Leveraging machine learning to estimate individualized treatment effects in cluster-randomized trials
Pith reviewed 2026-05-10 13:25 UTC · model grok-4.3
The pith
A unified mixed-effects machine learning framework estimates conditional average treatment effects in cluster-randomized trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a unified framework based on mixed-effects machine learning that integrates and extends methods including Bayesian additive regression trees with random effects, multilevel Bayesian causal forests, mixed-effects random forests, several mixed-effects gradient boosting procedures, and generalized additive mixed models. By incorporating cluster-specific random intercepts, the approach estimates conditional average treatment effects for continuous outcomes in two-arm parallel cluster-randomized trials while incorporating individual- and cluster-level covariates and marginalizing over unobserved cluster heterogeneity.
What carries the argument
Mixed-effects machine learning methods that add cluster-specific random intercepts to account for within-cluster dependence when estimating conditional average treatment effects.
If this is right
- Investigators can quantify treatment-effect heterogeneity in cluster-randomized trials using a single coherent workflow.
- Analyses can include both individual-level and cluster-level covariates in the causal targets.
- Practical guidance and code support application to real trials such as the Ghana hypertension study.
- Performance can be compared across diverse simulation scenarios to guide method choice.
Where Pith is reading between the lines
- This could support more targeted delivery of group-level interventions by highlighting which individuals or cluster types respond most.
- The methods might be combined with robustness checks for unmeasured factors that affect both treatment response and cluster assignment.
- Extensions to non-continuous outcomes would allow similar individualized-effect estimation in a wider range of cluster trials.
Load-bearing premise
The mixed-effects adaptations of machine learning methods can correctly identify and estimate the defined causal estimands without substantial bias from model misspecification or inadequate handling of cluster heterogeneity.
What would settle it
A simulation or real-data case in which the estimated conditional average treatment effects show large bias or inconsistency when cluster sizes vary widely or unobserved cluster differences are strong.
Figures
















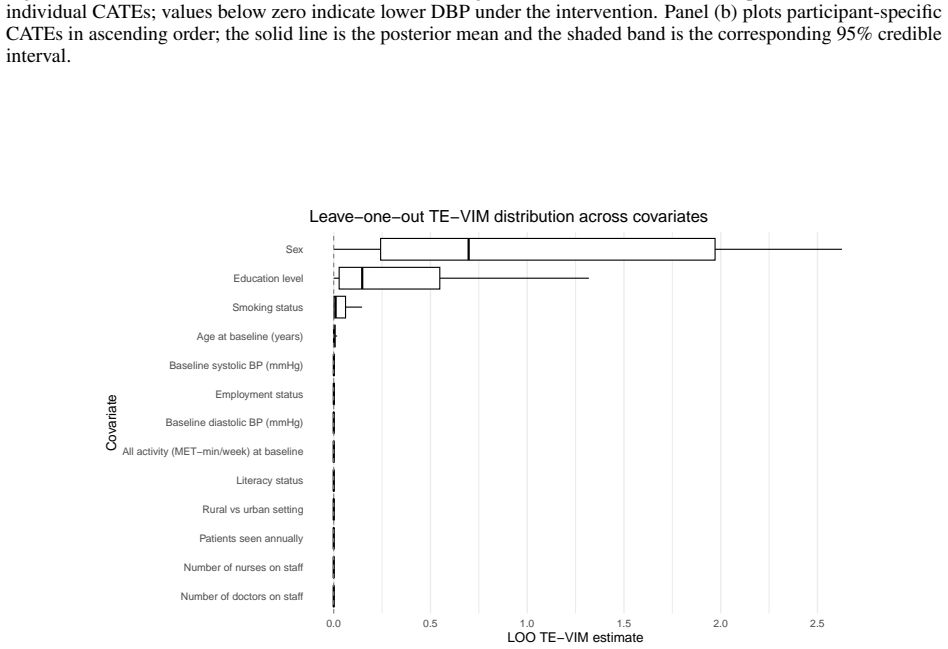
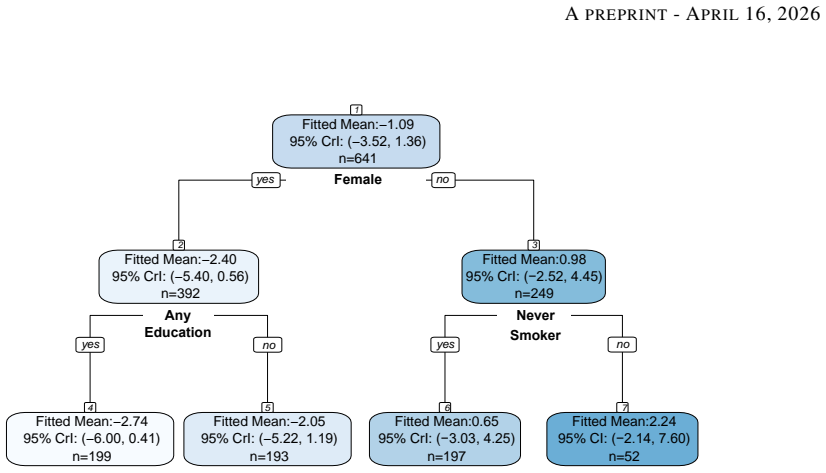







read the original abstract
Cluster-randomized trials (CRTs) are widely used to evaluate interventions delivered at the clinic, practice, or community level. Although standard analyses typically target average treatment effects, such summaries mask potentially meaningful variation in treatment response across individuals and clusters. This work addresses the estimation of conditional average treatment effects (CATEs) for continuous outcomes in two-arm parallel CRTs by defining causal estimands that incorporate both individual- and cluster-level baseline covariates while marginalizing over unobserved cluster heterogeneity. To estimate these quantities, we develop a