Distributed Nesterov Flows for Multi-agent Optimization
Pith reviewed 2026-05-10 06:12 UTC · model grok-4.3
The pith
A continuous-time Nesterov flow model yields discrete distributed algorithms that converge faster than standard gradient methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish a continuous-time approximation of distributed Nesterov gradient descent. The convergence properties and convergence rate of the resulting distributed Nesterov flow are analyzed using Lyapunov methods. Building on these insights, we design new parameter choices within the flow, from which we derive flow-inspired discrete-time algorithms for multi-agent optimization. The resulting algorithms achieve faster convergence compared to existing distributed gradient descent methods.
What carries the argument
The distributed Nesterov flow, a continuous-time dynamical system that approximates the discrete momentum-based updates and enables Lyapunov-based convergence analysis plus improved parameter selection.
If this is right
- The new discrete algorithms reach given accuracy in fewer iterations than prior distributed gradient descent for strongly convex objectives.
- The algorithms exhibit an improved convergence rate for general convex objectives.
- No additional communication rounds are needed beyond those of standard methods.
- The convergence rate has an explicit dependence on the condition number of the communication graph.
Where Pith is reading between the lines
- The same continuous-time modeling step could be applied to other accelerated distributed methods to derive improved discrete versions.
- The explicit graph-condition-number relation suggests that rewiring the network could further accelerate the new algorithms.
- The flow framework may support analysis of time-varying communication topologies without redesigning the discrete updates from scratch.
Load-bearing premise
The continuous-time approximation of distributed Nesterov gradient descent accurately captures the discrete dynamics sufficiently well to enable valid convergence analysis and improved parameter selection for the discrete algorithms.
What would settle it
A side-by-side run of the proposed discrete algorithms versus standard distributed gradient descent on the same strongly convex multi-agent problem, counting iterations to a fixed accuracy target, would show whether the claimed reduction in iterations holds.
Figures
read the original abstract
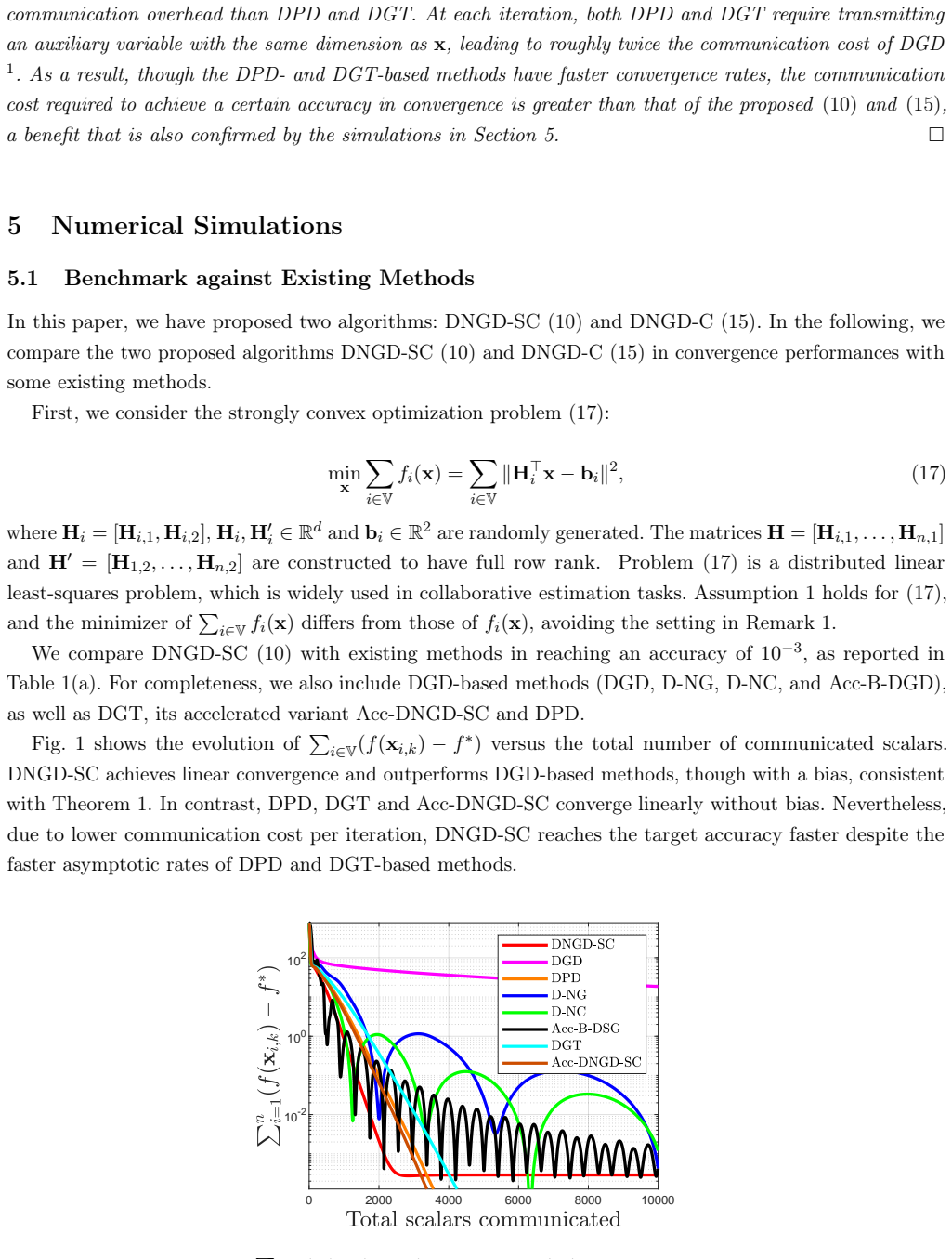
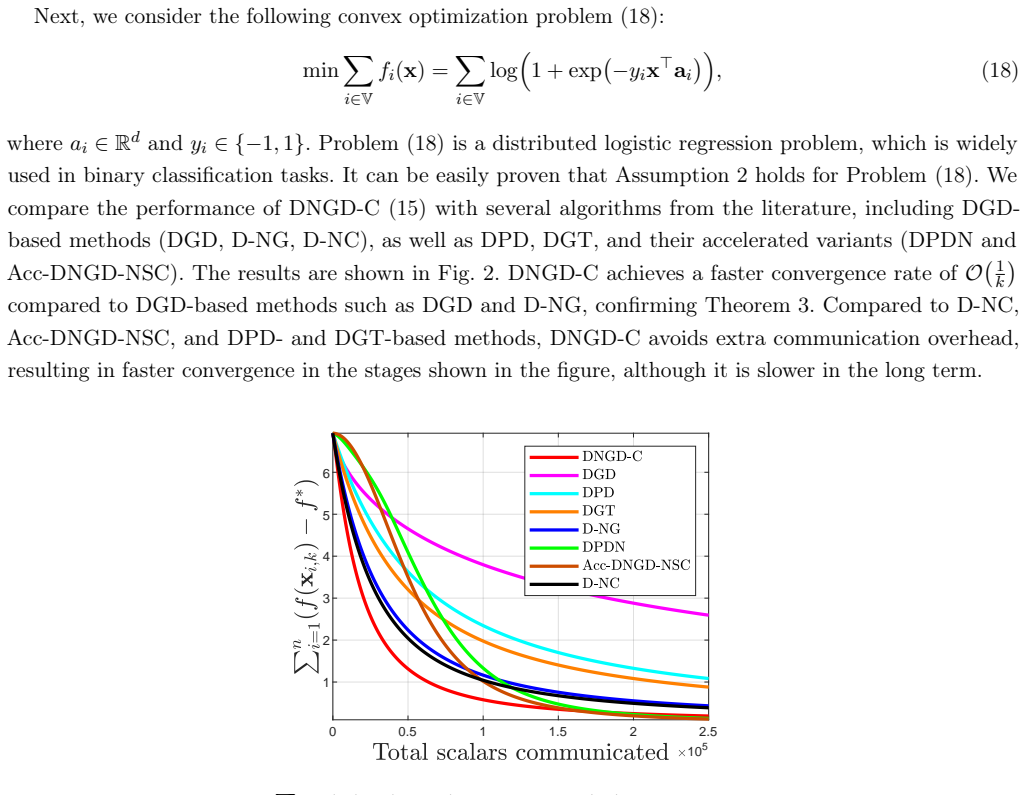
