, G. Park, W. Park, W. Jo, J. Park, and H.-J. Yoo, “A 66.6 fps high quality gaussian splats rendering fpga processor with reconfigurable computation architecture,” in2024 IEEE Asian Solid-State Circuits Conference (A- SSCC), 2024, pp. 1–3
work page 2024
-
[12]
Y . Sun, P. Yan, Y . Jing, L. Ye, and T. Jia, “GSNorm: An efficient 3D gaussian rendering accelerator with splat normalization and LUT-assist rasterization,” in Proceedings of the 30th Asia and South Pacific Design Automation Conference, 2025, pp. 1379–1385
work page 2025
-
[13]
A system for acquiring, processing, and rendering panoramic light field stills for virtual reality,
R. S. Overbeck, D. Erickson, D. Evangelakos, M. Pharr, and P. Debevec, “A system for acquiring, processing, and rendering panoramic light field stills for virtual reality,” ACM Transactions on Graphics (TOG), vol. 37, no. 6, pp. 1–15, 2018
work page 2018
-
[14]
3dgs. zip: A survey on 3d gaussian splatting compression methods,
M. T. Bagdasarian, P. Knoll, Y . Li, F. Barthel, A. Hilsmann, P. Eisert, and W. Morgenstern, “3dgs. zip: A survey on 3d gaussian splatting compression methods,” inComputer Graphics Forum, vol. 44, no. 2. Wiley Online Library, 2025, p. e70078
work page 2025
-
[15]
Eagles: Efficient accelerated 3D gaussians with lightweight encodings,
S. Girish, K. Gupta, and A. Shrivastava, “Eagles: Efficient accelerated 3D gaussians with lightweight encodings,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 54–71
work page 2024
-
[16]
Contextgs: Compact 3d gaussian splatting with anchor level context model,
Y . Wang, Z. Li, L. Guo, W. Yang, A. Kot, and B. Wen, “Contextgs: Compact 3d gaussian splatting with anchor level context model,”Advances in neural information processing systems, vol. 37, pp. 51 532–51 551, 2024
work page 2024
-
[17]
Hac: Hash-grid assisted context for 3d gaussian splatting compression,
Y . Chen, Q. Wu, W. Lin, M. Harandi, and J. Cai, “Hac: Hash-grid assisted context for 3d gaussian splatting compression,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 422–438
work page 2024
-
[18]
Compression of 3d gaussian splatting with optimized feature planes and standard video codecs,
S. Lee, F. Shu, Y . Sanchez, T. Schierl, and C. Hellge, “Compression of 3d gaussian splatting with optimized feature planes and standard video codecs,” inProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, 2025, pp. 25 496–25 505
work page 2025
-
[19]
3d gaussian splatting as markov chain monte carlo,
S. Kheradmand, D. Rebain, G. Sharma, W. Sun, Y .-C. Tseng, H. Isack, A. Kar, A. Tagliasacchi, and K. M. Yi, “3d gaussian splatting as markov chain monte carlo,” Advances in Neural Information Processing Systems, vol. 37, pp. 80 965–80 986, 2024
work page 2024
-
[20]
A hardware architecture for surface splatting,
T. Weyrich, S. Heinzle, T. Aila, D. B. Fasnacht, S. Oetiker, M. Botsch, C. Flaig, S. Mall, K. Rohrer, N. Felberet al., “A hardware architecture for surface splatting,”ACM Transactions on Graphics (TOG), vol. 26, no. 3, pp. 90–es, 2007
work page 2007
-
[21]
K-degree parallel comparison- free hardware sorter for complete sorting,
S. S. Ray and S. Ghosh, “K-degree parallel comparison- free hardware sorter for complete sorting,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 5, pp. 1438–1449, 2022
work page 2022
-
[22]
A comparison- free hardware sorting engine,
S. Ghosh, S. Dasgupta, and S. S. Ray, “A comparison- free hardware sorting engine,” in2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, 2019, pp. 586–591
work page 2019
-
[23]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields,
J. T. Barron, B. Mildenhall, D. Verbin, P. P. Srinivasan, and P. Hedman, “Mip-nerf 360: Unbounded anti-aliased neural radiance fields,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5470–5479
work page 2022
-
[24]
Tanks and temples: Benchmarking large-scale scene reconstruction,
A. Knapitsch, J. Park, Q.-Y . Zhou, and V . Koltun, “Tanks and temples: Benchmarking large-scale scene reconstruction,”ACM Transactions on Graphics (ToG), vol. 36, no. 4, pp. 1–13, 2017
work page 2017
-
[25]
Deep blending for free-viewpoint image-based rendering,
P. Hedman, J. Philip, T. Price, J.-M. Frahm, G. Drettakis, and G. Brostow, “Deep blending for free-viewpoint image-based rendering,”ACM Transactions on Graphics (ToG), vol. 37, no. 6, pp. 1–15, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.