Momentum-constrained Hybrid Heuristic Trajectory Optimization Framework with Residual-enhanced DRL for Visually Impaired Scenarios
Pith reviewed 2026-05-10 10:36 UTC · model grok-4.3
The pith
A hybrid heuristic framework with momentum constraints and residual DRL halves convergence iterations for safer, smoother navigation paths in visually impaired scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
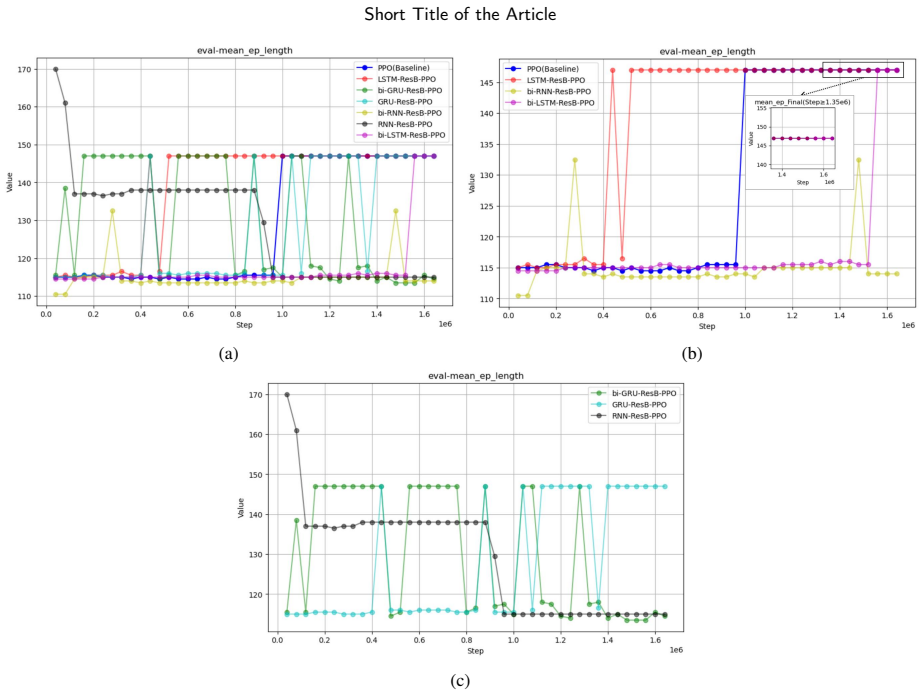
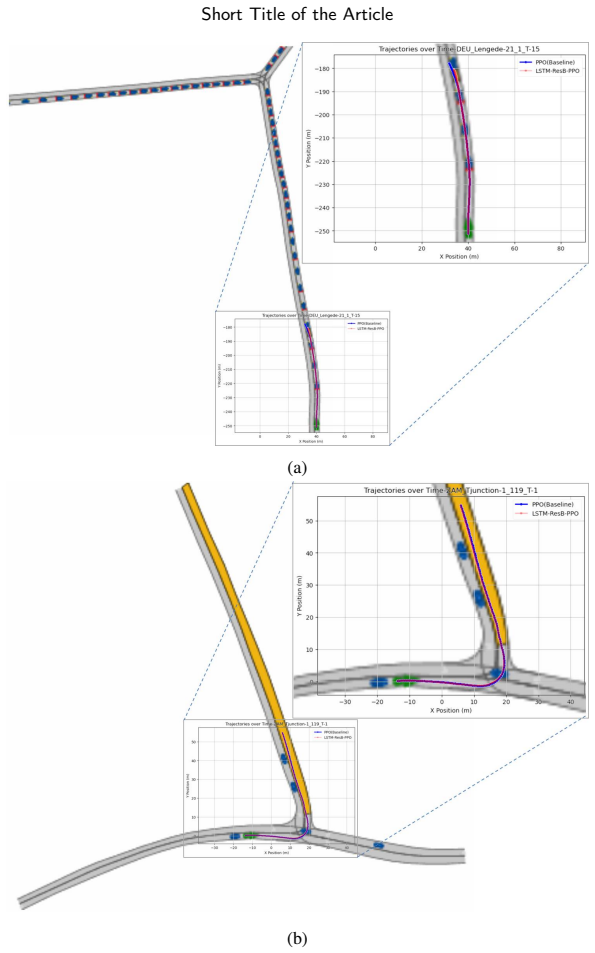
The MHHTOF framework combines a Heuristic Trajectory Sampling Cluster with Momentum-Constrained Trajectory Optimization to suppress abrupt changes, refines outputs via residual-enhanced DRL for better policy generalization, and uses dual-stage cost modeling with Frenet-space consistency costs plus Cartesian-space adaptive weights driven by rewards. Experiments demonstrate convergence in nearly half the iterations of baselines, lower and more stable costs, and velocity and acceleration profiles that remain stable with reduced risk in complex dynamic scenarios.