Various distributed gradient descent algorithms for multi-agent optimization have incorporated the Nesterov accelerated gradient method, where the use of momentum enhances convergence rates. These algorithms have found broad applications in large-scale machine learning and optimization owing to their simplicity and low communication complexity. In this paper, we establish a continuous-time approximation of distributed Nesterov gradient descent. The convergence properties and convergence rate of the resulting distributed Nesterov flow are analyzed using Lyapunov methods. Building on these insights, we design new parameter choices within the flow, from which we derive flow-inspired discrete-time algorithms for multi-agent optimization. Surprisingly, the resulting algorithms achieve faster convergence compared to existing distributed gradient descent methods: they require fewer iterations to reach the same accuracy for strongly convex functions and exhibit an improved convergence rate for general convex functions without incurring additional communication rounds. Furthermore, we investigate the influence of the network topology on algorithm performance and derive an explicit relationship between the convergence rate and the graph condition number. Numerical simulations are presented to validate the effectiveness of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes a continuous-time distributed Nesterov flow as an approximation to discrete distributed Nesterov gradient descent for multi-agent optimization over networks. It analyzes the flow's convergence properties and rates via Lyapunov methods, uses the analysis to select new momentum and step-size parameters, derives corresponding discrete-time algorithms, claims these achieve faster convergence (fewer iterations for strongly convex objectives; improved rate for general convex objectives) than standard distributed gradient descent without extra communication rounds, derives an explicit dependence of the rate on the graph condition number, and validates the approach with numerical simulations.
Significance. If the continuous-to-discrete transfer is rigorously justified, the work offers a systematic flow-based method for designing accelerated distributed optimization algorithms with topology-dependent rates, which could reduce iteration counts in large-scale multi-agent and machine-learning settings while preserving low communication complexity. The Lyapunov analysis and explicit graph-condition-number relation are constructive contributions.
major comments (2)
- [Section on derivation of discrete-time algorithms] The central claim that the flow-inspired discrete algorithms converge faster rests on the unstated assumption that the continuous-time approximation is sufficiently faithful. No discretization-error bounds or direct convergence proof for the final discrete algorithms (derived in the section following the Lyapunov analysis) are provided, leaving open whether step-size/momentum discretization artifacts eliminate the reported gains. This is load-bearing for both the strongly convex and general convex claims.
