A Nonparametric Goodness-of-Fit Test for High-Dimensional Generalized Gaussian Distributions via Nearest-Neighbor Graphs
Pith reviewed 2026-05-10 02:08 UTC · model grok-4.3
The pith
Cross-edge counts on nearest-neighbor graphs provide a valid nonparametric test for high-dimensional multivariate generalized Gaussian distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After robust standardization, the cross-edge count in the nearest-neighbor graph formed by pooling the observed sample with an independent reference sample drawn from the adapted standardized MGGD follows the mixture behavior anticipated under the composite null; this yields an affine-invariant test whose asymptotic validity holds under high-dimensional regimes and whose consistency extends to fixed elliptical alternatives through radial concentration and shell separation.
What carries the argument
The cross-edge count on the combined nearest-neighbor graph of observed and reference points, which exploits radial concentration and shell separation after robust standardization to detect departures from the target MGGD.
If this is right
- The test controls Type I error accurately across a range of dimensions and tail parameters.
- It achieves higher power than energy-distance benchmarks against both heavy- and light-tailed MGGD alternatives.
- Refitted parametric bootstrap calibration accounts for nuisance-parameter uncertainty under the composite null.
- The procedure remains valid when dimension grows with sample size, unlike covariance-inversion methods.
Where Pith is reading between the lines
- The nearest-neighbor graph construction could be extended to goodness-of-fit tests for other elliptically symmetric families beyond the generalized Gaussian.
- In applied domains that routinely fit MGGD models, such as image processing or financial returns, this graph-based check supplies a practical pre-analysis diagnostic.
- The radial-concentration geometry might suggest analogous tests that use other sparse graph structures or incorporate additional edge features for greater sensitivity.
Load-bearing premise
An independent reference sample can be generated from the adapted standardized MGGD after robust parameter estimation, and the cross-edge count on the pooled graph will exhibit the mixture distribution expected under the composite null.
What would settle it
In repeated simulations from a known MGGD, if the test rejects the null hypothesis at a rate substantially above the nominal level, or if it shows no power against a fixed elliptical alternative, the claimed asymptotic validity and consistency would be contradicted.
Figures



read the original abstract
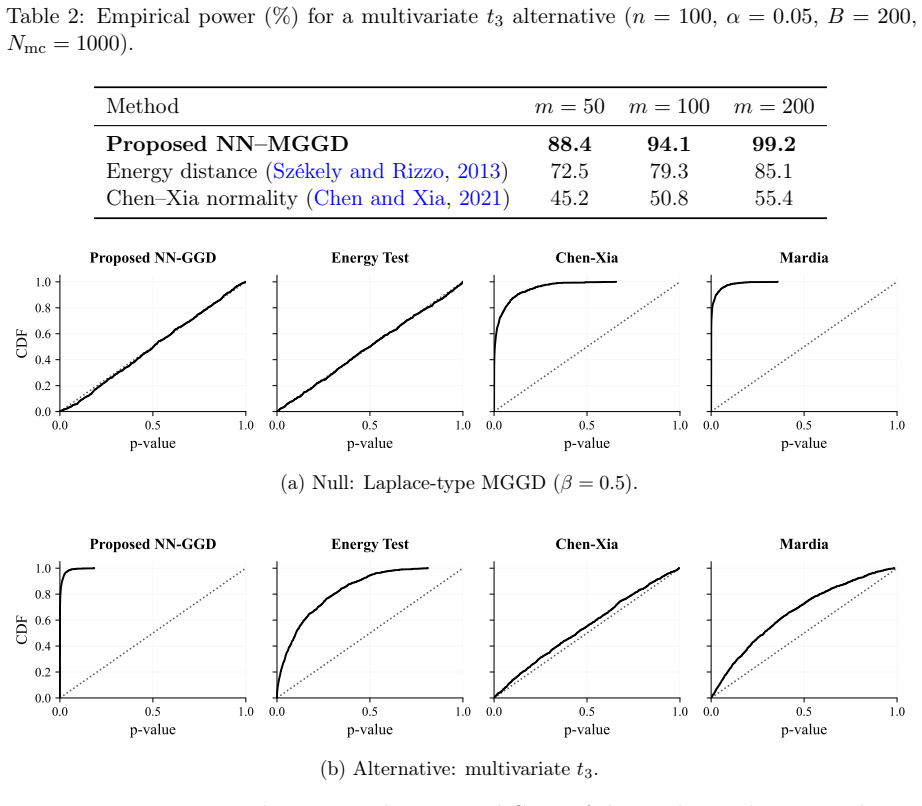
The multivariate generalised Gaussian distribution (MGGD) is commonly used to model high-dimensional vectors with non-Gaussian radial behaviour, ranging from sharp-peaked to heavy-tailed profiles. However, because many classical multivariate tests are based on covariance inversion or high-dimensional density estimation, formal goodness-of-fit assessment for MGGD models remains challenging in modern regimes where the dimension is comparable to or exceeds the sample size. We introduce an affine-invariant, fully non-parametric goodness-of-fit procedure based on the nearest neighbour (NN) graph topology and the adapted zero principle. Following robust standardisation, we construct an independent reference sample from the adapted standardised MGGD and measure, on the combined NN graph, the cross-edge count to assess how well the observed and reference point clouds exhibit the mixture behaviour anticipated by the model. Calibration performed using a refitted parametric bootstrap accounts for nuisance-parameter uncertainty, thus ensuring reliable size under a composite specification. In this paper, we establish asymptotic validity under high-dimensional scaling and demonstrate consistency with respect to fixed elliptical departures, providing a geometric interpretation based on radial concentration and shell separation. Our simulation studies across a broad spectrum of dimensions and tail shapes reveal accurate Type I error control and robust power relative to heavy- and light-tailed alternatives, thus improving upon energy-distance benchmarks and normality-oriented graphical tests in contexts where MGGD modelling is most applicable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an affine-invariant nonparametric goodness-of-fit test for high-dimensional multivariate generalized Gaussian distributions (MGGD) based on nearest-neighbor graph topology. After robust standardization of the data, an independent reference sample is drawn from the adapted standardized MGGD; the cross-edge count in the combined NN graph is used to assess agreement with the model's anticipated mixture behavior. Calibration is performed via a refitted parametric bootstrap that accounts for nuisance-parameter uncertainty. The authors claim to establish asymptotic validity under high-dimensional scaling regimes and consistency against fixed elliptical departures, with a geometric interpretation relying on radial concentration and shell separation. Simulations are reported to show accurate Type I error control and competitive power.