What carries the argument
The Momentum-Constrained Hybrid Heuristic Trajectory Optimization Framework (MHHTOF) that integrates heuristic trajectory sampling, momentum-constrained optimization, residual DRL refinement, and dual-stage cost modeling in Frenet and Cartesian spaces.
If this is right
- The method reaches stable solutions in roughly half the iterations required by existing planners.
- Optimization costs remain lower and exhibit less variation across runs.
- Velocity and acceleration traces stay smooth even inside crowded, changing environments.
- The dual cost stages allow explicit incorporation of individual comfort and safety priorities without losing interpretability.
Where Pith is reading between the lines
- The residual DRL component could support transfer to new user groups or sensor suites with minimal retraining.
- Frenet-space consistency combined with Cartesian reward weighting might generalize to other mobile-robot domains that must respect both local smoothness and global user intent.
- Stable convergence behavior suggests the framework could serve as a reliable inner loop inside larger lifelong-learning pipelines for assistive devices.
Load-bearing premise
That the combination of heuristic sampling, momentum limits, residual DRL, and dual cost modeling will continue to work when real-world obstacles, user preferences, and environments differ from the tested cases.
What would settle it
A field deployment with unpredictable moving obstacles and diverse user preference inputs in which the framework requires more iterations or produces higher peak velocities and accelerations than baseline planners.
Figures












read the original abstract
Safe and efficient assistive planning for visually impaired scenarios remains challenging, since existing methods struggle with multi-objective optimization, generalization, and interpretability. In response, this paper proposes a Momentum-Constrained Hybrid Heuristic Trajectory Optimization Framework (MHHTOF). To balance multiple objectives of comfort and safety, the framework designs a Heuristic Trajectory Sampling Cluster (HTSC) with a Momentum-Constrained Trajectory Optimization (MTO), which suppresses abrupt velocity and acceleration changes. In addition, a novel residual-enhanced deep reinforcement learning (DRL) module refines candidate trajectories, advancing temporal modeling and policy generalization. Finally, a dual-stage cost modeling mechanism (DCMM) is introduced to regulate optimization, where costs in the Frenet space ensure consistency, and reward-driven adaptive weights in the Cartesian space integrate user preferences for interpretability and user-centric decision-making. Experimental results show that the proposed framework converges in nearly half the iterations of baselines and achieves lower and more stable costs. In complex dynamic scenarios, MHHTOF further demonstrates stable velocity and acceleration curves with reduced risk, confirming its advantages in robustness, safety, and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Momentum-Constrained Hybrid Heuristic Trajectory Optimization Framework (MHHTOF) for assistive trajectory planning in visually impaired scenarios. It integrates a Heuristic Trajectory Sampling Cluster (HTSC) with Momentum-Constrained Trajectory Optimization (MTO) to limit abrupt velocity/acceleration changes, a residual-enhanced DRL module for candidate refinement and temporal generalization, and a dual-stage cost modeling mechanism (DCMM) that enforces consistency in Frenet space while using reward-driven adaptive weights in Cartesian space to incorporate user preferences. The central experimental claim is that MHHTOF converges in nearly half the iterations of baselines, yields lower and more stable costs, and produces stable velocity/acceleration profiles with reduced risk in complex dynamic scenarios.
Significance. If the performance claims are substantiated with proper controls, the hybrid heuristic-DRL approach could advance safe, interpretable navigation for visually impaired users by addressing multi-objective trade-offs between comfort, safety, and personalization. The momentum constraints and dual-space cost modeling offer a concrete mechanism for smoothness and user-centric adaptation that existing pure optimization or pure learning methods often lack.
major comments (2)
- [Experimental Results] Experimental Results section: The assertion that MHHTOF 'converges in nearly half the iterations of baselines' and achieves 'lower and more stable costs' with 'reduced risk' supplies no information on baseline algorithms, scenario generation (obstacle density, predictability, user-preference sampling), evaluation metrics, number of independent runs, or statistical tests. Without these, the reported advantages cannot be isolated from implementation artifacts or narrow test conditions and therefore do not support the central claim of superiority.