- [Section on convergence rates and graph condition number] The improved rate for general convex functions is asserted without additional communication rounds, but the manuscript does not supply an explicit iteration-complexity comparison (e.g., O(1/k) vs. O(1/k^2) or similar) against baseline distributed gradient descent that accounts for the network topology; the Lyapunov-derived continuous rate alone does not automatically transfer.
minor comments (2)
- [Abstract] The abstract's use of 'surprisingly' for the faster convergence should be replaced by a neutral statement; the improvement is presented as a consequence of the flow analysis rather than an unexpected outcome.
- [Preliminaries / Section 2] Notation for the momentum parameters and the graph condition number could be introduced more explicitly in the preliminaries to aid readability when the flow equations are first stated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications on the scope of our analysis and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Section on derivation of discrete-time algorithms] The central claim that the flow-inspired discrete algorithms converge faster rests on the unstated assumption that the continuous-time approximation is sufficiently faithful. No discretization-error bounds or direct convergence proof for the final discrete algorithms (derived in the section following the Lyapunov analysis) are provided, leaving open whether step-size/momentum discretization artifacts eliminate the reported gains. This is load-bearing for both the strongly convex and general convex claims.
Authors: We acknowledge that the manuscript relies on the continuous-time Lyapunov analysis to select parameters and derive the discrete algorithms via standard discretization, without providing explicit discretization-error bounds or a standalone convergence proof for the discrete versions. The faster convergence claims for both strongly convex and general convex cases are supported by the continuous analysis and validated through numerical simulations. In the revised manuscript, we will add a dedicated discussion clarifying the continuous-to-discrete connection, referencing related literature on discretization of accelerated flows, and explicitly noting the absence of rigorous discrete error bounds as a limitation of the current work. revision: partial
-
Referee: [Section on convergence rates and graph condition number] The improved rate for general convex functions is asserted without additional communication rounds, but the manuscript does not supply an explicit iteration-complexity comparison (e.g., O(1/k) vs. O(1/k^2) or similar) against baseline distributed gradient descent that accounts for the network topology; the Lyapunov-derived continuous rate alone does not automatically transfer.