unified framework based on mixed-effects machine learning, integrating and extending a range of existing approaches, including Bayesian additive regression trees with random effects, multilevel Bayesian causal forests, mixed-effects random forests, several mixed-effects gradient boosting procedures, and generalized additive mixed models, while incorporating cluster-specific random intercepts to account for within-cluster dependence. We evaluate these methods across diverse simulation scenarios and demonstrate their use in the Task Shifting and Blood Pressure Control in Ghana CRT, which investigates strategies for improving hypertension management. Drawing on these investigations, we provide practical guidance for applying mixed-effects machine learning to quantify treatment-effect heterogeneity in CRTs, together with reproducible code that enables investigators to implement all methods within a coherent workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a unified framework for estimating conditional average treatment effects (CATEs) in two-arm parallel cluster-randomized trials (CRTs) for continuous outcomes. It defines causal estimands that condition on individual- and cluster-level baseline covariates while marginalizing over unobserved cluster heterogeneity, then estimates these via mixed-effects adaptations of machine learning methods (BART with random effects, multilevel Bayesian causal forests, mixed-effects random forests, mixed-effects gradient boosting, and generalized additive mixed models) that incorporate cluster-specific random intercepts. The methods are evaluated in diverse simulation scenarios and applied to the Task Shifting and Blood Pressure Control in Ghana CRT, with practical guidance and reproducible code provided.
Significance. If the mixed-effects ML estimators are shown to be consistent for the defined marginal CATEs under cluster-level randomization, the work would provide a practical, extensible toolkit for detecting treatment-effect heterogeneity in CRTs, which are common in public health and social science. Unifying multiple ML approaches with random intercepts and supplying open code are clear strengths that would facilitate adoption beyond standard average-effect analyses.
major comments (3)
- [Identification / causal estimands] Identification section (likely §2 or §3): the manuscript defines the target CATE by marginalizing over the random-intercept distribution but provides no formal identification argument or proof that the mixed-effects adaptations of BART, forests, and boosting correctly separate the fixed treatment-interaction surface from the cluster-specific random intercepts when treatment is assigned at the cluster level. Without this, it is unclear whether the estimators target the stated estimand or incur bias from the cluster randomization mechanism.
- [Simulation study] Simulation study (likely §4): the reported simulation scenarios do not include a diagnostic or sensitivity check that isolates bias arising from marginalization over random effects under cluster-level assignment; this is load-bearing because the central claim is that the framework estimates the defined causal quantities without substantial bias from model misspecification or inadequate handling of cluster heterogeneity.