- [Method] Method section (DCMM and residual DRL): The reward-driven adaptive weights are described only at the level of 'integrate user preferences'; no explicit formulation, update rule, or ablation isolating their contribution is provided. This leaves open the possibility that the reported stability and risk reduction are artifacts of the particular training distribution rather than a general property of the framework.
minor comments (1)
- Several acronyms (MHHTOF, HTSC, MTO, DCMM) are introduced in the abstract and early text without immediate expansion on first use in the main body.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive criticism of our work on the Momentum-Constrained Hybrid Heuristic Trajectory Optimization Framework (MHHTOF). The comments highlight important aspects that require clarification and expansion to strengthen the paper's contributions. We address each major comment in detail below, outlining the specific revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: The assertion that MHHTOF 'converges in nearly half the iterations of baselines' and achieves 'lower and more stable costs' with 'reduced risk' supplies no information on baseline algorithms, scenario generation (obstacle density, predictability, user-preference sampling), evaluation metrics, number of independent runs, or statistical tests. Without these, the reported advantages cannot be isolated from implementation artifacts or narrow test conditions and therefore do not support the central claim of superiority.
Authors: We agree that additional details are necessary to fully support the experimental claims. In the revised version of the manuscript, we will enhance the Experimental Results section by providing comprehensive information on the baseline algorithms, including their names, key parameters, and implementation specifics. We will also describe the scenario generation process in detail, covering aspects such as obstacle density, predictability, and user-preference sampling. Furthermore, we will specify the evaluation metrics, report the number of independent runs conducted, and present results from statistical tests to validate the observed improvements. These additions will help isolate the contributions of MHHTOF and address concerns about potential artifacts. revision: yes
-
Referee: [Method] Method section (DCMM and residual DRL): The reward-driven adaptive weights are described only at the level of 'integrate user preferences'; no explicit formulation, update rule, or ablation isolating their contribution is provided. This leaves open the possibility that the reported stability and risk reduction are artifacts of the particular training distribution rather than a general property of the framework.
Authors: We recognize the need for more explicit details on the reward-driven adaptive weights within the DCMM. In the revision, we will include the mathematical formulation of these weights, the specific update rule employed, and the reward function used for adaptation. Additionally, we will conduct and report an ablation study that compares the full framework against variants without the adaptive weights or with fixed weights. This study will be performed across different training distributions to demonstrate that the benefits in stability and risk reduction are not limited to the original training conditions but represent a general property of the approach. revision: yes
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The paper presents an engineering framework (MHHTOF) combining heuristic sampling (HTSC), momentum-constrained optimization (MTO), residual DRL refinement, and dual-stage cost modeling (DCMM with Frenet/Cartesian spaces and reward-driven weights). Performance claims rest on experimental comparisons in simulation rather than a closed mathematical derivation. No equations or steps are quoted that reduce a 'prediction' or result to fitted inputs by construction, nor is there load-bearing self-citation for uniqueness theorems. The reward-driven weights are an explicit design element for user preferences, not shown to be tautological. The derivation chain from components to reported convergence/safety advantages is self-contained and externally falsifiable via the described experiments.