Authors: The explicit dependence of the rate on the graph condition number is derived from the continuous-time Lyapunov analysis. For the discrete algorithms, the improved rate for general convex objectives (without extra communication) is demonstrated via simulations. We agree that an explicit iteration-complexity comparison incorporating the network topology would improve clarity. In the revision, we will add a subsection providing such a comparison, relating the continuous rate to the discrete setting for small step sizes and highlighting how the graph condition number enters the complexity bounds. revision: yes
- A complete discretization-error analysis and direct convergence proof for the derived discrete-time algorithms are not included in the manuscript.
Circularity Check
No significant circularity; derivation proceeds from independent continuous-time analysis to discrete algorithms.
full rationale
The paper constructs a continuous-time distributed Nesterov flow as an approximation to existing discrete methods, then applies Lyapunov analysis directly to this flow to obtain convergence rates and new parameter selections. These parameters are used to define new discrete-time algorithms. No step reduces a claimed result to a fitted input, self-citation, or definitional renaming; the Lyapunov-derived rates and parameter choices are obtained from the flow equations themselves rather than presupposing the discrete performance gains. The central claims about discrete convergence improvements are presented as consequences of the flow-inspired design, with numerical validation offered separately. This chain is self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- Momentum and step-size parameters in the Nesterov flow
axioms (2)
- domain assumption The communication network is undirected and connected
- domain assumption Objective functions are convex or strongly convex
Reference graph
Works this paper leans on
-
[1]
M. Mesbahi and M. Egerstedt.Graph Theoretic Methods in Multiagent Networks. Princeton University Press, 2010
work page 2010
-
[2]
Motion Coordination with Distributed Information,
S. Martinez, J. Cortés, and F. Bullo, “Motion Coordination with Distributed Information,”IEEE Control Systems Magazine, vol. 27, no. 4, pp. 75-88, 2007
work page 2007
-
[3]
S. Kar, J. M. F. Moura and K. Ramanan, “Distributed Parameter Estimation in Sensor Networks: Nonlinear Observation Models and Imperfect Communication,”IEEE Transactions on Information Theory, vol. 58, no. 6, pp. 3575-52, 2012
work page 2012
-
[4]
Gossip Algorithms for Distributed Signal Processing,
A. G. Dimakis, S. Kar, J. M. F. Moura, M. G. Rabbat, and A Scaglione, “Gossip Algorithms for Distributed Signal Processing,”Proceedings of IEEE, vol. 98, no. 11, pp. 1847-1864, 2010
work page 2010
-
[5]
Distributed Opti- mization in Distribution Systems: Use Cases, Limitations, and Research Needs,
N. Patari, V. Venkataramanan, A. Srivastava, D. Molzahn, N. Li, A. Annaswamy, “Distributed Opti- mization in Distribution Systems: Use Cases, Limitations, and Research Needs,”IEEE Transactions on Power Systems, vol. 37, no. 5, pp. 3469–3481, 2022
work page 2022
-
[6]
An Improved Analysis of Gradient Tracking for Decentralized Machine Learning,
A. Koloskova, T. Lin, S. U. Stich, “An Improved Analysis of Gradient Tracking for Decentralized Machine Learning,” inProceedings of Neural Information Processing Systems, pp. 11422–11435, 2021
work page 2021
-
[7]
J. Shen, E. K. H. Kammara, L. Du, “Nonconvex, Fully Distributed Optimization Based CAV Platooning Control under Nonlinear Vehicle Dynamics,”IEEE Transactions on Intelligent Transportation Systems, 2022. 16
work page 2022
-
[8]
Fast Distributed Gradient Methods,