- [Application] Real-data application (likely §5): the Ghana CRT analysis does not report diagnostics for the random-intercept specification (e.g., posterior predictive checks or comparison of marginal vs. conditional predictions) or benchmark the CATE estimates against standard CRT mixed-model approaches to demonstrate that the ML extensions add value beyond conventional methods.
minor comments (2)
- [Abstract] The abstract lists the integrated methods but does not indicate how the unified framework coordinates hyperparameter tuning, random-effect estimation, or marginalization across the different algorithms.
- [Methods] Notation for the random intercepts and their incorporation (e.g., inside tree splits versus boosting updates) should be made uniform and explicit in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which have helped us identify areas to strengthen the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Identification / causal estimands] Identification section (likely §2 or §3): the manuscript defines the target CATE by marginalizing over the random-intercept distribution but provides no formal identification argument or proof that the mixed-effects adaptations of BART, forests, and boosting correctly separate the fixed treatment-interaction surface from the cluster-specific random intercepts when treatment is assigned at the cluster level. Without this, it is unclear whether the estimators target the stated estimand or incur bias from the cluster randomization mechanism.
Authors: We thank the referee for this important observation. Section 2 defines the target marginal CATE by integrating over the random-intercept distribution under cluster-level randomization, relying on standard causal assumptions (no unmeasured confounding at individual and cluster levels, positivity, and consistency). The mixed-effects ML procedures are constructed to estimate the fixed-effects component of the treatment-interaction surface while treating cluster intercepts as nuisance parameters. However, we acknowledge that an explicit identification proof would clarify separation from the randomization mechanism. In the revision we will add a dedicated subsection (new §2.3) that formally states the identification result, including the conditions under which the mixed-effects estimators recover the marginal CATE without bias induced by cluster assignment. revision: yes
-
Referee: [Simulation study] Simulation study (likely §4): the reported simulation scenarios do not include a diagnostic or sensitivity check that isolates bias arising from marginalization over random effects under cluster-level assignment; this is load-bearing because the central claim is that the framework estimates the defined causal quantities without substantial bias from model misspecification or inadequate handling of cluster heterogeneity.
Authors: We agree that a targeted diagnostic would strengthen the simulation evidence. The existing scenarios vary cluster size, ICC, and heterogeneity, which provide indirect support, but they do not isolate marginalization bias under cluster randomization. We will add a new sensitivity experiment in §4 that (i) generates data from known random-effect distributions, (ii) applies the estimators under cluster-level assignment, and (iii) reports bias and coverage specifically attributable to marginalization. Results and discussion of this check will be included in the revised simulation section. revision: yes
-
Referee: [Application] Real-data application (likely §5): the Ghana CRT analysis does not report diagnostics for the random-intercept specification (e.g., posterior predictive checks or comparison of marginal vs. conditional predictions) or benchmark the CATE estimates against standard CRT mixed-model approaches to demonstrate that the ML extensions add value beyond conventional methods.
Authors: We appreciate this practical suggestion. In the revised §5 we will include (i) posterior predictive checks for the random-intercept components of the fitted mixed-effects ML models, (ii) a comparison of marginal versus conditional predictions, and (iii) side-by-side benchmarking of CATE surfaces against a standard linear mixed model and a generalized additive mixed model. These additions will be presented with new figures and a brief discussion of where the ML extensions provide additional insight into treatment-effect heterogeneity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines causal estimands for CATEs that incorporate individual- and cluster-level covariates while marginalizing over unobserved cluster heterogeneity, then estimates them via a unified mixed-effects ML framework that adapts existing methods (BART with random effects, multilevel causal forests, mixed-effects random forests, gradient boosting, and GAMMs) by adding cluster-specific random intercepts. These steps rest on standard causal identification plus data-driven fitting of the adapted learners; no step reduces a claimed prediction or first-principles result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing uniqueness theorem or ansatz is imported solely via self-citation. The framework therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- ML hyperparameters
axioms (1)
- domain assumption Standard causal assumptions allowing identification of CATEs from observed data in CRTs (no unmeasured confounding within clusters, consistency, positivity)
Reference graph
Works this paper leans on
-
[1]
Treatment is assigned at the cluster level with balanced1:1allocation. Potential outcomes follow Yij(0) =f 0(Xij,V i) +b i +ε ij, Y ij(1) =f 0(Xij,V i) +τ(X ij,V i) +b i +ε ij, where bi i.i.d. ∼ N(0, σ 2 b) denotes a cluster random effect and εij i.i.d. ∼ N(0, σ 2) an individual error. For a specified total variance σ2 b +σ 2 and intracluster correlation ...