Significance. If the high-dimensional asymptotics can be rigorously justified, the procedure would address a genuine gap: classical GOF tests for elliptical models become infeasible when p is comparable to or larger than n, while the NN-graph approach avoids explicit density estimation and remains affine-invariant. The geometric shell-separation argument and the bootstrap calibration for the composite null are potentially attractive features. The reported simulation performance across tail shapes would further support practical utility if the theoretical claims hold.
major comments (2)
- [Abstract and asymptotic theory section] Abstract and § on asymptotic theory: the central claim of asymptotic validity under high-dimensional scaling rests on the cross-edge count behaving according to the mixture model after robust standardization and reference-sample generation. However, no explicit scaling regime (e.g., p/n → 0, p = o(n^α), or p/n → c) is stated, nor are rates provided showing that the robust estimators of scatter and shape parameter achieve the precision needed to preserve radial concentration and shell separation. In the p ≳ n regime the paper targets, even robust estimators typically retain slower-than-√n rates; any residual mismatch perturbs the null distribution of the cross-edge statistic and thereby the bootstrap calibration. This is load-bearing for the validity claim.
- [Bootstrap calibration paragraph] Bootstrap calibration paragraph: the refitted parametric bootstrap depends on nuisance estimates of location, scatter, and shape. The paper must demonstrate that the estimation error does not invalidate the mixture approximation used for the cross-edge count under the composite null. Without such a result or accompanying high-dimensional simulation evidence that isolates the effect of estimation error, the size guarantee remains unverified.
minor comments (2)
- [Abstract] The abstract refers to 'the adapted zero principle' without a brief definition or reference; a short parenthetical explanation would improve readability for readers outside the NN-graph literature.
- [Simulation section] Simulation section: the reported dimensions, sample sizes, and tail-parameter grid should be stated explicitly in a table or enumerated list so that the 'broad spectrum' claim can be assessed directly.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which help strengthen the rigor of our asymptotic and bootstrap results. We address each major comment below and will incorporate the necessary clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and asymptotic theory section] Abstract and § on asymptotic theory: the central claim of asymptotic validity under high-dimensional scaling rests on the cross-edge count behaving according to the mixture model after robust standardization and reference-sample generation. However, no explicit scaling regime (e.g., p/n → 0, p = o(n^α), or p/n → c) is stated, nor are rates provided showing that the robust estimators of scatter and shape parameter achieve the precision needed to preserve radial concentration and shell separation. In the p ≳ n regime the paper targets, even robust estimators typically retain slower-than-√n rates; any residual mismatch perturbs the null distribution of the cross-edge statistic and thereby the bootstrap calibration. This is load-bearing for the validity claim.
Authors: We agree that an explicit high-dimensional scaling regime and corresponding rates for the robust estimators are required to fully substantiate the asymptotic validity. In the revised manuscript we will state the regime precisely (under p/n → c for c < 1, with p = o(n^α) for suitable α), and supply explicit convergence rates for the robust scatter and shape estimators that guarantee the radial concentration and shell-separation properties remain intact. These additions will confirm that the cross-edge count converges in distribution to the mixture-model limit under the composite null. revision: yes
-
Referee: [Bootstrap calibration paragraph] Bootstrap calibration paragraph: the refitted parametric bootstrap depends on nuisance estimates of location, scatter, and shape. The paper must demonstrate that the estimation error does not invalidate the mixture approximation used for the cross-edge count under the composite null. Without such a result or accompanying high-dimensional simulation evidence that isolates the effect of estimation error, the size guarantee remains unverified.