D. Jakovetić, J. Xavier and J. M. F. Moura, “Fast Distributed Gradient Methods,”IEEE Transactions on Automatic Control, vol. 59, no. 5, pp. 1131-1146, 2014
work page 2014
-
[9]
Distributed Nesterov-like Gradient Algorithms,
D. Jakovetić, J. Moura and J. Xavier, “Distributed Nesterov-like Gradient Algorithms,” inProceedings of IEEE Conference on Decision and Control, pp. 5459-5464, 2012
work page 2012
-
[10]
Distributed Stochastic Optimization With Unbounded Subgradients Over Randomly Time-Varying Networks,
Y. Chen, A. L. Fradkov, K. Fu, X. Fu, and T. Li, “Distributed Stochastic Optimization With Unbounded Subgradients Over Randomly Time-Varying Networks,”IEEE Transactions on Automatic Control, vol. 70, no. 6, pp. 4008–4015, Jun. 2025, doi: 10.1109/TAC.2024.3525182
-
[11]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), PMLR, volume 54, pp. 1273–1282, 2017
work page 2017
-
[12]
Distributed Subgradient Methods for Multi-agent Optimization,
A. Nedic and A. Ozdaglar, “Distributed Subgradient Methods for Multi-agent Optimization,”IEEE Transaction on Automatic Control, vol. 54, no. 1, pp. 48–61, 2009
work page 2009
-
[13]
M. Bin, I. Notarnicola, L. Marconi and G. Notarstefano, “A System Theoretical Perspective to Gradient- tracking Algorithms for Distributed Quadratic Optimization,” InProceedings of IEEE Conference on Decision and Control, pp. 2994-2999, 2019
work page 2019
-
[14]
An Accelerated Decentralized Stochastic Proximal Algorithm for Finite Sums,
H. Hendrikx, F, Bach and L. Massoulié, “An Accelerated Decentralized Stochastic Proximal Algorithm for Finite Sums,” inProceedings of Neural Information Processing Systems, vol. 32, pp. 952–962, 2019
work page 2019
-
[15]
Accelerated Primal-Dual Algorithms for Distributed Smooth Convex Optimization over Networks,
J. Xu, Y. Tian, Y. Sun, and G. Scutari, “Accelerated Primal-Dual Algorithms for Distributed Smooth Convex Optimization over Networks,” inProceedings of the International Conference on Machine Learning, vol. 108, pp. 10562–10572, 2020
work page 2020
-
[16]
Accelerated Distributed Nesterov Gradient Descent,
G. Qu and N. Li, “Accelerated Distributed Nesterov Gradient Descent,”IEEE Transactions on Automatic Control, vol. 65, no. 6, pp. 2566-2581, 2020
work page 2020
-
[17]
R. Xin and U. A. Khan, “Distributed Heavy-Ball: A Generalization and Acceleration of First-Order Methods With Gradient Tracking,”IEEE Transactions on Automatic Control, vol. 65, no. 6, pp. 2627-2633, 2020
work page 2020
-
[18]
A Differential Equation for Modeling Nesterov’s Accelerated Gradient Method: Theory and Insights,
W. Su, S. Boyd and E. Candes, “A Differential Equation for Modeling Nesterov’s Accelerated Gradient Method: Theory and Insights,”Journal of Machine Learning Research, vol.17, pp. 1-43, 2016
work page 2016
-
[19]
Rate of Convergence of the Nesterov Accelerated Gradient Method in the Subcritical Caseα≤ 3,
H. Attouch, Z. Chbani, and H. Riahi, “Rate of Convergence of the Nesterov Accelerated Gradient Method in the Subcritical Caseα≤ 3,”ESAIM: Control, Optimization Calculus Variations, vol. 25, pp. 1–34, 2019
work page 2019
-
[20]
Fast Convergence of Inertial Dynamics and Algorithms with Asymptotic Vanishing Viscosity,
H. Attouch, Z. Chbani, J. Peypouquet, and P. Redont, “Fast Convergence of Inertial Dynamics and Algorithms with Asymptotic Vanishing Viscosity,”Mathematical Programming, vol. 168, no. 1/2, pp. 123–175, 2018
work page 2018
-
[21]
Dynamical Primal-Dual Nesterov Accelerated Method and Its Application to Network Optimization,
X. Zeng, J. Lei and J. Chen, “Dynamical Primal-Dual Nesterov Accelerated Method and Its Application to Network Optimization,”IEEE Transactions on Automatic Control, vol. 68, no. 3, pp. 1760-1767, 2023. 17
work page 2023
-
[22]