work page 2026
-
[2]
Y"). • treatment (character) Name of the binary treatment column in df (0/1, e.g
stan4bart Reference paper: https://www.mdpi.com/1099-4300/24/12/1782 R package: stan4bart F unction inputs • df A data.frame containing all variables used by the function. – Required columns: ∗ Outcome (continuous) ∗ Treatment indicator (0/1) ∗ All covariates for the BART term ∗ Cluster/group ID • outcome (character) Name of the numeric outcome column in ...
-
[3]
mixedBAR T Reference paper: https://pubmed.ncbi.nlm.nih.gov/33751659/ R package: mxbart, bart3, github: https://github.com/rsparapa/bnptools F unction inputs • df A data.frame containing in CRT data. Must include at least: – The outcome column (named by outcome) – The treatment indicator (named by treatment, values 0/1) – All covariate columns (named in c...
-
[4]
Treatment must be coded as 0/1
riBAR T Reference paper: https://intlpress.com/site/pub/files/_fulltext/journals/sii/2018/0011/0004/SII-2018- 0011-0004-a001.pdf R package: dbarts F unction inputs • df A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome) 6 – The treatment indicator (named by treatment, values 0/1) – All covariate columns (named...
work page 2018
-
[5]
MBCF Reference paper: https://www.nature.com/articles/s41586-022-04907-7 https://journals.sagepub.com/doi/full/10.1177/09567976211028984 https://link.springer.com/chapter/10.1007/978-3-031-55548-0_25 Source: R package multibart OSF: https://osf.io/3zmqc/ F unction inputs • df data.frame containing all variables used by the function. – Required columns: ∗ ...
-
[6]
URL https://doi.org/10.1080/ 01621459.2017.1307116
CF Reference paper: https://projecteuclid.org/journals/annals-of-statistics/volume-47/issue-2/Generalized-random-forests/10. 1214/18-AOS1709.full https://www.tandfonline.com/doi/full/10.1080/01621459.2017.1319839 https://academic.oup.com/biomet/article/108/2/299/5911092 R package: grf F unction inputs • df A data.frame containing CRT data. Must include at...
-
[7]
MERF Reference paper: https://journals.sagepub.com/doi/full/10.1177/0962280220946080 R package: LogituRF F unction inputs • df A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome, numeric) – The treatment indicator (named by treatment, values 0/1 or coercible to 0/1) – All covariate columns (named in covariates)...
-
[8]
GPBoost Reference paper: https://www.jmlr.org/papers/v23/20-322.html 20 https://ieeexplore.ieee.org/abstract/document/9759834 R package: gpboost F unction inputs • df A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome, numeric) – The treatment indicator (named by treatment, values 0/1) – All covariate columns (...
-
[9]
MEGB", quietly = TRUE)) { stop(
MEGB Reference paper: https://www.nature.com/articles/s41598-025-16526-z R package: MEGB F unction inputs • df A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome, numeric) – The treatment indicator (named by treatment, values 0/1 or coercible to 0/1) – All covariate columns (named in covariates) – The cluster I...
-
[10]
mermboost Reference paper: https://link.springer.com/article/10.1007/s11222-025-10612-y package: mermboost F unction inputs • data A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome, numeric) – The treatment indicator (named by treatment, values 0/1 or coercible to 0/1) – All covariate columns (named in covaria...
-
[11]
GAMM Reference paper: https://academic.oup.com/jrsssb/article/73/1/3/7034726 R package: mgcv F unction inputs 34 • df A data.frame containing CRT data. Must include at least: – The outcome column (named by outcome) – The treatment indicator (named by treatment, values 0/1) – All covariate columns (named in covariates) – The cluster ID column (named by clu...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.