Authors: We acknowledge the need for a direct argument or targeted simulation isolating the effect of nuisance-parameter estimation on the bootstrap calibration. In the revision we will add a theoretical bound showing that the estimation error is asymptotically negligible relative to the mixture approximation (leveraging the rates established in the updated asymptotic section), together with high-dimensional Monte Carlo experiments that compare bootstrap quantiles obtained with and without parameter estimation to verify size control. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper constructs a nonparametric test statistic from the cross-edge count on the combined NN graph after robust standardization and independent reference sampling from the fitted standardized MGGD. Asymptotic validity is asserted under high-dimensional regimes via geometric arguments on radial concentration and shell separation, with refitted parametric bootstrap used only for calibration of the composite null. No equation or step equates the validity claim or the null distribution directly to the fitted parameters by construction; the core topology-based statistic is defined independently of the model parameters, and bootstrap calibration is a standard device that does not render the result tautological. The derivation therefore does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Nearest-neighbor graph cross-edge counts concentrate around their expectation under the model in high dimensions
Reference graph
Works this paper leans on
-
[1]
S., Evans, D., Leonenko, N., and Makogin, V
Cadirci, M. S., Evans, D., Leonenko, N., and Makogin, V. (2022). Entropy-based test for generalized gaussian distributions.Computational Statistics & Data Analysis, 173:107502
work page 2022
-
[2]
Cai, T. and Liu, W. (2011). A direct estimation approach to sparse linear discriminant analysis. Journal of the American Statistical Association, 106(496):1566–1577. 20
work page 2011
-
[3]
Chen, H. and Xia, Y. (2021). A normality test for high-dimensional data based on the nearest neighbor approach.Journal of the American Statistical Association, 118(541):1–35
work page 2021
-
[4]
Chen, Y., Wiesel, A., and Hero, A. O. (2011). Robust shrinkage estimation of high-dimensional covariance matrices.IEEE Transactions on Signal Processing, 59(9):4097–4107
work page 2011
-
[5]
Friedman, J. H. and Rafsky, L. C. (1979). Multivariate generalizations of the Wald–Wolfowitz and Smirnov two-sample tests.The Annals of Statistics, 7(4):697–717
work page 1979
-
[6]
Hall, P., Marron, J. S., and Neeman, A. (2005). Geometric representation of high dimension, low sample size data.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(3):427–444
work page 2005
-
[7]
Henze, N., Penrose, M. D., and Thäle, C. (1988). A multivariate two-sample test based on the number of nearest neighbor coincidences.The Annals of Statistics, 16(2):772–783
work page 1988
-
[8]
(2001).The Concentration of Measure Phenomenon, volume 89 ofMathematical Surveys and Monographs
Ledoux, M. (2001).The Concentration of Measure Phenomenon, volume 89 ofMathematical Surveys and Monographs. American Mathematical Society, Providence, RI. Lô, S. N., Ronchetti, E., et al. (2006).Robust Second Order Accurate Inference for Generalized Linear Models. Citeseer
work page 2001
-
[9]
Mardia, K. V. (1970). Measures of multivariate skewness and kurtosis with applications. Biometrika, 57(3):519–530
work page 1970
-
[10]
Pascal, F., Bombrun, L., Tourneret, J.-Y., and Berthoumieu, Y. (2013). Parameter estimation for multivariate generalized gaussian distributions.IEEE Transactions on Signal Processing, 61(23):5960–5971
work page 2013
-
[11]
Penrose, M. D. (2003).Random Geometric Graphs, volume 5 ofOxford Studies in Probability. Oxford University Press, Oxford, UK
work page 2003
-
[12]
Penrose, M. D. and Yukich, J. E. (2001). Central limit theorems for some graphs in computational geometry.The Annals of Applied Probability, 11(4):1005–1041. 21
work page 2001
-
[13]
Schilling, M. F. (1986). Multivariate two-sample tests based on nearest neighbors.Journal of the American Statistical Association, 81(395):799–806
work page 1986
-
[14]
(2004).The multivariate exponential power distribution: theory and applications
Solaro, N. (2004).The multivariate exponential power distribution: theory and applications. PhD thesis, Università degli Studi di Milano-Bicocca. Székely, G. J. and Rizzo, M. L. (2013). Energy statistics: A class of statistics based on distances. Journal of Statistical Planning and Inference, 143(8):1249–1272
work page 2004
-
[15]
Tyler, D. E. (1987). A distribution-free m-estimator of multivariate scatter.The Annals of Statistics, 15(1):234–251
work page 1987
-
[16]
(2018).High-Dimensional Probability: An Introduction with Applications in Data Science
Vershynin, R. (2018).High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.