S. Liang, X. Zeng, and Y. Hong, “Distributed Nonsmooth Optimization with Coupled Inequality Constraints via Modified Lagrangian Function,”IEEE Transactions on Automatic Control, vol. 63, no. 6, pp. 1753–1759, 2018
work page 2018
-
[23]
A Control Approach to Distributed Optimization,
J. Wang and N. Elia, “A Control Approach to Distributed Optimization,” in2010 48th Annual Allerton Conference on Communication, Control, and Computing, pp. 557-561. 2010,
work page 2010
-
[24]
Distributed Continuous-time Convex Optimization on Weight-balanced Digraphs,
B. Gharesifard and J. Cortés, “Distributed Continuous-time Convex Optimization on Weight-balanced Digraphs,”IEEE Transactions on Automatic Control, vol. 59, no. 3, pp. 781-786, 2014
work page 2014
-
[25]
A Multi-agent System with A Proportional-integral Protocol for Distributed Constrained Optimization,
S. Yang, Q. Liu and J. Wang, “A Multi-agent System with A Proportional-integral Protocol for Distributed Constrained Optimization,”IEEE Transactions on Automatic Control, vol. 62, no. 7, pp. 3461-3467, 2017
work page 2017
-
[26]
An Asynchronous Distributed Algorithm for Solving a Linear Algebraic Equation,
J. Liu, S. Mou and A. S. Morse, “An Asynchronous Distributed Algorithm for Solving a Linear Algebraic Equation,” InProceedings of IEEE Conference on Decision and Control, pp. 5409-5414, 2013
work page 2013
-
[27]
Network Flows That Solve Linear Equations,
G. Shi, B. D. O. Anderson, and U. Helmke, “Network Flows That Solve Linear Equations,”IEEE Transactions on Automatic Control, vol. 62, no. 6, pp. 2659–2674, 2017
work page 2017
-
[28]
A Passivity-Based Approach to Nash Equilibrium Seeking Over Networks,
D. Gadjov and L. Pavel, “A Passivity-Based Approach to Nash Equilibrium Seeking Over Networks,” IEEE Transactions on Automatic Control, vol. 64, no. 3, pp. 1077–1092, 2019
work page 2019
-
[29]
Distributed Nash Equilibrium Seeking by a Consensus-Based Approach,
M. Ye and G. Hu, “Distributed Nash Equilibrium Seeking by a Consensus-Based Approach,”IEEE Transactions on Automatic Control, vol. 62, no. 9, pp. 4811–4818, 2017
work page 2017
-
[30]
L. Wang and G. Shi, “Distributed Flow Computing,”Foundations and Trends in Systems and Control, vol. 12, no 1, 2025
work page 2025
-
[31]
Y. Nesterov.Introductory Lectures on Convex Pptimization: A Basic Course, Kluwer Academic Pub- lishers, Boston, 2004
work page 2004
-
[32]
A Variational Perspective on Accelerated Methods in Optimization,
A. Wibisono, A. Wilson, M. Jordan, “A Variational Perspective on Accelerated Methods in Optimization,” Proceedings of the National Academy of Sciences of the United States of America, vol.113, no. 47, pp. E7351-E7358, 2016
work page 2016
-
[33]
EXTRA: An Exact First-order Algorithm for Decentralized Consensus Optimization,
W. Shi, Q. Ling, G. Wu, and W. Yin, “EXTRA: An Exact First-order Algorithm for Decentralized Consensus Optimization,”SIAM Journal on Optimization, vol. 25, no. 2, pp. 944-966, 2015
work page 2015
-
[34]
X. Yi, S. Zhang, T. Yang, T. Chai and K. H. Johansson, “Linear Convergence of First- and Zeroth-order Primal–dual Algorithms for Distributed Nonconvex Optimization,”IEEE Transactions on Automatic Control, vol. 67, no. 8, pp. 4194-4201, 2022
work page 2022
-
[35]
G. Wu, R. Mallipeddi and P. Suganthan, “Problem Definitions and Evaluation Criteria for the CEC 2017 Competition on Constrained Real-Parameter Optimization”. National University of Defense Technology, Kyungpook National University and Nanyang Technological, 2017
work page 2017
-
[36]
Distributed Optimization by Network Flows With Spatio-Temporal Compression,
Z. Ren et al., “Distributed Optimization by Network Flows With Spatio-Temporal Compression,” in IEEE Transactions on Automatic Control, doi: 10.1109/TAC.2026.3654479. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.