Axiom & Free-Parameter Ledger
invented entities (5)
-
MHHTOF
no independent evidence
-
HTSC
no independent evidence
-
MTO
no independent evidence
-
residual-enhanced DRL
no independent evidence
-
DCMM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. P. Kalidas, C. J. Joshua, A. Q. Md, S. Basheer, S. Mohan, S. Sakri, Deep reinforcement learning for vision-based navigation of uavs in avoiding stationary and mobile obstacles, Drones 7 (4) (2023) 245
work page 2023
-
[2]
A. B. Najjar, A. R. Al-Issa, M. Hosny, Dynamic indoor path planning for the visually impaired, Journal of King Saud University-Computer and Information Sciences 34 (9) (2022) 7014–7024
work page 2022
-
[3]
S.M.Shin,J.Lim,Y.Choi,Guidedogar:Atactileandauditoryassistingdevicedesignwiththemotifofaguidedogforthevisuallyimpaired, International Journal of Human–Computer Interaction (2024) 1–14
work page 2024
-
[4]
H. R. Surougi, J. A. McCann, Real-time optimisation-based path planning for visually impaired people in dynamic environments, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1839–1848
work page 2023
-
[5]
I.Patel,M.Kulkarni,N.Mehendale,Reviewofsensor-drivenassistivedevicetechnologiesforenhancingnavigationforthevisuallyimpaired, Multimedia Tools and Applications 83 (17) (2024) 52171–52195
work page 2024
-
[6]
S. Teng, X. Hu, P. Deng, B. Li, Y. Li, Y. Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhu, et al., Motion planning for autonomous driving: The state of the art and future perspectives, IEEE Transactions on Intelligent Vehicles 8 (6) (2023) 3692–3711
work page 2023
-
[7]
C.Zhang,W.Xu,Intelligentvehiclepathbasedondiscretizedsamplingpointsandimprovedcostfunction:Aquadraticprogrammingapproach, IEEE Access 12 (2024) 24500–24515
work page 2024
-
[8]
J.Wang,L.Chu,Y.Zhang,Y.Mao,C.Guo,Intelligentvehicledecision-makingandtrajectoryplanningmethodbasedondeepreinforcement learning in the frenet space, Sensors 23 (24) (2023) 9819
work page 2023
-
[9]
IEEE Journal of Biomedical and Health Informatics , author =
S. Siboo, A. Bhattacharyya, R. Naveen Raj, S. H. Ashwin, An empirical study of ddpg and ppo-based reinforcement learning algorithms for autonomous driving, IEEE Access 11 (2023) 125094–125108.doi:10.1109/ACCESS.2023.3330665
-
[10]
Q. Xiao, L. Jiang, M. Wang, X. Zhang, An improved distributed sampling ppo algorithm based on beta policy for continuous global path planning scheme, Sensors 23 (13) (2023) 6101
work page 2023
-
[11]
R.Zhang,J.Hou,G.Chen,Z.Li,J.Chen,A.Knoll,Residualpolicylearningfacilitatesefficientmodel-freeautonomousracing,IEEERobotics and Automation Letters 7 (4) (2022) 11625–11632
work page 2022
-
[12]
S.Wen,Y.Shu,A.Rad,Z.Wen,Z.Guo,S.Gong,Adeepresidualreinforcementlearningalgorithmbasedonsoftactor-criticforautonomous navigation, Expert Systems with Applications 259 (2025) 125238
work page 2025
-
[13]
R.Zhang,X.Qin,M.Pan,S.Li,H.Shen,Adaptivetemporalreinforcementlearningformappingcomplexmaritimeenvironmentalstatespaces in autonomous ship navigation, Journal of Marine Science and Engineering 13 (3) (2025) 514
work page 2025
-
[14]
Z.Zhang,C.Shi,P.Zhu,Z.Zeng,H.Zhang,Autonomousexplorationofmobilerobotsviadeepreinforcementlearningbasedonspatiotemporal information on graph, Applied Sciences 11 (18) (2021) 8299
work page 2021
- [15]
-
[16]
S.Zhao,S.-H.Hwang,Exploration-andexploitation-drivendeepdeterministicpolicygradientforactiveslaminunknownindoorenvironments, Electronics 13 (5) (2024) 999
work page 2024
-
[17]
N.Fernando,D.A.McMeekin,I.Murray,Routeplanningmethodsinindoornavigationtoolsforvisionimpairedpersons:asystematicreview, Disability and Rehabilitation: Assistive Technology 18 (6) (2023) 763–782
work page 2023
- [18]
-
[19]
D. Chen, S. Li, J. Wang, Y. Feng, Y. Liu, A multi-objective trajectory planning method based on the improved immune clonal selection algorithm, Robotics and computer-integrated manufacturing 59 (2019) 431–442
work page 2019
-
[20]
P. Balatti, I. Ozdamar, D. Sirintuna, L. Fortini, M. Leonori, J. M. Gandarias, A. Ajoudani, Robot-assisted navigation for visually impaired through adaptive impedance and path planning, in: 2024 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2024, pp. 2310–2316
work page 2024
-
[21]
First Author et al.:Preprint submitted to ElsevierPage 23 of 24 Short Title of the Article
B.Li,Y.Ouyang,L.Li,Y.Zhang,Autonomousdrivingoncurvyroadswithoutrelianceonfrenetframe:Acartesian-basedtrajectoryplanning method, IEEE Transactions on Intelligent Transportation Systems 23 (9) (2022) 15729–15741. First Author et al.:Preprint submitted to ElsevierPage 23 of 24 Short Title of the Article
work page 2022
-
[23]
B. Li, Y. Zhang, Fast trajectory planning in cartesian rather than frenet frame: A precise solution for autonomous driving in complex urban scenarios, IFAC-PapersOnLine 53 (2) (2020) 17065–17070
work page 2020
-
[24]
M. Morsali, E. Frisk, J. Åslund, Spatio-temporal planning in multi-vehicle scenarios for autonomous vehicle using support vector machines, IEEE Transactions on Intelligent Vehicles 6 (4) (2020) 611–621
work page 2020
- [25]
- [26]
- [27]
-
[28]
Y. Wang, Z. Lin, Research on path planning for autonomous vehicle based on frenet system, Journal of engineering research 11 (2) (2023) 100080
work page 2023
-
[29]
J.Wang,J.Wu,X.Zheng,D.Ni,K.Li,Drivingsafetyfieldtheorymodelinganditsapplicationinpre-collisionwarningsystem,Transportation research part C: emerging technologies 72 (2016) 306–324
work page 2016
-
[30]
R.Zhang,H.Guo,M.A.Sotelo,H.Du,A.Darius,Z.Li,Newrrt-basedmethodforvehiclepathplanningincurvescenariosconsideringpath oscillations, IEEE Transactions on Vehicular Technology (2025)
work page 2025
- [31]
-
[32]
B.Zhao,Y.Wu,C.Wu,R.Sun,Deepreinforcementlearningtrajectoryplanningforroboticmanipulatorbasedonsimulation-efficienttraining, Scientific Reports 15 (1) (2025) 8286
work page 2025
-
[33]
Y. Qin, Y. Huang, W. Yu, H. Wang, Roitp: Road obstacle-involved trajectory planner for autonomous trucks, Chinese Journal of Mechanical Engineering 38 (1) (2025) 9
work page 2025
-
[34]
M.Jin,M.Qu,Q.Gao,Z.Huang,T.Su,Z.Liang,Advancedtrajectoryplanningandcontrolforautonomousvehicleswithquinticpolynomials, Sensors 24 (24) (2024) 7928
work page 2024
-
[35]
X.Qian,F.Altché,P.Bender,C.Stiller,A.deLaFortelle,Optimaltrajectoryplanningforautonomousdrivingintegratinglogicalconstraints: An miqp perspective, in: 2016 IEEE 19th international conference on intelligent transportation systems (ITSC), IEEE, 2016, pp. 205–210
work page 2016
-
[36]
J. Wang, J. Wu, Y. Li, The driving safety field based on driver–vehicle–road interactions, IEEE Transactions on Intelligent Transportation Systems 16 (4) (2015) 2203–2214
work page 2015
-
[37]
D. Helbing, J. Keltsch, P. Molnar, Modelling the evolution of human trail systems, Nature 388 (6637) (1997) 47–50
work page 1997
-
[38]
K. Chu, M. Lee, M. Sunwoo, Local path planning for off-road autonomous driving with avoidance of static obstacles, IEEE transactions on intelligent transportation systems 13 (4) (2012) 1599–1616
work page 2012
- [39]
-
[40]
R.Trauth,K.Moller,G.Würsching,J.Betz,Frenetix:Ahigh-performanceandmodularmotionplanningframeworkforautonomousdriving, IEEE Access (2024)
work page 2024
- [41]
-
[42]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms, arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[44]
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780
work page 1997
-
[45]
D.Dakopoulos,N.G.Bourbakis,Wearableobstacleavoidanceelectronictravelaidsforblind:asurvey,IEEETransactionsonSystems,Man, and Cybernetics, Part C (Applications and Reviews) 40 (1) (2009) 25–35
work page 2009
- [46]
-
[47]
H.Khan,T.D.Chaudhari,J.V.N.Ramesh,A.S.Kranthi,E.Muniyandy,Y.A.B.El-Ebiary,D.N.P.Devadhas,Neuro-symbolicreinforcement learningforcontext-awaredecisionmakinginsafeautonomousvehicles.,InternationalJournalofAdvancedComputerScience&Applications 16 (5) (2025)
work page 2025
-
[48]
C.Glanois,P.Weng,M.Zimmer,D.Li,T.Yang,J.Hao,W.Liu,Asurveyoninterpretablereinforcementlearning,MachineLearning113(8) (2024) 5847–5890
work page 2024
-
[49]
M.Althoff,M.Koschi,S.Manzinger,Commonroad:Composablebenchmarksformotionplanningonroads,in:2017IEEEIntelligentVehicles Symposium (IV), IEEE, 2017, pp. 719–726. First Author et al.:Preprint submitted to ElsevierPage 24 of 24
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.